Data Lake Tools voor Visual Studio gebruiken om verbinding te maken met Azure HDInsight en Apache Hive-query's uit te voeren
Meer informatie over het gebruik van Microsoft Azure Data Lake en Stream Analytics Tools voor Visual Studio (Data Lake Tools). Gebruik het hulpprogramma om verbinding te maken met Apache Hadoop-clusters in Azure HDInsight en Hive-query's te verzenden.
Zie Aan de slag met HDInsight voor meer informatie over het gebruik van HDInsight.
U kunt Data Lake Tools voor Visual Studio gebruiken voor toegang tot Azure Data Lake Analytics en HDInsight. Zie voor informatie over Data Lake Tools Zelfstudie: U-SQL-scripts ontwikkelen met Data Lake Tools voor Visual Studio.
Vereisten
U hebt het volgende nodig om dit artikel te voltooien en Data Lake Tools voor Visual Studio te gebruiken:
Een Azure HDInsight-cluster. Zie Aan de slag met Apache Hadoop in Azure HDInsight om een HDInsight-cluster te maken. Als u interactieve Apache Hive-query's wilt uitvoeren, hebt u een HDInsight Interactive Query-cluster nodig.
Visual Studio. De Visual Studio Community-editie is gratis. De instructies die hier worden weergegeven, zijn voor Visual Studio 2019.
Data Lake Tools voor Visual Studio installeren
Volg de juiste instructies voor het installeren van Data Lake Tools voor uw versie van Visual Studio:
Voor Visual Studio 2017 of Visual Studio 2019:
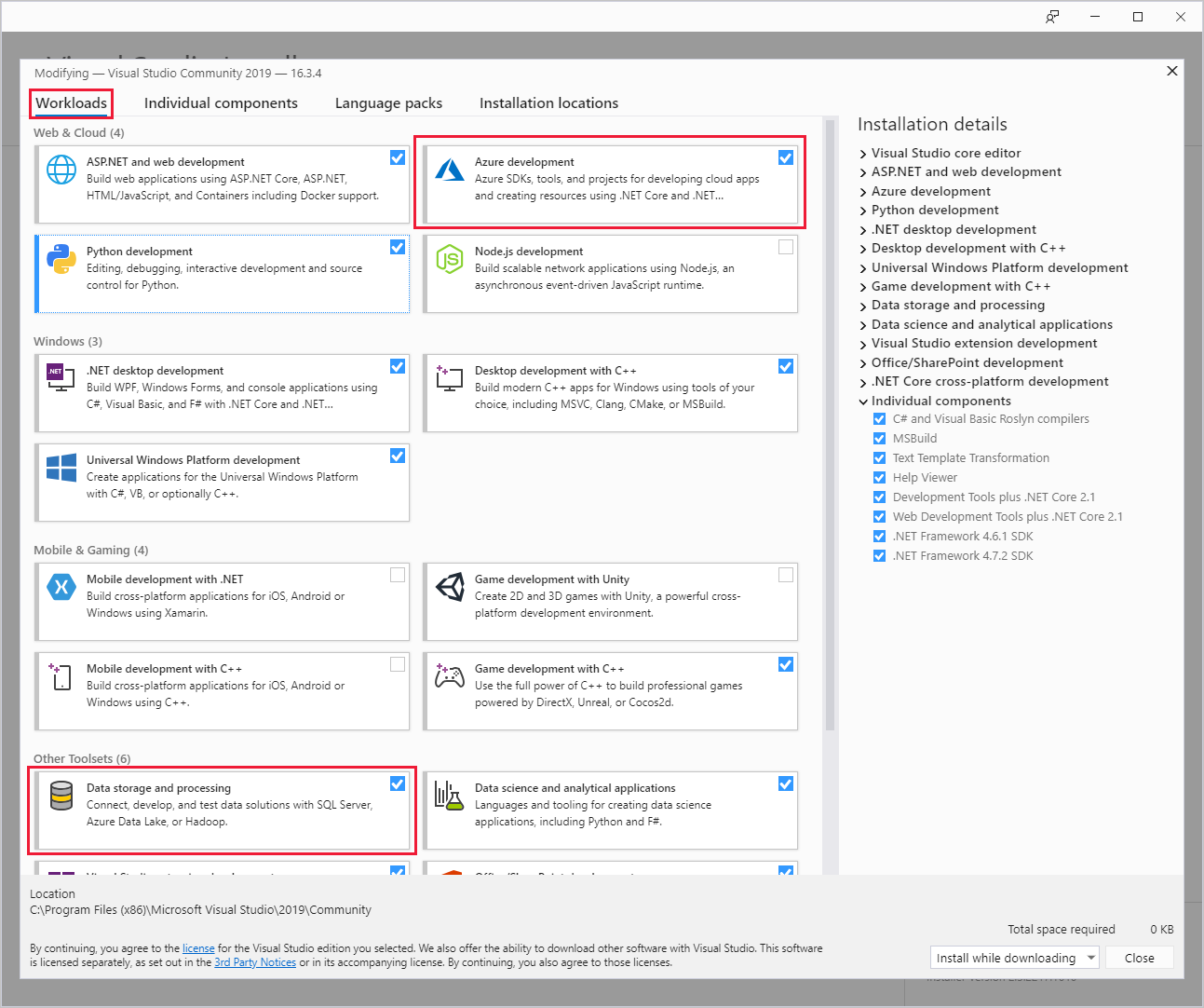
Zorg er tijdens de installatie van Visual Studio voor dat u de Azure-ontwikkelworkload of de werkbelasting voor gegevensopslag en -verwerking opneemt.
