Betrouwbaarheid in Azure AI Search
In Azure betekent betrouwbaarheid tolerantie en beschikbaarheid als er sprake is van een servicestoring of afname. In Azure AI Search kan betrouwbaarheid worden bereikt binnen één service of via meerdere zoekservices in afzonderlijke regio's.
Implementeer één zoekservice en schaal omhoog voor hoge beschikbaarheid. U kunt meerdere replica's toevoegen om hogere indexering en queryworkloads af te handelen. Als uw zoekservice beschikbaarheidszones ondersteunt, worden replica's automatisch ingericht in verschillende fysieke datacenters voor extra tolerantie.
Implementeer meerdere zoekservices in verschillende geografische regio's. Alle zoekworkloads zijn volledig opgenomen in één service die wordt uitgevoerd in één geografische regio, maar in een scenario met meerdere services hebt u opties voor het synchroniseren van inhoud, zodat deze voor alle services hetzelfde is. U kunt ook een taakverdelingsoplossing instellen om aanvragen opnieuw te distribueren of een failover uit te voeren als er een servicestoring optreedt.
Plan voor bedrijfscontinuïteit en herstel na noodgevallen op regionaal niveau een cross-regional topologie, bestaande uit meerdere zoekservices met identieke configuratie en inhoud. Uw aangepaste script of code biedt het failovermechanisme voor een alternatieve zoekservice als er plotseling een niet meer beschikbaar is.
Hoge beschikbaarheid
In Azure AI Search zijn replica's kopieën van uw index. Een zoekservice wordt in gebruik genomen met ten minste één replica en kan maximaal 12 replica's bevatten. Door replica's toe te voegen, kan Azure AI Search machine opnieuw opstarten en onderhoud uitvoeren op één replica, terwijl de uitvoering van query's op andere replica's wordt voortgezet.
Voor elke afzonderlijke zoekservice garandeert Microsoft een beschikbaarheid van ten minste 99,9% voor configuraties die aan de volgende criteria voldoen:
Twee replica's voor hoge beschikbaarheid van alleen-lezen workloads (query's)
Drie of meer replica's voor hoge beschikbaarheid van lees-/schrijfworkloads (query's en indexering)
Het systeem heeft interne mechanismen voor het bewaken van de replicastatus en partitie-integriteit. Als u een specifieke combinatie van replica's en partities inricht, zorgt het systeem voor dat capaciteitsniveau voor uw service.
Er is geen SLA (Service Level Agreement) beschikbaar voor de gratis laag. Zie de SLA voor Azure AI Search voor meer informatie.
Ondersteuning voor beschikbaarheidszone
Beschikbaarheidszones zijn een Azure-platformmogelijkheid waarmee de datacenters van een regio worden verdeeld in afzonderlijke fysieke locatiegroepen om hoge beschikbaarheid te bieden binnen dezelfde regio. In Azure AI Search zijn afzonderlijke replica's de eenheden voor zonetoewijzing. Een zoekservice wordt uitgevoerd binnen één regio; de replica's worden uitgevoerd in verschillende fysieke datacenters (of zones) binnen die regio.
Beschikbaarheidszones worden gebruikt wanneer u twee of meer replica's toevoegt aan uw zoekservice. Elke replica wordt in een andere beschikbaarheidszone binnen de regio geplaatst. Als u meer replica's hebt dan beschikbare zones in de zoekserviceregio, worden de replica's zo gelijkmatig mogelijk verdeeld over zones. Er is geen specifieke actie op uw onderdeel, behalve om een zoekservice te maken in een regio die beschikbaarheidszones biedt en vervolgens de service te configureren voor het gebruik van meerdere replica's.
