Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Met behulp van Copilot Studio kunt u uw agents verbeteren met domeinspecifieke kennis, mogelijk gemaakt door dezelfde vertrouwde en bekende gegevensbronnen die u bouwt via Power Platform-connectors.
Wanneer u externe inhoud uploadt vanaf uw apparaat, OneDrive of SharePoint, kunt u uw agents verrijken met contextuele kennis die is afgestemd op uw bedrijf. Microsoft Dataverse deze bestanden veilig opslaat en deze automatisch verwerkt in semantische indexen en vector embeddings. Met deze configuratie kunnen uw agenten nauwkeurigere, onderbouwde antwoorden genereren op basis van de informatie die u opgeeft.
Bestanden die zijn geüpload in Copilot Studio gebruiken Microsoft Dataverse om onbewerkte bestanden op te nemen en indexen en vector-insluitingen te maken. Deze indexen en embeddings helpen om kwalitatieve antwoorden te bieden aan uw agenten. U kunt deze bestanden uploaden vanaf uw computer of door verbinding te maken met OneDrive of SharePoint.
Wanneer je bestanden als kennisbron uploadt, help je je agenten te verrijken met extra data, breid je de kennis van het taalmodel uit en veranker je de agent in specifieke informatie die je verstrekt. U kunt verschillende bestanden uploaden, die het systeem semantisch indexeert als vector insluitingen en vervolgens gebruikt als kennis voor agents. Je kunt deze kennis die in agenten wordt gebruikt delen met geauthenticeerde en niet-geauthenticeerde gebruikers van de agent.
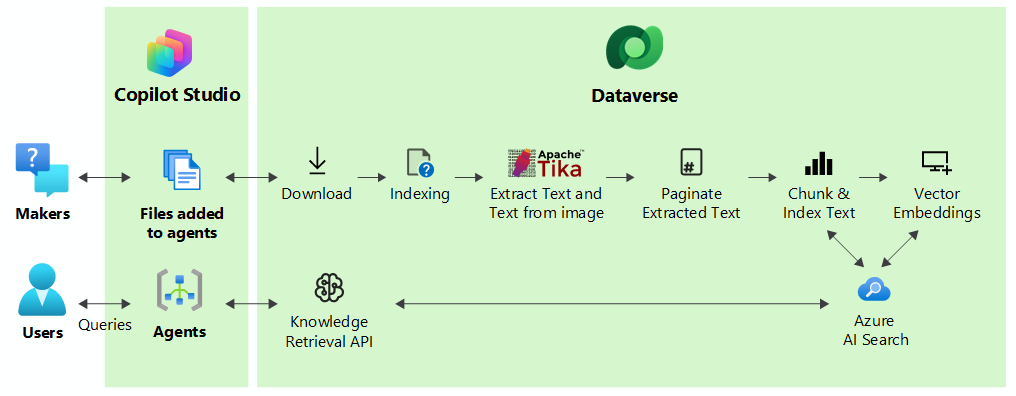
Om de antwoorden van een agent te verbeteren, splitst het systeem bestanden in stukken voor snellere verwerking en vector-indexeert deze om semantische overeenkomsten met de zoekopdracht van de gebruiker te bieden. Het systeem slaat de bestanden veilig op in Dataverse. Wanneer een gebruiker query's uitvoert via een agent, vindt Copilot Studio de meest relevante segmenten die overeenkomen met de intentie van de gebruikersquery en de resultaten worden geretourneerd aan de gebruiker.
Op dezelfde manier neemt Dataverse OneDrive- en SharePoint-bestanden op met behulp van de opties onder het uploaden van bestanden. Er wordt ook ongestructureerde inhoud opgenomen, zoals knowledge base-artikelen van Salesforce, ServiceNow, Confluence en Zendesk, om betere semantische resultaten voor de agent te bieden.
Note
Meer informatie in Code-interpreter gebruiken om gestructureerde gegevens te analyseren.
Power Platform-connectors voor ongestructureerde gegevens
De volgende Power Platform-connectors werken met niet-gestructureerde gegevensbronnen:
OneDrive
Gebruik de oneDrive-optie Bestanden > uploaden met een bestandskiezerinterface om de bestanden en mappen te kiezen die u wilt opnemen. Eenmaal geselecteerd, haalt het systeem de items op in Dataverse en indexeert ze voor gebruik. De mappen die je toevoegt bevatten alle ondersteunde bestanden en submappen binnen die map tot aan het totale bestandslimiet.
SharePoint
Gebruik de SharePoint-optie Bestanden > uploaden om bestanden en mappen te selecteren via een bestandskiezerinterface. Nadat u deze items hebt geselecteerd, haalt de connector deze op in Dataverse en indexeert deze voor gebruik. Wanneer u mappen toevoegt, neemt u alle ondersteunde bestanden en submappen in die map op tot de totale bestandslimiet. Momenteel biedt de connector geen ondersteuning voor Pagina's.
