Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Vectoren zijn high-dimensionale insluitingen die tekst, afbeeldingen en andere inhoud wiskundig vertegenwoordigen. Azure AI Search slaat vectoren op veldniveau op, waardoor vector- en niet-vectorinhoud naast elkaar kunnen bestaan binnen dezelfde zoekindex.
Een zoekindex wordt een vectorindex wanneer u vectorvelden en een vectorconfiguratie definieert. Als u vectorvelden wilt vullen, kunt u vooraf ingevulde insluitingen pushen of geïntegreerde vectorisatie gebruiken, een ingebouwde Azure AI Search-functie waarmee insluitingen worden gegenereerd tijdens het indexeren.
Tijdens query's maken de vectorvelden in uw index overeenkomsten zoeken mogelijk, waarbij het systeem documenten ophaalt waarvan de vectoren het meest lijken op de vectorquery. U kunt vectorzoeken voor uitsluitend overeenkomsten gebruiken of hybride zoeken voor een combinatie van overeenkomsten en trefwoordmatching.
In dit artikel worden de belangrijkste concepten besproken voor het maken en beheren van een vectorindex, waaronder:
- Patronen voor vectoropvragingen
- Inhoud (vectorvelden en configuratie)
- Fysieke gegevensstructuur
- Basisbewerkingen
Aanbeveling
Wilt u meteen aan de slag? Zie Een vectorindex maken.
Patronen voor vectoropvragingen
Azure AI Search ondersteunt twee patronen voor het ophalen van vectoren:
Klassieke zoekopdracht. Dit patroon maakt gebruik van een zoekbalk, query-invoer en weergegeven resultaten. Tijdens het uitvoeren van query's wordt de invoer van de gebruiker door de zoekmachine of uw toepassingscode gevectoraliseerd. De zoekmachine voert vervolgens vectorzoekopdrachten uit op de vectorvelden in uw index en formuleert een antwoord dat u in een client-app weergeeft.
In Azure AI Search worden resultaten geretourneerd als een afgevlakte rijset en kunt u kiezen welke velden u wilt opnemen in het antwoord. Hoewel de zoekmachine werkt met vectoren, moet uw index wel niet-vector, voor mensen leesbare inhoud bevatten om de zoekresultaten te kunnen tonen. Klassieke zoekopdrachten ondersteunen zowel vectorquery's als hybride query's.
Generatief zoeken. Taalmodellen gebruiken gegevens van Azure AI Search om te reageren op gebruikersquery's. Een indelingslaag coördineert doorgaans prompts en onderhoudt context, waardoor zoekresultaten worden ingevoerd in chatmodellen zoals GPT. Dit patroon is gebaseerd op de retrieval-augmented generation (RAG) architectuur, waarin de zoekindex de benodigde gegevens levert.
Schema van een vectorindex
Voor het schema van een vectorindex is het volgende vereist:
- Naam
- Sleutelveld (tekenreeks)
- Een of meer vectorvelden
- Vectorconfiguratie
Niet-vectorvelden zijn niet vereist, maar we raden u aan deze op te nemen voor hybride query's of voor het teruggeven van letterlijke inhoud die geen taalmodel doorloopt. Zie Een vectorindex maken voor meer informatie.
Het indexschema moet het patroon voor het ophalen van vectoren weerspiegelen. In deze sectie wordt voornamelijk aandacht besteed aan veldsamenstelling voor klassieke zoekopdrachten, maar het bevat ook schemarichtlijnen voor generatieve zoekopdrachten.
Basisvectorveldconfiguratie
Vectorvelden hebben unieke gegevenstypen en eigenschappen. Hier ziet u hoe een vectorveld eruitziet in een veldenverzameling:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Alleen bepaalde gegevenstypen worden ondersteund voor vectorvelden. Het meest voorkomende type is Collection(Edm.Single), maar het gebruik van compacte typen kan opslagruimte besparen.
Vectorvelden moeten doorzoekbaar en ophaalbaar zijn, maar ze kunnen niet worden gefilterd, facetabel of sorteerbaar. Ze kunnen ook geen analyses, normalizers of synoniemtoewijzingen hebben.
De dimensions eigenschap moet worden ingesteld op het aantal insluitingen dat wordt gegenereerd door het insluitingsmodel. Met tekst-insluiten-ada-002 worden bijvoorbeeld 1536 insluitingen gegenereerd voor elk stuk tekst.
