Scoreprofielen toevoegen om zoekscores te verhogen
Met scoreprofielen kunt u de rangorde van overeenkomende documenten verbeteren op basis van criteria. In dit artikel leert u hoe u een scoreprofiel opgeeft en toewijst waarmee een zoekscore wordt verhoogd op basis van parameters die u opgeeft.
U kunt scoreprofielen gebruiken voor trefwoordzoekopdrachten, vectorzoekopdrachten en hybride zoekopdrachten. Scoreprofielen zijn echter alleen van toepassing op niet-ctorvelden, dus zorg ervoor dat uw index tekst- of numerieke velden bevat die kunnen worden gebruikt in een scoreprofiel. Scoreprofielondersteuning voor vector- en hybride zoekopdrachten is beschikbaar in 2024-05-01-preview en 2024-07-01 REST API's en in Azure SDK-pakketten die gericht zijn op deze releases.
Belangrijke punten over scoreprofielen
Scoreprofielparameters zijn:
Gewogen velden, waarbij een overeenkomst wordt gevonden in een specifiek tekenreeksveld. U wilt bijvoorbeeld dat overeenkomsten in een samenvattingsveld relevanter zijn dan dezelfde overeenkomst die in een inhoudsveld is gevonden.
Functies voor numerieke gegevens, waaronder datums, bereiken en geografische coördinaten. Er is ook een functie Tags die werkt op een veld dat een willekeurige verzameling tekenreeksen biedt. U kunt deze benadering kiezen voor gewogen velden als u een score wilt verhogen op basis van of een overeenkomst wordt gevonden in een tagsveld.
U kunt meerdere profielen maken en vervolgens querylogica wijzigen om te kiezen welke wordt gebruikt.
U kunt maximaal 100 scoreprofielen binnen een index hebben (zie servicelimieten), maar u kunt slechts één profiel tegelijk opgeven in een bepaalde query.
U kunt een semantische rangschikking gebruiken met scoreprofielen. Wanneer er meerdere classificatie- of relevantiefuncties worden afgespeeld, is semantische rangschikking de laatste stap. Hoe het scoren van zoekopdrachten werkt , biedt een afbeelding.
Notitie
Onbekend met relevantieconcepten? Ga naar Relevantie en score in Azure AI Search voor achtergrond. U kunt dit videosegment ook bekijken op YouTube voor scoreprofielen boven bm25-gerangschikte resultaten.
Scoreprofieldefinitie
Een scoreprofiel is een benoemd object dat is gedefinieerd in een indexschema. Een scoreprofiel bestaat uit gewogen velden, functies en parameters.
De volgende definitie toont een eenvoudig profiel met de naam 'geo'. In dit voorbeeld worden de resultaten verhoogd met de zoekterm in het veld HotelName. Ook wordt de distance functie gebruikt om resultaten te bevorderen die zich binnen 10 kilometer van de huidige locatie bevinden. Als iemand op de term 'inn' zoekt en 'inn' deel uitmaakt van de naam van het hotel, worden documenten met hotels met 'inn' binnen een straal van 10 KM van de huidige locatie hoger weergegeven in de zoekresultaten.
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
Als u dit scoreprofiel wilt gebruiken, wordt uw query geformuleerd om de scoreProfile-parameter in de aanvraag op te geven. Als u de REST API gebruikt, worden query's opgegeven via GET- en POST-aanvragen. In het volgende voorbeeld heeft 'currentLocation' een scheidingsteken van één streepje (-). Het wordt gevolgd door lengte- en breedtegraadcoördinaten, waarbij lengtegraad een negatieve waarde is.
GET /indexes/hotels/docs?search+inn&scoringProfile=geo&scoringParameter=currentLocation--122.123,44.77233&api-version=2024-07-01
Let op de syntaxisverschillen bij het gebruik van POST. In POST is 'scoringParameters' meervoud en het is een matrix.
POST /indexes/hotels/docs&api-version=2024-07-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
Met deze query wordt gezocht naar de term 'inn' en wordt de huidige locatie doorgegeven. U ziet dat deze query andere parameters bevat, zoals scoringParameter. Queryparameters, waaronder scoringParameter, worden beschreven in Zoekdocumenten (REST API).
Zie het uitgebreide voorbeeld voor vector- en hybride zoekopdrachten en uitgebreid voorbeeld voor het zoeken naar trefwoorden voor meer scenario's.
