VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
In dit artikel leert u hoe u uw model implementeert op een online-eindpunt voor gebruik in realtime deductie. U begint met het implementeren van een model op uw lokale computer om fouten op te sporen. Vervolgens implementeert en test u het model in Azure, bekijkt u de implementatielogboeken en bewaakt u de SLA (Service Level Agreement). Aan het einde van dit artikel hebt u een schaalbaar HTTPS/REST-eindpunt dat u kunt gebruiken voor realtime deductie.
Online-eindpunten zijn eindpunten die worden gebruikt voor realtime deductie. Er zijn twee typen online-eindpunten: beheerde online-eindpunten en Kubernetes-online-eindpunten. Zie Beheerde online-eindpunten versus Kubernetes online-eindpunten voor meer informatie over de verschillen.
Met beheerde online-eindpunten kunt u uw Machine Learning modellen op een kant-en-klare manier implementeren. Beheerde online-eindpunten werken met krachtige CPU- en GPU-machines in Azure op een schaalbare, volledig beheerde manier. Beheerde online-eindpunten zorgen voor het leveren, schalen, beveiligen en bewaken van uw modellen. Deze hulp maakt u vrij van de overhead van het instellen en beheren van de onderliggende infrastructuur.
In het hoofdvoorbeeld in dit artikel worden beheerde online-eindpunten gebruikt voor implementatie. Als u In plaats daarvan Kubernetes wilt gebruiken, raadpleegt u de notities in dit document die inline zijn met de discussie over beheerde online-eindpunten.
Vereisten
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
De Azure CLI en de ml extensie voor de Azure CLI, geïnstalleerd en geconfigureerd. Zie De CLI (v2) installeren en instellen voor meer informatie.
Een Bash-shell of een compatibele shell, bijvoorbeeld een shell op een Linux-systeem of Windows-subsysteem voor Linux. In de Azure CLI-voorbeelden in dit artikel wordt ervan uitgegaan dat u dit type shell gebruikt.
Een Azure Machine Learning-werkruimte. Zie Instellen voor instructies voor het maken van een werkruimte.
Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) wordt gebruikt om toegang te verlenen tot bewerkingen in Azure Machine Learning. Als u de stappen in dit artikel wilt uitvoeren, moet aan uw gebruikersaccount de rol Eigenaar of Inzender zijn toegewezen voor de Azure Machine Learning-werkruimte, of moet een aangepaste rol zijn toegestaan Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Als u Azure Machine Learning Studio gebruikt om online-eindpunten of implementaties te maken en te beheren, hebt u de extra machtiging Microsoft.Resources/deployments/write van de eigenaar van de resourcegroep nodig. Zie Toegang tot Azure Machine Learning-werkruimten beheren voor meer informatie.
(Optioneel) Als u lokaal wilt implementeren, moet u Docker Engine installeren op uw lokale computer. We raden deze optie ten zeerste aan , waardoor u gemakkelijker problemen kunt opsporen.
VAN TOEPASSING OP: Python SDK azure-ai-ml v2 (actueel)
Een Azure Machine Learning-werkruimte. Zie De werkruimte maken voor stappen voor het maken van een werkruimte.
De Azure Machine Learning SDK voor Python v2. Gebruik de volgende opdracht om de SDK te installeren:
pip install azure-ai-ml azure-identity
Gebruik de volgende opdracht om een bestaande installatie van de SDK bij te werken naar de nieuwste versie:
pip install --upgrade azure-ai-ml azure-identity
Zie de Clientbibliotheek van Het Azure Machine Learning-pakket voor Python voor meer informatie.
Azure RBAC wordt gebruikt om toegang te verlenen tot bewerkingen in Azure Machine Learning. Als u de stappen in dit artikel wilt uitvoeren, moet aan uw gebruikersaccount de rol Eigenaar of Inzender zijn toegewezen voor de Azure Machine Learning-werkruimte, of moet een aangepaste rol zijn toegestaan Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Zie Toegang tot Azure Machine Learning-werkruimten beheren voor meer informatie.
(Optioneel) Als u lokaal wilt implementeren, moet u Docker Engine installeren op uw lokale computer. We raden deze optie ten zeerste aan , waardoor u gemakkelijker problemen kunt opsporen.
Voordat u de stappen in dit artikel volgt, moet u ervoor zorgen dat u over de volgende vereisten beschikt:
De Azure CLI en de CLI-extensie voor machine learning worden in deze stappen gebruikt, maar ze zijn niet de belangrijkste focus. Ze worden meer gebruikt als hulpprogramma's om sjablonen door te geven aan Azure en de status van sjabloonimplementaties te controleren.
De Azure CLI en de ml extensie voor de Azure CLI, geïnstalleerd en geconfigureerd. Zie De CLI (v2) installeren en instellen voor meer informatie.
Een Bash-shell of een compatibele shell, bijvoorbeeld een shell op een Linux-systeem of Windows-subsysteem voor Linux. In de Azure CLI-voorbeelden in dit artikel wordt ervan uitgegaan dat u dit type shell gebruikt.
Een Azure Machine Learning-werkruimte. Zie Instellen voor instructies voor het maken van een werkruimte.
- Azure RBAC wordt gebruikt om toegang te verlenen tot bewerkingen in Azure Machine Learning. Als u de stappen in dit artikel wilt uitvoeren, moet aan uw gebruikersaccount de rol Eigenaar of Inzender zijn toegewezen voor de Azure Machine Learning-werkruimte, of moet een aangepaste rol zijn toegestaan
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Zie Toegang tot een Azure Machine Learning-werkruimte beheren voor meer informatie.
Zorg ervoor dat er voldoende VM-quotum (virtuele machine) is toegewezen voor implementatie. Azure Machine Learning reserveert 20% van uw rekenresources voor het uitvoeren van upgrades op sommige VM-versies. Als u bijvoorbeeld 10 exemplaren in een implementatie aanvraagt, moet u een quotum van 12 hebben voor elk aantal kernen voor de VM-versie. Als er geen rekening wordt gehouden met de extra rekenresources, treedt er een fout op. Sommige VM-versies zijn uitgesloten van de extra quotumreservering. Zie quotatoewijzing voor virtuele machines voor implementatie voor meer informatie over quotumtoewijzing.
U kunt ook een quotum van de gedeelde quotumgroep van Azure Machine Learning gedurende een beperkte tijd gebruiken. Azure Machine Learning biedt een gedeelde quotumgroep van waaruit gebruikers in verschillende regio's toegang hebben tot het quotum voor het uitvoeren van tests gedurende een beperkte tijd, afhankelijk van de beschikbaarheid.
Wanneer u de studio gebruikt voor het implementeren van Llama-2, Phi, Nemotron, Mistral, Dolly en Deci-DeciLM-modellen uit de modelcatalogus naar een beheerd online-eindpunt, kunt u met Azure Machine Learning gedurende korte tijd toegang krijgen tot de gedeelde quotumpool, zodat u tests kunt uitvoeren. Zie het gedeelde quotum van Azure Machine Learning voor meer informatie over de gedeelde quotumgroep.
Uw systeem voorbereiden
Omgevingsvariabelen instellen
Als u de standaardinstellingen voor de Azure CLI nog niet hebt ingesteld, slaat u de standaardinstellingen op. Voer deze code uit om te voorkomen dat de waarden voor uw abonnement, werkruimte en resourcegroep meerdere keren worden doorgegeven:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
De opslagplaats met voorbeelden klonen
Als u dit artikel wilt volgen, kloont u eerst de opslagplaats azureml-examples en gaat u vervolgens over naar de azureml-examples/cli-map van de opslagplaats:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli
Gebruik --depth 1 om alleen de meest recente commit naar de repository te klonen, wat de tijd voor het voltooien van de operatie vermindert.
De opdrachten in deze handleiding bevinden zich in de bestanden deploy-local-endpoint.sh en deploy-managed-online-endpoint.sh in de cli-directory. De YAML-configuratiebestanden bevinden zich in de submap eindpunten/online/beheerd/sample/.
Notitie
De YAML-configuratiebestanden voor Online-eindpunten van Kubernetes bevinden zich in de submap eindpunten/online/kubernetes/ .
De opslagplaats met voorbeelden klonen
Als u de trainingsvoorbeelden wilt uitvoeren, kloont u eerst de opslagplaats azureml-examples en gaat u vervolgens over naar de azureml-examples/sdk/python/endpoints/online/managed directory:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
Gebruik --depth 1 om alleen de meest recente commit naar de opslagplaats te klonen, waardoor de tijd voor het voltooien van de bewerking wordt verkort.
De informatie in dit artikel is gebaseerd op het notebook online-endpoints-simple-deployment.ipynb . Het bevat dezelfde inhoud als dit artikel, hoewel de volgorde van de codes iets anders is.
Verbinding maken met Azure Machine Learning-werkruimte
De werkruimte is de resource op het hoogste niveau voor Azure Machine Learning. Het biedt een gecentraliseerde plek om te werken met alle artefacten die u maakt wanneer u Azure Machine Learning gebruikt. In deze sectie maakt u verbinding met de werkruimte waarin u implementatietaken uitvoert. Om mee te volgen, opent u uw notebook online-endpoints-simple-deployment.ipynb.
Importeer de vereiste bibliotheken:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration
)
from azure.identity import DefaultAzureCredential
Notitie
Als u het online-eindpunt van Kubernetes gebruikt, importeert u de KubernetesOnlineEndpoint en KubernetesOnlineDeployment klasse uit de azure.ai.ml.entities bibliotheek.
Configureer werkruimtegegevens en haal een ingang op voor de werkruimte.
Als u verbinding wilt maken met een werkruimte, hebt u deze id-parameters nodig: een abonnement, resourcegroep en werkruimtenaam. U gebruikt deze gegevens in MLClient van azure.ai.ml om toegang te krijgen tot de vereiste Azure Machine Learning-werkruimte. In dit voorbeeld wordt de standaard Azure-verificatie gebruikt.
# enter details of your Azure Machine Learning workspace
subscription_id = "<subscription ID>"
resource_group = "<resource group>"
workspace = "<workspace name>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
Als Git op uw lokale computer is geïnstalleerd, kunt u de instructies volgen om de opslagplaats met voorbeelden te klonen. Volg anders de instructies voor het downloaden van bestanden uit de opslagplaats met voorbeelden.
De opslagplaats met voorbeelden klonen
Als u dit artikel wilt volgen, kloont u eerst de azureml-examples repository en navigeert u vervolgens naar de azureml-examples/cli/endpoints/online/model-1 map.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
Gebruik --depth 1 om alleen de meest recente commit naar de opslagplaats te klonen, waardoor de tijd voor het voltooien van de bewerking wordt verkort.
Bestanden downloaden uit de voorbeeldenopslagplaats
Als u de opslagplaats met voorbeelden hebt gekloond, bevat uw lokale computer al kopieën van de bestanden voor dit voorbeeld en kunt u doorgaan naar de volgende sectie. Als u de opslagplaats niet hebt gekloond, download deze naar uw lokale apparaat.
- Ga naar de opslagplaats met voorbeelden (azureml-examples).