Vereisten
- De servicelaag moet Standard of hoger zijn
- De serviceregio moet zich in een regio bevinden met beschikbare zones (vermeld in de volgende sectie)
- Configuratie moet meerdere replica's bevatten: twee voor alleen-lezen queryworkloads, drie voor workloads met lezen/schrijven die indexering bevatten
Ondersteunde regio’s
Ondersteuning voor beschikbaarheidszones is afhankelijk van infrastructuur en opslag. Op dit moment heeft de volgende zone onvoldoende opslagruimte en biedt deze geen beschikbaarheidszone voor Azure AI Search:
- Japan - west
Anders worden beschikbaarheidszones voor Azure AI Search ondersteund in de volgende regio's:
| Regio | Implementatiedatum |
|---|---|
| Australië - oost | 30 januari 2021 of hoger |
| Brazilië - zuid | 2 mei 2021 of hoger |
| Canada - centraal | 30 januari 2021 of hoger |
| India - centraal | 20 januari 2022 of hoger |
| VS - centraal | 4 december 2020 of hoger |
| China - noord 3 | 7 september 2022 of hoger |
| Azië - oost | 13 januari 2022 of hoger |
| VS - oost | 27 januari 2021 of hoger |
| VS - oost 2 | 30 januari 2021 of hoger |
| Frankrijk - centraal | 23 oktober 2020 of hoger |
| Duitsland - west-centraal | 3 mei 2021 of hoger |
| Israël - centraal | 1 april 2024 of hoger |
| Italië - noord | 1 april 2024 of hoger |
| Japan - oost | 30 januari 2021 of hoger |
| Korea - centraal | 20 januari 2022 of hoger |
| Europa - noord | 28 januari 2021 of hoger |
| Noorwegen - oost | 20 januari 2022 of hoger |
| Qatar - centraal | 25 augustus 2022 of hoger |
| Zuid-Afrika - noord | 7 september 2022 of hoger |
| VS - zuid-centraal | 30 april 2021 of hoger |
| Azië - zuidoost | 31 januari 2021 of hoger |
| Zweden - centraal | 21 januari 2022 of hoger |
| Zwitserland - noord | 7 september 2022 of hoger |
| VAE - noord | 9 september 2022 of hoger |
| VK - zuid | 30 januari 2021 of hoger |
| VS (overheid) - Virginia | 30 april 2021 of hoger |
| Europa - west | 29 januari 2021 of hoger |
| VS - west 2 | 30 januari 2021 of hoger |
| VS - west 3 | 02 juni 2021 of hoger |
Notitie
In beschikbaarheidszones worden de voorwaarden van de SLA niet gewijzigd. U hebt nog steeds drie of meer replica's nodig voor hoge beschikbaarheid van query's.
Meerdere services in afzonderlijke geografische regio's
Serviceredundantie is nodig als uw operationele vereisten het volgende omvatten:
Vereisten voor bedrijfscontinuïteit en herstel na noodgevallen (BCDR). Azure AI Search biedt geen directe failover als er een storing is.
Snelle prestaties voor een wereldwijd gedistribueerde toepassing. Als query- en indexeringsaanvragen afkomstig zijn van over de hele wereld, ervaren gebruikers die zich het dichtst bij het hostdatacentrum bevinden snellere prestaties. Het maken van meer services in regio's met een nauwe nabijheid van deze gebruikers kan de prestaties voor alle gebruikers gelijkstellen.
Als u twee of meer zoekservices nodig hebt, kan het maken ervan in verschillende regio's voldoen aan de toepassingsvereisten voor continuïteit en herstel, en snellere reactietijden voor een globale gebruikersbasis.
Azure AI Search biedt geen geautomatiseerde methode voor het repliceren van zoekindexen in geografische regio's, maar er zijn enkele technieken waarmee dit proces eenvoudig kan worden geïmplementeerd en beheerd. Deze technieken worden beschreven in de volgende secties.