Note
Wanneer u SharePoint als kennisbron gebruikt, haalt Copilot Studio inhoud op via SharePoint-zoekindexering, niet door lijstweergaven zoals AllItems.aspx rechtstreeks te lezen. Nieuw toegevoegde of bijgewerkte SharePoint-items zijn mogelijk pas beschikbaar voor de agent als de zoekindexering is voltooid. Zorg ervoor dat de agent over de vereiste machtigingen beschikt, zoals Sites.Read.All en Files.Read.Allen dat de inhoud is opgeslagen in ondersteunde bestandsindelingen.
Salesforce
De Salesforce-connector voor ongestructureerde gegevens biedt ondersteuning voor het ophalen van Knowledge Bases die kennisartikelen bevatten. Selecteer een Knowledge Base en de connector indexeert alle artikelen in die Knowledge Base. Je kunt geen individuele artikelen of onderwerpen selecteren. Bij het opvragen van data kun je geen specifiek artikel of kennisbank specificeren. In de Kennislijst wordt één object weergegeven voor alle kennisobjecten die u selecteert bij het maken van de bron.
ServiceNow
De ServiceNow-connector voor ongestructureerde gegevens biedt ondersteuning voor het ophalen van Knowledge Bases die kennisartikelen bevatten. Knowledge Bases bevatten artikelen. Selecteer een Knowledge Base en de connector indexeert alle artikelen in die Knowledge Base. Je kunt geen individuele artikelen selecteren. Bij het opvragen van data kun je geen kennisbank, map of individueel artikel specificeren. In de Kennislijst wordt één object weergegeven voor alle kennisobjecten die u selecteert bij het maken van de bron.
Confluence
De Confluence-connector voor ongestructureerde gegevens ondersteunt ophalen van de ruimten die pagina's bevatten. De connector ondersteunt ook submappen. Je kunt geen individuele pagina's selecteren. Bij het opvragen van data kun je geen pagina specificeren. De kennislijst toont één enkel object voor alle pagina's binnen de ruimte.
Zendesk
De Zendesk-connector voor ongestructureerde gegevens ondersteunt het ophalen van de knowledge base die kennisartikelen bevat. Je kunt geen individuele artikelen, categorieën of secties selecteren. Bij het opvragen van data kun je geen artikel, categorie of sectie specificeren. De kennisbaselijst bevat één object voor alle artikelen in de kennisbank.
Beveiliging
Wanneer een gebruiker een query uitvoert op een agent die gebruikmaakt van een Power Platform Connector-bron, voert het systeem autorisatiecontroles uit.
Toegang tot de connector
Wanneer u voor het eerst een bron op basis van een connector gebruikt, wordt u gevraagd een bestaande Power Platform-connector te selecteren of er een toe te voegen. Dit proces zorgt ervoor dat u alleen gegevens deelt met makers die over de juiste machtigingen beschikken om toegang te krijgen tot de gegevensbron.
Toegang tot inhoud
Wanneer een gebruiker een query doet, gebruikt het systeem hun verbindingsinformatie om de gegevensbron te controleren en te verifiëren dat hij toestemming heeft om de inhoud te zien. Hoewel het systeem chunks en indexen lokaal opslaat in Dataverse, voert het een live controle uit op de queries om te controleren of de huidige gebruiker toegang heeft tot de data voordat een samenvatting of antwoord wordt gegeven.
Note
- Het systeem retourneert geen resultaten aan gebruikers als ze geen machtigingen hebben voor specifieke sets bestanden of knowledge base-artikelen. In plaats daarvan ontvangen ze een standaardbericht met de tekst "er konden geen resultaten worden gevonden." Als gebruikers vinden dat er resultaten voor die bron moeten zijn, moeten ze samenwerken met hun beheerders om ervoor te zorgen dat ze rechten hebben voor de data die ze willen bereiken. De gebruiker moet een passende Dataverse-beveiligingsrol toegewezen krijgen, zoals de Basic User-rol.
- Het systeem slaat inhoudsmachtigingen niet lokaal op. Het voert alle toestemmingscontroles live uit met de bron om ervoor te zorgen dat deze het meest up-to-date zijn.
