Het onderdeel Gegevens importeren
In dit artikel wordt een onderdeel in Azure Machine Learning Designer beschreven.
Gebruik dit onderdeel om gegevens te laden in een machine learning-pijplijn van bestaande cloudgegevensservices.
Notitie
Alle functionaliteit van dit onderdeel kan worden uitgevoerd door gegevensopslag en gegevenssets op de landingspagina van de werkruimte. U wordt aangeraden gegevensarchief en gegevensset te gebruiken die aanvullende functies bevatten, zoals gegevensbewaking. Zie het artikel Gegevenssets registreren voor meer informatie. Nadat u een gegevensset hebt geregistreerd, kunt u deze vinden in de categorie Gegevenssets -> Mijn gegevenssets in de ontwerpinterface. Dit onderdeel is gereserveerd voor Gebruikers van Studio (klassiek) voor een vertrouwde ervaring.
Het onderdeel Gegevens importeren biedt ondersteuning voor het lezen van gegevens uit de volgende bronnen:
- URL via HTTP
- Azure-cloudopslag via gegevensarchieven)
- Azure Blob Container
- Azure-bestandsshare
- Azure Data Lake
- Azure Data Lake Gen2
- Azure SQL-database
- Azure PostgreSQL
Voordat u cloudopslag gebruikt, moet u eerst een gegevensarchief registreren in uw Azure Machine Learning-werkruimte. Zie Gegevens openen voor meer informatie.
Nadat u de gewenste gegevens hebt gedefinieerd en verbinding hebt gemaakt met de bron, wordt het gegevenstype van elke kolom afgeleid op basis van de waarden die deze bevat en laadt u de gegevens in de ontwerppijplijn. De uitvoer van Import Data is een gegevensset die kan worden gebruikt met elke ontwerppijplijn.
Als uw brongegevens worden gewijzigd, kunt u de gegevensset vernieuwen en nieuwe gegevens toevoegen door importgegevens opnieuw uit te voeren.
Waarschuwing
Als uw werkruimte zich in een virtueel netwerk bevindt, moet u uw gegevensarchieven configureren voor het gebruik van de functies voor gegevensvisualisatie van de ontwerper. Zie Azure Machine Learning-studio gebruiken in een virtueel Azure-netwerk voor meer informatie over het gebruik van gegevensarchieven en gegevenssets in een virtueel Azure-netwerk.
Importgegevens configureren
Voeg het onderdeel Gegevens importeren toe aan uw pijplijn. U vindt dit onderdeel in de categorie Gegevensinvoer en -uitvoer in de ontwerpfunctie.
Selecteer het onderdeel om het rechterdeelvenster te openen.
Selecteer Gegevensbron en kies het gegevensbrontype. Dit kan HTTP of gegevensarchief zijn.
Als u gegevensarchief kiest, kunt u bestaande gegevensarchieven selecteren die al zijn geregistreerd bij uw Azure Machine Learning-werkruimte of een nieuw gegevensarchief maken. Definieer vervolgens het pad van de gegevens die moeten worden geïmporteerd in het gegevensarchief. U kunt eenvoudig door het pad bladeren door Bladeren te selecteren.