- Ga naar de <> knop Code op de pagina en selecteer Vervolgens op het tabblad Lokaal de optie ZIP downloaden.
- Zoek de map /cli/endpoints/online/model-1/model en het bestand /cli/endpoints/online/model-1/onlinescoring/score.py.
Omgevingsvariabelen instellen
Stel de volgende omgevingsvariabelen in, zodat u deze kunt gebruiken in de voorbeelden in dit artikel. Vervang de waarden door uw Azure-abonnements-id, de Azure-regio waar uw werkruimte zich bevindt, de resourcegroep die de werkruimte bevat en de naam van de werkruimte:
export SUBSCRIPTION_ID="<subscription ID>"
export LOCATION="<your region>"
export RESOURCE_GROUP="<resource group>"
export WORKSPACE="<workspace name>"
Voor een aantal sjabloonvoorbeelden moet u bestanden uploaden naar Azure Blob Storage voor uw werkruimte. Met de volgende stappen wordt een query uitgevoerd op de werkruimte en worden deze gegevens opgeslagen in omgevingsvariabelen die in de voorbeelden worden gebruikt:
Een toegangstoken ophalen:
TOKEN=$(az account get-access-token --query accessToken -o tsv)
Stel de REST API-versie in:
API_VERSION="2022-05-01"
Haal de opslaggegevens op:
# Get values for storage account
response=$(curl --location --request GET "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices/workspaces/$WORKSPACE/datastores?api-version=$API_VERSION&isDefault=true" \
--header "Authorization: Bearer $TOKEN")
AZUREML_DEFAULT_DATASTORE=$(echo $response | jq -r '.value[0].name')
AZUREML_DEFAULT_CONTAINER=$(echo $response | jq -r '.value[0].properties.containerName')
export AZURE_STORAGE_ACCOUNT=$(echo $response | jq -r '.value[0].properties.accountName')
De opslagplaats met voorbeelden klonen
Als u dit artikel wilt volgen, kloont u eerst de opslagplaats azureml-examples en gaat u vervolgens over naar de map azureml-examples :
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
Gebruik --depth 1 dit om alleen de meest recente doorvoering naar de opslagplaats te klonen, waardoor de tijd voor het voltooien van de bewerking wordt verkort.
Het eindpunt definiëren
Als u een online-eindpunt wilt definiëren, geeft u de eindpuntnaam en verificatiemodus op. Zie Online-eindpunten voor meer informatie over beheerde online-eindpunten.
Een eindpuntnaam instellen
Voer de volgende opdracht uit om de naam van uw eindpunt in te stellen. Vervang door <YOUR_ENDPOINT_NAME> een naam die uniek is in de Azure-regio. Zie Eindpuntlimieten voor meer informatie over de naamgevingsregels.
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
In het volgende fragment ziet u de eindpunten/online/managed/sample/endpoint.yml bestand:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
De verwijzing voor de YAML-indeling van het eindpunt wordt beschreven in de volgende tabel. Zie de YAML-referentie voor het online-eindpunt voor meer informatie over het opgeven van deze kenmerken. Zie Azure Machine Learning Online-eindpunten en batcheindpunten voor informatie over limieten met betrekking tot beheerde eindpunten.
| Toets |
Beschrijving |
$schema |
(Optioneel) Het YAML-schema. Als u alle beschikbare opties in het YAML-bestand wilt zien, kunt u het schema bekijken in het voorgaande codefragment in een browser. |
name |
De naam van het eindpunt. |
auth_mode |
Gebruiken key voor verificatie op basis van sleutels.
Gebruiken aml_token voor verificatie op basis van tokens op basis van Azure Machine Learning.
Gebruiken aad_token voor verificatie op basis van Microsoft Entra-tokens (preview).
Zie Clients verifiëren voor online-eindpunten voor meer informatie over verificatie. |
Definieer eerst de naam van het online-eindpunt en configureer vervolgens het eindpunt.
Vervang <YOUR_ENDPOINT_NAME> door een naam die uniek is in de Azure-regio of gebruik de voorbeeldmethode om een willekeurige naam te definiëren. Verwijder de methode die u niet gebruikt. Zie Eindpuntlimieten voor meer informatie over de naamgevingsregels.
# method 1: define an endpoint name
endpoint_name = "<YOUR_ENDPOINT_NAME>"
# method 2: example way to define a random name
import datetime
endpoint_name = "endpt-" + datetime.datetime.now().strftime("%m%d%H%M%f")
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name = endpoint_name,
description="this is a sample endpoint",
auth_mode="key"
)
De vorige code gebruikt key voor verificatie op basis van sleutels. Als u verificatie op basis van een Azure Machine Learning-token wilt gebruiken, gebruikt u aml_token. Als u verificatie op basis van Microsoft Entra-tokens (preview) wilt gebruiken, gebruikt u aad_token. Zie Clients verifiëren voor online-eindpunten voor meer informatie over verificatie.
Wanneer u vanuit de studio in Azure implementeert, maakt u een eindpunt en een implementatie die eraan moet worden toegevoegd. Op dat moment wordt u gevraagd om namen op te geven voor het eindpunt en de implementatie.
Een eindpuntnaam instellen
Als u de naam van uw eindpunt wilt instellen, voert u de volgende opdracht uit om een willekeurige naam te genereren. Deze moet uniek zijn in de Azure-regio. Zie Eindpuntlimieten voor meer informatie over de naamgevingsregels.
export ENDPOINT_NAME=endpoint-`echo $RANDOM`
Voor het definiëren van het eindpunt en de implementatie gebruikt dit artikel de ARM-sjablonen (Azure Resource Manager) -online-endpoint.json en online-endpoint-deployment.json. Als u de sjablonen wilt gebruiken voor het definiëren van een online-eindpunt en -implementatie, raadpleegt u de sectie Implementeren in Azure .
De implementatie definiëren
Een implementatie is een set resources die vereist is voor het hosten van het model dat de werkelijke deductie uitvoert. In dit voorbeeld implementeert u een scikit-learn model dat regressie uitvoert en een scorescript gebruikt score.py het model uit te voeren op een specifieke invoeraanvraag.
Zie Online-implementaties voor meer informatie over de belangrijkste kenmerken van een implementatie.
Uw implementatieconfiguratie maakt gebruik van de locatie van het model dat u wilt implementeren.
In het volgende fragment ziet u de eindpunten/online/managed/sample/blue-deployment.yml bestand, met alle vereiste invoer voor het configureren van een implementatie:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
In het bestand blue-deployment.yml worden de volgende implementatiekenmerken opgegeven:
-
model: Hiermee geeft u de modeleigenschappen inline op met behulp van de path parameter (waar bestanden moeten worden geüpload). De CLI uploadt automatisch de modelbestanden en registreert het model met een automatisch gegenereerde naam.
-
environment: maakt gebruik van inlinedefinities die de locaties omvatten vanwaar bestanden geüpload moeten worden. De CLI uploadt automatisch het conda.yaml-bestand en registreert de omgeving. Later gebruikt de implementatie de parameter image voor de basisimage om de omgeving op te bouwen. In dit voorbeeld is het mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. De conda_file afhankelijkheden worden op de basisafbeelding geïnstalleerd.
-
code_configuration: Uploadt de lokale bestanden, zoals de Python-bron voor het scoremodel, vanuit de ontwikkelomgeving tijdens de implementatie.
Zie de YAML-referentie voor het online-eindpunt voor meer informatie over het YAML-schema.
Notitie
Kubernetes-eindpunten gebruiken in plaats van beheerde online-eindpunten als rekendoel:
- Maak en koppel uw Kubernetes-cluster als rekendoel aan uw Azure Machine Learning-werkruimte met behulp van Azure Machine Learning-studio.
- Gebruik het eindpunt YAML om Kubernetes te richten op in plaats van de beheerde eindpunt YAML. U moet de YAML bewerken om de waarde te wijzigen in
compute de naam van uw geregistreerde rekendoel. U kunt deze deployment.yaml gebruiken met andere eigenschappen die van toepassing zijn op een Kubernetes-implementatie.
Alle opdrachten die in dit artikel worden gebruikt voor beheerde online-eindpunten zijn ook van toepassing op Kubernetes-eindpunten, met uitzondering van de volgende mogelijkheden die niet van toepassing zijn op Kubernetes-eindpunten:
Gebruik de volgende code om een implementatie te configureren:
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
-
Model: Hiermee geeft u de modeleigenschappen inline op met behulp van de path parameter (waar bestanden moeten worden geüpload). De SDK uploadt automatisch de modelbestanden en registreert het model met een automatisch gegenereerde naam.
-
Environment: maakt gebruik van inlinedefinities die aangeven waar vandaan bestanden geüpload moeten worden. De SDK uploadt automatisch het conda.yaml-bestand en registreert de omgeving. Later gebruikt de implementatie de image-parameter voor de basisafbeelding om de omgeving op te bouwen. In dit voorbeeld is het mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. De conda_file afhankelijkheden worden op de basisafbeelding geïnstalleerd.
-
CodeConfiguration: Uploadt de lokale bestanden, zoals de Python-bron voor het scoremodel, vanuit de ontwikkelomgeving tijdens de implementatie.
Zie OnlineDeployment Class voor meer informatie over de definitie van onlineimplementatie.
Wanneer u in Azure implementeert, maakt u een eindpunt en een implementatie om hieraan toe te voegen. Op dat moment wordt u gevraagd om namen op te geven voor het eindpunt en de implementatie.
Inzicht in het scorescript
De indeling van het scorescript voor online-eindpunten is dezelfde indeling die wordt gebruikt in de vorige versie van de CLI en in de Python SDK.
Het scorescript dat is opgegeven, code_configuration.scoring_script moet een init() functie en een run() functie hebben.
Het scorescript moet een init() functie en een run() functie hebben.
Het scorescript moet een init() functie en een run() functie hebben.
Het scorescript moet een init() functie en een run() functie hebben. In dit artikel wordt het score.py-bestand gebruikt.
Wanneer u een sjabloon voor implementatie gebruikt, moet u eerst het scorebestand uploaden naar Blob Storage en het vervolgens registreren:
De volgende code maakt gebruik van de Azure CLI-opdracht az storage blob upload-batch om het scorebestand te uploaden:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/score -s cli/endpoints/online/model-1/onlinescoring --account-name $AZURE_STORAGE_ACCOUNT
De volgende code maakt gebruik van een sjabloon om de code te registreren:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/code-version.json \
--parameters \
workspaceName=$WORKSPACE \
codeAssetName="score-sklearn" \
codeUri="https://$AZURE_STORAGE_ACCOUNT.blob.core.windows.net/$AZUREML_DEFAULT_CONTAINER/score"
In dit voorbeeld wordt het score.py-bestand uit de opslagplaats gebruikt die u eerder hebt gekloond of gedownload:
import os
import logging
import json
import numpy
import joblib
def init():
"""
This function is called when the container is initialized/started, typically after create/update of the deployment.
You can write the logic here to perform init operations like caching the model in memory
"""
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment.