Het doel van een geografisch gedistribueerde set zoekservices is dat er twee of meer indexen beschikbaar zijn in twee of meer regio's, waarbij een gebruiker wordt doorgestuurd naar de Azure AI-Search-service die de laagste latentie biedt:
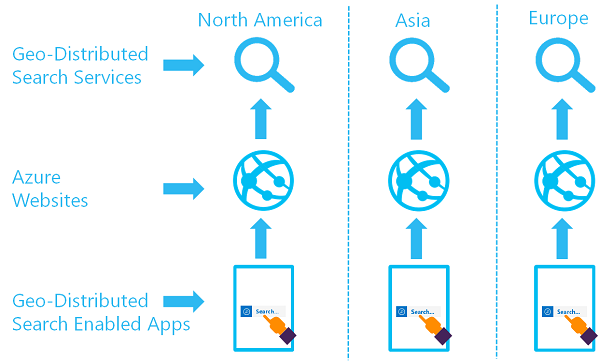
U kunt deze architectuur implementeren door meerdere services te maken en een strategie voor gegevenssynchronisatie te ontwerpen. U kunt eventueel een resource zoals Azure Traffic Manager opnemen voor routeringsaanvragen.
Tip
Voor hulp bij het implementeren van meerdere zoekservices in meerdere regio's raadpleegt u dit Bicep-voorbeeld op GitHub waarmee een volledig geconfigureerde, multi-regionale zoekoplossing wordt geïmplementeerd. Het voorbeeld biedt twee opties voor indexsynchronisatie en omleiding aanvragen met Traffic Manager.
Gegevens synchroniseren tussen meerdere services
Er zijn twee opties voor het synchroniseren van twee of meer afzonderlijke zoekservices:
- Inhoudsupdates ophalen in een zoekindex met behulp van een indexeerfunctie.
- Push inhoud naar een index met behulp van de REST-API (Add or Update Documents) of een equivalente API van Azure SDK.
Als u een van beide opties wilt configureren, raden we u aan het bicep-voorbeeldscript te gebruiken in de opslagplaats azure-search-multiple-region , gewijzigd in uw regio's en indexeringsstrategieën.
Optie 1: Indexeerfuncties gebruiken voor het bijwerken van inhoud op meerdere services
Als u al indexeerfunctie voor één service gebruikt, kunt u een tweede indexeerfunctie voor een tweede service configureren om hetzelfde gegevensbronobject te gebruiken, waarbij gegevens van dezelfde locatie worden opgehaald. Elke service in elke regio heeft een eigen indexeerfunctie en een doelindex (uw zoekindex wordt niet gedeeld, wat betekent dat elke index een eigen kopie van de gegevens heeft), maar elke indexeerfunctie verwijst naar dezelfde gegevensbron.
Hier volgt een visueel element op hoog niveau van hoe die architectuur eruit zou zien.
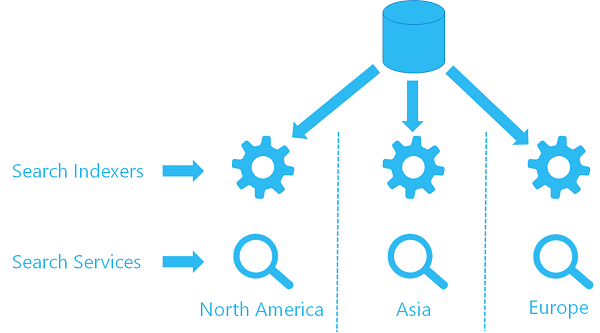
Optie 2: REST API's gebruiken voor het pushen van inhoudsupdates op meerdere services
Als u de REST API van Azure AI Search gebruikt om inhoud naar uw zoekindex te pushen, kunt u uw verschillende zoekservices synchroon houden door wijzigingen naar alle zoekservices te pushen wanneer een update is vereist. Zorg ervoor dat u in uw code gevallen afhandelt waarbij een update naar één zoekservice mislukt, maar wel slaagt voor andere zoekservices.
Failover- of omleidingsqueryaanvragen
Als u redundantie op aanvraagniveau nodig hebt, biedt Azure verschillende opties voor taakverdeling:
- Azure Traffic Manager, gebruikt voor het routeren van aanvragen naar meerdere geografische websites die vervolgens worden ondersteund door meerdere zoekservices.
- Application Gateway, die wordt gebruikt om de taakverdeling tussen servers in een regio op de toepassingslaag te verdelen.