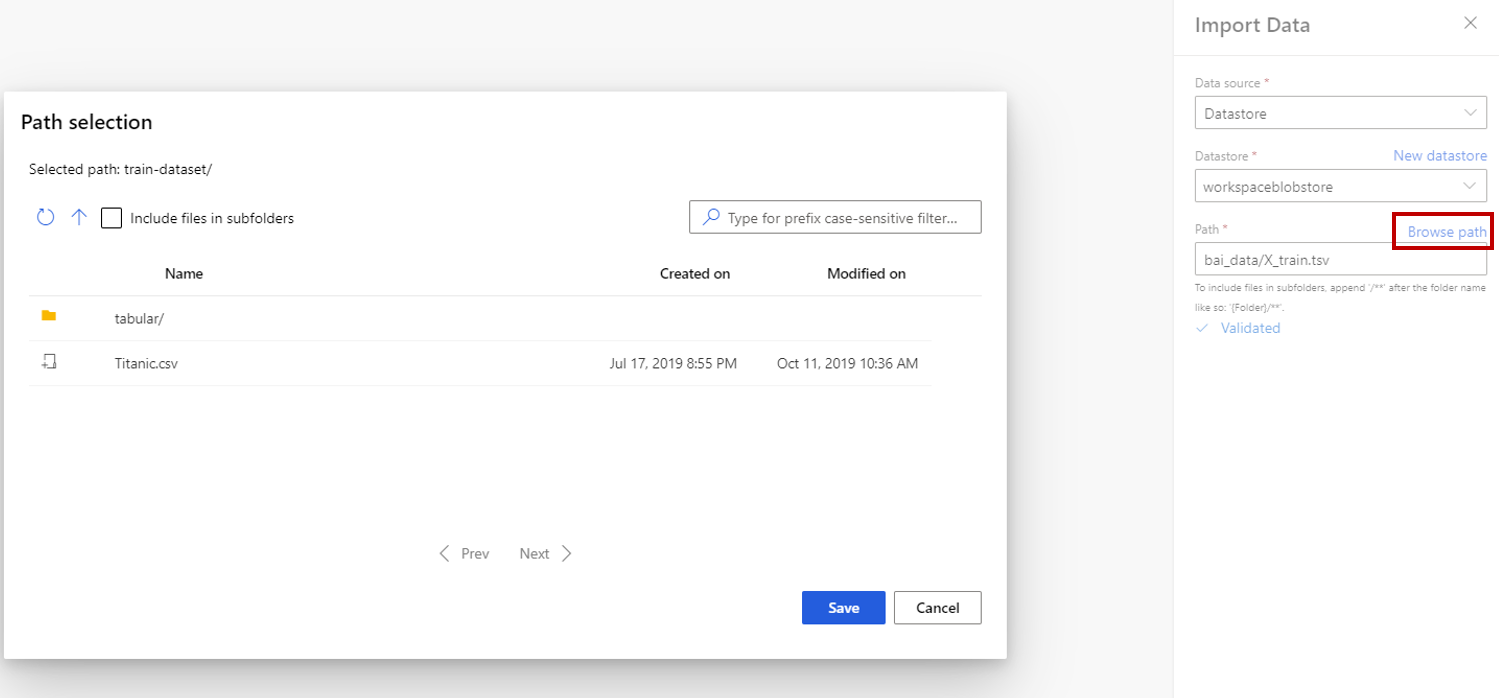
Notitie
Het onderdeel Gegevens importeren is alleen bedoeld voor tabelgegevens . Als u meerdere gegevensbestanden in tabelvorm één keer wilt importeren, zijn de volgende voorwaarden vereist. Anders treden er fouten op:
- Als u alle gegevensbestanden in de map wilt opnemen, moet u invoeren
folder_name/**voor Path. - Alle gegevensbestanden moeten worden gecodeerd in Unicode-8.
- Alle gegevensbestanden moeten dezelfde kolomnummers en kolomnamen hebben.
- Het resultaat van het importeren van meerdere gegevensbestanden is het samenvoegen van alle rijen uit meerdere bestanden in volgorde.