# It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION)
# Please provide your model's folder name if there is one
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl"
)
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
logging.info("Init complete")
def run(raw_data):
"""
This function is called for every invocation of the endpoint to perform the actual scoring/prediction.
In the example we extract the data from the json input and call the scikit-learn model's predict()
method and return the result back
"""
logging.info("model 1: request received")
data = json.loads(raw_data)["data"]
data = numpy.array(data)
result = model.predict(data)
logging.info("Request processed")
return result.tolist()
De init() functie wordt aangeroepen wanneer de container wordt geïnitialiseerd of gestart. Initialisatie vindt meestal kort nadat de implementatie is gemaakt of bijgewerkt. De init functie is de plaats om logica te schrijven voor globale initialisatiebewerkingen, zoals het opslaan van het model in het geheugen (zoals wordt weergegeven in dit score.py bestand).
De run() functie wordt aangeroepen telkens wanneer het eindpunt wordt aangeroepen. Het voert de eigenlijke beoordeling en voorspelling uit. In dit score.py bestand extraheert de run() functie gegevens uit een JSON-invoer, roept de methode van predict() het scikit-learn-model aan en retourneert het voorspellingsresultaat.
Lokaal implementeren en fouten opsporen met behulp van een lokaal eindpunt
We raden u ten zeerste aan om uw eindpunt lokaal uit te voeren om uw code en configuratie te valideren en fouten op te sporen voordat u implementeert in Azure. De Azure CLI en Python SDK ondersteunen lokale eindpunten en implementaties, maar Azure Machine Learning Studio en ARM-sjablonen niet.
Als u lokaal wilt implementeren, moet Docker Engine worden geïnstalleerd en uitgevoerd. Docker Engine wordt doorgaans gestart wanneer de computer wordt gestart. Als dat niet het probleem is, kunt u problemen met Docker Engine oplossen.
U kunt het Azure Machine Learning-inferentie HTTP-server Python-pakket gebruiken om uw scorescript lokaal te debuggen zonder Docker Engine. Foutopsporing met de deductieserver helpt u bij het opsporen van fouten in het scorescript voordat u implementeert op lokale eindpunten, zodat u fouten kunt opsporen zonder dat dit wordt beïnvloed door de configuraties van de implementatiecontainer.
Zie Online-eindpunten opsporen voor meer informatie over het lokaal opsporen van fouten in online-eindpunten voordat u implementeert in Azure.
Het model lokaal implementeren
Maak eerst een eindpunt. U kunt deze stap desgewenst overslaan voor een lokaal eindpunt. U kunt de implementatie rechtstreeks (volgende stap) maken, waardoor de vereiste metagegevens worden gemaakt. Het lokaal implementeren van modellen is handig voor ontwikkelings- en testdoeleinden.
az ml online-endpoint create --local -n $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
ml_client.online_endpoints.begin_create_or_update(endpoint, local=True)
De studio biedt geen ondersteuning voor lokale eindpunten. Zie de Azure CLI- of Python-tabbladen voor stappen om het eindpunt lokaal te testen.
De sjabloon biedt geen ondersteuning voor lokale eindpunten. Zie de Azure CLI- of Python-tabbladen voor stappen om het eindpunt lokaal te testen.
Maak nu een implementatie met de naam blue onder het eindpunt.
az ml online-deployment create --local -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml
Met --local de vlag wordt de CLI om het eindpunt in de Docker-omgeving te implementeren.
ml_client.online_deployments.begin_create_or_update(
deployment=blue_deployment, local=True
)
Met local=True de vlag wordt de SDK om het eindpunt in de Docker-omgeving te implementeren.
De studio biedt geen ondersteuning voor lokale eindpunten. Zie de Azure CLI- of Python-tabbladen voor stappen om het eindpunt lokaal te testen.
De sjabloon biedt geen ondersteuning voor lokale eindpunten. Zie de Azure CLI- of Python-tabbladen voor stappen om het eindpunt lokaal te testen.
Controleer of de lokale implementatie is geslaagd
Controleer de implementatiestatus om te zien of het model zonder fouten is geïmplementeerd:
az ml online-endpoint show -n $ENDPOINT_NAME --local
De uitvoer moet er ongeveer uitzien als in de volgende JSON. De provisioning_state parameter is Succeeded.
{
"auth_mode": "key",
"location": "local",
"name": "docs-endpoint",
"properties": {},
"provisioning_state": "Succeeded",
"scoring_uri": "http://localhost:49158/score",
"tags": {},
"traffic": {}
}
ml_client.online_endpoints.get(name=endpoint_name, local=True)
De methode retourneert ManagedOnlineEndpoint de entiteit. De provisioning_state parameter is Succeeded.
ManagedOnlineEndpoint({'public_network_access': None, 'provisioning_state': 'Succeeded', 'scoring_uri': 'http://localhost:49158/score', 'swagger_uri': None, 'name': 'endpt-10061534497697', 'description': 'this is a sample endpoint', 'tags': {}, 'properties': {}, 'id': None, 'Resource__source_path': None, 'base_path': '/path/to/your/working/directory', 'creation_context': None, 'serialize': <msrest.serialization.Serializer object at 0x7ffb781bccd0>, 'auth_mode': 'key', 'location': 'local', 'identity': None, 'traffic': {}, 'mirror_traffic': {}, 'kind': None})
De studio biedt geen ondersteuning voor lokale eindpunten. Zie de Azure CLI- of Python-tabbladen voor stappen om het eindpunt lokaal te testen.
De sjabloon biedt geen ondersteuning voor lokale eindpunten. Zie de Azure CLI- of Python-tabbladen voor stappen om het eindpunt lokaal te testen.
De volgende tabel bevat de mogelijke waarden voor provisioning_state:
| Weergegeven als |
Beschrijving |
Creating |
De resource wordt gemaakt. |
Updating |
De resource wordt bijgewerkt. |
Deleting |
De resource wordt verwijderd. |
Succeeded |
De operatie voor maken of bijwerken is geslaagd. |
Failed |
De bewerking voor maken, bijwerken of verwijderen is mislukt. |
Het lokale eindpunt aanroepen om gegevens te scoren met behulp van uw model
Roep het eindpunt aan om het model te scoren met behulp van de invoke opdracht en queryparameters door te geven die zijn opgeslagen in een JSON-bestand:
az ml online-endpoint invoke --local --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Als u een REST-client (zoals curl) wilt gebruiken, moet u de score-URI hebben. Voer de score-URI uit az ml online-endpoint show --local -n $ENDPOINT_NAMEom de score-URI op te halen. Zoek het scoring_uri kenmerk in de geretourneerde gegevens.
Roep het eindpunt aan om het model te scoren met behulp van de invoke opdracht en queryparameters door te geven die zijn opgeslagen in een JSON-bestand.
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
request_file="../model-1/sample-request.json",
local=True,
)
Als u een REST-client (zoals curl) wilt gebruiken, moet u de score-URI hebben. Voer de volgende code uit om de score-URI op te halen. Zoek het scoring_uri kenmerk in de geretourneerde gegevens.
endpoint = ml_client.online_endpoints.get(endpoint_name, local=True)
scoring_uri = endpoint.scoring_uri
De studio biedt geen ondersteuning voor lokale eindpunten. Zie de Azure CLI- of Python-tabbladen voor stappen om het eindpunt lokaal te testen.
De sjabloon biedt geen ondersteuning voor lokale eindpunten. Zie de Azure CLI- of Python-tabbladen voor stappen om het eindpunt lokaal te testen.
Bekijk de logboeken voor uitvoer van de aanroepbewerking
In het voorbeeldbestand score.py registreert de run() methode uitvoer naar de console.
U kunt deze uitvoer weergeven met behulp van de get-logs opdracht:
az ml online-deployment get-logs --local -n blue --endpoint $ENDPOINT_NAME
U kunt deze uitvoer weergeven met behulp van de get_logs methode:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, local=True, lines=50
)
De studio biedt geen ondersteuning voor lokale eindpunten. Zie de Azure CLI- of Python-tabbladen voor stappen om het eindpunt lokaal te testen.
De sjabloon biedt geen ondersteuning voor lokale eindpunten. Zie de Azure CLI- of Python-tabbladen voor stappen om het eindpunt lokaal te testen.
Uw online-eindpunt implementeren in Azure
Implementeer vervolgens uw online-eindpunt in Azure. Als best practice voor productie raden we u aan het model en de omgeving te registreren die u in uw implementatie gebruikt.
Uw model en omgeving registreren
U wordt aangeraden uw model en omgeving te registreren vóór de implementatie in Azure, zodat u hun geregistreerde namen en versies tijdens de implementatie kunt opgeven. Nadat u uw assets hebt geregistreerd, kunt u ze opnieuw gebruiken zonder ze telkens te hoeven uploaden wanneer u implementaties maakt. Deze praktijk verhoogt de reproduceerbaarheid en traceerbaarheid.
In tegenstelling tot implementatie in Azure biedt lokale implementatie geen ondersteuning voor het gebruik van geregistreerde modellen en omgevingen. In plaats daarvan maakt lokale implementatie gebruik van lokale modelbestanden en maakt alleen gebruik van omgevingen met lokale bestanden.
Voor implementatie naar Azure kunt u lokale of geregistreerde assets (modellen en omgevingen) gebruiken. In deze sectie van het artikel maakt de implementatie in Azure gebruik van geregistreerde assets, maar in plaats daarvan hebt u de mogelijkheid om lokale assets te gebruiken. Zie Een implementatie configureren voor een voorbeeld van een implementatieconfiguratie waarmee lokale bestanden worden geüpload die moeten worden gebruikt voor lokale implementatie.
Als u het model en de omgeving wilt registreren, gebruikt u het formulier model: azureml:my-model:1 of environment: azureml:my-env:1.
Voor registratie kunt u de YAML-definities van model en environment in afzonderlijke YAML-bestanden extraheren in de map endpoints/online/managed/sample, en de opdrachten az ml model create en az ml environment create gebruiken. Voor meer informatie over deze opdrachten voert u de opdracht uit az ml model create -h en az ml environment create -h.
Maak een YAML-definitie voor het model. Geef het bestand de naam model.yml:
$schema: https://azuremlschemas.azureedge.net/latest/model.schema.json
name: my-model
path: ../../model-1/model/
Registreer het model:
az ml model create -n my-model -v 1 -f endpoints/online/managed/sample/model.yml
Maak een YAML-definitie voor de omgeving. Geef het bestand de naam environment.yml:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: my-env
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
conda_file: ../../model-1/environment/conda.yaml
Registreer de omgeving:
az ml environment create -n my-env -v 1 -f endpoints/online/managed/sample/environment.yml
Zie Een model registreren met behulp van de Azure CLI of Python SDK voor meer informatie over het registreren van uw model als asset. Zie Een aangepaste omgeving maken voor meer informatie over het maken van een omgeving.