Vectorvelden worden geïndexeerd met behulp van algoritmen die zijn opgegeven in een vectorzoekprofiel, dat elders in de index is gedefinieerd en niet wordt weergegeven in dit voorbeeld. Zie Een vectorzoekconfiguratie toevoegen voor meer informatie.
Verzameling velden voor basisvectorwerklasten
Vectorindexen vereisen meer dan alleen vectorvelden. Alle indexen moeten bijvoorbeeld een sleutelveld hebben, dat id zich in het volgende voorbeeld bevindt:
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Andere velden, zoals het content veld, bieden het leesbare equivalent van het content_vector veld. Als u taalmodellen uitsluitend gebruikt voor antwoordformulering, kunt u niet-ctorinhoudsvelden weglaten, maar oplossingen die zoekresultaten rechtstreeks naar client-apps pushen, moeten niet-ctorinhoud hebben.
Metagegevensvelden zijn handig voor filters, met name als ze broninformatie over het brondocument bevatten. Hoewel u niet rechtstreeks op een vectorveld kunt filteren, kunt u prefilter- of postfiltermodi instellen om te filteren voor of na de uitvoering van vectorquery's.
Schema gegenereerd door de wizard Gegevens importeren en vectoriseren
We raden de wizard Gegevens importeren en vectoriseren aan voor evaluatie en proof-of-concept-tests. De wizard genereert het voorbeeldschema in deze sectie.
De wizard segmenteert uw inhoud in kleinere zoekdocumenten, wat ten goede komt aan RAG-apps die taalmodellen gebruiken om reacties te formuleren. Segmentering helpt u binnen de invoerlimieten van taalmodellen en de tokenlimieten van semantische rangschikking te blijven. Het verbetert ook de precisie in overeenkomsten zoeken door query's te vergelijken met segmenten die zijn opgehaald uit meerdere bovenliggende documenten. Zie Documenten opdelen voor vectorzoekoplossingen voor meer informatie.
Voor elk zoekdocument in het volgende voorbeeld is er één segment-id, bovenliggende id, segment, titel en vectorveld. De wizard:
Hiermee worden de
chunk_idenparent_idvelden gevuld met base64-gecodeerde blobmetagegevens (pad).Extraheert respectievelijk de
chunkentitlevelden uit de blob-inhoud en de blobnaam.Hiermee maakt u het
vectorveld door een Azure OpenAI-insluitmodel aan te roepen dat u opgeeft om hetchunkveld te vectoriseren. Alleen het vectorveld wordt tijdens dit proces volledig gegenereerd.
"name": "example-index-from-import-wizard",
"fields": [
{ "name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Schema voor generatieve zoekopdracht
Als u vectoropslag ontwerpt voor RAG- en chat-apps, kunt u twee indexen maken:
- Een voor statische inhoud die u hebt geïndexeerd en gevectoriseerd.
- Een voor gesprekken die kunnen worden gebruikt in promptstromen.
Ter illustratie gebruikt deze sectie de chat-with-your-data-solution-accelerator om de chat-index en conversations indexen te maken.
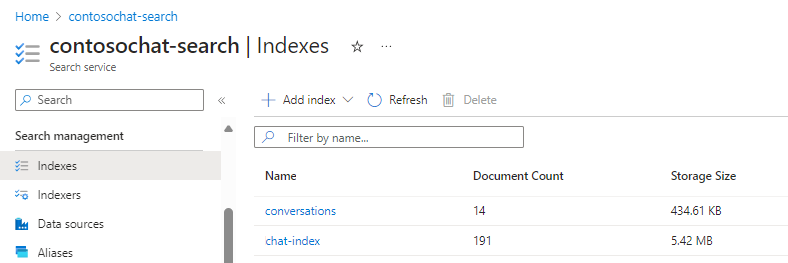
De volgende velden van chat-index ondersteunen generatieve zoekervaringen:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
De volgende velden van conversations ondersteunen orkestratie en chatgeschiedenis:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
In de volgende schermopname ziet u zoekresultaten in conversationsSearch Explorer:
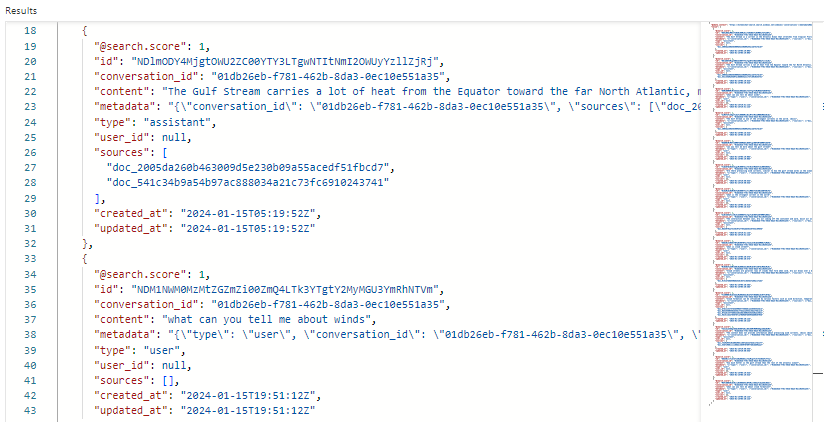
In ons voorbeeld is de zoekscore 1,00 omdat de zoekopdracht niet gekwalificeerd is. Verschillende velden ondersteunen orkestratie- en promptstromen.