Synchronisatie- en bestandsvernieuwingsfrequentie
Met een geplande synchronisatietaak blijven verbonden bestanden van OneDrive en SharePoint en ongestructureerde kennisartikelen vers. Deze taak wordt automatisch op de achtergrond uitgevoerd, vernieuwt de inhoud van de bestanden en indexeert de wijzigingen opnieuw om nauwkeurige resultaten voor query's te bieden. Vernieuwingen beheren niet alleen wijzigingen in inhoud, maar zorgen er ook voor dat inhoud die uit de bron is verwijderd, niet meer wordt weergegeven als onderdeel van queryreacties. Op dit moment kunt u een vernieuwing niet handmatig activeren.
Zie Copilot Studio ongestructureerde limieten voor gegevensbronnen voor meer informatie over tijdsinstellingen voor vernieuwingsfrequenties.
Licenties
Alle aanvragen waarbij kennis is betrokken, worden in rekening gebracht op basis van de tarieven voor het verzenden van antwoorden van Microsoft Copilot. Voor meer informatie, zie Factureringstarieven en beheer.
Als kennisbronnen gegevensopname vereisen, zijn de opslag van de data en de bijbehorende indexen om die data op te halen onderworpen aan de opslagrechten die de klant heeft. Voor meer informatie over Dataverse natuurlijke taalzoekopdrachten, zie Verbeter AI-gestuurde ervaringen met Dataverse zoekopdracht.
Limieten en beperkingen
Wanneer je voor het eerst ondersteuning voor ongestructureerde data inschakelt, kan Dataverse tussen de 5 en 30 minuten duren om te configureren en indexeren voordat het de toegevoegde bestanden verwerkt. De tijdsduur is afhankelijk van de grootte van de huidige Dataverse-omgeving.
Elke agent kan maximaal 500 kennisobjecten hebben. Deze objecten kunnen bestanden, mappen, kennisartikelen, websites of andere bronnen zijn.
Op dit moment kan een agent slechts vijf verschillende bronnen tegelijk gebruiken. Bijvoorbeeld SharePoint, Dataverse, OneDrive of andere bronnen.
Zie Copilot Studio niet-gestructureerde gegevensbronlimieten voor meer informatie over specifieke limieten en beperkingen voor de ondersteunde ongestructureerde gegevensbronnen.
Note
Copilot Studio-agents vereisen dat Dataverse-zoekopdrachten gebruikmaken van deze kennisbron. Als u geen bestand met Dataverse-functionaliteit aan een agent kunt toevoegen, vraagt u de beheerder om Dataverse-zoekopdracht in te schakelen in uw omgeving. Zie Wat is Dataverse zoeken en Dataverse configureren voor uw omgeving voor meer informatie over zoeken in Dataverse en hoe u deze kunt beheren.
Voor toegang tot OneDrive en SharePoint inhoud die is opgeslagen in Dataverse, moeten gebruikers ten minste een basislicentie voor Power Apps of Dynamics 365 hebben. Daarnaast moeten de Basic User-rechten ook leesrechten bevatten voor de volgende tabellen en entiteiten:
- Invoegtoepassingsassembly
- Type invoegtoepassing
- SDK Message
- Stap voor het verwerken van SDK-berichten
- Afbeelding van stap voor verwerking van SDK-berichten
U kunt deze machtigingen configureren in het Power Platform-beheercentrum of het Dynamics 365-beheercentrum.
Veelgestelde vragen
Wat is het verschil tussen de twee SharePoint-opties in Kennis toevoegen?
In het dialoogvenster Aanvoegingskennis ziet u twee SharePoint opties.

De SharePoint optie in de sectie voor het uploaden van bestanden (1) is voor het uploaden van afzonderlijke SharePoint bestanden of mappen naar uw agent. Met deze optie uploadt u een kopie van het bestand van SharePoint naar Dataverse en onderhoudt u een synchrone relatie om het bestand up-to-date te houden. Tijdens query's wordt SharePoint geopend om gebruikersmachtigingen voor de inhoud te valideren. De opgeslagen Dataverse-bestanden verbruiken gegevensopslag, maar bieden een semantische zoekfunctie voor volledig document en ondersteuning voor tekst in afbeeldingen voor bepaalde documenttypen, zoals PDF-bestanden.
Gebruik optie 1 als u snelle synchronisatie wilt en niet statische bestanden wilt uploaden naar Dataverse. Het wordt automatisch bijgewerkt wanneer bronbestanden worden gewijzigd.
De andere SharePoint optie (2) biedt de volledige SharePoint integratie in Copilot Studio met behulp van de SharePoint-connector. Gebruik deze optie wanneer u volledige SharePoint connectormogelijkheden, aangepaste verificatieconfiguraties of geavanceerde queryopties nodig hebt.