Een model registreren:
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
file_model = Model(
path="../model-1/model/",
type=AssetTypes.CUSTOM_MODEL,
name="my-model",
description="Model created from local file.",
)
ml_client.models.create_or_update(file_model)
Registreer de omgeving:
from azure.ai.ml.entities import Environment
env_docker_conda = Environment(
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file="../model-1/environment/conda.yaml",
name="my-env",
description="Environment created from a Docker image plus Conda environment.",
)
ml_client.environments.create_or_update(env_docker_conda)
Zie Een model registreren met behulp van de Azure CLI of Python SDK voor meer informatie over het registreren van uw model als asset, zodat u de geregistreerde naam en versie tijdens de implementatie kunt opgeven.
Zie Een aangepaste omgeving maken voor meer informatie over het maken van een omgeving.
Het model registreren
Een modelregistratie is een logische entiteit in de werkruimte die één modelbestand of een map met meerdere bestanden kan bevatten. Als best practice voor productie registreert u het model en de omgeving. Voordat u het eindpunt en de implementatie in dit artikel maakt, registreert u de modelmap die het model bevat.
Voer de volgende stappen uit om het voorbeeldmodel te registreren:
Ga naar Azure Machine Learning-studio.
Selecteer in het linkerdeelvenster de pagina Modellen .
Selecteer Registreren en kies vervolgens Uit lokale bestanden.
Selecteer Niet-opgegeven type voor het modeltype.
Selecteer Bladeren en kies Bladeren in de map Bladeren.
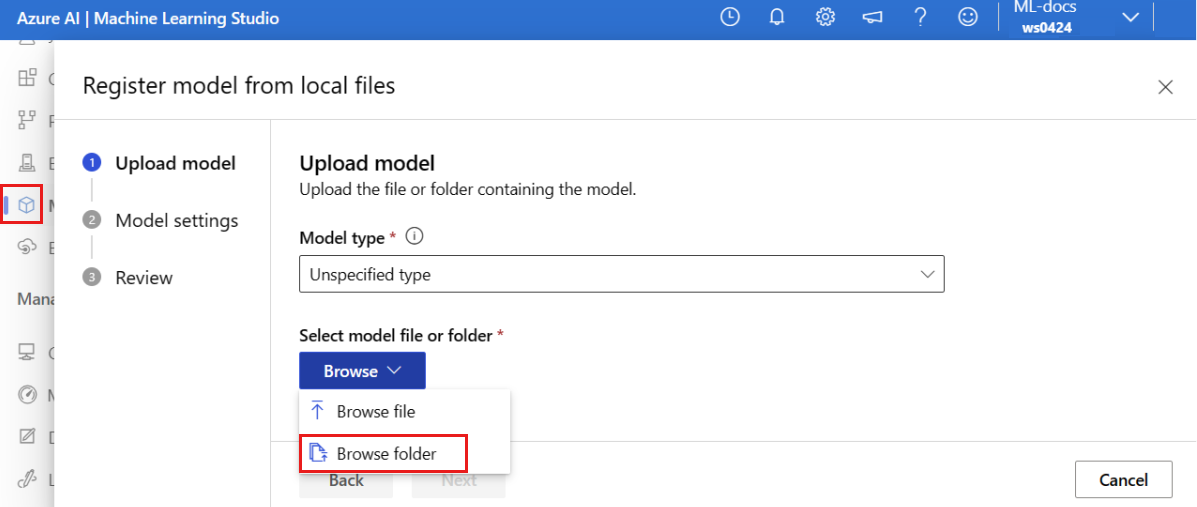
Selecteer de map \azureml-examples\cli\endpoints\online\model-1\model uit de lokale kopie van de opslagplaats die u eerder hebt gekloond of gedownload. Wanneer u hierom wordt gevraagd, selecteert u Uploaden en wacht u totdat het uploaden is voltooid.
Kies Volgende.
Voer een vriendelijke naam in voor het model. Bij de stappen in dit artikel wordt ervan uitgegaan dat het model de naam model-1heeft.
Selecteer Volgende en selecteer Registreren om de registratie te voltooien.
Zie Werken met geregistreerde modellen voor meer informatie over het werken met geregistreerde modellen.
De omgeving maken en registreren
Selecteer in het linkerdeelvenster de pagina Omgevingen .
Selecteer het tabblad Aangepaste omgevingen en kies Maken.
Voer op de pagina Instellingen een naam in, zoals my-env voor de omgeving.
Kies voor Omgevingsbron selecterenGebruik bestaande Docker-image met een optionele Conda-bron.
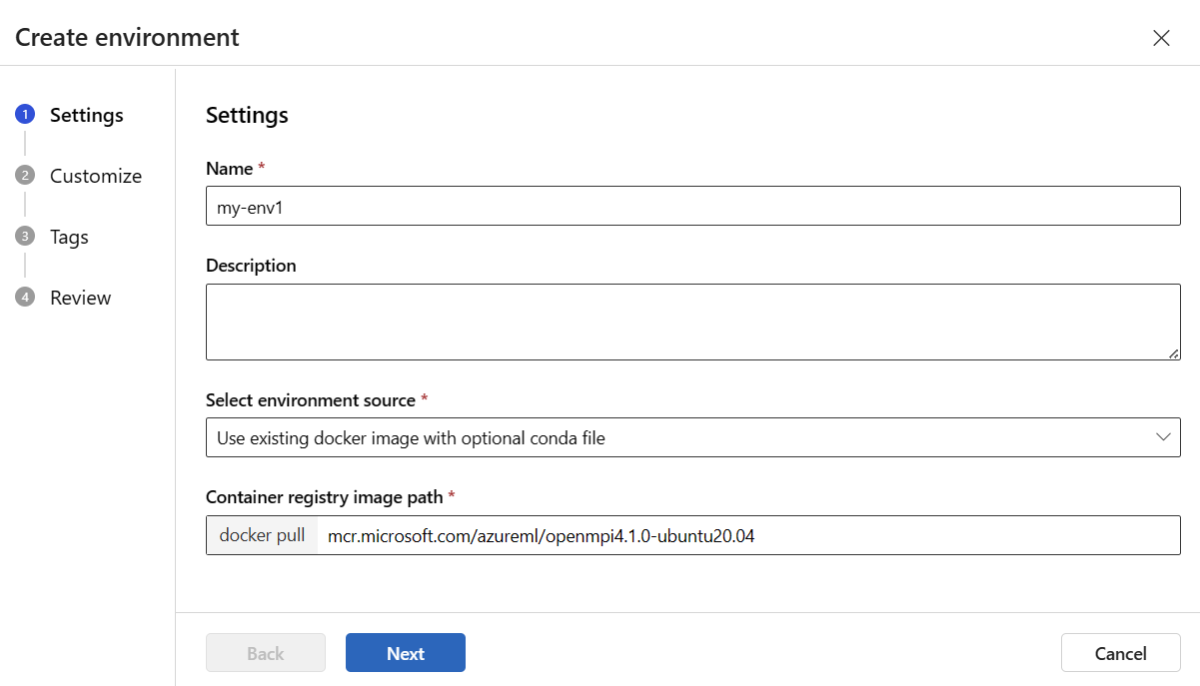
Selecteer Volgende om naar de pagina Aanpassen te gaan.
Kopieer de inhoud van het bestand \azureml-examples\cli\endpoints\online\model-1\environment\conda.yaml uit de opslagplaats die u eerder hebt gekloond of gedownload.
Plak de inhoud in het tekstvak.
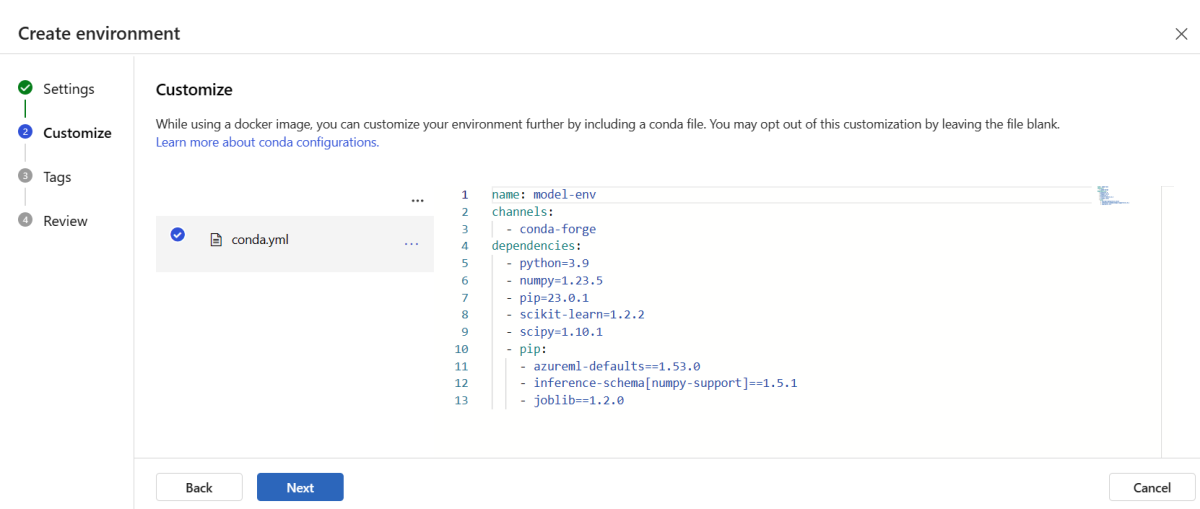
Selecteer Volgende totdat u bij de pagina Maken bent en selecteer Vervolgens Maken.
Zie Een omgeving maken voor meer informatie over het maken van een omgeving in de studio.
Als u het model wilt registreren met behulp van een sjabloon, moet u eerst het modelbestand uploaden naar Blob Storage. In het volgende voorbeeld wordt de az storage blob upload-batch opdracht gebruikt om een bestand te uploaden naar de standaardopslag voor uw werkruimte:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/model -s cli/endpoints/online/model-1/model --account-name $AZURE_STORAGE_ACCOUNT
Nadat u het bestand hebt geüpload, gebruikt u de sjabloon om een modelregistratie te maken. In het volgende voorbeeld bevat de modelUri parameter het pad naar het model:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/model-version.json \
--parameters \
workspaceName=$WORKSPACE \
modelAssetName="sklearn" \
modelUri="azureml://subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/workspaces/$WORKSPACE/datastores/$AZUREML_DEFAULT_DATASTORE/paths/model/sklearn_regression_model.pkl"
Een deel van de omgeving is een Conda-bestand dat de modelafhankelijkheden aangeeft die nodig zijn om het model te hosten. In het volgende voorbeeld ziet u hoe u de inhoud van het Conda-bestand kunt lezen in omgevingsvariabelen:
CONDA_FILE=$(cat cli/endpoints/online/model-1/environment/conda.yaml)
In het volgende voorbeeld ziet u hoe u de sjabloon gebruikt om de omgeving te registreren. De inhoud van het Conda-bestand uit de vorige stap wordt doorgegeven aan de sjabloon met behulp van de condaFile parameter:
ENV_VERSION=$RANDOM
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/environment-version.json \
--parameters \
workspaceName=$WORKSPACE \
environmentAssetName=sklearn-env \
environmentAssetVersion=$ENV_VERSION \
dockerImage=mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1 \
condaFile="$CONDA_FILE"
Belangrijk
Wanneer u een aangepaste omgeving voor uw implementatie definieert, moet u ervoor zorgen dat het azureml-inference-server-http pakket is opgenomen in het Conda-bestand. Dit pakket is essentieel voor een goede werking van de deductieserver. Als u niet bekend bent met het maken van uw eigen aangepaste omgeving, gebruikt u een van onze gecureerde omgevingen zoals minimal-py-inference (voor aangepaste modellen die niet worden gebruikt mlflow) of mlflow-py-inference (voor modellen die gebruikmaken mlflowvan). U vindt deze gecureerde omgevingen op het tabblad Omgevingen van uw exemplaar van Azure Machine Learning Studio.