Voor bestaande Visual Studio-installaties gaat u naar de IDE-menubalk en selecteert u Hulpprogramma's>ophalen en onderdelen om Visual Studio Installer te openen. Selecteer op het tabblad Workloads ten minste de Azure-ontwikkelworkload (onder Web & Cloud). Of selecteer de werkbelasting voor gegevensopslag en -verwerking (onder Andere hulpprogramma's).
Voor Visual Studio 2015:
Download Data Lake Tools. Kies de versie van Data Lake Tools die overeenkomt met uw versie van Visual Studio.
Data Lake Tools voor Visual Studio bijwerken
Zorg er vervolgens voor dat u Data Lake Tools bijwerkt naar de meest recente versie.
Open Visual Studio.
Selecteer Doorgaan zonder code in het startvenster.
Kies extensies beheren in> de menubalk van Visual Studio IDE.
Vouw in het dialoogvenster Extensies beheren het knooppunt Updates uit.
Als de lijst met beschikbare updates Azure Data Lake en Stream Analytics Tools bevat, selecteert u deze. Selecteer vervolgens de knop Bijwerken . Nadat het dialoogvenster Downloaden en installeren wordt weergegeven en verdwijnt, voegt Visual Studio de extensie Azure Data Lake en Stream Analytic Tools toe aan het updateschema.
Sluit alle Visual Studio-vensters. Het dialoogvenster VSIX Installer wordt weergegeven.
Selecteer Licentie om de licentievoorwaarden te lezen en selecteer Sluiten om terug te keren naar het dialoogvenster VSIX Installer .
Selecteer Wijzigen. De installatie van de extensie-update begint. Na een tijdje verandert het dialoogvenster om aan te geven dat het klaar is met het aanbrengen van wijzigingen. Selecteer Sluiten en start Visual Studio opnieuw om de installatie te voltooien.
Notitie
U kunt alleen Data Lake Tools versie 2.3.0.0 of hoger gebruiken om verbinding te maken met Interactive Query-clusters en interactieve Hive-query's uit te voeren.
Verbinding maken met Azure-abonnementen
U kunt Data Lake Tools voor Visual Studio gebruiken om verbinding te maken met uw HDInsight-clusters, enkele eenvoudige beheerbewerkingen uit te voeren en Hive-query's uit te voeren.
Notitie
Zie Hive-query's schrijven en verzenden met Behulp van Visual Studio voor meer informatie over het maken van verbinding met een algemeen Hadoop-cluster.
Verbinding maken met een Azure-abonnement
Verbinding maken met uw Azure-abonnement:
Open Visual Studio.
Selecteer Doorgaan zonder code in het startvenster.
Kies In de IDE-menubalk de optie Serververkenner weergeven>.
Klik in Server Explorer met de rechtermuisknop op Azure, selecteer Verbinding maken met Microsoft Azure-abonnement en voltooi het verificatieproces. Vouw vanuit Server Explorer Azure>HDInsight uit om een lijst met bestaande HDInsight-clusters weer te geven.
Als u geen clusters hebt, maakt u er een met behulp van Azure Portal, Azure PowerShell of de HDInsight SDK. Zie Clusters instellen in HDInsight voor meer informatie.
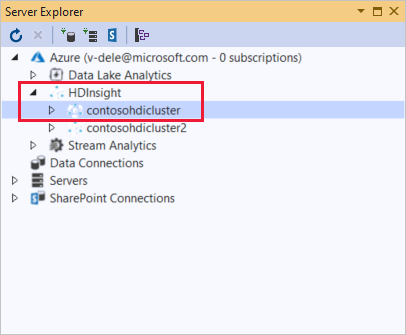
Een HDInsight-cluster uitbreiden. Het cluster bevat knooppunten voor Hive-databases. Ook een standaardopslagaccount, eventuele extra gekoppelde opslagaccounts en Hadoop-servicelogboek. U kunt de entiteiten verder uitbreiden.
Nadat u verbinding hebt gemaakt met het Azure-abonnement, kunt u de volgende taken uitvoeren.
Verbinding maken met Azure vanuit Visual Studio
Verbinding maken met Azure Portal vanuit Visual Studio:
Vouw in Server Explorer Azure>HDInsight uit en selecteer uw cluster.
Klik met de rechtermuisknop op een HDInsight-cluster en selecteer Cluster beheren in Azure Portal.
Vragen en feedback van Visual Studio aanbieden
Vragen stellen en of feedback geven van Visual Studio:
Kies Azure>HDInsight in Server Explorer.