Runtimeverschillen
| Scenario | Optie 1: bestand uploaden | Optie 2: SharePoint-connector |
|---|---|---|
| Inhoudsopslag | Gekopieerd naar Dataverse vanuit SharePoint | Bevindt zich in SharePoint |
| Zoekfunctionaliteit | Zoekt in een semantische Dataverse-index die is gebouwd op basis van ingesloten vectoren van de opgenomen inhoud die is gekopieerd uit SharePoint | Rechtstreeks query's uitvoeren op de SharePoint-zoekinfrastructuur |
| Versheid van inhoud | Inhoud wordt elke vier tot zes uur gesynchroniseerd op basis van opnamevoltooiing | Realtime en geeft de nieuwste beschikbare inhoud weer |
| SharePoint-lijsten | Ondersteund | Niet ondersteund |
| Dataverse-opslagverbruik | Ja, voor gekopieerde bestanden en zoekindexen | No |
| Geavanceerde queryfilters | Niet beschikbaar | Filteren op titel, auteur, gewijzigd door, datum gewijzigd |
Gebruik van opties
Gebruik optie 1 in de volgende situaties:
- U hebt ondersteuning nodig voor SharePoint-lijsten
- De agent gebruikt alleen een specifieke set bestanden of mappen
- U wilt semantische zoekopdrachten van hoge kwaliteit mogelijk maken door vector-insluitingen
- Een vernieuwingsinterval van vier tot zes uur is voldoende
Gebruik optie 2 in de volgende situaties:
- Geen vertraging in inhoudssynchronisatie, zoals een regelmatig bijgewerkte wiki of een aankondigingssite
- Dataverse-verbruik vermijden, met name voor grote documentbibliotheken
- Gebruik van geavanceerde queryfilters, zoals filteren op basis van auteur, gewijzigde datum of titel
Note
Voor beide opties is gebruikersverificatie vereist. Gebruikers kunnen zich aanmelden voordat de agent resultaten ophaalt uit SharePoint-inhoud. Meer informatie over synchronisatietijdsinstellingen en bestandslimieten in Niet-gestructureerde gegevensbronlimieten in Copilot Studio.
Waarom wordt het SharePoint-pictogram niet weergegeven in de sectie Bestanden uploaden van het dialoogvenster Kennis toevoegen?
Er is een kleine vertraging na het installeren van een oplossing totdat deze in alle bestaande organisaties wordt weergegeven. Volg deze stappen om een handmatige update te starten:
Log in bij het Power Platform admin center met behulp van beheerdersgegevens.
Selecteer Beheren aan de zijbalk.
Selecteer Dynamics 365 Apps in de lijst met producten.
Zoek naar poweraiextensions.
Selecteer de drie puntjes (... ) voor Microsoft Dynamics 365 - PowerAIExtensions en selecteer Install.
Selecteer uw omgeving in de vervolgkeuzelijst en selecteer vervolgens Installeren.
Nadat de installatie is voltooid, opent u Power Apps in een nieuw venster.
Selecteer in het linkerdeelvenster de optie Oplossingen.
Kies Details.
Controleer of de versie van PowerAIExtensions Solution Anchor is ingesteld op 1.01.688 of hoger.
Wat gebeurt er wanneer ik meer dan 500 kennisobjecten aan mijn agent toevoeg?
Je kunt geen extra objecten toevoegen tenzij je eerst eerdere objecten verwijdert.
Heeft elke agent een eigen index van de kennisbron?
Dataverse slaat kennisbronnen op voor gebruik in de omgeving waar je ze maakt. Als meerdere agents dezelfde SharePoint map gebruiken, gebruiken alle agents één exemplaar van die map.
Wat gebeurt er als ik een SharePoint- of OneDrive-map toevoeg die het maximum aantal bestanden, mappen en submappen overschrijdt?
Copilot Studio haalt en indexeert maximaal het maximum aantal bestanden, mappen en submappen. De resterende items worden niet verwerkt en er wordt niet aangegeven welke items wel of niet worden verwerkt.
Een van de bestanden die ik heb toegevoegd, wordt weergegeven als onderdeel van de kennisbron, maar ik kan er geen antwoorden van krijgen. Waarom?
Dit probleem kan te maken hebben met een van de volgende redenen:
- De Knowledge-pagina rapporteert het bestand of de map niet als Gereed.
- De bestandsnaam bevat een niet-ondersteund teken (met name voor SharePoint-bestanden).
- Het bestand heeft een vertrouwelijkheidsinstelling vertrouwelijk of Zeer vertrouwelijk, of heeft wachtwoordbeveiliging.
- Het bestandstype wordt niet ondersteund.
- Het bestand of de map is afkomstig van de OneDrive- of SharePoint-site van een andere gebruiker en de gebruiker heeft het niet met u gedeeld.
- Het bestand is een Knowledge Base-bestand en uw account beschikt niet over de vereiste machtigingen om de inhoud in het bronsysteem weer te geven.