Uw implementatieconfiguratie maakt gebruik van het geregistreerde model dat u wilt implementeren en uw geregistreerde omgeving.
Gebruik de geregistreerde assets (model en omgeving) in uw implementatiedefinitie. In het volgende fragment ziet u de endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml bestand, met alle vereiste ingevoerde gegevens voor het configureren van een implementatie.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:my-model:1
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment: azureml:my-env:1
instance_type: Standard_DS3_v2
instance_count: 1
Als u een implementatie wilt configureren, gebruikt u het geregistreerde model en de omgeving:
model = "azureml:my-model:1"
env = "azureml:my-env:1"
blue_deployment_with_registered_assets = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
Wanneer u vanuit de studio implementeert, maakt u een eindpunt en een implementatie die eraan moet worden toegevoegd. Op dat moment wordt u gevraagd om namen in te voeren voor het eindpunt en de implementatie.
Verschillende typen CPU- en GPU-exemplaren en -installatiekopieën gebruiken
U kunt de typen CPU- of GPU-exemplaren en -installatiekopieën in uw implementatiedefinitie opgeven voor zowel lokale implementatie als implementatie in Azure.
Uw implementatiedefinitie in het blue-deployment-with-registered-assets.yml-bestand heeft een exemplaar voor algemeen gebruik Standard_DS3_v2 en de niet-GPU Docker-installatiekopie mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latestgebruikt. Voor GPU-rekenkracht kiest u een versie van het GPU-rekentype en een GPU Docker-afbeelding.
Zie de SKU-lijst met beheerde online-eindpunten voor ondersteunde typen algemeen gebruik en GPU-exemplaren. Zie Basisinstallatiekopieën van Azure Machine Learning CPU en GPU voor een lijst met basisinstallatiekopieën van Azure Machine Learning.
Met de voorgaande registratie van de omgeving wordt een Docker-image mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04 zonder GPU opgegeven door de waarde door te geven aan de environment-version.json-sjabloon met behulp van de dockerImage parameter. Geef voor een GPU-bewerking een waarde op voor een GPU Docker-image aan de sjabloon (gebruik de dockerImage parameter) en geef een versie van het GPU-rekentype op aan de online-endpoint-deployment.json sjabloon (gebruik de skuName parameter).
Zie de SKU-lijst met beheerde online-eindpunten voor ondersteunde typen algemeen gebruik en GPU-exemplaren. Zie Basisinstallatiekopieën van Azure Machine Learning CPU en GPU voor een lijst met basisinstallatiekopieën van Azure Machine Learning.
Implementeer vervolgens uw online-eindpunt in Azure.
Implementeren op Azure
Maak het eindpunt in de Azure-cloud:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Maak de implementatie met de naam blue onder het eindpunt:
az ml online-deployment create --name blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml --all-traffic
Het maken van de implementatie kan maximaal 15 minuten duren, afhankelijk van of de onderliggende omgeving of installatiekopie voor het eerst wordt gebouwd. Volgende implementaties die dezelfde omgeving gebruiken, worden sneller verwerkt.
Als u de CLI-console liever niet blokkeert, kunt u de vlag --no-wait toevoegen aan de opdracht. Met deze optie wordt echter de interactieve weergave van de implementatiestatus gestopt.
De --all-traffic vlag in de code az ml online-deployment create die wordt gebruikt om de implementatie te maken, wijst 100% van het eindpuntverkeer toe aan de zojuist gemaakte blauwe implementatie. Het gebruik van deze vlag is handig voor ontwikkelings- en testdoeleinden, maar voor productie kunt u het verkeer naar de nieuwe implementatie routeren via een expliciete opdracht. Gebruik bijvoorbeeld az ml online-endpoint update -n $ENDPOINT_NAME --traffic "blue=100".
Maak het eindpunt:
Met behulp van de endpoint parameter die u eerder hebt gedefinieerd en de MLClient parameter die u eerder hebt gemaakt, kunt u nu het eindpunt in de werkruimte maken. Met deze opdracht wordt het maken van het eindpunt gestart en wordt een bevestigingsantwoord geretourneerd terwijl het maken van het eindpunt wordt voortgezet.
ml_client.online_endpoints.begin_create_or_update(endpoint)
De implementatie maken:
Met behulp van de blue_deployment_with_registered_assets parameter die u eerder hebt gedefinieerd en de MLClient parameter die u eerder hebt gemaakt, kunt u nu de implementatie in de werkruimte maken. Met deze opdracht wordt het maken van de implementatie gestart en wordt een bevestigingsantwoord geretourneerd terwijl het maken van de implementatie wordt voortgezet.
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Als u de Python-console liever niet blokkeert, kunt u de vlag no_wait=True toevoegen aan de parameters. Met deze optie wordt echter de interactieve weergave van de implementatiestatus gestopt.
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint)
Een beheerd online-eindpunt en -implementatie maken
Gebruik de studio om rechtstreeks in uw browser een beheerd online-eindpunt te maken. Wanneer u een beheerd online-eindpunt in de studio maakt, moet u een eerste implementatie definiëren. U kunt geen leeg beheerd online-eindpunt maken.
Eén manier om een beheerd online-eindpunt in de studio te maken, is op de pagina Modellen . Deze methode biedt ook een eenvoudige manier om een model toe te voegen aan een bestaande beheerde online-implementatie. Als u het model wilt implementeren dat model-1 u eerder hebt geregistreerd in de sectie Uw model en omgeving registreren:
Ga naar Azure Machine Learning-studio.
Selecteer in het linkerdeelvenster de pagina Modellen .
Selecteer het model met de naam model-1.
Selecteer Realtime-eindpunt>.
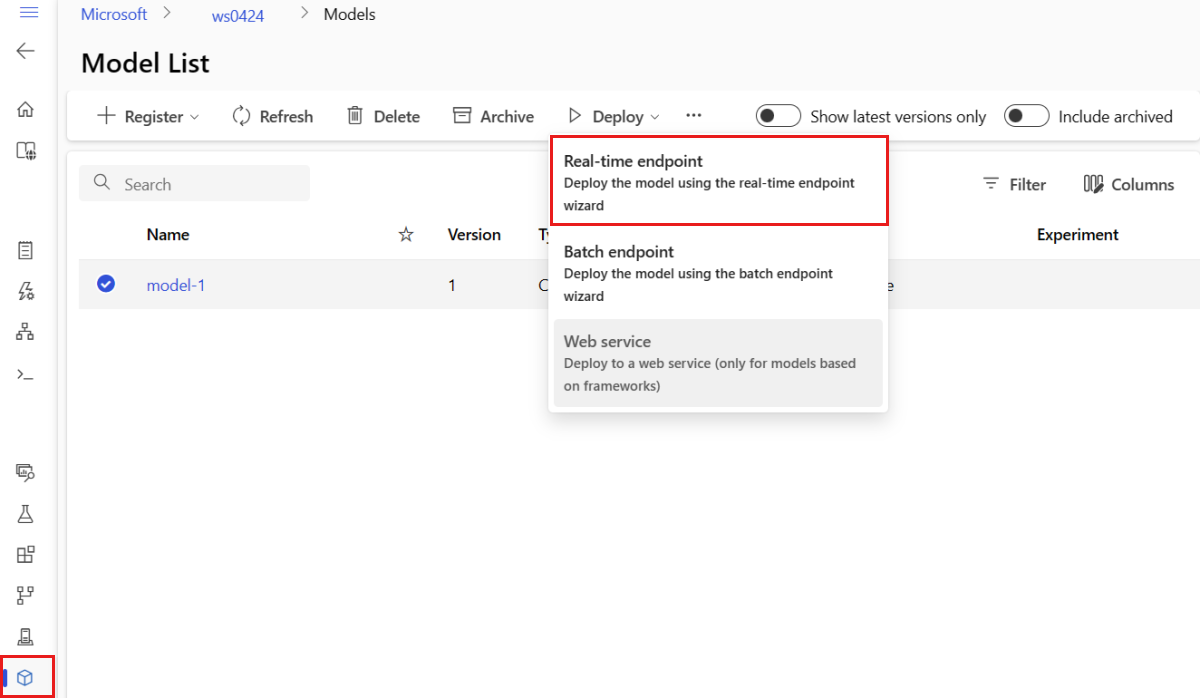
Met deze actie wordt een venster geopend waarin u details over uw eindpunt kunt opgeven.