Klik met de rechtermuisknop op HDInsight en selecteer MSDN-forum om vragen te stellen of feedback geven om feedback te geven.
Een cluster koppelen of bewerken
Notitie
Momenteel is het enige type HDInsight-cluster waarnaar u een koppeling kunt maken een Hive-type.
Een HDInsight-cluster koppelen:
Klik met de rechtermuisknop op HDInsight en selecteer vervolgens Een HDInsight-cluster koppelen om het dialoogvenster Een HDInsight-cluster koppelen weer te geven.
Voer een verbindings-URL in het formulier
https://CLUSTERNAME.azurehdinsight.netin. De clusternaam vult automatisch het clusternaamgedeelte van uw URL in wanneer u naar een ander veld gaat. Voer vervolgens een gebruikersnaam en wachtwoord in en selecteer Volgende.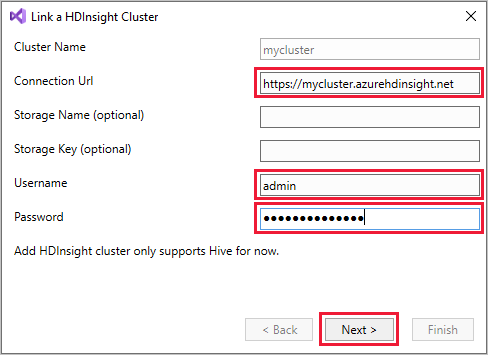
Selecteer Voltooien. Als het koppelen van het cluster is geslaagd, wordt het cluster weergegeven onder het HDInsight-knooppunt .
Als u een gekoppeld cluster wilt bijwerken, klikt u met de rechtermuisknop op het cluster en selecteert u Bewerken. Vervolgens kunt u de clustergegevens bijwerken.
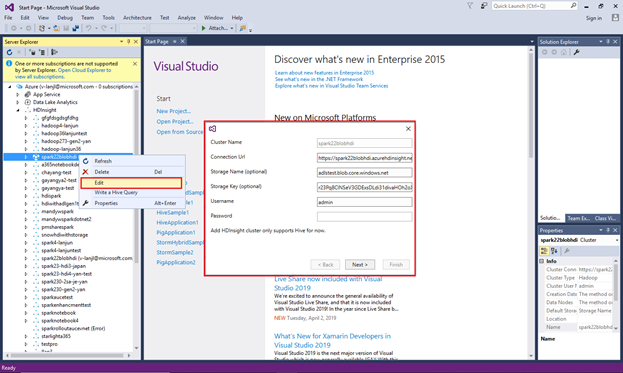
Gekoppelde resources verkennen
In Server Explorer worden het standaardaccount voor opslag en alle gekoppelde opslagaccounts weergegeven. Als u het standaardopslagaccount uitvouwt, kunt u de containers op het opslagaccount zien. Het standaardopslagaccount en de standaardcontainer worden gemarkeerd.
Klik met de rechtermuisknop op een container en selecteer Container weergeven om de inhoud van de container weer te geven. Nadat u een container hebt geopend, kunt u met de werkbalkknoppen de lijst met inhoud vernieuwen, Blob uploaden, geselecteerde blobs verwijderen, Blob openen en geselecteerde blobs downloaden (Opslaan als).
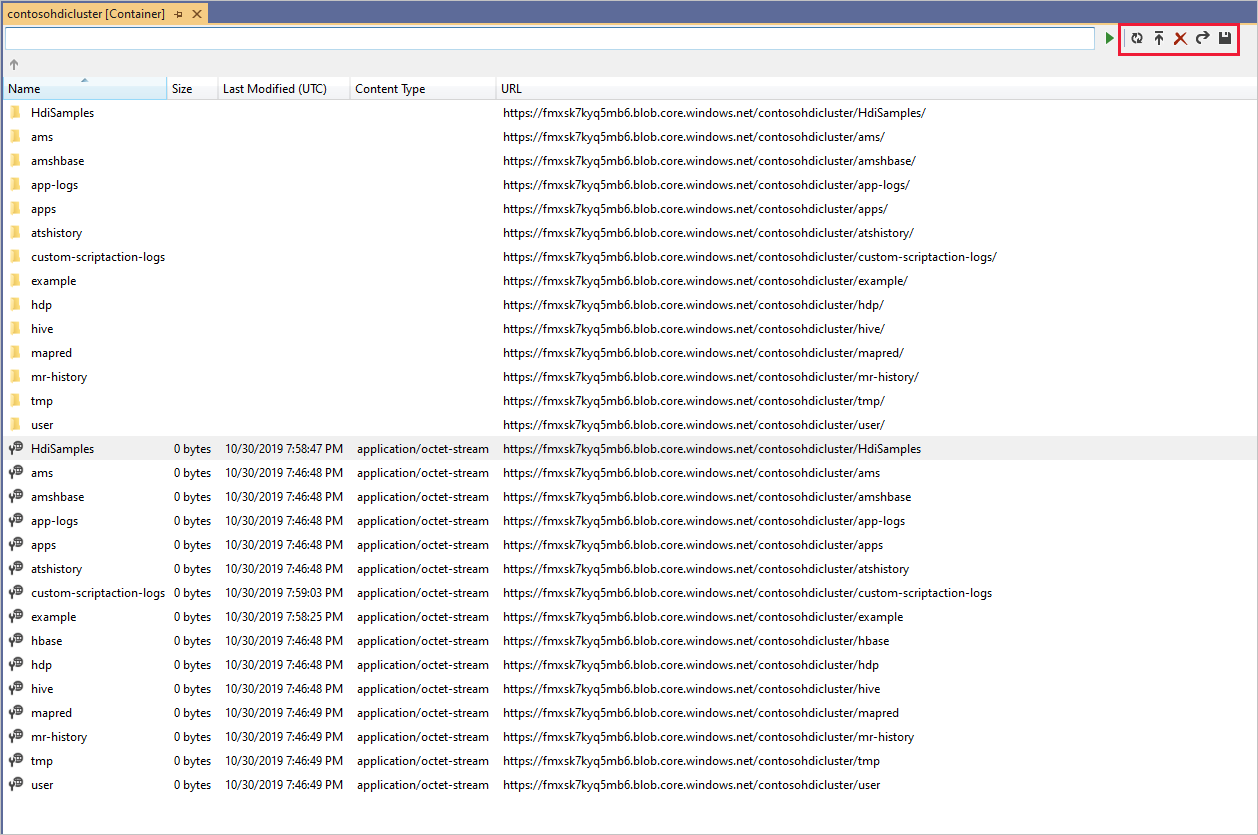
Interactieve Apache Hive-query's uitvoeren
Apache Hive is een datawarehouse-infrastructuur die is gebouwd op Hadoop. Hive wordt gebruikt voor gegevenssamenvatting, query's en analyse. U kunt Data Lake Tools voor Visual Studio gebruiken om Hive-query's uit te voeren vanuit Visual Studio. Zie Wat is Apache Hive en HiveQL in Azure HDInsight voor meer informatie over Hive.
