REST-zelfstudie: Vaardighedensets gebruiken om doorzoekbare inhoud te genereren in Azure AI Search
In deze zelfstudie leert u hoe u REST API's aanroept die een AI-verrijkingspijplijn maken voor inhoudextractie en transformaties tijdens het indexeren.
Vaardighedensets voegen AI-verwerking toe aan onbewerkte inhoud, waardoor die inhoud uniformer en doorzoekbaarder wordt. Zodra u weet hoe vaardighedensets werken, kunt u een breed scala aan transformaties ondersteunen: van afbeeldingsanalyse tot verwerking van natuurlijke taal tot aangepaste verwerking die u extern levert.
In deze zelfstudie leert u het volgende:
- Objecten definiëren in een verrijkingspijplijn.
- Bouw een vaardighedenset. Roep OCR, taaldetectie, entiteitsherkenning en sleuteltermextractie aan.
- Voer de pijplijn uit. Een zoekindex maken en laden.
- Controleer de resultaten met behulp van zoeken in volledige tekst.
Als u geen abonnement op Azure hebt, opent u een gratis account voordat u begint.
Overzicht
In deze zelfstudie worden een REST-client en de REST API's van Azure AI Search gebruikt om een gegevensbron, index, indexeerfunctie en vaardighedenset te maken.
De indexeerfunctie stuurt elke stap in de pijplijn aan, te beginnen met het ophalen van inhoud van voorbeeldgegevens (ongestructureerde tekst en afbeeldingen) in een blobcontainer in Azure Storage.
Zodra inhoud is geëxtraheerd, voert de vaardighedenset ingebouwde vaardigheden van Microsoft uit om informatie te vinden en te extraheren. Deze vaardigheden omvatten Optical Character Recognition (OCR) voor afbeeldingen, taaldetectie op tekst, sleuteltermextractie en entiteitsherkenning (organisaties). Nieuwe informatie die door de vaardighedenset is gemaakt, wordt verzonden naar velden in een index. Zodra de index is ingevuld, kunt u de velden in query's, facetten en filters gebruiken.
Vereisten
Notitie
U kunt een gratis zoekservice gebruiken voor deze zelfstudie. De gratis laag beperkt u tot drie indexen, drie indexeerfuncties en drie gegevensbronnen. In deze zelfstudie wordt één exemplaar van elk onderdeel gemaakt. Voordat u aan de slag gaat, zorg ervoor dat uw service voldoende ruimte heeft voor de nieuwe resources.
Bestanden downloaden
Download een zip-bestand van de opslagplaats met voorbeeldgegevens en pak de inhoud uit. Meer informatie.
Voorbeeldgegevens uploaden naar Azure Storage
Maak in Azure Storage een nieuwe container en geef deze de naam cog-search-demo.
Haal een opslag verbindingsreeks zodat u een verbinding kunt formuleren in Azure AI Search.
Selecteer aan de linkerkant Toegangssleutels.
Kopieer de verbindingsreeks voor sleutel één of twee. De verbindingsreeks is vergelijkbaar met het volgende voorbeeld:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure AI-services
Ingebouwde AI-verrijking wordt ondersteund door Azure AI-services, waaronder taalservice en Azure AI Vision voor natuurlijke taal en beeldverwerking. Voor kleine workloads zoals deze zelfstudie kunt u de gratis toewijzing van twintig transacties per indexeerfunctie gebruiken. Voor grotere workloads koppelt u een Resource voor meerdere regio's van Azure AI Services aan een vaardighedenset voor prijzen voor betalen per gebruik.
