Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Inleiding
De Toegewezen SQL-poolconnector van Azure Synapse voor Apache Spark in Azure Synapse Analytics maakt een efficiënte overdracht van grote gegevenssets mogelijk tussen de Apache Spark-runtime en de toegewezen SQL-pool. De connector wordt geleverd als een standaardbibliotheek met Azure Synapse-werkruimte. De connector wordt geïmplementeerd met behulp van Scala taal. De connector ondersteunt Scala en Python. Als u de connector wilt gebruiken met andere taalkeuzes voor notebooks, gebruikt u de Spark Magic-opdracht - %%spark.
Op hoog niveau biedt de connector de volgende mogelijkheden:
- Lezen uit de toegewezen SQL-pool van Azure Synapse:
- Lees grote gegevenssets uit Synapse Dedicated SQL-pooltabellen (intern en extern) en weergaven.
- Uitgebreide ondersteuning voor predicaat-naar-beneden, waarbij filters op DataFrame worden omgezet in de bijbehorende SQL-predicaat-naar-beneden.
- Ondersteuning voor het snoeien van kolommen.
- Ondersteuning voor het doordrukken van query's.
- Schrijven naar een toegewezen SQL-pool van Azure Synapse:
- Gegevens van grote volumes opnemen in interne en externe tabeltypen.
- Ondersteunt de volgende voorkeuren voor de opslagmodus van DataFrame:
AppendErrorIfExistsIgnoreOverwrite
- Schrijven naar een extern tabeltype ondersteunt de Parquet- en gescheiden tekstbestandsindeling (bijvoorbeeld CSV).
- Als u gegevens naar interne tabellen wilt schrijven, gebruikt de connector nu de COPY-instructie in plaats van de CETAS-/CTAS-benadering.
- Verbeteringen voor het optimaliseren van end-to-end schrijfdoorvoerprestaties.
- Introduceert een optionele call-back-handle (een scala-functieargument) die clients kunnen gebruiken om metrische gegevens na schrijven te ontvangen.
- Enkele voorbeelden zijn: het aantal records, de duur voor het voltooien van een bepaalde actie en de reden van de fout.
Orkestratiebenadering
Lezen
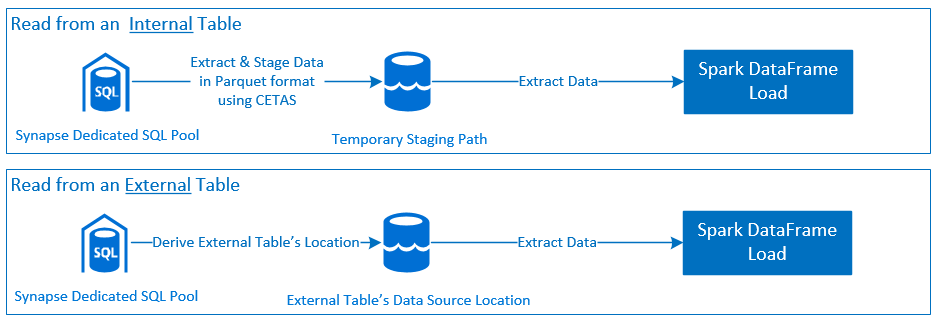
Schrijven
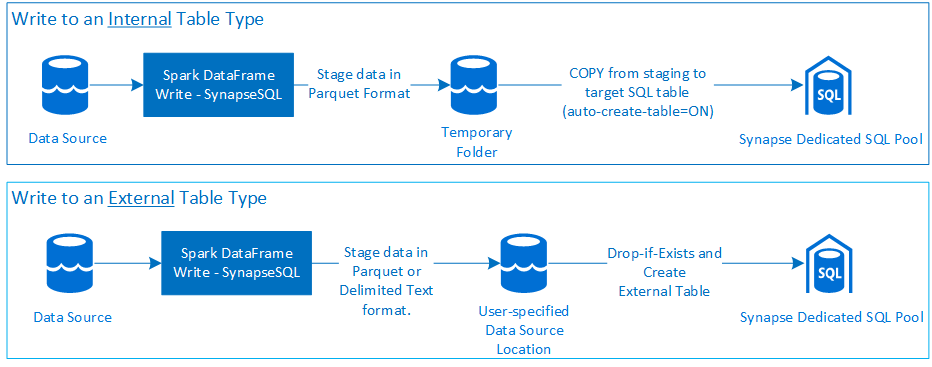
Vereiste voorwaarden
Vereisten, zoals het instellen van vereiste Azure-resources en stappen voor het configureren ervan, worden in deze sectie besproken.