Interactive Query in Azure HDInsight maakt gebruik van Hive in LLAP in Apache Hive 2.1. Interactive Query brengt interactiviteit naar complexe query's in datawarehousestijl op grote, opgeslagen gegevenssets. Het uitvoeren van Hive-query's op Interactive Query is veel sneller dan traditionele Hive-batchtaken.
Notitie
U kunt alleen interactieve Hive-query's uitvoeren wanneer u verbinding maakt met een HDInsight Interactive Query-cluster.
U kunt Data Lake Tools voor Visual Studio ook gebruiken om te zien wat er in een Hive-taak zit. Data Lake Tools voor Visual Studio verzamelt de Yarn-logboeken van bepaalde Hive-taken en maakt ze zichtbaar.
Kies Azure>HDInsight in Server Explorer en selecteer uw cluster. Dit knooppunt is het startpunt in Server Explorer om de volgende secties te volgen.
hivesampletable bekijken
Alle HDInsight-clusters hebben een standaard hive-voorbeeldtabel met de naam hivesampletable.
Kies in uw cluster de standaard>hivesampletable voor Hive-databases.>
Het schema weergeven
hivesampletable:Vouw hivesampletable uit. De namen en gegevenstypen van de
hivesampletablekolommen worden weergegeven.De
hivesampletablegegevens weergeven:Klik met de rechtermuisknop op Hivesampletable en selecteer Top 100 rijen weergeven. De lijst met 100 resultaten wordt weergegeven in de Hive-tabel: hivesampletable venster. Deze actie is gelijk aan het uitvoeren van de volgende Hive-query met behulp van het Hive ODBC-stuurprogramma:
SELECT * FROM hivesampletable LIMIT 100U kunt het aantal rijen aanpassen door het aantal rijen te wijzigen. U kunt in de vervolgkeuzelijst 50, 100, 200 of 1000 rijen kiezen.
Hive-tabellen maken
U een Hive-tabel maken door de GUI te gebruiken of door Hive-query's te gebruiken. Zie Hive-query's maken en uitvoeren voor informatie over het gebruik van Hive-query's.
Kies in uw cluster de standaardwaarde voor Hive-databases>.
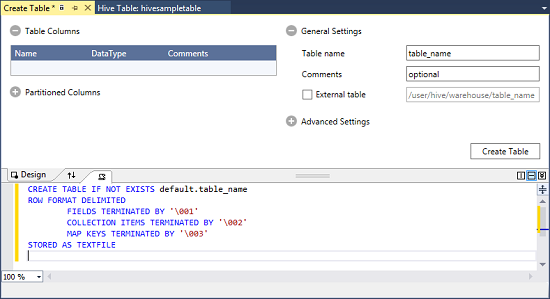
Klik met de rechtermuisknop op standaard en selecteer Tabel maken.
Configureer de tabel.
Selecteer de knop Tabel maken om de taak te verzenden, waarmee de nieuwe Hive-tabel wordt gemaakt.