Hoe zoeken scoren werkt in Azure AI Search
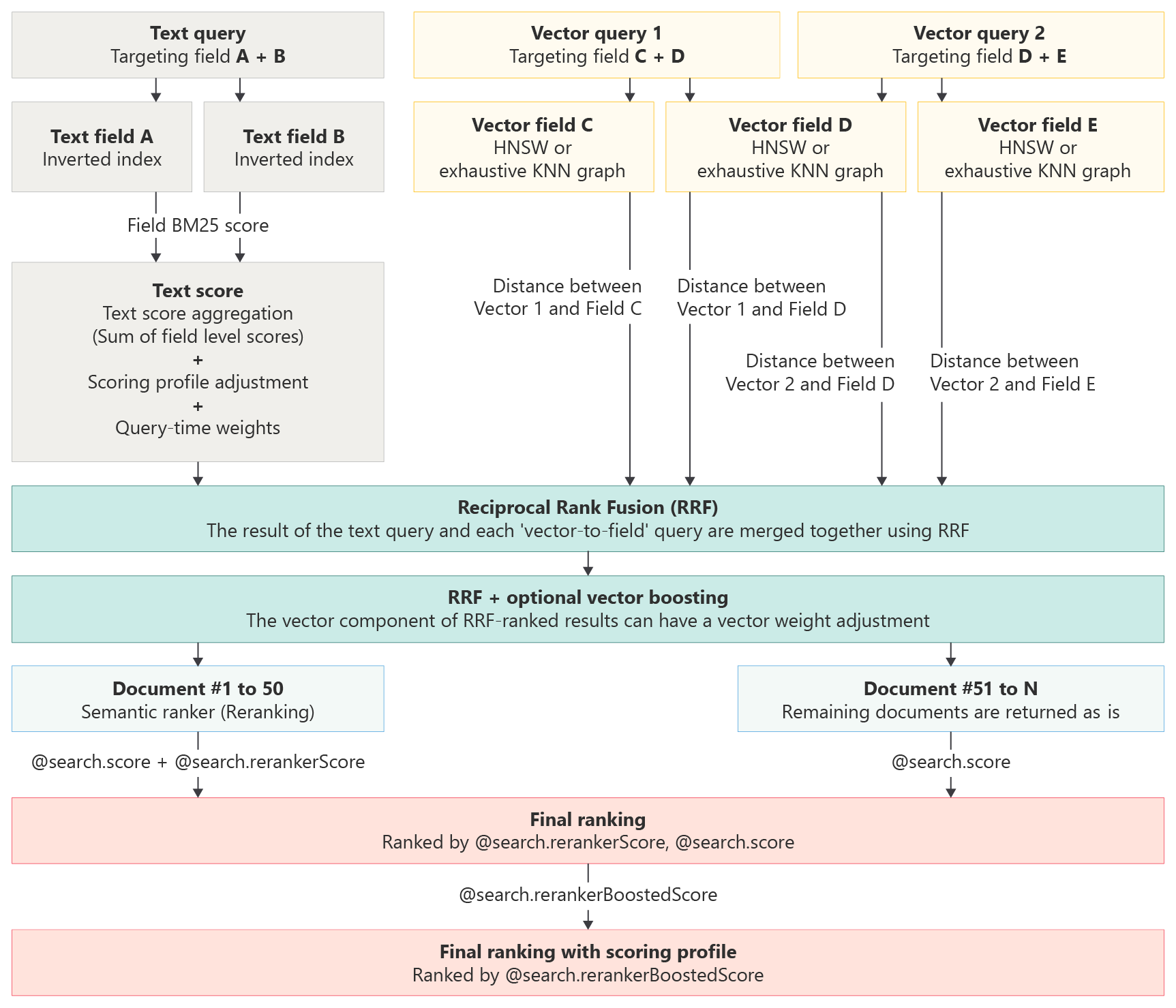
Scoreprofielen vormen een aanvulling op het standaardscore-algoritme door de scores van overeenkomsten te verbeteren die voldoen aan de criteria van het profiel. Scorefuncties zijn van toepassing op:
- Zoeken naar tekst (trefwoorden)
- Pure vectorquery's
- Hybride query's, waarbij subquery's voor tekst en vector parallel worden uitgevoerd
Voor zelfstandige tekstquery's identificeren scoreprofielen de maximum 1000 overeenkomsten in een bm25-gerangschikte zoekopdracht en worden de top 50 geretourneerd in de resultaten.
Voor pure vectoren is de query alleen vectoren, maar als de k-overeenkomende documenten alfanumerieke velden bevatten die een scoreprofiel kan verwerken, wordt een scoreprofiel toegepast. Het scoreprofiel wijzigt de resultatenset door documenten te stimuleren die voldoen aan criteria in het profiel.
Voor tekstquery's in een hybride query identificeren scoreprofielen de maximum 1000 overeenkomsten in een met BM25 gerangschikte zoekopdracht. Zodra deze 1000 resultaten echter zijn geïdentificeerd, worden ze hersteld naar hun oorspronkelijke BM25-volgorde, zodat ze naast vectoren kunnen worden geherscored, resulteert in de uiteindelijke volgorde van de rangorde van de rangschikkingsfunctie (RRF), waarbij het scoreprofiel (geïdentificeerd als 'definitieve documentverhoging aanpassing' in de afbeelding) wordt toegepast op de samengevoegde resultaten, samen met vectorgewicht en semantische rangschikking als de laatste stap.