Azure-hulpmiddelen
Controleer en stel de volgende afhankelijke Azure-resources in:
- Azure Data Lake Storage : wordt gebruikt als het primaire opslagaccount voor de Azure Synapse-werkruimte.
- Azure Synapse-werkruimte : notebooks maken, op DataFrame gebaseerde werkstromen voor inkomend verkeer maken en implementeren.
- Toegewezen SQL-pool (voorheen SQL DW): biedt enterprise-Databeheersysteem-functies.
- Serverloze Spark-pool van Azure Synapse - Spark-runtime waarin de taken worden uitgevoerd als Spark-toepassingen.
De database voorbereiden
Maak verbinding met de Synapse Dedicated SQL-pooldatabase en voer de volgende installatie-instructies uit:
Maak een databasegebruiker die is toegewezen aan de Microsoft Entra-gebruikersidentiteit die wordt gebruikt om u aan te melden bij de Azure Synapse-werkruimte.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Maak een schema waarin tabellen worden gedefinieerd, zodat de connector kan schrijven naar en lezen vanuit respectieve tabellen.
CREATE SCHEMA [<schema_name>];
Verificatie
Verificatie op basis van Microsoft Entra-id
Verificatie op basis van Microsoft Entra ID is een geïntegreerde verificatiemethode. De gebruiker moet zich aanmelden bij de Azure Synapse Analytics-werkruimte.
Basisverificatie
Voor een basisverificatiebenadering moet de gebruiker de opties username en password instellen. Raadpleeg de sectie - Configuratieopties voor meer informatie over relevante configuratieparameters voor het lezen van en schrijven naar tabellen in Azure Synapse Dedicated SQL-pool.
Autorisatie
Azure Data Lake Storage Gen2
Er zijn twee manieren om toegangsmachtigingen te verlenen aan Azure Data Lake Storage Gen2 - Opslagaccount:
- Rol voor rolgebaseerde toegangscontrole - Storage Blob Data Contributor-rol
- Door de
Storage Blob Data Contributor Roletoe te wijzen, krijgt de gebruiker machtigingen om te lezen, te schrijven en te verwijderen uit de Azure Storage Blob-containers. - RBAC biedt een benadering voor grof beheer op containerniveau.
- Door de
-
Toegangsbeheerlijsten (ACL)
- Met de ACL-aanpak kunt u nauwkeurige controle toepassen op specifieke paden en/of bestanden onder een bepaalde map.
- ACL-controles worden niet afgedwongen als de gebruiker al machtigingen krijgt met behulp van de RBAC-benadering.
- Er zijn twee algemene typen ACL-machtigingen:
- Toegangsmachtigingen (op een specifiek niveau of object toegepast).
- Standaardmachtigingen (automatisch toegepast op alle subobjecten wanneer ze worden gemaakt).
- Het type machtigingen zijn onder andere:
-
Executemaakt het mogelijk om door de mappenhiërarchieën te navigeren. -
Readmaakt het mogelijk om te lezen. -
Writemaakt het mogelijk om te schrijven.
-
- Het is belangrijk om ACL's te configureren, zodat de connector kan schrijven en lezen vanaf de opslaglocaties.
Notitie
Als u notebooks wilt gebruiken met behulp van Synapse Workspace-pijplijnen, moet u ook de hierboven vermelde toegangsmachtigingen verlenen aan de standaard-beheerde identiteit van de Synapse-werkruimte. De standaardnaam van de beheerde identiteit van de werkruimte is hetzelfde als de naam van de werkruimte.
Als u de Synapse-werkruimte wilt gebruiken met beveiligde opslagaccounts, moet een beheerd privé-eindpunt worden geconfigureerd vanuit het notebook. Het beheerde privé-eindpunt moet worden goedgekeurd uit de
Private endpoint connectionssectie van het ADLS Gen2-opslagaccount in hetNetworkingdeelvenster.
