Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: ✓ Ongestructureerde documentverwerking
Volg de instructies in Een model maken in Syntex om een ongestructureerd documentverwerkingsmodel te maken in een inhoudscentrum. Of volg de instructies in Een model maken op een lokale SharePoint-site om het model op een lokale site te maken. Begin vervolgens met dit artikel om te beginnen met het trainen van uw model.
Een classificatie maken
Een classificatie is een typemodel dat je kunt gebruiken om de identificatie en classificatie van een documenttype te automatiseren.
Je wilt mogelijk alle documenten voor Contractvernieuwing wilt identificeren die zijn toegevoegd aan de documentbibliotheek, zoals weergegeven in de volgende afbeelding.

Als je een classificatie maakt, kun je een nieuw SharePoint-inhoudstype maken dat aan het model wordt gekoppeld.
Bij het maken van de classificatie moet je uitleg maken om het model te definiëren. Met deze stap kunt u algemene gegevens noteren die u verwacht dit documenttype consistent te vinden.
Gebruik voorbeelden van het documenttype (' voorbeeldbestanden') om het model te trainen om bestanden met hetzelfde inhoudstype te identificeren.
Om een classificatie te maken, moet je:
- Geef het model een naam.
- Voeg je voorbeeldbestanden toe.
- Label je voorbeeldbestanden.
- Maak een uitleg.
- Test uw model.
Opmerking
Hoewel je model een classificatie gebruikt om documenttypen te identificeren en te classificeren, kun je er ook voor kiezen om specifieke gegevens te verzamelen uit elk bestand dat door het model wordt aangeduid. Dit doe je door een Extractor te maken om toe te voegen aan je model. ZieEen extractor maken.
Geef het model een naam
De eerste stap voor het maken van een model is het geven van een naam:
Selecteer in het inhoudscentrum De optie Nieuw en vervolgens Model.
Selecteer op de pagina Opties voor het maken van een modelde optie Methode onderwijzen.
Selecteer volgende op de pagina Lesmethode: Details.
Typ op de pagina Een model maken met de lesmethode in het veld Modelnaam de naam van het model. Als je bijvoorbeeld documenten voor het verlengen van het contract wilt identificeren, kun je het model Contractverlenging noemen.
Kies Create. Met deze actie maakt u een startpagina voor het model.
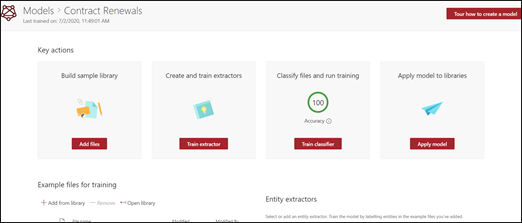
Wanneer u een model maakt, maakt u ook een nieuw site-inhoudstype. Een inhoudstype is een categorie documenten met gemeenschappelijke kenmerken en een verzameling kolommen of metagegevenseigenschappen voor die inhoud delen. SharePoint-inhoudstypen worden beheerd via de Galerie met inhoudstypen. In dit voorbeeld maakt u een nieuw inhoudstype contractverlenging wanneer u het model maakt.
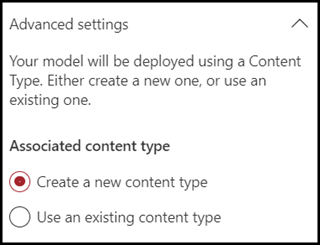
Selecteer Geavanceerde instellingen als u dit model wilt toewijzen aan een bestaand ondernemingsinhoudstype in de sharePoint-galerie Inhoudstype om het bijbehorende schema te gebruiken. Ondernemingsinhoudtypen worden opgeslagen in de hub inhoudstype in het SharePoint-Beheercentrum en worden gepubliceerd naar alle sites in de Tenant. Hoewel u een bestaand inhoudstype kunt gebruiken om het schema te gebruiken om te helpen bij identificatie en classificatie, moet u uw model nog steeds trainen om informatie te extraheren uit bestanden die het identificeert.
Voeg je voorbeeldbestanden toe
Voeg op de startpagina van het model uw voorbeeldbestanden toe die u nodig hebt om het model te trainen om uw documenttype te identificeren.