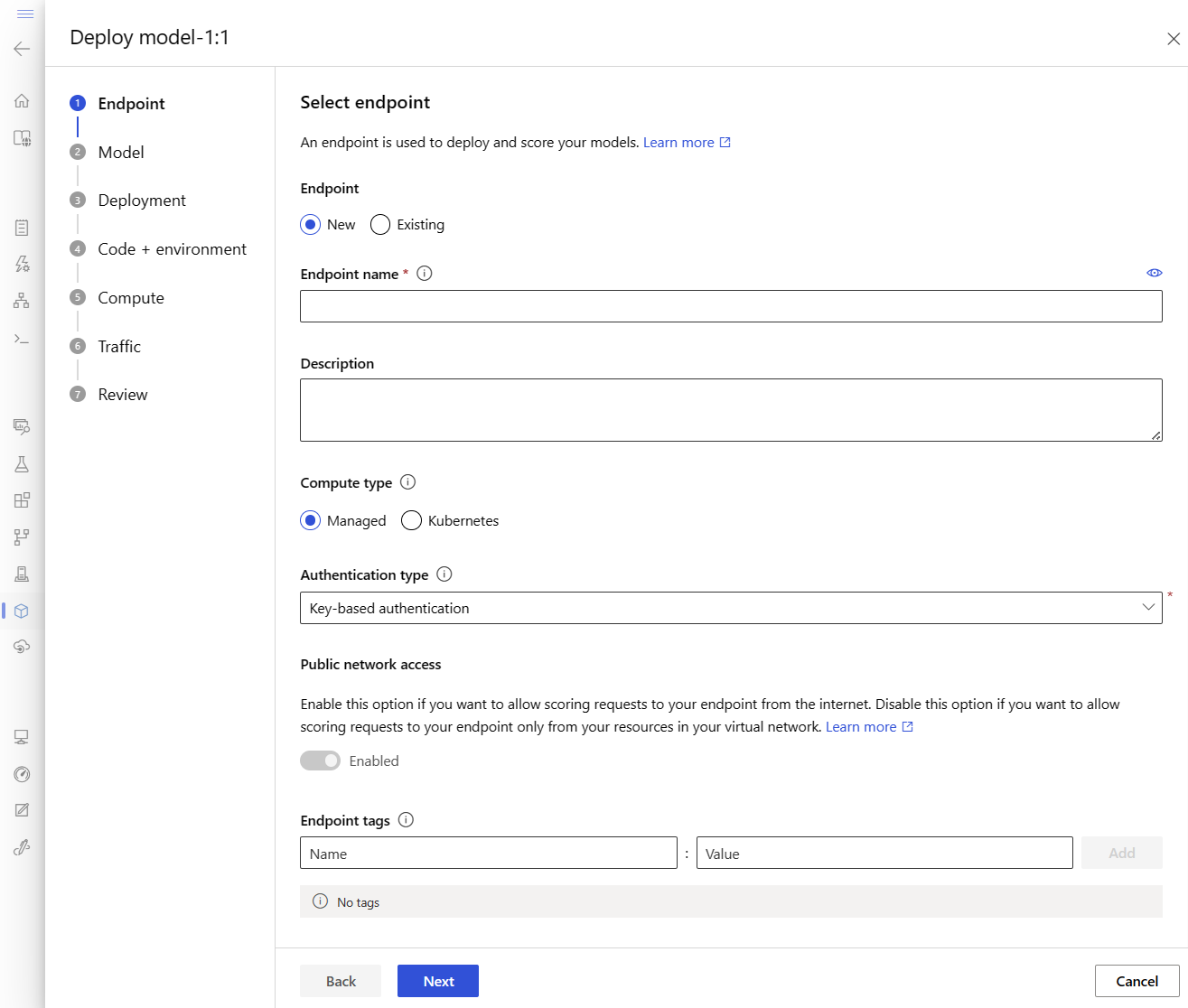
Voer een eindpuntnaam in die uniek is in de Azure-regio. Zie Eindpuntlimieten voor meer informatie over de naamgevingsregels.
Behoud de standaardselectie: beheerd voor het rekentype.
Behoud de standaardselectie: verificatie op basis van sleutels voor het verificatietype. Zie Clients verifiëren voor online-eindpunten voor meer informatie over verificatie.
Selecteer Volgende totdat u bij de pagina Implementatie bent. Schakel diagnostische gegevens van Application Insights in op Ingeschakeld , zodat u grafieken van de activiteiten van uw eindpunt in de studio later kunt bekijken en metrische gegevens en logboeken kunt analyseren met behulp van Application Insights.
Selecteer Volgende om naar de pagina Code en omgeving te gaan. Selecteer de volgende opties:
-
Selecteer een scorescript voor inferentie: Blader en selecteer het \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py bestand uit de opslagplaats die u eerder hebt gekloond of gedownload.
-
Omgevingssectie selecteren: Selecteer aangepaste omgevingen en selecteer vervolgens de omgeving my-env:1 die u eerder hebt gemaakt.
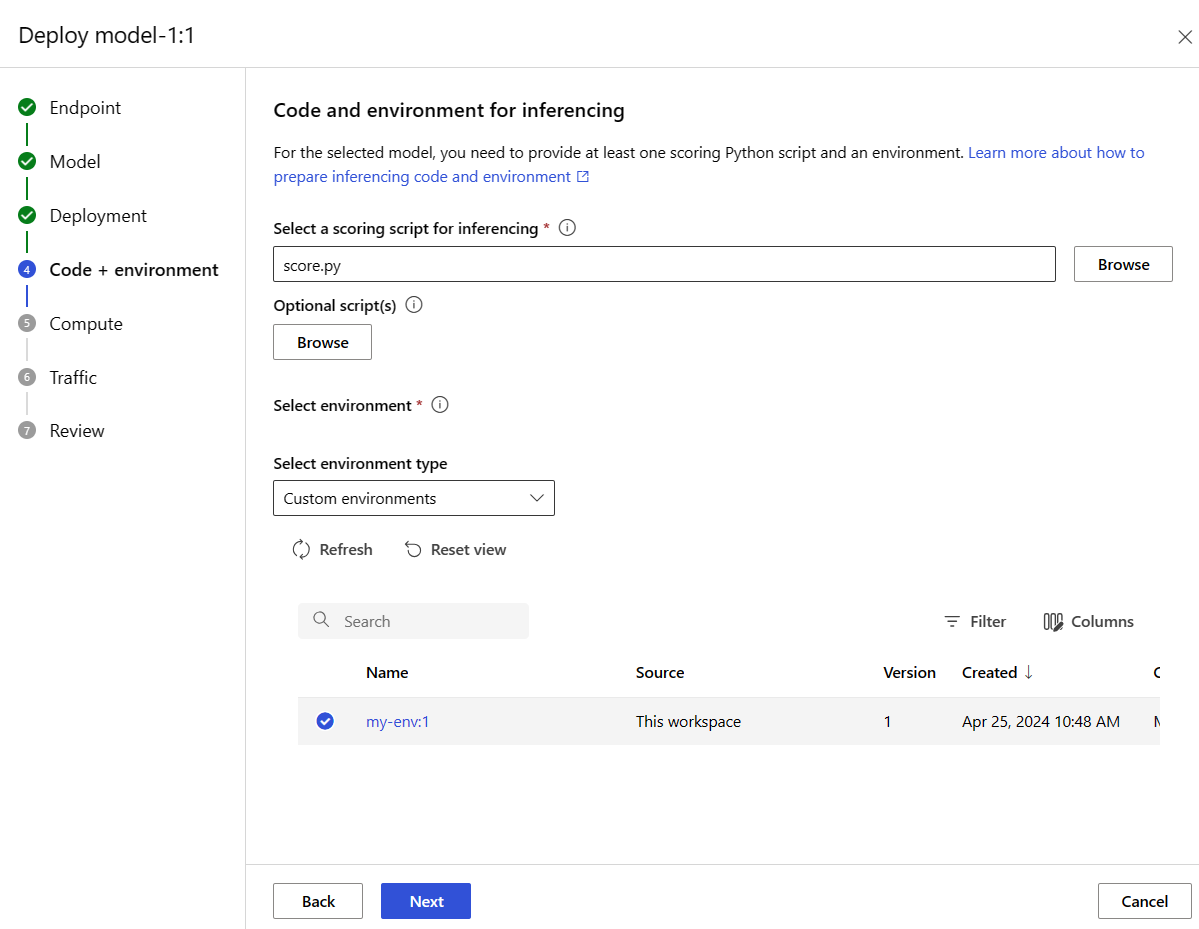
Selecteer Volgende en accepteer de standaardwaarden totdat u wordt gevraagd om de implementatie te maken.
Controleer uw implementatie-instellingen en selecteer Maken.
U kunt ook een beheerd online-eindpunt maken op de pagina Eindpunten in de studio.
Ga naar Azure Machine Learning-studio.
Selecteer in het linkerdeelvenster de pagina Eindpunten .
Selecteer + Maken.
Met deze actie wordt een venster geopend waarin u uw model kunt selecteren en details over uw eindpunt en implementatie kunt opgeven. Voer instellingen in voor uw eindpunt en implementatie zoals eerder beschreven en selecteer vervolgens Maken om de implementatie te maken.
Gebruik de sjabloon om een online-eindpunt te maken:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint.json \
--parameters \
workspaceName=$WORKSPACE \
onlineEndpointName=$ENDPOINT_NAME \
identityType=SystemAssigned \
authMode=AMLToken \
location=$LOCATION
Implementeer het model naar het eindpunt nadat het eindpunt is gemaakt:
resourceScope="/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices"
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint-deployment.json \
--parameters \
workspaceName=$WORKSPACE \
location=$LOCATION \
onlineEndpointName=$ENDPOINT_NAME \
onlineDeploymentName=blue \
codeId="$resourceScope/workspaces/$WORKSPACE/codes/score-sklearn/versions/1" \
scoringScript=score.py \
environmentId="$resourceScope/workspaces/$WORKSPACE/environments/sklearn-env/versions/$ENV_VERSION" \
model="$resourceScope/workspaces/$WORKSPACE/models/sklearn/versions/1" \
endpointComputeType=Managed \
skuName=Standard_F2s_v2 \
skuCapacity=1
Zie Problemen met online-eindpuntimplementaties oplossen om fouten in uw implementatie op te sporen.
De status van het online-eindpunt controleren
Gebruik de show opdracht om informatie weer te geven in het provisioning_state eindpunt en de implementatie:
az ml online-endpoint show -n $ENDPOINT_NAME
Geef alle eindpunten in de werkruimte weer in een tabelindeling met behulp van de list opdracht:
az ml online-endpoint list --output table
Controleer de status van het eindpunt om te zien of het model zonder fouten is geïmplementeerd:
ml_client.online_endpoints.get(name=endpoint_name)
Vermeld alle eindpunten in de werkruimte in een tabelindeling met behulp van de list methode:
for endpoint in ml_client.online_endpoints.list():
print(endpoint.name)
De methode retourneert een lijst (iterator) van ManagedOnlineEndpoint entiteiten.