- Azure Front Door, gebruikt om wereldwijde routering van webverkeer te optimaliseren en wereldwijde failover te bieden.
Enkele punten waarmee u rekening moet houden bij het evalueren van opties voor taakverdeling:
Zoeken is een back-endservice die query- en indexeringsaanvragen van een client accepteert.
Aanvragen van de client naar een zoekservice moeten worden geverifieerd. Voor toegang tot zoekbewerkingen moet de aanroeper machtigingen op basis van rollen hebben of een API-sleutel opgeven voor de aanvraag.
Service-eindpunten worden standaard bereikt via een openbare internetverbinding. Als u een privé-eindpunt instelt voor clientverbindingen die afkomstig zijn uit een virtueel netwerk, gebruikt u Application Gateway.
Azure AI Search accepteert aanvragen die zijn geadresseerd aan het
<your-search-service-name>.search.windows.neteindpunt. Als u hetzelfde eindpunt bereikt met behulp van een andere DNS-naam in de hostheader, zoals een CNAME, wordt de aanvraag geweigerd.
Azure AI Search biedt een implementatievoorbeeld voor meerdere regio's dat gebruikmaakt van Azure Traffic Manager voor omleiding van aanvragen als het primaire eindpunt mislukt. Deze oplossing is handig wanneer u routeert naar een client met zoekmogelijkheden die alleen een zoekservice in dezelfde regio aanroept.
Azure Traffic Manager wordt voornamelijk gebruikt voor het routeren van netwerkverkeer over verschillende eindpunten op basis van specifieke routeringsmethoden (zoals prioriteit, prestaties of geografische locatie). Het fungeert op DNS-niveau om binnenkomende aanvragen naar het juiste eindpunt te leiden. Als een eindpunt dat Traffic Manager onderhoudt begint met het weigeren van aanvragen, wordt verkeer doorgestuurd naar een ander eindpunt.
Traffic Manager biedt geen eindpunt voor een directe verbinding met Azure AI Search, wat betekent dat u geen zoekservice rechtstreeks achter Traffic Manager kunt plaatsen. In plaats daarvan wordt ervan uitgegaan dat aanvragen naar Traffic Manager stromen, vervolgens naar een webclient met zoekmogelijkheden en ten slotte naar een zoekservice op de back-end. De client en service bevinden zich in dezelfde regio. Als één zoekservice uitvalt, mislukt de zoekclient en wordt Traffic Manager omgeleid naar de resterende client.
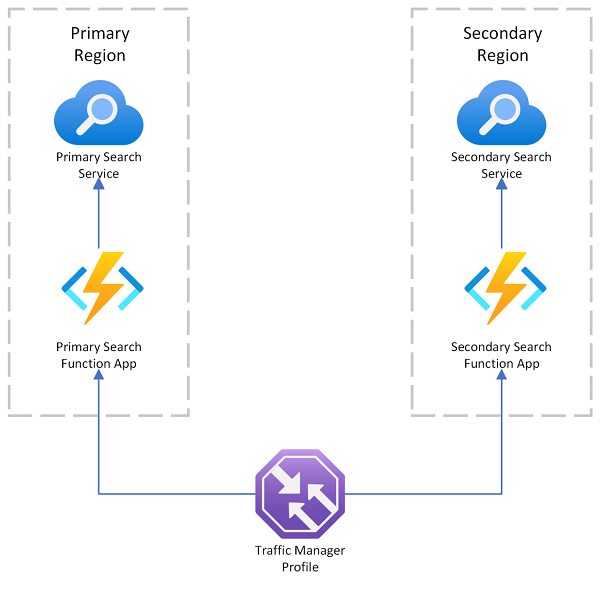
Gegevenslocatie in een implementatie met meerdere regio's
Wanneer u meerdere zoekservices in verschillende geografische regio's implementeert, wordt uw inhoud opgeslagen in de regio die u voor elke zoekservice hebt gekozen.