Hive-query's maken en uitvoeren
U hebt twee opties voor het maken en uitvoeren van Hive-query's:
- Ad-hocquery's maken
- Een Hive-toepassing maken
Een ad-hocquery maken
Een ad-hocquery maken en uitvoeren:
Klik met de rechtermuisknop op het cluster waarop u de query wilt uitvoeren en selecteer Een Hive-query schrijven.
Voer een Hive-query in.
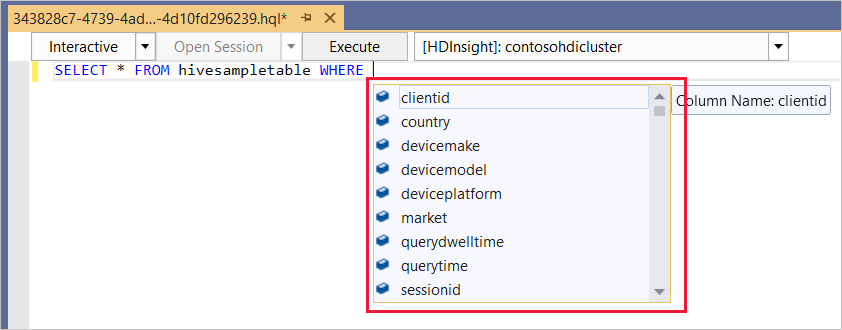
De Hive-editor ondersteunt IntelliSense. Data Lake Tools voor Visual Studio biedt ondersteuning voor het laden van externe metagegevens wanneer u het Hive-script bewerkt. Als u bijvoorbeeld typt
SELECT * FROM, worden intelliSense alle voorgestelde tabelnamen weergegeven. Wanneer een tabelnaam wordt opgegeven, geeft IntelliSense de kolomnamen weer. De hulpprogramma's ondersteunen de meeste DML-instructies, subquery's en ingebouwde UDF's van Hive.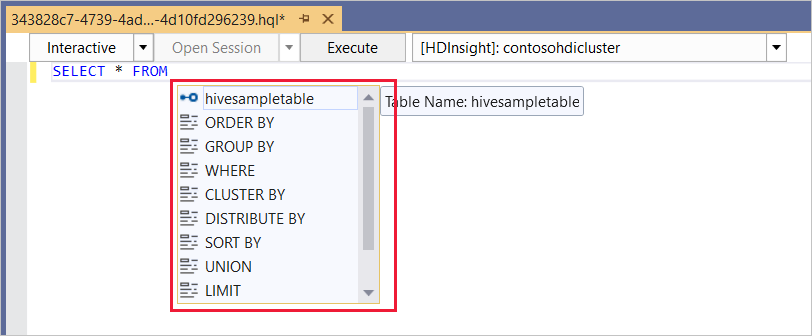
Notitie
IntelliSense suggereert alleen de metagegevens van het cluster dat in de HDInsight-werkbalk is geselecteerd.
Hier volgt een voorbeeldquery die u kunt gebruiken:
SELECT devicemodel, COUNT(devicemodel) AS deviceCount FROM hivesampletable GROUP BY devicemodel ORDER BY devicemodelKies de uitvoeringsmodus:
Interactief
Kies Interactive in de eerste vervolgkeuzelijst en selecteer vervolgens Uitvoeren.

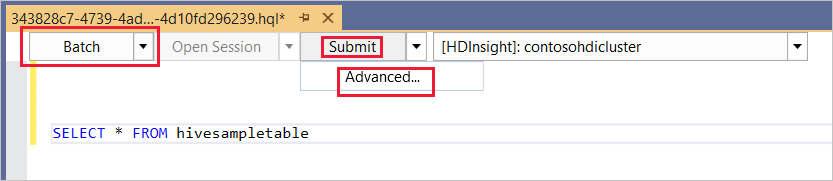
Batch
Kies Batch in de eerste vervolgkeuzelijst en selecteer vervolgens Verzenden. Of selecteer het vervolgkeuzepictogram naast Verzenden en kies Geavanceerd.
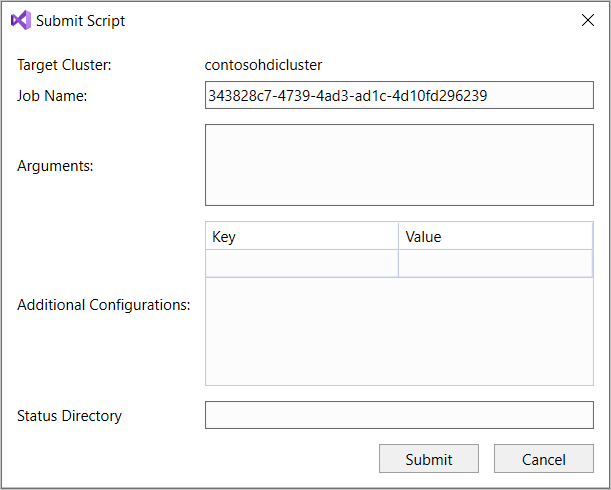
Als u de optie Geavanceerd verzenden selecteert, wordt het dialoogvenster Script verzenden weergegeven. Configureer de taaknaam, argumenten, aanvullende configuraties en statusmap voor het script.