-
conversation_ididentificeert elke chatsessie. -
typegeeft aan of de inhoud afkomstig is van de gebruiker of de assistent. -
created_atenupdated_atverwijderen chats na verloop van tijd uit de geschiedenis.
Fysieke structuur en grootte
In Azure AI Search is de fysieke structuur van een index grotendeels een interne implementatie. U kunt toegang krijgen tot het schema, de inhoud laden en er query's op uitvoeren, de grootte ervan bewaken en de capaciteit ervan beheren. Microsoft beheert echter de infrastructuur en fysieke gegevensstructuren die zijn opgeslagen met uw zoekservice.
De grootte en inhoud van een index worden bepaald door:
Hoeveelheid en samenstelling van uw documenten.
Kenmerken voor afzonderlijke velden. Er is bijvoorbeeld meer opslagruimte vereist voor filterbare velden.
Indexconfiguratie, inclusief de vectorconfiguratie die aangeeft hoe de interne navigatiestructuren worden gemaakt. U kunt HNSW of uitgebreide KNN kiezen voor overeenkomsten zoeken.
Azure AI Search legt limieten op voor vectoropslag, waarmee u een evenwichtig en stabiel systeem voor alle workloads kunt onderhouden. Om u te helpen onder de limieten te blijven, wordt vectorgebruik afzonderlijk bijgehouden en gerapporteerd in Azure Portal en programmatisch via service- en indexstatistieken.
In de volgende schermopname ziet u een S1-service die is geconfigureerd met één partitie en één replica. Deze service heeft 24 kleine indexen, elk met een gemiddelde van één vectorveld dat bestaat uit 1536 insluitingen. Op de tweede tegel ziet u het quotum en het gebruik voor vectorindexen. Omdat een vectorindex een interne gegevensstructuur is die voor elk vectorveld is gemaakt, is opslag voor vectorindexen altijd een fractie van de totale opslag die door de index wordt gebruikt. Niet-vectorvelden en andere gegevensstructuren verbruiken de rest.
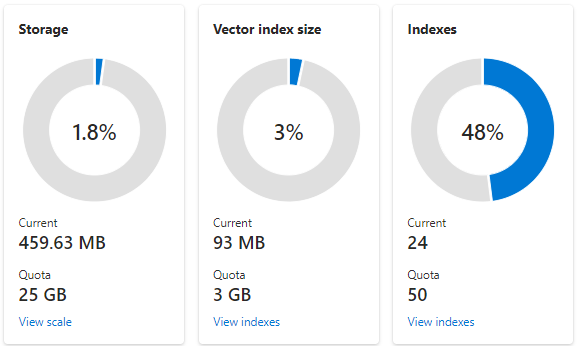
Vectorindexlimieten en schattingen worden behandeld in een ander artikel, maar twee punten om te benadrukken zijn dat maximale opslag afhankelijk is van de aanmaakdatum en prijscategorie van uw zoekservice. Nieuwere services met dezelfde laag hebben aanzienlijk meer capaciteit voor vectorindexen. Om deze redenen moet u het volgende doen:
Controleer de aanmaakdatum van uw zoekservice. Als deze vóór 3 april 2024 is gemaakt, kunt u uw service mogelijk upgraden voor een grotere capaciteit.
Kies een schaalbare laag als u schommelingen in vectoropslagvereisten verwacht. Voor oudere zoekdiensten is de Basic-laag vastgesteld op één partitie. Overweeg Standard 1 (S1) en hoger voor meer flexibiliteit en snellere prestaties. In de preview-versie 2025-02-01 kunt u ook overschakelen van een lagere laag naar een hogere laag.
Basisbewerkingen en interactie
In deze sectie worden vectorruntimebewerkingen geïntroduceerd, waaronder verbinding maken met en beveiligen van één index.