Een scoreprofiel toevoegen aan een zoekindex
Begin met een indexdefinitie. U kunt scoreprofielen toevoegen en bijwerken op een bestaande index zonder dat u deze opnieuw hoeft op te bouwen. Gebruik een aanvraag index maken of bijwerken om een revisie te posten.
Plak de sjabloon in dit artikel.
Geef een naam op die voldoet aan naamconventies.
Geef boostcriteria op. Eén profiel kan tekstgewogen velden, functies of beide bevatten.
U moet iteratief werken met behulp van een gegevensset die u helpt de werkzaamheid van een bepaald profiel te bewijzen of te weer te geven.
Scoreprofielen kunnen worden gedefinieerd in Azure Portal, zoals wordt weergegeven in de volgende schermopname, of programmatisch via REST API's of in Azure SDK's , zoals de scoringProfile-klasse in de Azure SDK voor .NET.

Tekstgewogen velden gebruiken
Gebruik tekstgewogen velden wanneer veldcontext belangrijk is en query's tekenreeksvelden bevatten searchable . Als een query bijvoorbeeld de term 'airport' bevat, wilt u in het veld Beschrijving mogelijk meer gewicht hebben dan in hotelnaam.
Gewogen velden zijn naam-waardeparen die bestaan uit een searchable veld en een positief getal dat wordt gebruikt als vermenigvuldiger. Als de oorspronkelijke veldscore van HotelName 3 is, wordt de hogere score voor dat veld 6, wat bijdraagt aan een hogere algehele score voor het bovenliggende document zelf.
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
Functies gebruiken
Gebruik functies wanneer eenvoudige relatieve gewichten onvoldoende zijn of niet van toepassing zijn, zoals het geval is bij afstand en nieuwheid, wat berekeningen zijn voor numerieke gegevens. U kunt meerdere functies per scoreprofiel opgeven. Zie Ondersteunde gegevenstypen voor meer informatie over de EDM-gegevenstypen die worden gebruikt in Azure AI Search.
| Functie | Beschrijving | Gebruiksgevallen |
|---|---|---|
| afstand | Boost door nabijheid of geografische locatie. Deze functie kan alleen worden gebruikt met Edm.GeographyPoint velden. |
Gebruik deze optie voor scenario's in de buurt van mij. |
| frisheid | Verhogen op basis van waarden in een datum/tijd-veld (Edm.DateTimeOffset). Stel boostingDuration in om een waarde op te geven die een periode aangeeft waarvoor het stimuleren plaatsvindt. |
Gebruik deze optie als u wilt verbeteren door nieuwere of oudere datums. Rangschik items zoals agendagebeurtenissen met toekomstige datums, zodat items dichter bij het heden hoger kunnen worden gerangschikt dan items verder in de toekomst. Het ene uiteinde van het bereik is vastgezet aan de huidige tijd. Gebruik een positieve boostDuration om een reeks tijden in het verleden te stimuleren. Gebruik een negatieve boostDuration om een reeks tijden in de toekomst te stimuleren. |
| grootte | Classificaties wijzigen op basis van het bereik van waarden voor een numeriek veld. De waarde moet een geheel getal of een drijvendekommagetal zijn. Voor sterbeoordelingen van 1 tot en met 4 zou dit 1 zijn. Voor marges van meer dan 50%, zou dit 50 zijn. Deze functie kan alleen worden gebruikt met Edm.Double en Edm.Int velden. Voor de groottefunctie kunt u het bereik omkeren, hoog naar laag, als u het omgekeerde patroon wilt (bijvoorbeeld om lagere prijzen te verhogen dan items met een hogere prijs). Gezien een reeks prijzen van $ 100 tot $ 1, zou boostingRangeStart u instellen op 100 en boostingRangeEnd op 1 om de lager geprijsde items te verhogen. |
Gebruik dit wanneer u wilt verhogen op basis van winstmarge, waarderingen, clickthrough-tellingen, aantal downloads, hoogste prijs, laagste prijs of een telling van downloads. Wanneer twee items relevant zijn, wordt het item met de hogere classificatie eerst weergegeven. |
| tag | Boost door tags die gebruikelijk zijn om documenten en queryreeksen te doorzoeken. Tags worden opgegeven in een tagsParameter. Deze functie kan alleen worden gebruikt met zoekvelden van het type Edm.String en Collection(Edm.String). |
Gebruik deze functie wanneer u tagvelden hebt. Als een bepaalde tag in de lijst zelf een door komma's gescheiden lijst is, kunt u een tekstnormalisatiefunctie in het veld gebruiken om de komma's op het moment van de query te verwijderen (wijs het kommateken toe aan een spatie). Met deze benadering wordt de lijst afgevlakt, zodat alle termen één lange tekenreeks met door komma's gescheiden termen zijn. |
Regels voor het gebruik van functies
- Functies kunnen alleen worden toegepast op velden die worden toegeschreven als
filterable. - Het functietype ('freshness', 'magnitude', 'distance', 'tag') moet een kleine letter zijn.