Notitie
U kunt geen batches verzenden naar Interactive Query-clusters. U moet de interactieve modus gebruiken.
Een Hive-toepassing maken
Een Hive-oplossing maken en uitvoeren:
Kies bestand>nieuw>project in de menubalk.
Selecteer in het venster Een nieuw project maken het zoekvak en typ Hive. Kies vervolgens Hive-toepassing en selecteer Volgende.
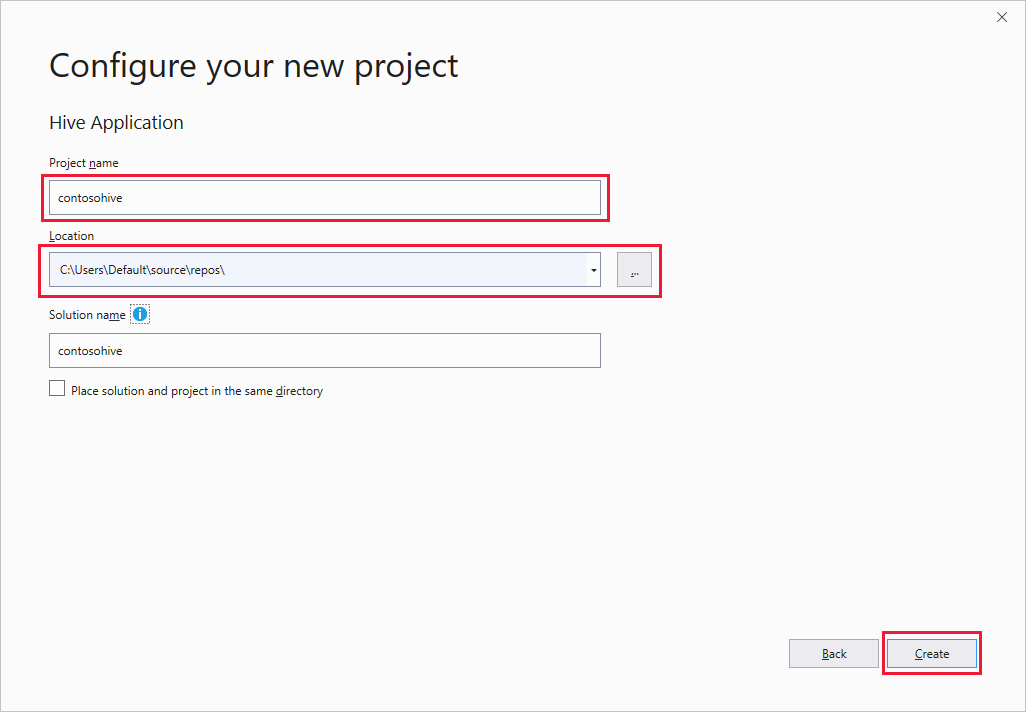
Voer in het venster Uw nieuwe project configureren een projectnaam in, selecteer of maak de projectlocatie en selecteer Vervolgens Maken.
Dubbelklik in Solution Explorer op Script.hql om het script te openen.
Taakoverzicht en uitvoer weergeven
De taaksamenvatting varieert enigszins tussen batch - en interactieve modus.
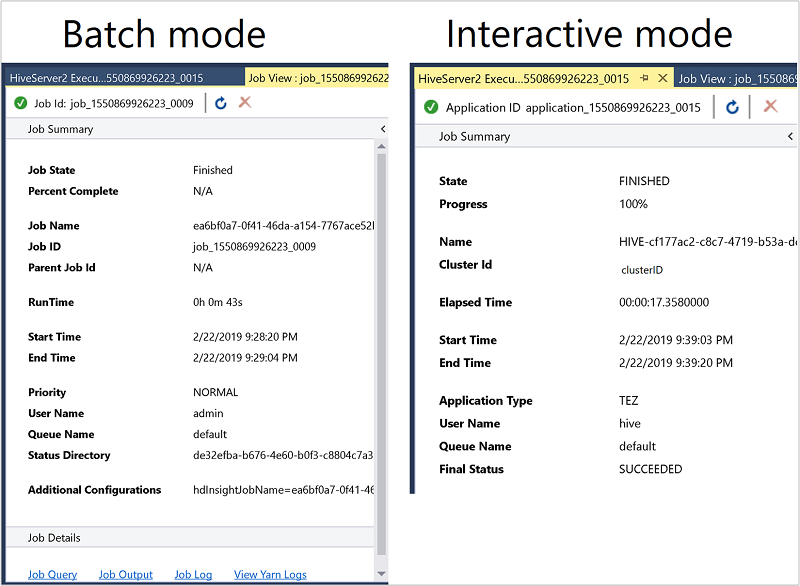
Gebruik het pictogram Vernieuwen om de status bij te werken totdat de taakstatus verandert in Voltooid.