Azure AI Search slaat geen gegevens op buiten uw opgegeven regio zonder uw autorisatie. Autorisatie is impliciet wanneer u functies gebruikt die schrijven naar een Azure Storage-resource: verrijkingscache, foutopsporingssessie, kennisarchief. In alle gevallen is het opslagaccount een account dat u opgeeft, in de regio van uw keuze.
Notitie
Als zowel het opslagaccount als de zoekservice zich in dezelfde regio bevinden, gebruikt netwerkverkeer tussen zoeken en opslag een privé-IP-adres en vindt plaats via het Backbone-netwerk van Microsoft. Omdat privé-IP-adressen worden gebruikt, kunt u geen IP-firewalls of een privé-eindpunt configureren voor netwerkbeveiliging. Gebruik in plaats daarvan de uitzondering voor vertrouwde services als alternatief wanneer beide services zich in dezelfde regio bevinden.
Over servicestoringen en onherstelbare gebeurtenissen
Zoals vermeld in de SLA garandeert Microsoft een hoge beschikbaarheid voor indexqueryaanvragen wanneer een Azure AI-Search-service-exemplaar is geconfigureerd met twee of meer replica's en indexupdateaanvragen wanneer een Azure AI-Search-service-exemplaar is geconfigureerd met drie of meer replica's. Er is echter geen ingebouwd mechanisme voor herstel na noodgevallen. Als continue service vereist is in het geval van een onherstelbare fout buiten de controle van Microsoft, raden we u aan om een tweede service in een andere regio in te richten en een strategie voor geo-replicatie te implementeren om ervoor te zorgen dat indexen volledig redundant zijn in alle services.
Klanten die indexeerfuncties gebruiken om indexen te vullen en te vernieuwen, kunnen herstel na noodgevallen verwerken via geospecifieke indexeerfuncties die gegevens ophalen uit dezelfde gegevensbron. Twee services in verschillende regio's, die elk een indexeerfunctie uitvoeren, kunnen dezelfde gegevensbron indexeren om georedundantie te bereiken. Als u indexeert uit gegevensbronnen die ook geografisch redundant zijn, moet u er rekening mee houden dat indexeerfuncties van Azure AI Search alleen incrementele indexering kunnen uitvoeren (updates uit nieuwe, gewijzigde of verwijderde documenten samenvoegen) uit primaire replica's. In een failover-gebeurtenis moet u de indexeerfunctie omleiden naar de nieuwe primaire replica.
Als u geen indexeerfuncties gebruikt, gebruikt u uw toepassingscode om objecten en gegevens parallel naar verschillende zoekservices te pushen. Zie Gegevens synchroniseren tussen meerdere services voor meer informatie.
Alternatieven voor back-ups maken en herstellen
Een strategie voor bedrijfscontinuïteit voor de gegevenslaag bevat meestal een herstel-van-back-upstap. Omdat Azure AI Search geen primaire oplossing voor gegevensopslag is, biedt Microsoft geen formeel mechanisme voor selfserviceback-up en herstel. U kunt echter de voorbeeldcode indexback-up-restore gebruiken in deze Voorbeeldopslagplaats van Azure AI Search .NET om een back-up te maken van uw indexdefinitie en momentopname naar een reeks JSON-bestanden en deze bestanden vervolgens gebruiken om de index te herstellen, indien nodig. Dit hulpprogramma kan ook indexen tussen servicelagen verplaatsen.
Anders is de toepassingscode die wordt gebruikt voor het maken en vullen van een index de feitelijke hersteloptie als u per ongeluk een index verwijdert. Als u een index opnieuw wilt opbouwen, verwijdert u deze (ervan uitgaande dat deze bestaat), maakt u de index opnieuw in de service en laadt u deze opnieuw door gegevens op te halen uit uw primaire gegevensarchief.
Gerelateerde inhoud
- Bekijk servicelimieten voor meer informatie over de prijscategorieën en servicelimieten.
- Bekijk het plan voor capaciteit voor meer informatie over partitie- en replicacombinaties.
- Casestudy bekijken : Cognitive Search gebruiken ter ondersteuning van complexe AI-scenario's voor meer configuratierichtlijnen.