U kunt meer informatie krijgen door meer parameters op te geven. Voer bijvoorbeeld de lijst met eindpunten uit zoals een tabel:
print("Kind\tLocation\tName")
print("-------\t----------\t------------------------")
for endpoint in ml_client.online_endpoints.list():
print(f"{endpoint.kind}\t{endpoint.location}\t{endpoint.name}")
Beheerde online-eindpunten weergeven
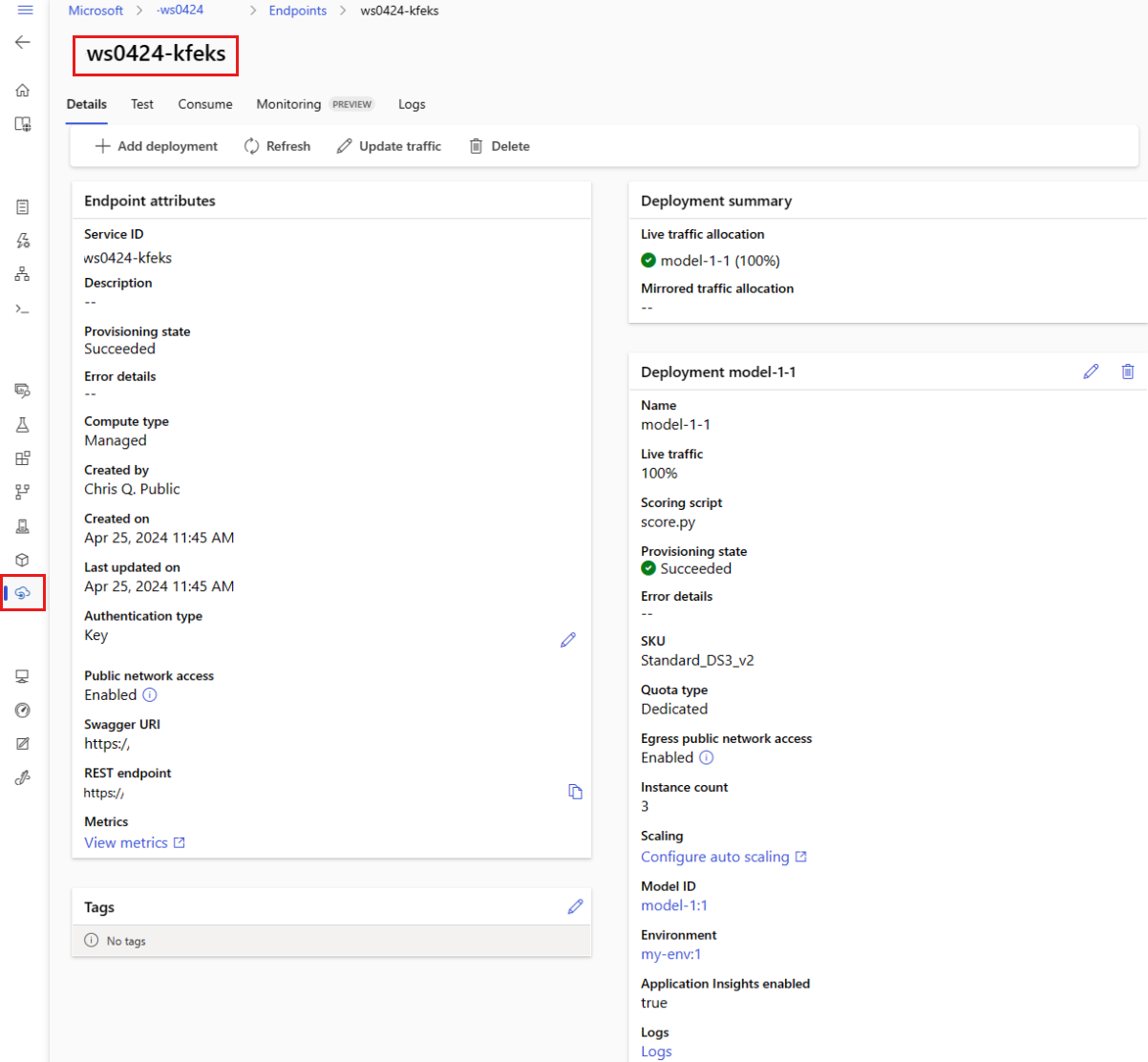
U kunt al uw beheerde online-eindpunten weergeven op de pagina Eindpunten . Ga naar de pagina Details van het eindpunt om kritieke informatie te vinden, zoals de eindpunt-URI, status, testhulpprogramma's, activiteitsmonitoren, implementatielogboeken en voorbeeldcode voor verbruik.
Selecteer in het linkerdeelvenster Eindpunten om een lijst met alle eindpunten in de werkruimte weer te geven.
(Optioneel) Maak een filter voor het rekentype om alleen beheerde rekentypen weer te geven.
Selecteer een eindpuntnaam om de pagina Details van het eindpunt weer te geven.
Sjablonen zijn handig voor het implementeren van resources, maar u kunt ze niet gebruiken om resources op te sommen, te tonen of aan te roepen. Gebruik de Azure CLI, Python SDK of de studio om deze bewerkingen uit te voeren. De volgende code maakt gebruik van de Azure CLI.
Gebruik de show opdracht om informatie weer te geven in de provisioning_state parameter voor het eindpunt en de implementatie:
az ml online-endpoint show -n $ENDPOINT_NAME
Geef alle eindpunten in de werkruimte weer in een tabelindeling met behulp van de list opdracht:
az ml online-endpoint list --output table
De status van de online-implementatie controleren
Controleer de logboeken om te zien of het model zonder fouten is geïmplementeerd.
Gebruik de volgende CLI-opdracht om logboekuitvoer van een container weer te geven:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Logboeken worden standaard opgehaald uit de container van de deductieserver. Voeg de --container storage-initializer vlag toe om logboeken uit de container voor de opslag-initialisatiefunctie weer te geven. Zie Containerlogboeken ophalen voor meer informatie over implementatielogboeken.
U kunt logboekuitvoer weergeven met behulp van de get_logs methode:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Logboeken worden standaard opgehaald uit de container van de deductieserver. Als u logboeken uit de container voor opslag initialisatie wilt zien, voegt u de container_type="storage-initializer" optie toe. Zie Containerlogboeken ophalen voor meer informatie over implementatielogboeken.
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50, container_type="storage-initializer"
)
Als u logboekuitvoer wilt weergeven, selecteert u het tabblad Logboeken op de pagina van het eindpunt. Als u meerdere implementaties in uw eindpunt hebt, gebruikt u de vervolgkeuzelijst om de implementatie te selecteren met het logboek dat u wilt zien.
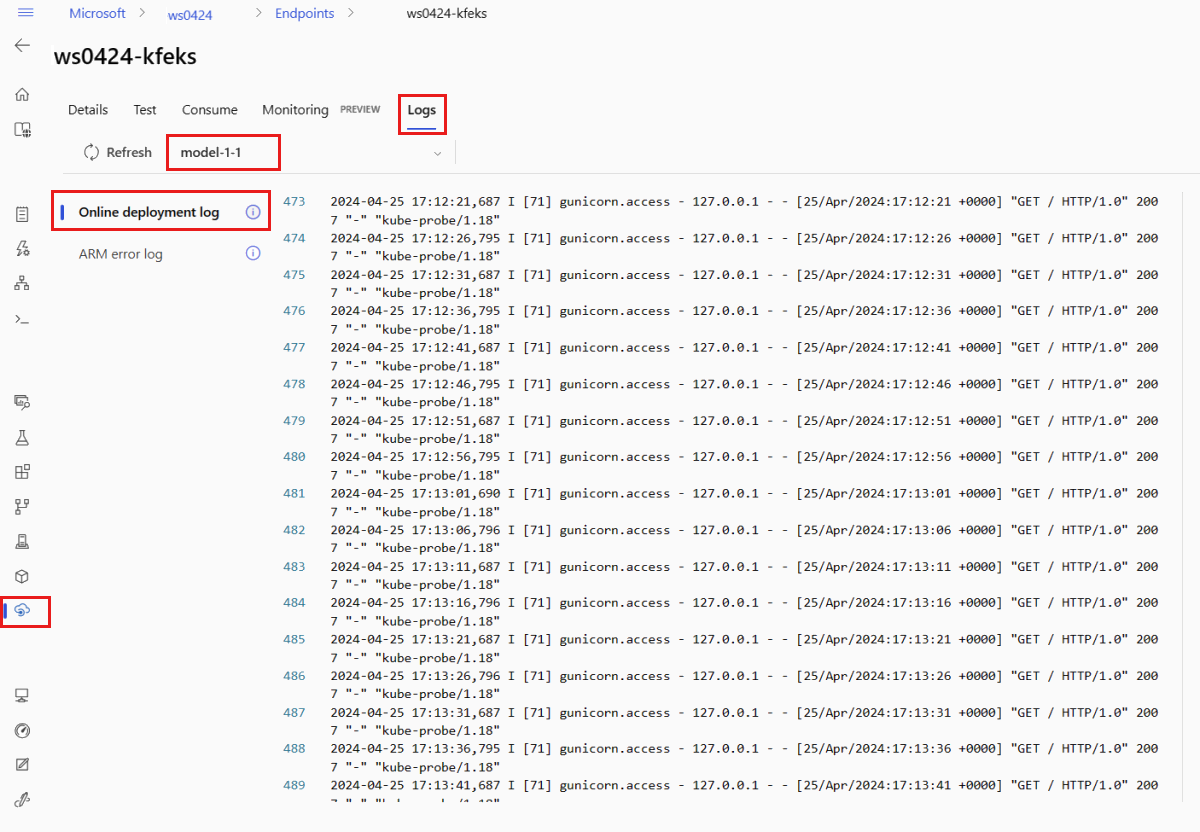
Logboeken worden standaard opgehaald van de deductieserver. Gebruik de Azure CLI of Python SDK (zie elk tabblad voor meer informatie) om logboeken van de container voor de opslag-initialisatiefunctie te bekijken. Logboeken van de container voor de opslag-initialisatiefunctie bevatten informatie over het feit of code- en modelgegevens zijn gedownload naar de container. Zie Containerlogboeken ophalen voor meer informatie over implementatielogboeken.
Sjablonen zijn handig voor het implementeren van resources, maar u kunt ze niet gebruiken om resources op te sommen, weer te geven of aan te roepen. Gebruik de Azure CLI, Python SDK of de studio om deze bewerkingen uit te voeren. De volgende code maakt gebruik van de Azure CLI.
Gebruik de volgende CLI-opdracht om logboekuitvoer van een container weer te geven:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Logboeken worden standaard opgehaald uit de container van de deductieserver. Voeg de --container storage-initializer vlag toe om logboeken uit de container voor de opslag-initialisatiefunctie weer te geven. Zie Containerlogboeken ophalen voor meer informatie over implementatielogboeken.
Het eindpunt aanroepen om gegevens te scoren met behulp van uw model
Gebruik de invoke opdracht of een REST-client van uw keuze om het eindpunt aan te roepen en enkele gegevens te scoren:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Haal de sleutel op die wordt gebruikt om te verifiëren bij het eindpunt:
U kunt bepalen welke Microsoft Entra-beveiligingsprinciplen de verificatiesleutel kunnen ophalen door ze toe te wijzen aan een aangepaste rol waarmee Microsoft.MachineLearningServices/workspaces/onlineEndpoints/token/action en Microsoft.MachineLearningServices/workspaces/onlineEndpoints/listkeys/action. Zie Toegang tot een Azure Machine Learning-werkruimte beheren voor meer informatie over het beheren van autorisatie voor werkruimten.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n $ENDPOINT_NAME -o tsv --query primaryKey)
Gebruik curl om gegevens te beoordelen.
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @endpoints/online/model-1/sample-request.json
Merk op dat u de show en get-credentials opdrachten gebruikt om de authenticatiegegevens te verkrijgen. U ziet ook dat u de --query vlag gebruikt om alleen de kenmerken te filteren die nodig zijn. Zie --query van de Azure CLI-opdracht opvragen voor meer informatie over de vlag.
Als u de aanroeplogboeken wilt zien, voert u de opdracht opnieuw uit get-logs .
Door de MLClient parameter te gebruiken die u eerder hebt gemaakt, krijgt u een ingang naar het eindpunt. Vervolgens kunt u het eindpunt aanroepen met behulp van de invoke opdracht met de volgende parameters:
-
endpoint_name: naam van het eindpunt.
-
request_file: Bestand met aanvraaggegevens.
-
deployment_name: De naam van de specifieke implementatie die moet worden getest in een eindpunt.
Een voorbeeldaanvraag verzenden met behulp van een JSON-bestand .