Toegewezen SQL-pool van Azure Synapse
Als u een succesvolle interactie met een toegewezen SQL-pool van Azure Synapse wilt inschakelen, is de volgende autorisatie nodig, tenzij u een gebruiker bent die ook als een Active Directory Admin is geconfigureerd op het Dedicated SQL Eindpunt:
Scenario lezen
Verleen de gebruiker
db_exportertoegang met de door het systeem opgeslagen proceduresp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Scenario schrijven
- Connector gebruikt het COPY-commando om gegevens van de tussenopslag naar de beheerde locatie van de interne tabel te schrijven.
Configureer de vereiste machtigingen die hier worden beschreven.
Hier volgt een snel toegangsfragment van hetzelfde:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- Connector gebruikt het COPY-commando om gegevens van de tussenopslag naar de beheerde locatie van de interne tabel te schrijven.
API-documentatie
Azure Synapse Dedicated SQL Pool Connector voor Apache Spark - API-documentatie.
Configuratieopties
Om de lees- of schrijfbewerking op te starten en te organiseren, verwacht de connector bepaalde configuratieparameters. De objectdefinitie: com.microsoft.spark.sqlanalytics.utils.Constants biedt een lijst met gestandaardiseerde constanten voor elke parametersleutel.
Hieronder volgt de lijst met configuratieopties op basis van gebruiksscenario:
-
Lezen met verificatie op basis van Microsoft Entra ID
- Referenties worden automatisch toegewezen, en de gebruiker hoeft geen specifieke configuratieopties op te geven.
- Driedelige tabelnaamargument voor de
synapsesql-methode is vereist om de respectieve tabel te lezen in de Dedicated SQL Pool van Azure Synapse.
-
Lezen met basisverificatie
- Toegewezen SQL-eindpunt van Azure Synapse
-
Constants.SERVER- Eindpunt van toegewezen SQL-pool synapse (server-FQDN) -
Constants.USER- SQL-gebruikersnaam. -
Constants.PASSWORD- SQL-gebruikerswachtwoord.
-
- Eindpunt van Azure Data Lake Storage (Gen 2) - Stagingmappen
-
Constants.DATA_SOURCE- Het opslagpad dat is ingesteld op de locatieparameter van de gegevensbron wordt gebruikt voor het faseren van gegevens.
-
- Toegewezen SQL-eindpunt van Azure Synapse
-
Schrijven met verificatie op basis van Microsoft Entra ID
- Toegewezen SQL-eindpunt van Azure Synapse
- De Connector bepaalt standaard het Dedicated SQL-eindpunt van Synapse met behulp van de databasenaam die is ingesteld op de parameter voor de driedelige tabelnaam van de
synapsesqlmethode. - Gebruikers kunnen ook de
Constants.SERVERoptie gebruiken om het SQL-eindpunt op te geven. Zorg ervoor dat het eindpunt als host fungeert voor de bijbehorende database met het respectieve schema.
- De Connector bepaalt standaard het Dedicated SQL-eindpunt van Synapse met behulp van de databasenaam die is ingesteld op de parameter voor de driedelige tabelnaam van de
- Eindpunt van Azure Data Lake Storage (Gen 2) - Stagingmappen
- Voor intern tabeltype:
-
Constants.TEMP_FOLDERConfigureer een van beide ofConstants.DATA_SOURCEopties. - Als de gebruiker ervoor heeft gekozen de optie
Constants.DATA_SOURCEop te geven, wordt de faseringsmap afgeleid door gebruik te maken van delocation-waarde uit de DataSource. - Als beide zijn opgegeven, wordt de
Constants.TEMP_FOLDERoptiewaarde gebruikt. - Als er geen optie voor een tijdelijke map is, zal de connector er een afleiden op basis van de runtime-configuratie -
spark.sqlanalyticsconnector.stagingdir.prefix.
-
- Voor extern tabeltype:
-
Constants.DATA_SOURCEis een vereiste configuratieoptie. - De connector maakt gebruik van het opslagpad dat is ingesteld op de locatieparameter van de gegevensbron in combinatie met het
locationargument voor desynapsesqlmethode en leidt het absolute pad af om externe tabelgegevens op te slaan. - Als het argument voor
locationdesynapsesqlmethode niet is opgegeven, wordt de locatiewaarde door de connector afgeleid als<base_path>/dbName/schemaName/tableName.