- Functies kunnen geen null- of lege waarden bevatten.
- Functies kunnen slechts één veld per functiedefinitie hebben. Als u de grootte twee keer in hetzelfde profiel wilt gebruiken, geeft u twee definities op, één voor elk veld.
Template
In deze sectie ziet u de syntaxis en sjabloon voor scoreprofielen. Zie de REST API-verwijzing voor een beschrijving van de eigenschappen.
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference location)
"boostingDistance": # (the distance in kilometers from the reference location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
Interpolaties instellen
Interpolaties stellen de vorm van de helling in die wordt gebruikt voor scoren. Omdat scoren hoog tot laag is, neemt de helling altijd af, maar de interpolatie bepaalt de curve van de neerwaartse helling. De volgende interpolaties kunnen worden gebruikt:
| Interpolatie | Beschrijving |
|---|---|
linear |
Voor items die binnen het maximum- en minimumbereik vallen, wordt het stimuleren toegepast in een voortdurend afnemende hoeveelheid. Lineair is de standaardinterpolatie voor een scoreprofiel. |
constant |
Voor items die zich binnen het begin- en eindbereik bevinden, wordt een constante boost toegepast op de rangschikkingsresultaten. |
quadratic |
In vergelijking met een lineaire interpolatie die een voortdurend afnemende boost heeft, neemt quadratisch in eerste instantie in een kleiner tempo af en vervolgens naarmate het eindbereik nadert, neemt het af met een veel hoger interval. Deze interpolatieoptie is niet toegestaan in scorefuncties voor tags. |
logarithmic |
In vergelijking met een lineaire interpolatie die een voortdurend afnemende boost heeft, neemt logaritmisch in eerste instantie in een hoger tempo af en vervolgens naarmate het eindbereik nadert, neemt het af met een veel kleiner interval. Deze interpolatieoptie is niet toegestaan in scorefuncties voor tags. |

BoostDuration instellen voor versheidsfunctie
boostingDuration is een kenmerk van de freshness functie. U gebruikt deze om een verloopperiode in te stellen waarna het stimuleren stopt voor een bepaald document. Als u bijvoorbeeld een productlijn of merk wilt stimuleren voor een promotieperiode van 10 dagen, geeft u de periode van 10 dagen op als 'P10D' voor deze documenten.
boostingDuration moet worden opgemaakt als een XSD dayTimeDuration-waarde (een beperkte subset van een ISO 8601-duurwaarde). Het patroon hiervoor is: "P[nD][T[nH][nM][nS]]".
De volgende tabel bevat verschillende voorbeelden.
| Duur | boostDuration |
|---|---|
| 1 dag | "P1D" |
| 2 dagen en 12 uur | "P2DT12H" |
| 15 minuten | "PT15M" |
| 30 dagen, 5 uur, 10 minuten en 6,334 seconden | "P30DT5H10M6.334S" |
Zie XML-schema: Gegevenstypen (W3.org website) voor meer voorbeelden.
Uitgebreid voorbeeld voor vector en hybride zoekopdracht
Zie deze blogpost en notebook voor een demonstratie van het gebruik van scoreprofielen en het stimuleren van documenten in vector- en generatieve AI-scenario's.
Uitgebreid voorbeeld voor zoeken op trefwoorden
In het volgende voorbeeld ziet u het schema van een index met twee scoreprofielen (boostGenre, newAndHighlyRated). Elke query voor deze index die een profiel als queryparameter bevat, gebruikt het profiel om de resultatenset te scoren.
Het boostGenre profiel maakt gebruik van gewogen tekstvelden, het stimuleren van overeenkomsten in de velden albumTitle, genre en artistName. De velden worden respectievelijk verhoogd met 1,5, 5 en 2. Waarom is genre zo veel hoger dan de anderen? Als zoeken wordt uitgevoerd op gegevens die enigszins homogeen zijn (zoals het geval is met 'genre' in de musicstoreindex), hebt u mogelijk een grotere variantie in de relatieve gewichten nodig. In de musicstoreindex wordt 'rock' bijvoorbeeld weergegeven als een genre en in identieke genrebeschrijvingen. Als u het genre wilt opwegen tegen genrebeschrijving, heeft het genreveld een veel hoger relatieve gewicht nodig.
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [ "albumTitle", "artistName" ]
}
]
}