Opmerking
Je moet dezelfde bestanden gebruiken voor zowel classificatie als Extractor-training. Je kunt altijd later meer toevoegen, maar meestal voeg je een volledige set voorbeeldbestanden toe. Geef een naam op voor je model en test de resterende niet-gelabelde om model geschiktheid te evalueren.
Voor het instellen van je training wil je zowel positieve als negatieve voorbeelden gebruiken:
- Positief voorbeeld: documenten die het documenttype voorstellen. Dit zijn tekenreeksen en informatie die altijd in dit type document voorkomen.
- Negatief voorbeeld: elk ander document dat niet het document vertegenwoordigt dat u wilt classificeren.
Zorg ervoor dat je minimaal vijf positieve voorbeelden gebruikt en ten minste één negatief voorbeeld om het model te trainen. U wilt nog een model maken om uw model na het trainingsproces te testen.
Om voorbeeldbestanden toe te voegen:
Selecteer op de startpagina van het model in de tegel Voorbeeldbestanden toevoegende optie Bestanden toevoegen.
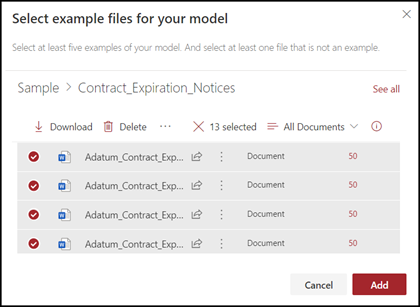
Selecteer op de pagina Voorbeeldbestanden voor je model de optie bestanden uit de bibliotheek van trainingsbestanden in het inhoudscentrum. Als u ze daar nog niet had geüpload, kiest u ervoor om ze nu te uploaden door op Uploaden te klikken om ze te kopiëren naar de bibliotheek Trainingsbestanden.
Nadat u de voorbeeldbestanden hebt geselecteerd die u wilt gebruiken om het model te trainen, selecteert u Toevoegen.
Label je voorbeeldbestanden
Nadat je de voorbeeldbestanden hebt toegevoegd, moet je ze een label geven als positieve of negatieve voorbeelden.
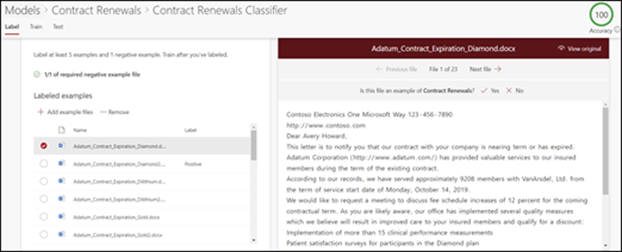
Selecteer op de startpagina van het model op de tegel Bestanden classificeren en training uitvoerende optie Classificatie trainen. In deze stap wordt de labelpagina weergegeven met een lijst met uw voorbeeldbestanden, waarbij het eerste bestand zichtbaar is in de viewer.
In de viewer boven aan het eerste voorbeeldbestand zie je tekst waarin je wordt gevraagd of het bestand een voorbeeld is van het model dat je zojuist hebt gemaakt. Als het een positief voorbeeld is, selecteert u Ja. Als het een negatief voorbeeld is, selecteert u Nee.
Klik in de lijst met gelabelde voorbeelden aan de linkerkant op extra bestanden die je als voorbeeld wilt gebruiken en voorzie ze van een label.
Opmerking
Voorzie ten minste vijf positieve voorbeelden van labels. Je moet ook een label aan ten minste één negatief voorbeeld geven.
Maak een uitleg
In de volgende stap wordt uitgelegd hoe je op de pagina Train een uitleg maakt. Met een uitleg wordt het model uitgelegd hoe je het document kunt herkennen. De documenten voor het verlengen van een contract bevatten bijvoorbeeld altijd een Verzoek om aanvullende informatie tekenreeks.
Opmerking
Als je een verklaring gebruikt met uittreksels, wordt de tekenreeks die je wilt ophalen uit het document geïdentificeerd.
Maak een uitleg:
Op de startpagina van het model selecteer je het tabblad Train om naar de pagina Train te gaan.
Op de pagina Train kun je in de sectie Getrainde bestanden een lijst zien met de voorbeeldbestanden waaraan je eerder een label hebt gegeven. Selecteer een van de positieve bestanden uit de lijst en deze wordt weergegeven in de viewer.