-
- Voor intern tabeltype:
- Toegewezen SQL-eindpunt van Azure Synapse
-
Schrijven met basisverificatie
- Toegewezen SQL-eindpunt van Azure Synapse
-
Constants.SERVER- Synapse Toegewezen SQL-pooleindpunt (server-FQDN). -
Constants.USER- SQL-gebruikersnaam. -
Constants.PASSWORD- SQL-gebruikerswachtwoord. -
Constants.STAGING_STORAGE_ACCOUNT_KEYgekoppeld aan opslagaccount dat als host fungeertConstants.TEMP_FOLDERS(alleen interne tabeltypen) ofConstants.DATA_SOURCE.
-
- Eindpunt van Azure Data Lake Storage (Gen 2) - Stagingmappen
- Sql-basisverificatiereferenties zijn niet van toepassing op toegang tot opslageindpunten.
- Zorg er daarom voor dat u relevante machtigingen voor opslagtoegang toewijst, zoals beschreven in de sectie Azure Data Lake Storage Gen2.
- Toegewezen SQL-eindpunt van Azure Synapse
Codesjablonen
In deze sectie vindt u referentiecodesjablonen om te beschrijven hoe u de Toegewezen SQL-poolconnector van Azure Synapse voor Apache Spark gebruikt en aanroept.
Notitie
De connector gebruiken in Python-
- De connector wordt alleen ondersteund in Python voor Spark 3. Zie gematerialiseerde gegevens in cellen gebruiken.
- De callbackmechanisme is niet beschikbaar in Python.
Lezen uit de toegewezen SQL-pool van Azure Synapse
Leesverzoek - synapsesql methodehandtekening
Lezen uit een tabel met verificatie op basis van Microsoft Entra-id
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Lezen uit een query met behulp van verificatie op basis van Microsoft Entra ID
Notitie
Beperkingen tijdens het lezen van query's:
- Tabelnaam en query kunnen niet tegelijkertijd worden opgegeven.
- Alleen bepaalde query's zijn toegestaan. DDL- en DML-MCL's zijn niet toegestaan.
- De opties voor selecteren en filteren in het dataframe worden niet naar de toegewezen SQL-pool gepusht wanneer een query wordt opgegeven.
- Lezen vanuit een query is alleen beschikbaar in Spark 3.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Lezen uit een tabel met basisverificatie
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Lezen uit een query met basisverificatie
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Schrijven naar toegewezen SQL-pool van Azure Synapse
Schrijfaanvraag - synapsesql methodesignatuur
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Schrijven met verificatie op basis van Microsoft Entra ID
Hieronder volgt een uitgebreide codesjabloon waarin wordt beschreven hoe u de connector gebruikt voor schrijfscenario's:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Schrijven met basisverificatie
Met het volgende codefragment wordt de schrijfdefinitie vervangen die wordt beschreven in de sectie Schrijven met behulp van verificatie op basis van Microsoft Entra ID, om schrijfaanvragen in te dienen met behulp van de basisverificatiemethode van SQL:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
Voor een basisverificatiemethode zijn andere configuratieopties vereist om gegevens uit een bronopslagpad te lezen. Het volgende codefragment biedt een voorbeeld om te lezen uit een Azure Data Lake Storage Gen2-gegevensbron met behulp van service-principalreferenties:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Ondersteunde dataframe-opslagmodi
De volgende opslagmodi worden ondersteund bij het schrijven van brongegevens naar een doeltabel in een toegewezen SQL-pool van Azure Synapse:
- ErrorIfExists (standaard opslaanmodus)
- Als de doeltabel bestaat, wordt de schrijfbewerking afgebroken met een foutmelding die wordt teruggestuurd naar de aanroeper. Anders wordt er een nieuwe tabel gemaakt met gegevens uit de faseringsmappen.
- Negeren
- Als de doeltabel bestaat, negeert de schrijfbewerking de schrijfaanvraag zonder een fout te retourneren. Anders wordt er een nieuwe tabel gemaakt met gegevens uit de faseringsmappen.
- Overschrijven
- Als de doeltabel bestaat, worden bestaande gegevens in de bestemming vervangen door gegevens uit de tussenliggende mappen. Anders wordt er een nieuwe tabel gemaakt met gegevens uit de faseringsmappen.