Notitie
Er is geen portal- of API-ondersteuning voor het verplaatsen of kopiëren van een index. Normaal gesproken verwijst u de implementatie van uw toepassing naar een andere zoekservice (met dezelfde indexnaam) of wijzigt u de naam om een kopie te maken in uw huidige zoekservice en bouwt u deze vervolgens.
Indexisolatie
In Azure AI Search werkt u met één index tegelijk. Alle indexgerelateerde bewerkingen zijn gericht op één index. Er is geen concept van gerelateerde indexen of het samenvoegen van onafhankelijke indexen voor indexering of query's.
Continu beschikbaar
Er is direct een index beschikbaar voor query's zodra het eerste document is geïndexeerd, maar het is pas volledig operationeel als alle documenten zijn geïndexeerd. Intern wordt een index verdeeld over partities en wordt uitgevoerd op replica's. De fysieke index wordt intern beheerd. U beheert de logische index.
Een index is continu beschikbaar en kan niet worden onderbroken of offline gehaald. Omdat het is ontworpen voor continue werking, worden updates van de inhoud en toevoegingen aan de index zelf in realtime uitgevoerd. Als een aanvraag samenvalt met een documentupdate, kunnen query's tijdelijk onvolledige resultaten retourneren.
Querycontinuïteit bestaat voor documentbewerkingen, zoals vernieuwen of verwijderen, en voor wijzigingen die geen invloed hebben op de bestaande structuur of integriteit van een index, zoals het toevoegen van nieuwe velden. Structurele updates, zoals het wijzigen van bestaande velden, worden doorgaans beheerd met behulp van een werkstroom voor neerzetten en herbouwen in een ontwikkelomgeving of door een nieuwe versie van de index in de productieservice te maken.
Om te voorkomen dat een index opnieuw wordt opgebouwd, kiezen sommige klanten die kleine wijzigingen aanbrengen ervoor om een veld te "versiebeheren" door een nieuw veld te maken dat naast een eerdere versie bestaat. Na verloop van tijd leidt dit tot zwevende inhoud door middel van verouderde velden en verouderde aangepaste analysedefinities, met name in een productieindex die duur is om te repliceren. U kunt deze problemen oplossen tijdens geplande updates van de index als onderdeel van het levenscyclusbeheer van de index.
Eindpuntverbinding
Alle vectorindexerings- en queryaanvragen richten zich op een index. Eindpunten zijn meestal een van de volgende:
| Eindpunt | Verbinding en toegangsbeheer |
|---|---|
<your-service>.search.windows.net/indexes |
Is gericht op de verzameling indexen. Wordt gebruikt bij het maken, weergeven of verwijderen van een index. Beheerdersrechten zijn vereist voor deze bewerkingen en zijn beschikbaar via beheerders-API-sleutels of een rol van Zoeken-bijdrager. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Richt zich op de documentenverzameling van een enkele index. Wordt gebruikt bij het uitvoeren van query's op een index of gegevensvernieuwing. Voor query's zijn leesrechten voldoende en beschikbaar via query-API-sleutels of een rol van gegevenslezer. Voor het vernieuwen van gegevens zijn beheerdersrechten vereist. |
Verbinding maken met Azure AI Search
Zorg ervoor dat u over machtigingen of een API-toegangssleutel beschikt. Tenzij u een query uitvoert op een bestaande index, hebt u beheerdersrechten of een roltoewijzing Inzender nodig om inhoud in een zoekservice te beheren en weer te geven.
Begin met Azure Portal. De persoon die de zoekservice heeft gemaakt, kan deze bekijken en beheren, inclusief het verlenen van toegang aan anderen op de pagina Toegangsbeheer (IAM).
Schakel over naar andere klanten voor programmatische toegang. Voor de eerste stappen raden we quickstart aan: Vector search using REST and the azure-search-vector-samples repo.
Vectorarchieven beheren
Azure biedt een bewakingsplatform met diagnostische logboekregistratie en waarschuwingen. U wordt aangeraden dat u:
- Schakel diagnostische logboekregistratie in.
- Waarschuwingen instellen.
- Prestaties van query's en indexen analyseren.
Beveiligde toegang tot vectorgegevens
Azure AI Search implementeert gegevensversleuteling, privéverbindingen voor scenario's zonder internet en roltoewijzingen voor beveiligde toegang via Microsoft Entra-id. Zie Beveiliging in Azure AI Search voor meer informatie over bedrijfsbeveiligingsfuncties.