Voor de taakdetails in de Batch-modus selecteert u de koppelingen onderaan om de taakquery, taakuitvoer of taaklogboek weer te geven of om Yarn-logboeken weer te geven.
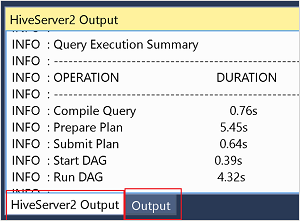
Zie de uitvoer- en HiveServer2-uitvoervensters voor de taak in de interactieve modus.
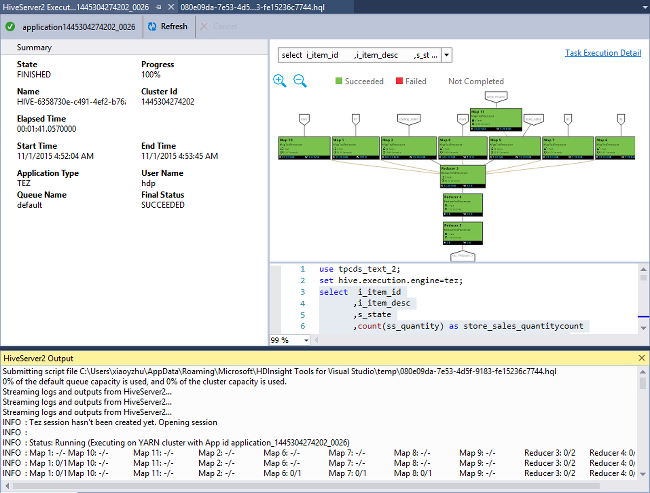
Taakgrafiek weergeven
Op dit moment worden taakgrafieken alleen weergegeven voor Hive-taken die Gebruikmaken van Tez als de uitvoeringsengine. Zie Wat is Apache Hive en HiveQL in Azure HDInsight voor meer informatie over het inschakelen van Tez. Zie ook Apache Tez gebruiken in plaats van Map Reduce.
Als u alle operators in het hoekpunt wilt weergeven, dubbelklikt u op de hoekpunten van de taakgrafiek. U kunt ook een bepaalde operator aanwijzen voor meer informatie over de operator.
Zelfs als Tez is opgegeven als de uitvoeringsengine, wordt de taakgrafiek mogelijk niet weergegeven als er geen Tez-toepassing wordt gestart. Deze situatie kan optreden omdat de taak geen DML-instructies bevat. Of omdat de DML-instructies kunnen worden geretourneerd zonder een Tez-toepassing te starten. Start bijvoorbeeld SELECT * FROM table1 de Tez-toepassing niet.
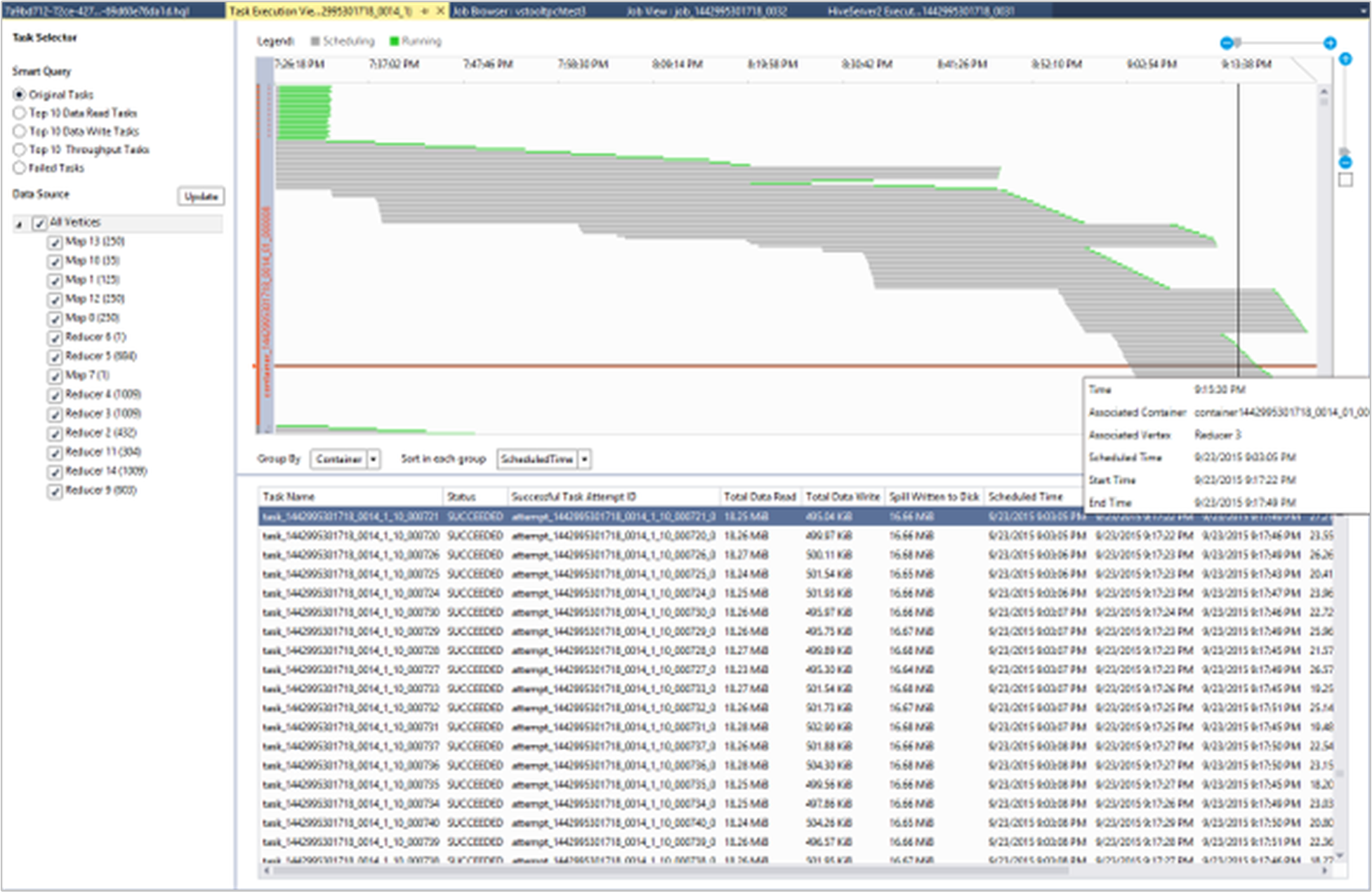
Details van taakuitvoering weergeven
In de taakgrafiek kunt u Details van taakuitvoering selecteren om gestructureerde en gevisualiseerde informatie voor Hive-taken op te halen. Mogelijk krijgt u ook meer informatie over taken. Als er prestatieproblemen optreden, kunt u de weergave gebruiken om meer informatie over het probleem op te vragen. U kunt bijvoorbeeld informatie ophalen over hoe elke taak werkt en gedetailleerde informatie over elke taak (gegevens lezen/schrijven, planning/begin-/eindtijd en meer). Gebruik de informatie om taakconfiguraties of systeemarchitectuur bij te stellen op basis van de gevisualiseerde informatie.
Hive-taken weergeven