- Toevoegen
- Als de doeltabel bestaat, worden de nieuwe gegevens eraan toegevoegd. Anders wordt er een nieuwe tabel gemaakt met gegevens uit de faseringsmappen.
Callback-handle voor schrijfaanvraag
Met de nieuwe api voor schrijfpadwijzigingen is een experimentele functie geïntroduceerd om de client een sleutelwaardetoewijzing> van metrische gegevens na schrijven te bieden. Sleutels voor de metrische gegevens worden gedefinieerd in de nieuwe objectdefinitie - Constants.FeedbackConstants. Metrische gegevens kunnen worden opgehaald als een JSON-tekenreeks door de callback-handle te gebruiken (a Scala Function). Hier volgt de functiehandtekening:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
Hieronder volgen enkele belangrijke metrische gegevens (gepresenteerd in kameel geval):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Hier volgt een voorbeeld van een JSON-tekenreeks met metrische gegevens na schrijven:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
Meer codevoorbeelden
Gematerialiseerde gegevens over cellen heen gebruiken
Spark DataFrame's createOrReplaceTempView kunnen worden gebruikt voor toegang tot gegevens die zijn opgehaald in een andere cel door een tijdelijke weergave te registreren.
- Cel waarin gegevens worden opgehaald (bijvoorbeeld met notebook-taalvoorkeur als
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Wijzig nu de taalvoorkeur in het notitieblok in
PySpark (Python)en haal gegevens op uit de geregistreerde weergave<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Verwerking van antwoorden
Aanroepen synapsesql heeft twee mogelijke eindstatussen: geslaagd of mislukt. In deze sectie wordt beschreven hoe u het aanvraagantwoord voor elk scenario kunt verwerken.
Antwoord op aanvraag lezen
Na voltooiing wordt het leesantwoordfragment weergegeven in de uitvoer van de cel. Als de huidige cel niet werkt, worden ook volgende celuitvoeringen geannuleerd. Gedetailleerde foutinformatie is beschikbaar in de Spark-toepassingslogboeken.
Antwoord van schrijfaanvraag
Standaard wordt een bevestiging van de schrijfactie weergegeven in de uitvoer van de cel. Bij een fout wordt de huidige cel gemarkeerd als mislukt en worden de volgende celuitvoeringen afgebroken. De andere methode is het doorgeven van de callback-handleoptie aan de synapsesql methode. De callback-handle biedt programmeerbare toegang tot de schrijfreactie.
Andere overwegingen
- Wanneer u leest vanuit de tabellen met toegewezen SQL-pool van Azure Synapse:
- Overweeg om de benodigde filters toe te passen op het DataFrame om te profiteren van de kolomsnoeifunctie van de Connector.
- Leesscenario biedt geen ondersteuning voor de
TOP(n-rows)clausule bij het formuleren van deSELECT-queryopdrachten. De keuze om gegevens te beperken, is door de component limit(.) van het DataFrame te gebruiken.- Verwijs naar het voorbeeld - De sectie "Het gebruik van gematerialiseerde gegevens over cellen heen".
- Wanneer u naar de toegewezen SQL-pooltabellen van Azure Synapse schrijft:
- Voor interne tabeltypen:
- Tabellen worden gemaakt met ROUND_ROBIN gegevensdistributie.
- Kolomtypen worden afgeleid uit het DataFrame dat gegevens uit de bron zou lezen. Tekenreekskolommen worden toegewezen aan
NVARCHAR(4000).
- Voor externe tabeltypen:
- De initiële parallelle uitvoering van DataFrame bepaalt de gegevensorganisatie voor de externe tabel.
- Kolomtypen worden afgeleid uit het DataFrame dat gegevens uit de bron zou lezen.
- Een betere gegevensdistributie over uitvoerders kan worden bereikt door de
spark.sql.files.maxPartitionBytesen derepartitionparameter van het DataFrame af te stemmen. - Bij het schrijven van grote gegevenssets is het belangrijk om rekening te houden met de impact van dwU-prestatieniveau dat de transactiegrootte beperkt.
- Voor interne tabeltypen:
- Bewaak de gebruikstrends van Azure Data Lake Storage Gen2 om beperkingsgedrag te herkennen dat de lees- en schrijfprestaties kan beïnvloeden.