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
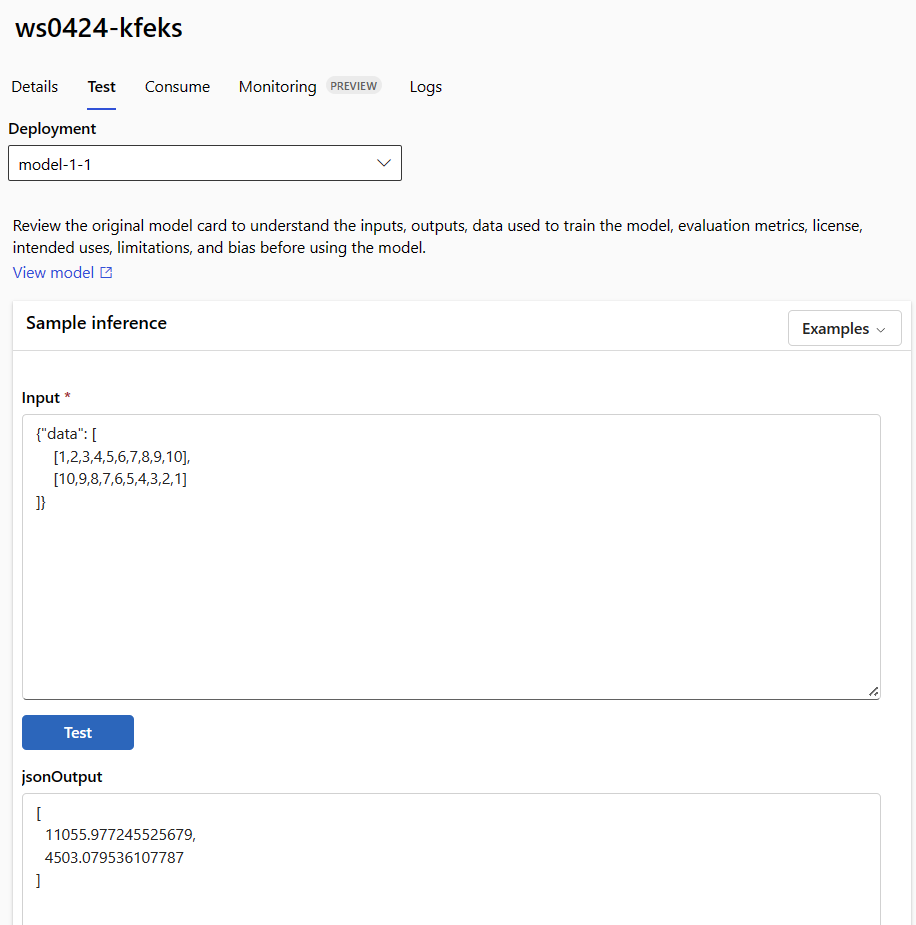
Gebruik het tabblad Testen op de detailpagina van het eindpunt om uw beheerde online-implementatie te testen. Voer voorbeeldinvoer in en bekijk de resultaten.
Selecteer het tabblad Testen op de detailpagina van het eindpunt.
Gebruik de vervolgkeuzelijst om de implementatie te selecteren die u wilt testen.
Voer de voorbeeldinvoer in.
Selecteer Testen.
Sjablonen zijn handig voor het implementeren van resources, maar u kunt ze niet gebruiken om resources op te sommen, tonen of aan te roepen. Gebruik de Azure CLI, Python SDK of de studio om deze bewerkingen uit te voeren. De volgende code maakt gebruik van de Azure CLI.
Gebruik de invoke opdracht of een REST-client van uw keuze om het eindpunt aan te roepen en enkele gegevens te scoren:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file cli/endpoints/online/model-1/sample-request.json
(Optioneel) De implementatie bijwerken
Als u de code, het model of de omgeving wilt bijwerken, werkt u het YAML-bestand bij. Voer vervolgens de az ml online-endpoint update opdracht uit.
Als u het aantal exemplaren bijwerkt (om uw implementatie te schalen) samen met andere modelinstellingen (zoals code, model of omgeving) in één update opdracht, wordt de schaalbewerking eerst uitgevoerd. De andere updates worden vervolgens toegepast. Het is een goede gewoonte om deze bewerkingen afzonderlijk uit te voeren in een productieomgeving.
Ga als volgt te werk om te begrijpen hoe update het werkt:
Open het bestand online/model-1/onlinescoring/score.py.
De laatste regel van de init() functie wijzigen: Na logging.info("Init complete"), toevoegen logging.info("Updated successfully").
Sla het bestand op.
Voer deze opdracht uit:
az ml online-deployment update -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml
Bijwerken met behulp van YAML is declaratief. Dat wil gezegd, wijzigingen in de YAML worden doorgevoerd in de onderliggende Resource Manager-resources (eindpunten en implementaties). Een declaratieve benadering faciliteert GitOps: alle wijzigingen in eindpunten en implementaties (zelfs instance_count) doorlopen de YAML.
U kunt algemene updateparameters--setmet de CLI-opdracht update om kenmerken in uw YAML te overschrijven of om specifieke kenmerken in te stellen zonder deze door te geven in het YAML-bestand. Het gebruik --set van één kenmerk is vooral waardevol in ontwikkelings- en testscenario's. Als u bijvoorbeeld de waarde voor de instance_count eerste implementatie omhoog wilt schalen, kunt u de --set instance_count=2 vlag gebruiken. Omdat de YAML echter niet wordt bijgewerkt, faciliteert deze techniek GitOps niet.
Het opgeven van het YAML-bestand is niet verplicht. Als u bijvoorbeeld verschillende gelijktijdigheidsinstellingen voor een specifieke implementatie wilt testen, kunt u iets proberen als az ml online-deployment update -n blue -e my-endpoint --set request_settings.max_concurrent_requests_per_instance=4 environment_variables.WORKER_COUNT=4. Met deze methode blijven alle bestaande configuraties behouden, maar worden alleen de opgegeven parameters bijgewerkt.
Omdat u de init() functie hebt gewijzigd, die wordt uitgevoerd wanneer het eindpunt wordt gemaakt of bijgewerkt, wordt het bericht Updated successfully weergegeven in de logboeken. Haal de logboeken op door het volgende uit te voeren:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
De update opdracht werkt ook met lokale implementaties. Gebruik dezelfde az ml online-deployment update opdracht met de --local vlag.
Als u de code, het model of de omgeving wilt bijwerken, werkt u de configuratie bij en voert u vervolgens de MLClientmethode uit online_deployments.begin_create_or_update om een implementatie te maken of bij te werken.
Als u het aantal exemplaren bijwerkt (om uw implementatie te schalen) samen met andere modelinstellingen (zoals code, model of omgeving) in één begin_create_or_update methode, wordt de schaalbewerking eerst uitgevoerd. Vervolgens worden de andere updates toegepast. Het is een goede gewoonte om deze bewerkingen afzonderlijk uit te voeren in een productieomgeving.
Ga als volgt te werk om te begrijpen hoe begin_create_or_update het werkt:
Open het bestand online/model-1/onlinescoring/score.py.
De laatste regel van de init() functie wijzigen: Na logging.info("Init complete"), toevoegen logging.info("Updated successfully").
Sla het bestand op.
Voer de methode uit:
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Omdat u de init() functie hebt gewijzigd, die wordt uitgevoerd wanneer het eindpunt wordt gemaakt of bijgewerkt, wordt het bericht Updated successfully weergegeven in de logboeken. Haal de logboeken op door het volgende uit te voeren:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
De begin_create_or_update methode werkt ook met lokale implementaties. Gebruik dezelfde methode met de local=True vlag.
Op dit moment kunt u alleen updates aanbrengen voor het aantal exemplaren van een implementatie. Gebruik de volgende instructies om een afzonderlijke implementatie omhoog of omlaag te schalen door het aantal exemplaren aan te passen:
- Open de pagina Details van het eindpunt en zoek de kaart voor de implementatie die u wilt bijwerken.
- Selecteer het bewerkingspictogram (potloodpictogram) naast de naam van de implementatie.
- Werk het aantal exemplaren bij dat is gekoppeld aan de implementatie. Kies tussen standaardgebruik of doelgebruik voor het implementatieschaaltype.
- Als u Standaard selecteert, kunt u ook een numerieke waarde opgeven voor het aantal exemplaren.
- Als u doelgebruik selecteert, kunt u waarden opgeven die moeten worden gebruikt voor parameters wanneer u de implementatie automatisch schaalt.
- Selecteer Bijwerken om het bijwerken van het aantal exemplaren voor uw implementatie te voltooien.
Er is momenteel geen optie om de implementatie bij te werken met behulp van een ARM-sjabloon.
Notitie
De update voor de implementatie in deze sectie is een voorbeeld van een in-place rolling update.
- Voor een beheerd online-eindpunt wordt de implementatie bijgewerkt naar de nieuwe configuratie met 20% van de knooppunten tegelijk. Als de implementatie 10 knooppunten heeft, worden twee knooppunten tegelijk bijgewerkt.
- Voor een Online-eindpunt van Kubernetes maakt het systeem iteratief een nieuw implementatie-exemplaar met de nieuwe configuratie en verwijdert het oude exemplaar.
- Overweeg voor productiegebruik blauwgroene implementatie, die een veiliger alternatief biedt voor het bijwerken van een webservice.
Automatisch schalen wordt uitgevoerd met de juiste hoeveelheid resources om de belasting van uw toepassing te verwerken. Beheerde online-eindpunten bieden ondersteuning voor automatisch schalen via integratie met de functie voor automatische schaalaanpassing van Azure Monitor. Zie Online-eindpunten voor automatisch schalen als u automatische schaalaanpassing wilt configureren.
(Optioneel) SLA bewaken met behulp van Azure Monitor
Als u metrische gegevens wilt weergeven en waarschuwingen wilt instellen op basis van uw SLA, volgt u de stappen die worden beschreven in Online-eindpunten bewaken.
(Optioneel) Integreren met Log Analytics
De get-logs opdracht voor de CLI of de get_logs methode voor de SDK biedt alleen de laatste honderd regels logboeken van een automatisch geselecteerd exemplaar. Log Analytics biedt echter een manier om logboeken duurzaam op te slaan en te analyseren. Zie Logboeken gebruiken voor meer informatie over het gebruik van logboekregistratie.
Het eindpunt en de implementatie verwijderen
Gebruik de volgende opdracht om het eindpunt en alle onderliggende implementaties te verwijderen:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Gebruik de volgende opdracht om het eindpunt en alle onderliggende implementaties te verwijderen:
ml_client.online_endpoints.begin_delete(name=endpoint_name)
Als u het eindpunt en de implementatie niet gaat gebruiken, verwijdert u deze. Door het eindpunt te verwijderen, verwijdert u ook alle onderliggende implementaties.
- Ga naar Azure Machine Learning-studio.
- Selecteer in het linkerdeelvenster de pagina Eindpunten .
- Selecteer een eindpunt.
- Selecteer Verwijderen.
U kunt ook een beheerd online-eindpunt rechtstreeks verwijderen door het pictogram Verwijderen te selecteren op de pagina met eindpuntdetails.
Gebruik de volgende opdracht om het eindpunt en alle onderliggende implementaties te verwijderen:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Gerelateerde inhoud