- Als u alle gegevensbestanden in de map wilt opnemen, moet u invoeren
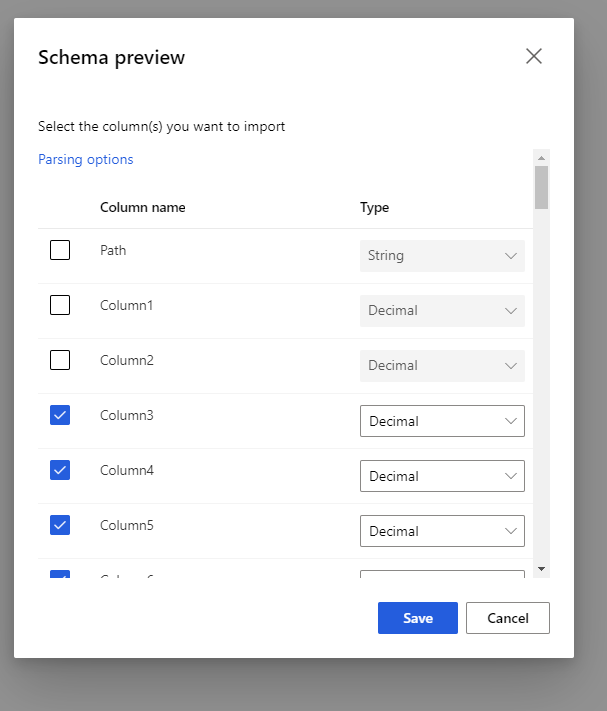
Selecteer het voorbeeldschema om de kolommen te filteren die u wilt opnemen. U kunt ook geavanceerde instellingen, zoals scheidingsteken, definiëren in opties voor parseren.
Het selectievakje, Uitvoer opnieuw genereren, bepaalt of het onderdeel moet worden uitgevoerd om uitvoer tijdens uitvoering opnieuw te genereren.
Dit is standaard niet geselecteerd, wat betekent dat als het onderdeel eerder is uitgevoerd met dezelfde parameters, het systeem de uitvoer van de laatste uitvoering opnieuw gebruikt om de uitvoeringstijd te verminderen.
Als dit is geselecteerd, voert het systeem het onderdeel opnieuw uit om uitvoer opnieuw te genereren. Selecteer deze optie dus wanneer onderliggende gegevens in de opslag worden bijgewerkt, kan het helpen om de meest recente gegevens op te halen.
Verzend de pijplijn.
Wanneer Gegevens importeren de gegevens in de ontwerpfunctie laadt, wordt het gegevenstype van elke kolom afgeleid op basis van de waarden die deze bevat, numeriek of categorisch.
Als er een koptekst aanwezig is, wordt de koptekst gebruikt om de kolommen van de uitvoergegevensset een naam te geven.
Als er geen bestaande kolomkoppen in de gegevens staan, worden nieuwe kolomnamen gegenereerd met de indeling col1, col2,... , coln*.

Resultaten
Wanneer het importeren is voltooid, klikt u met de rechtermuisknop op de uitvoergegevensset en selecteert u Visualiseren om te zien of de gegevens zijn geïmporteerd.
Als u de gegevens voor hergebruik wilt opslaan in plaats van telkens wanneer de pijplijn wordt uitgevoerd een nieuwe set gegevens te importeren, selecteert u het pictogram Gegevensset registreren onder het tabblad Uitvoer+logboeken in het rechterdeelvenster van het onderdeel. Kies een naam voor de gegevensset. De opgeslagen gegevensset behoudt de gegevens op het moment van opslaan. De gegevensset wordt niet bijgewerkt wanneer de pijplijn opnieuw wordt uitgevoerd, zelfs niet als de gegevensset in de pijplijn verandert. Dit kan handig zijn voor het maken van momentopnamen van gegevens.
Nadat u de gegevens hebt geïmporteerd, hebt u mogelijk aanvullende voorbereidingen nodig voor modellering en analyse:
Gebruik Metagegevens bewerken om kolomnamen te wijzigen, een kolom als een ander gegevenstype te verwerken of aan te geven dat sommige kolommen labels of functies zijn.
Gebruik Select Columns in Dataset om een subset van kolommen te selecteren om modellering te transformeren of te gebruiken. De getransformeerde of verwijderde kolommen kunnen eenvoudig opnieuw worden toegevoegd aan de oorspronkelijke gegevensset met behulp van het onderdeel Kolommen toevoegen.
Gebruik Partition and Sample om de gegevensset te verdelen, steekproeven uit te voeren of de bovenste n rijen op te halen.
Beperkingen
Als uw deductiepijplijn importgegevensonderdeel bevat, wordt deze vanwege de toegangsbeperking voor gegevensopslag automatisch verwijderd wanneer deze wordt geïmplementeerd op een realtime-eindpunt.
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.