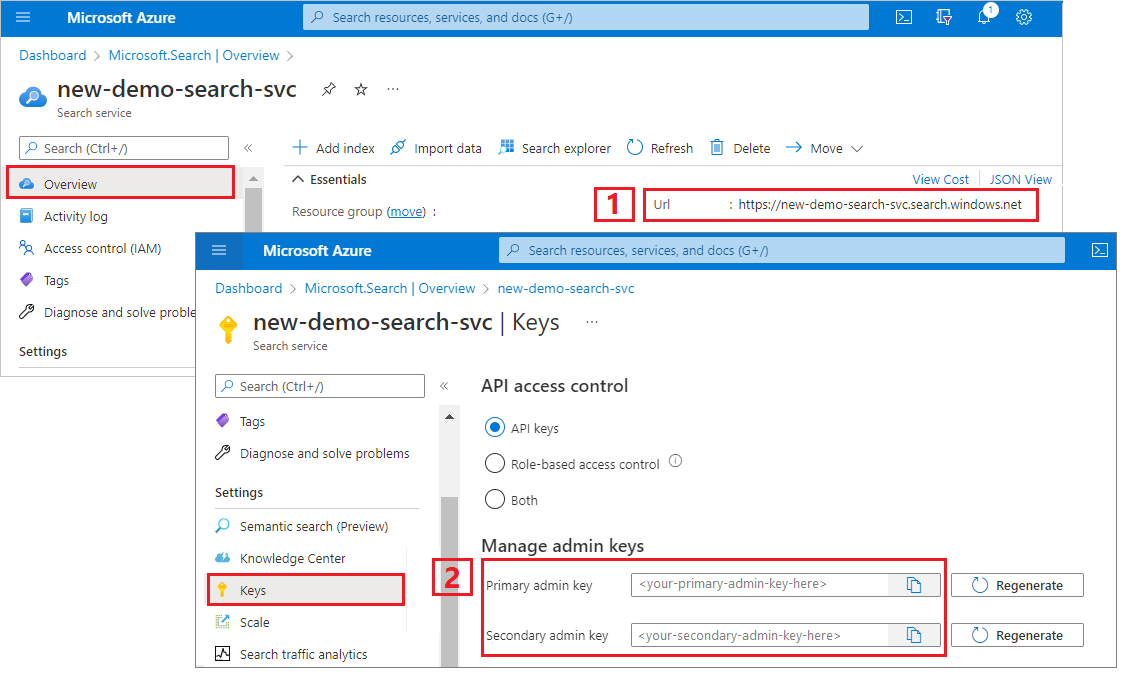
Een URL en API-sleutel van een zoekservice kopiëren
Voor deze zelfstudie is voor verbindingen met Azure AI Search een eindpunt en een API-sleutel vereist. U kunt deze waarden ophalen uit Azure Portal.
Meld u aan bij Azure Portal, navigeer naar de overzichtspagina van de zoekservice en kopieer de URL. Een eindpunt ziet er bijvoorbeeld uit als
https://mydemo.search.windows.net.Kopieer onder Instellingensleutels> een beheerderssleutel. Beheerderssleutels worden gebruikt om objecten toe te voegen, te wijzigen en te verwijderen. Er zijn twee uitwisselbare beheerderssleutels. Kopieer een van beide.
Uw REST-bestand instellen
Start Visual Studio Code en open het bestand skillset-tutorial.rest . Zie quickstart: Tekst zoeken met REST als u hulp nodig hebt bij de REST-client.
Geef waarden op voor de variabelen: zoekservice-eindpunt, api-sleutel voor zoekservicebeheerder, een indexnaam, een verbindingsreeks voor uw Azure Storage-account en de naam van de blobcontainer.
Maak de pijplijn
AI-verrijking is gebaseerd op indexeerfuncties. In dit deel van het scenario worden vier objecten gemaakt: gegevensbron, indexdefinitie, vaardighedenset, indexeerfunctie.
Stap 1: een gegevensbron maken
Roep Gegevensbron maken aan om de verbindingsreeks in te stellen op de blobcontainer met de voorbeeldgegevensbestanden.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Stap 2: een vaardighedenset maken
Roep Vaardighedenset maken aan om op te geven welke verrijkingsstappen op uw inhoud worden toegepast. Vaardigheden worden parallel uitgevoerd, tenzij er een afhankelijkheid is.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Belangrijkste punten:
De hoofdtekst van de aanvraag geeft de volgende ingebouwde vaardigheden op:
Vaardigheid Beschrijving Optische tekenherkenning Herkent tekst en getallen in afbeeldingsbestanden. Tekst samenvoegen Hiermee maakt u 'samengevoegde inhoud' die eerder gescheiden inhoud opnieuw samenvoegt, handig voor documenten met ingesloten afbeeldingen (PDF, DOCX, enzovoort). Afbeeldingen en tekst worden gescheiden tijdens de fase van het kraken van documenten. Met de samenvoegvaardigheid worden ze opnieuw samengevoegd door herkende tekst, bijschriften van afbeeldingen of tags in te voegen die tijdens de verrijking zijn gemaakt op dezelfde locatie waar de afbeelding uit het document is geëxtraheerd. Wanneer u met samengevoegde inhoud in een vaardighedenset werkt, bevat dit knooppunt alle tekst in het document, inclusief alleen-tekstdocumenten die nooit OCR- of afbeeldingsanalyse ondergaan. Taaldetectie Detecteert de taal en voert een taalnaam of code uit. In meertalige gegevenssets kan een taalveld handig zijn voor filters. Herkenning van entiteiten Extraheert de namen van personen, organisaties en locaties uit samengevoegde inhoud. Tekst splitsen Hiermee wordt grote samengevoegde inhoud opgesplitst in kleinere segmenten voordat u de vaardigheid voor sleuteltermextractie aanroept. Sleuteltermextractie accepteert invoeren van 50.000 tekens of minder. Enkele voorbeeldbestanden moeten worden opgesplitst om aan deze limiet te voldoen. Sleuteltermextractie Hiermee worden de belangrijkste sleuteltermen opgehaald. Elke vaardigheid wordt uitgevoerd voor de inhoud van het document. Tijdens de verwerking scheurt Azure AI Search elk document om inhoud uit verschillende bestandsindelingen te lezen. Gevonden tekst uit het bronbestand wordt in een gegenereerd
content-veld geplaatst, één voor elk document. Als zodanig wordt de invoer"/document/content".Voor het extraheren van sleuteltermen is de context voor de vaardigheid sleuteltermextractie
"document/pages/*"(voor elke pagina in het document) in plaats van"/document/content", omdat de vaardigheid Tekst splitsen wordt gebruikt om grotere bestanden in pagina's op te splitsen.
