Quickstart: Apache Hive-query's uitvoeren in Azure HDInsight met Apache Zeppelin
In deze quickstart leert u hoe u Apache Zeppelin gebruikt om Apache Hive-query's uit te voeren in Azure HDInsight. Interactive Query-clusters in HDInsight bevatten Apache Zeppelin-notebooks waarmee u interactieve Hive-query's kunt uitvoeren.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
Een Interactive Query-cluster in HDInsight. Raadpleeg Cluster maken voor het maken van een HDInsight-cluster. Zorg ervoor dat u het clustertype Interactive Query kiest.
Een Apache Zeppelin-notitie maken
Vervang
CLUSTERNAMEdoor de naam van uw cluster in de volgende URL:https://CLUSTERNAME.azurehdinsight.net/zeppelin. Voer vervolgens de URL in een webbrowser in.Voer uw gebruikersnaam en wachtwoord in om u aan te melden bij het cluster. Op de Zeppelin-pagina kunt u een nieuwe notitie maken of bestaande notities openen. HiveSample bevat enkele voorbeelden van Hive-query's.
Selecteer Create new note (Nieuwe notitie maken).
Typ of selecteer in het dialoogvenster Create new note de volgende waarden:
- Naam van notitie: voer een naam in voor de notitie.
- Standaard-interpreter: selecteer jdbc in de vervolgkeuzelijst.
Selecteer Create Note (Notitie maken).
Voer de volgende Hive-query in de codesectie in en druk op Shift+Enter:
%jdbc(hive) show tables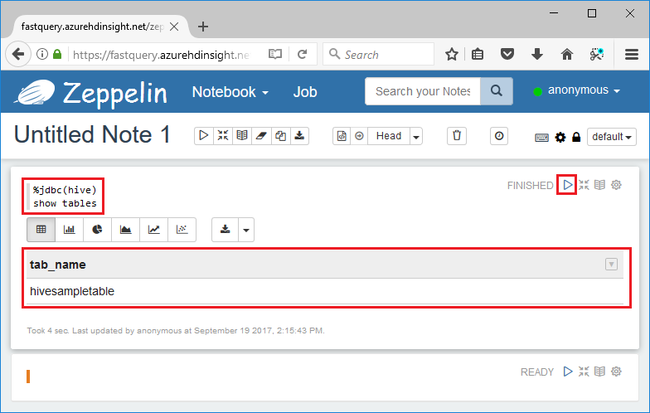
De
%jdbc(hive)instructie in de eerste regel geeft aan dat het notebook de Hive JDBC-interpreter moet gebruiken.De query retourneert een Hive-tabel met de naam hivesampletable.
Hier volgen nog twee Hive-query's die u kunt uitvoeren op hivesampletable:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}In vergelijking met de traditionele Hive komen de queryresultaten veel sneller terug.
Meer voorbeelden
Een tabel maken. Voer de code uit in het Zeppelin Notebook:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Gegevens in de nieuwe tabel laden. Voer de code uit in het Zeppelin Notebook:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Eén record invoegen. Voer de code uit in het Zeppelin Notebook:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Raadpleeg de Hive-taalhandleiding voor meer syntaxis.
Resources opschonen
Nadat u de quickstart hebt voltooid, kunt u het cluster verwijderen. Met HDInsight worden uw gegevens opgeslagen in Azure Storage zodat u een cluster veilig kunt verwijderen wanneer deze niet wordt gebruikt. Voor een HDInsight-cluster worden ook kosten in rekening gebracht, zelfs wanneer het niet wordt gebruikt. Aangezien de kosten voor het cluster vaak zoveel hoger zijn dan de kosten voor opslag, is het financieel gezien logischer clusters te verwijderen wanneer ze niet worden gebruikt.
Als u een cluster wilt verwijderen, raadpleegt u HDInsight-cluster verwijderen met behulp van uw browser, PowerShell of de Azure CLI.
Volgende stappen
In deze quickstart hebt u geleerd hoe u Apache Zeppelin gebruikt om Apache Hive-query's uit te voeren in Azure HDInsight. Meer informatie over Hive-query's vindt u in het volgende artikel. Hierin wordt uitgelegd hoe u query's kunt uitvoeren met Visual Studio.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor