Een extractor maken in Microsoft Syntex
Van toepassing op: ✓ Ongestructureerde documentverwerking
Vóór of na het maken van een classificatiemodel voor het automatiseren van de identificatie en classificatie van specifieke documenttypen, kun je desgewenst extra uittreksels toevoegen aan je model om specifieke informatie uit deze documenten te halen. U wilt bijvoorbeeld dat uw model niet alleen alle Contractverlengingsdocumenten identificeert die zijn toegevoegd aan uw documentbibliotheek, maar ook dat de servicestartdatum voor elk document wordt weergegeven als kolomwaarde in de documentbibliotheek.
Je moet een extractor maken voor elke entiteit in het document die je wilt ophalen. In ons voorbeeld willen we de begindatum van de service extraheren voor elk document voor contractverlenging dat wordt geïdentificeerd door het model. We willen een weergave kunnen zien in de documentbibliotheek van alle documenten voor contractverlenging , met een kolom met de waarde voor de begindatum van de service van elk document.
Opmerking
Als u een extractor wilt maken, gebruikt u dezelfde bestanden die u eerder hebt geüpload om de classificatie te trainen.
Een naam voor de Extractor geven
Selecteer op de startpagina van het model in de tegel Extractoren maken en trainende optie Extractor trainen.
Typ in het scherm New entiteit Extractor de naam van je extractor in het veld Nieuwe extractorname. Als je bijvoorbeeld de begindatum van de service wilt wijzigen als je de begindatum van de service wilt ophalen uit elk document voor het verlengen van een contract. Je kunt er ook voor kiezen om een eerder gemaakte kolom opnieuw te gebruiken (bijvoorbeeld een kolom met beheerde metagegevens).
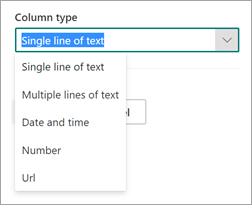
Standaard is het kolomtype Één regel tekst. Als u het kolomtype wilt wijzigen, selecteert u Geavanceerde instellingen>Kolomtype en selecteert u vervolgens het type dat u wilt gebruiken.
Opmerking
Voor extractoren met het kolomtype Eén tekstregel is de maximale tekenlimiet 255. Tekens die u selecteert die de limiet overschrijden, worden afgekapt. Als u meer dan 255 tekens wilt selecteren, kiest u het kolomtype Meerdere regels tekst bij het maken van de extractor.
Standaard worden meerdere regels tekstkolommen gemaakt met een limiet voor de hoeveelheid tekst die kan worden toegevoegd. In dit geval kan geëxtraheerde tekst afgekapt worden weergegeven. Als dit gebeurt, kan de kolominstelling Onbeperkte lengte in documentbibliotheken toestaan worden gebruikt om de limiet te verwijderen.
Wanneer u klaar bent, selecteert u Maken.
Een label toevoegen
De volgende stap bestaat uit het label van de entiteit die je wilt ophalen in de voorbeeldbestanden van de training.
Als je de Extractor maakt, wordt de extractor-pagina geopend. Hier zie je een lijst met je voorbeeldbestanden, met het eerste bestand in de lijst die wordt weergegeven in de viewer.
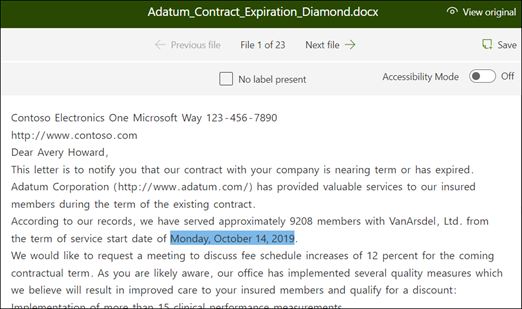
Selecteer in de viewer de gegevens die je wilt ophalen uit de bestanden. Als u bijvoorbeeld de beginservicedatum wilt extraheren, markeert u de datumwaarde in het eerste bestand (maandag 14 oktober 2022). en selecteert u vervolgens Opslaan. De weergave van de waarde wordt weergegeven in het bestand in de lijst voorbeelden met een bijschrift onder de labelkolom.
Selecteer Volgend bestand om automatisch op te slaan en open het volgende bestand in de lijst in de viewer. Of selecteer Opslaan en selecteer een ander bestand van de lijst Gelabelde voorbeelden.
Herhaal stap 1 en 2 in de viewer en herhaal dit totdat je het label in alle vijf bestanden hebt opgeslagen.
Wanneer je vijf bestanden hebt voorzien van een label, wordt een melding weergegeven met de mededeling dat je wilt overstappen op de training. Je kunt ervoor kiezen om meer documenten beter te labelen of verder te gaan met de training.
Zoeken gebruiken om in je bestand te zoeken
Je kunt de functie Zoeken gebruiken om te zoeken naar een entiteit in je document, dat je van een label wilt voorzien.
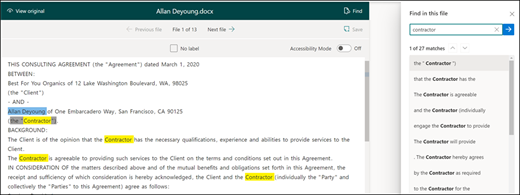
De functie Zoeken is handig als u in een groot document zoekt of als er meerdere exemplaren van de entiteit in het document zijn. Als je meerdere exemplaren hebt gevonden, kun je in de zoekresultaten het exemplaar selecteren dat je nodig hebt om naar die locatie in de viewer te gaan en dat exemplaar van een label te voorzien.
Voeg een uitleg toe
Voor ons voorbeeld gaan we een uitleg maken die een hint geeft over de entiteitsindeling zelf en de variaties die deze kunnen hebben in de voorbeelddocumenten. Een datumwaarde kan bijvoorbeeld verschillende notaties hebben, zoals:
- 10/14/2022
- dinsdag 14 oktober 2022
- Maandag 14 oktober 2022
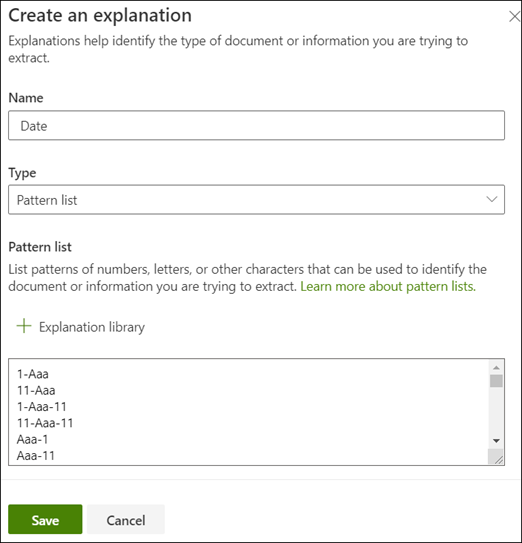
Als u de begindatum van de service wilt identificeren, kunt u een patroonuitleg maken.
- In de sectie uitleg selecteer je Nieuw en type een naam (bijvoorbeeld, Leeg).
- Selecteer bij type Patroonlijst.
- Geef bij waarde de datumvariant op zoals deze wordt weergegeven in de voorbeeldbestanden. Als je bijvoorbeeld datumnotaties hebt die worden weergegeven als 0/00/0000, geef je de variaties op die worden weergegeven in je documenten, zoals:
- 0/0/0000
- 0/00/0000
- 00/0/0000
- 00/00/0000
- Kies Opslaan.
Opmerking
Zie Uitlegtypenvoor meer informatie over uitlegtypen.
De uitlegbibliotheek gebruiken
Voor het maken van uitleg voor items zoals datums is het gemakkelijker om de uitlegbibliotheek te gebruiken dan om alle variaties handmatig in te voeren. De uitlegbibliotheek is een set vooraf gedefinieerde frasen en patroonverklaringen. De bibliotheek probeert alle indelingen op te geven voor algemene woordgroepen of patroonlijsten, zoals datums, telefoonnummers, postcodes en nog veel meer.
Voor het voorbeeld van de begindatum van de service is het efficiënter om de vooraf gemaakte uitleg voor Datum in de uitlegbibliotheek te gebruiken:
In de Sectie uitleg selecteer je Nieuw en vervolgens Uit Uitlegbibliotheek.
Uit de uitlegbibliotheek, selecteer Datum. Je kunt alle datumvariaties weergeven die worden herkend.
Kies Toevoegen.
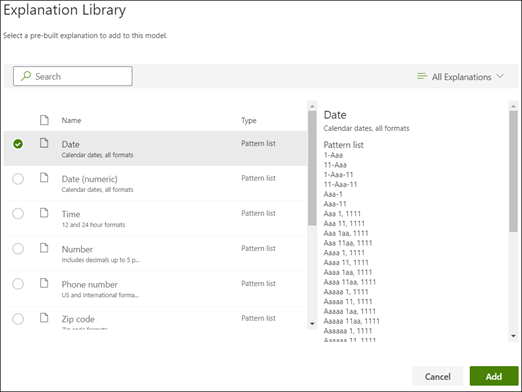
Op de pagina een uitleg maken wordt de Datum informatie uit de uitlegbibliotheek automatisch ingevuld op de velden. Kies Opslaan.
Het model trainen
Als u uw uitleg opslaat, begint de training. Als uw model voldoende informatie heeft om de gegevens uit de gelabelde voorbeeldbestanden te extraheren, ziet u dat elk bestand is gelabeld met Overeenkomst.
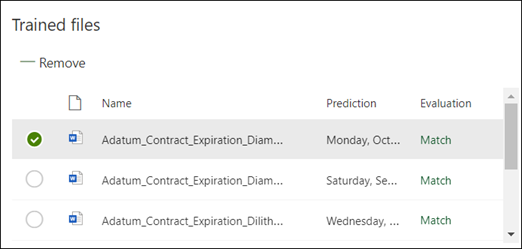
Als de uitleg niet voldoende informatie bevat om de gegevens te vinden die u wilt extraheren, wordt elk bestand gelabeld met Niet overeenkomend. U kunt Niet-overeenkomende bestanden selecteren voor meer informatie over waarom er een onjuiste overeenkomst is opgetreden.
Nog een uitleg toevoegen
Vaak is de niet-overeenkomende verklaring een indicatie dat de uitleg die we hebben opgegeven niet voldoende informatie bevat om de waarde voor de begindatum van de service te extraheren zodat deze overeenkomt met onze gelabelde bestanden. Mogelijk moet u deze bewerken of een andere uitleg toevoegen.
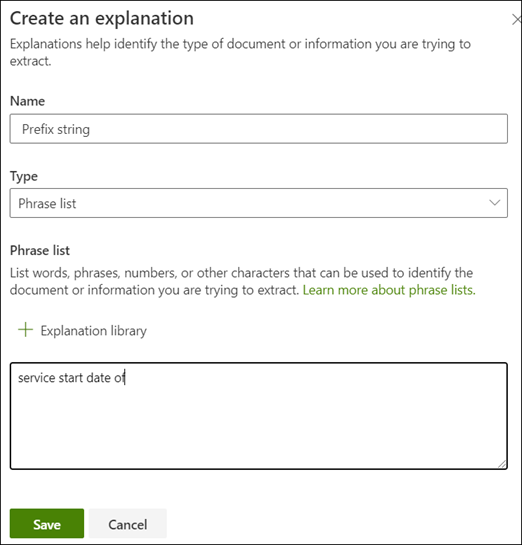
In ons voorbeeld ziet u dat de tekenreeks Begindatum van de service van altijd vóór de werkelijke waarde begint. Als je de begindatum van de service wilt identificeren moet je een uitleg bij de frase maken.
In de sectie uitleg selecteer je Nieuw en type een naam (bijvoorbeeld, Voorvoegseltekenreeks).
Voor het type selecteer je Woordenlijst.
De Begindatum van de service van als waarde gebruiken.
Kies Opslaan.
Het model nogmaals trainen
Door de uitleg op te slaan, wordt de training opnieuw gestart en deze keer worden met beide uitleggen in het voorbeeld gebruikt. Als je model voldoende gegevens heeft om de gegevens uit de voorbeeldbestanden met een label te halen, zie je elk bestand dat is gemarkeerd met Overeenkomst.
Als je opnieuw een Komt niet overeen op je gelabelde bestanden ontvangt, moet je waarschijnlijk nog een uitleg maken om het model meer informatie te geven om het documenttype te identificeren, of je kunt wijzigingen aanbrengen in je bestaande bestanden.
Test je model.
Als je een overeenkomst hebt gekregen met de gelabelde voorbeeldbestanden, kun je nu je model testen op de andere niet-gelabelde voorbeeldbestanden. Deze stap is optioneel, maar handig om de 'geschiktheid' of gereedheid van het model te evalueren voordat u het gebruikt, door het te testen op bestanden die het model nog niet eerder heeft gezien.
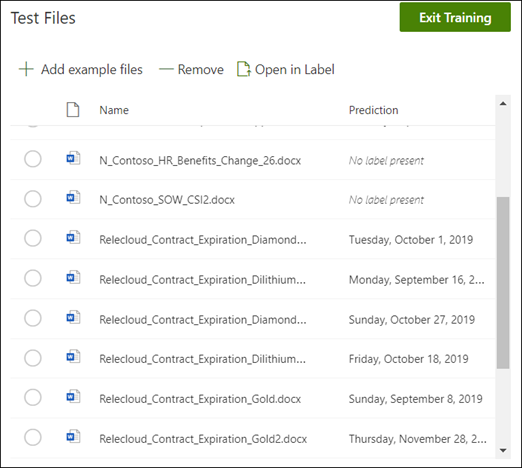
Selecteer op de startpagina van het model het tabblad Testen . Hiermee wordt het model uitgevoerd op uw niet-gelabelde voorbeeldbestanden.
In de lijst Testbestanden worden de voorbeeldbestanden weergegeven om aan te geven of de gegevens die je nodig hebt, door het model kunnen worden opgehaald. Gebruik deze informatie om de effectiviteit van je classificatie bij het identificeren van je documenten vast te stellen.
Een extractor verder verfijnen
Als u dubbele entiteiten hebt en slechts één waarde of een bepaald aantal waarden wilt extraheren, kunt u een regel instellen om op te geven hoe u deze wilt verwerken. Voer de volgende stappen uit om een regel toe te voegen om geëxtraheerde informatie te verfijnen:
Selecteer op de startpagina van het model in de sectie Entiteitsextractors de extractor die u wilt verfijnen en selecteer vervolgens Geëxtraheerde gegevens verfijnen.
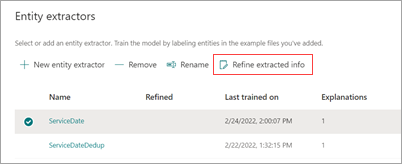
Selecteer op de pagina Uitgepakte gegevens verfijnen een van de volgende regels:
- Een of meer van de eerste waarden behouden
- Een of meer van de laatste waarden behouden
- Dubbele waarden verwijderen
- Een of meer van de eerste regels behouden
- Een of meer van de laatste regels behouden
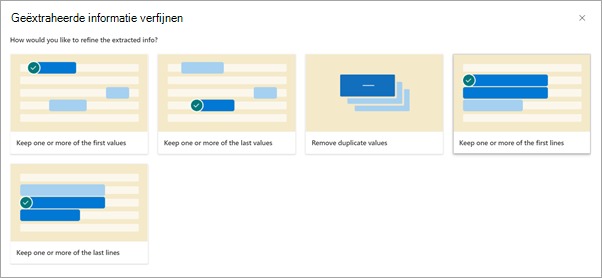
Voer het aantal regels of waarden in dat u wilt gebruiken en selecteer vervolgens Verfijnen.
Als u een regel wilt bewerken door het aantal regels of waarden te wijzigen, selecteert u de extractor die u wilt bewerken, selecteert u Uitgepakte gegevens verfijnen, wijzigt u het getal en selecteert u vervolgens Opslaan.
Wanneer u de extractor test, kunt u de verfijning zien in de kolom Verfijningsresultaat van de lijst Testbestanden .
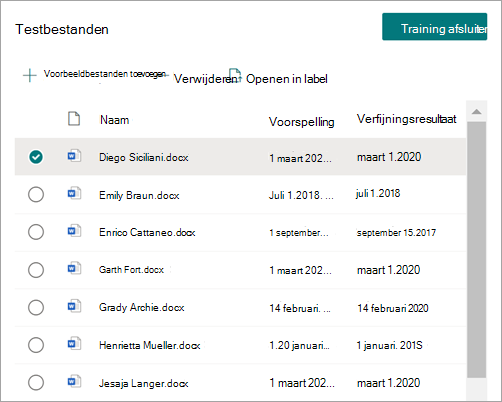
Als u een verfijningsregel van een extractor wilt verwijderen, selecteert u de extractor waaruit u de regel wilt verwijderen, selecteert u Geëxtraheerde gegevens verfijnen en selecteert u vervolgens Verwijderen.
Zie ook
De taxonomie van een termenarchief benutten bij het maken van een extractor