Notitie
Uitvoeren kunnen aan een index worden toegewezen, als invoer worden gebruikt voor een downstream-vaardigheid, of beide zoals bij taalcode. Een taalcode is in de index handig om te filteren. Zie How to define a skillset (Een set vaardigheden definiëren) voor meer informatie over de grondbeginselen van vaardigheden.
Stap 3: Een index maken
Roep Index maken aan om het schema op te geven dat wordt gebruikt voor het maken van omgekeerde indexen en andere constructies in Azure AI Search.
Het grootste onderdeel van een index is de verzameling velden, waarbij gegevenstype en kenmerken inhoud en gedrag bepalen in Azure AI Search. Zorg ervoor dat u velden hebt voor de zojuist gegenereerde uitvoer.
### Create an index
POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Stap 4: Een indexeerfunctie maken en uitvoeren
Roep Indexeerfunctie maken aan om de pijplijn te besturen. De drie onderdelen die u tot nu toe hebt gemaakt (gegevensbron, vaardighedenset, index) zijn invoer naar een indexeerfunctie. Het maken van de indexeerfunctie in Azure AI Search is de gebeurtenis waarmee de hele pijplijn in beweging wordt gebracht.
Deze stap kan enkele minuten in beslag nemen. De gegevensset is klein, maar analytische vaardigheden zijn berekeningsintensief.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Belangrijkste punten:
De hoofdtekst van de aanvraag bevat verwijzingen naar de vorige objecten, configuratie-eigenschappen die vereist zijn voor de verwerking van afbeeldingen en twee typen veldtoewijzingen.
"fieldMappings"worden verwerkt vóór de vaardighedenset, waarbij inhoud van de gegevensbron naar doelvelden in een index wordt verzonden. U gebruikt veldtoewijzingen om bestaande, ongewijzigde inhoud naar de index te verzenden. Als veldnamen en -typen gelijk zijn aan beide uiteinden, is toewijzing niet vereist."outputFieldMappings"zijn voor velden die zijn gemaakt door vaardigheden, na uitvoering van de vaardighedenset. De verwijzingen naarsourceFieldNameinoutputFieldMappingsbestaan pas wanneer ze door kraken van het document of verrijking zijn gemaakt.targetFieldNameis een veld in een index dat in het indexschema is gedefinieerd.De
"maxFailedItems"parameter is ingesteld op -1, waarmee de indexeringsengine fouten tijdens het importeren van gegevens negeert. Dit is acceptabel omdat de demo-gegevensbron maar een paar documenten bevat. Voor een grotere gegevensbron zou u de waarde op groter dan 0 instellen.De
"dataToExtract":"contentAndMetadata"instructie vertelt de indexeerfunctie dat de waarden automatisch moeten worden geëxtraheerd uit de inhoudseigenschap van de blob en de metagegevens van elk object.De
imageActionparameter vertelt de indexeerfunctie om tekst te extraheren uit afbeeldingen die in de gegevensbron zijn gevonden. De configuratie van"imageAction":"generateNormalizedImages", OCR Skill en Text Merge Skill geeft de indexeerfunctie de opdracht om tekst uit de afbeeldingen te extraheren (bijvoorbeeld het woord 'stop' van een Stop-verkeersbord) en deze in te sluiten als onderdeel van het inhoudsveld. Dit gedrag is van toepassing op zowel ingesloten afbeeldingen (denk aan een afbeelding in een PDF) als zelfstandige afbeeldingsbestanden, bijvoorbeeld een JPG-bestand.