U kunt taakquery's, taakuitvoer, logboeken van taken en Yarn-logboeken voor Hive-taken weergeven.
In de meest recente release van de hulpprogramma's kunt u zien wat er in uw Hive-taken zit door yarn-logboeken te verzamelen en weer te geven. Een Yarn-logboek kan u helpen bij het onderzoeken van prestatieproblemen. Zie Toegang tot Apache Hadoop YARN-toepassingslogboeken voor meer informatie over hoe HDInsight Yarn-logboeken verzamelt.
Hive-taken weergeven:
Klik met de rechtermuisknop op een HDInsight-cluster en selecteer Taken weergeven.
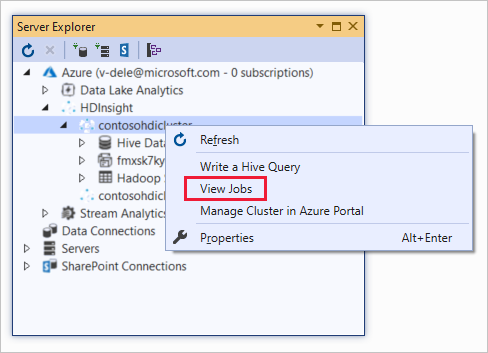
Er wordt een lijst weergegeven met de Hive-taken die op het cluster zijn uitgevoerd.
Selecteer een taak. Selecteer in het venster Samenvatting van Hive-taak een van de volgende koppelingen:
- Taakquery
- Taakuitvoer
- Takenlogboek
- Yarn-logboek
Apache Pig-scripts uitvoeren
Kies bestand>nieuw>project in de menubalk.
Selecteer in het startvenster het zoekvak en voer Pig in. Selecteer vervolgens Pig Application en selecteer Volgende.
Voer in het venster Uw nieuwe project configureren een projectnaam in en selecteer of maak een locatie voor het project. Selecteer vervolgens Maken.
Dubbelklik in het deelvenster IDE Solution Explorer op Script.pig om het script te openen.
Feedback en bekende problemen
Een probleem waardoor resultaten beginnend met null-waarden niet worden weergegeven, is opgelost. Neem contact op met het ondersteuningsteam als u vastloopt op dit probleem.
Het HQL-script dat door Visual Studio wordt gemaakt, wordt gecodeerd, afhankelijk van de lokale regio-instelling van de gebruiker. Het script wordt niet correct uitgevoerd als u het script als binair bestand naar een cluster uploadt.
Volgende stappen
In dit artikel hebt u hoe geleerd u het Data Lake Tools-pakket voor Visual Studio kunt gebruiken om verbinding te maken met HDInsight-clusters vanuit Visual Studio. U hebt ook geleerd hoe u een Hive-query uitvoert.