In de sectie uitleg selecteert je Nieuw en vervolgens Leeg.
Op de pagina Een uitleg maken :
a. Typ de Naam(bijvoorbeeld "uitnamelijst").
b. Selecteer het Type. Voor het voorbeeld selecteer je lijst met frasenomdat je een tekenreeks toevoegt.
c. Typ de tekenreeks in het vak Type hier. Voor het voorbeeld moet je „verzoek om aanvullende informatie“ toe voegen. Je kunt hoofdlettergevoeligheid selecteren als de tekenreeks hoofdlettergevoelig moet zijn.
d. Klik op Opslaan.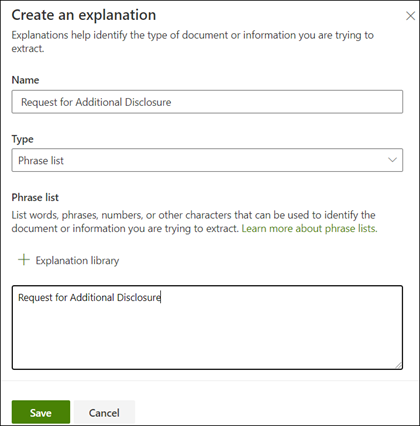
Het inhoudscentrum controleert nu of de uitleg die je hebt gemaakt compleet genoeg is om de overige gelabelde voorbeeldbestanden op de juiste manier te identificeren als positieve en negatieve voorbeelden. Schakel in de sectie Getrainde bestanden de kolom Evaluatie nadat de training voltooid is om de resultaten weer te geven. De bestanden geven de waarde Overeenkomst weer als de verklaringen die je hebt gemaakt voldoende zijn om aan te geven wat je als positief of negatief hebt gemarkeerd.
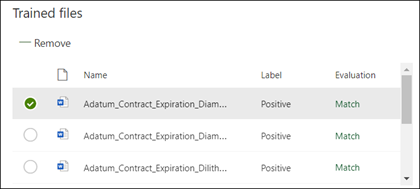
Als je een Discrepantie ontvangt voor de gelabelde bestanden, moet je mogelijk extra uitleg opgeven om het model meer informatie te geven om het documenttype te identificeren. Als er een niet-overeenkomende fout optreedt, selecteert u het bestand voor meer informatie over waarom de niet-overeenkomende fout is opgetreden.
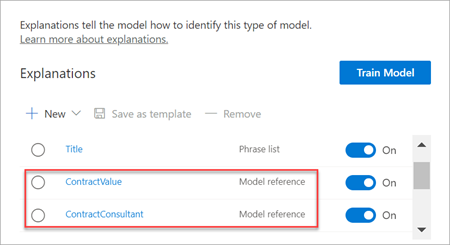
Van zodra je de extractor getraind hebt, kan deze gebruikt worden als een uitleg. In de sectie Uitleg wordt dit weergegeven als Modelreferentie.
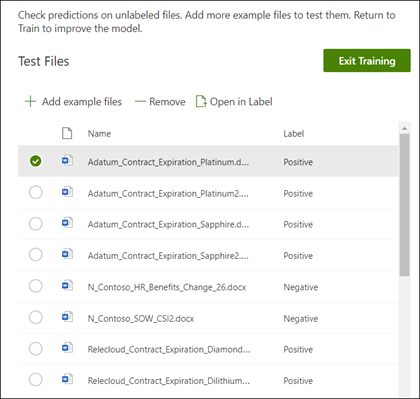
Test je model.
Als u een overeenkomst hebt ontvangen voor uw gelabelde voorbeeldbestanden, kunt u uw model nu testen op de resterende niet-gelabelde voorbeeldbestanden die het model nog niet eerder heeft gezien. Deze stap is optioneel, maar een handige stap om de 'geschiktheid' of gereedheid van het model te evalueren voordat u het gebruikt, door het te testen op bestanden die het model nog niet eerder heeft gezien.
Op de startpagina van het model selecteer je het tabblad Testen. Hiermee wordt het model uitgevoerd op de niet-gelabelde voorbeeldbestanden.
In de lijst Testbestanden worden de voorbeeldbestanden weergegeven en weergegeven als het model deze positief of negatief is. Gebruik deze informatie om de effectiviteit van je classificatie bij het identificeren van je documenten vast te stellen.