Notitie
Het maken van een indexeerfunctie roept de pijplijn aan. Als er problemen zijn met het bereiken van de gegevens, het toewijzen van invoeren en uitvoeren of de volgorde van bewerkingen, worden ze in deze fase weergegeven. Mogelijk moet u eerst objecten verwijderen om de pijplijn opnieuw uit te voeren met code- of scriptwijzigingen. Zie Reset and re-run (Opnieuw instellen en uitvoeren) voor meer informatie.
Het indexeren bewaken
Het indexeren en verrijken begint zodra u de aanvraag Indexeerfunctie maken hebt verzonden. Afhankelijk van de complexiteit en bewerkingen van vaardigheden kan het indexeren enige tijd duren.
Als u wilt weten of de indexeerfunctie nog steeds actief is, roept u Status van indexeerfunctie ophalen aan om de status van de indexeerfunctie te controleren.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Belangrijkste punten:
Waarschuwingen zijn gebruikelijk in sommige scenario's en geven niet altijd een probleem aan. Als een blobcontainer bijvoorbeeld afbeeldingsbestanden bevat en de pijplijn geen installatiekopieën verwerkt, krijgt u een waarschuwing waarin staat dat afbeeldingen niet zijn verwerkt.
In dit voorbeeld is er een PNG-bestand dat geen tekst bevat. Alle vijf de op tekst gebaseerde vaardigheden (taaldetectie, entiteitsherkenning van locaties, organisaties, personen en sleuteltermextractie) kunnen niet worden uitgevoerd op dit bestand. De resulterende melding wordt weergegeven in de uitvoeringsgeschiedenis.
Resultaten controleren
Nu u een index hebt gemaakt die door AI gegenereerde inhoud bevat, roept u Zoekdocumenten aan om enkele query's uit te voeren om de resultaten te bekijken.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Filters kunnen u helpen de resultaten te beperken tot interessante items:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Deze query's illustreren een aantal manieren waarop u met querysyntaxis en filters kunt werken voor nieuwe velden die zijn gemaakt door Azure AI Search. Zie Voorbeelden in Documenten zoeken (Azure Cognitive Search REST API), Voorbeelden van query's met eenvoudige syntaxisen Voorbeelden van volledige Lucene-query'svoor meer query voorbeelden.
Opnieuw instellen en uitvoeren
Tijdens een vroeg stadium van ontwikkeling is iteratie over het ontwerp gebruikelijk. Opnieuw instellen en opnieuw uitvoeren helpt bij iteratie.
Opgedane kennis
In deze zelfstudie ziet u de basisstappen voor het gebruik van de REST API's voor het maken van een AI-verrijkingspijplijn: een gegevensbron, vaardighedenset, index en indexeerfunctie.
Ingebouwde vaardigheden zijn geïntroduceerd, samen met de definitie van de vaardighedenset die de mechanica laat zien van het koppelen van vaardigheden via invoer en uitvoer. U hebt ook geleerd dat outputFieldMappings in de definitie van de indexeerfunctie is vereist voor het routeren van verrijkte waarden uit de pijplijn naar een doorzoekbare index op een Azure AI-Search-service.
Tot slot hebt u geleerd hoe u resultaten kunt testen en het systeem opnieuw kunt instellen voor verdere iteraties. U hebt geleerd dat het uitvoeren van query's op de index de uitvoer retourneert die is gemaakt door de pijplijn voor verrijkte indexering.
Resources opschonen
Wanneer u in uw eigen abonnement werkt, is het een goed idee om aan het einde van een project te bepalen of u de gemaakte resources nog steeds nodig hebt en of u deze moet verwijderen. Resources die actief blijven, kunnen u geld kosten. U kunt resources afzonderlijk verwijderen, maar u kunt ook de resourcegroep verwijderen als u de volledige resourceset wilt verwijderen.
U kunt resources vinden en beheren in de portal via de koppeling Alle resources of Resourcegroepen in het navigatiedeelvenster aan de linkerkant.
Volgende stappen
Nu u bekend bent met alle objecten in een AI-verrijkingspijplijn, gaat u dieper in op definities van vaardighedensets en afzonderlijke vaardigheden.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor