Omówienie elastycznych pul w warstwie Hiperskala w usłudze Azure SQL Database
Dotyczy: ![]() Azure SQL Database
Azure SQL Database
Ten artykuł zawiera omówienie elastycznych pul w warstwie Hiperskala w usłudze Azure SQL Database.
Elastyczna pula usługi Azure SQL Database umożliwia deweloperom oprogramowania jako usługi (SaaS) optymalizowanie współczynnika wydajności cen dla grupy baz danych w ramach określonego budżetu przy jednoczesnym zapewnieniu elastyczności wydajności dla każdej bazy danych. Elastyczne pule usługi Azure SQL Database w warstwie Hiperskala wprowadza udostępniony model zasobów dla baz danych w warstwie Hiperskala.
Przykłady tworzenia, skalowania lub przenoszenia baz danych do elastycznej puli hiperskala przy użyciu interfejsu wiersza polecenia platformy Azure lub programu PowerShell można znaleźć w artykule Praca z elastycznymi pulami hiperskala przy użyciu narzędzi wiersza polecenia
Uwaga
Pule elastyczne dla warstwy Hiperskala są obecnie dostępne w wersji zapoznawczej.
Omówienie
Wdróż bazę danych w warstwie Hiperskala w elastycznej puli , aby udostępniać zasoby między bazami danych w puli i zoptymalizować koszt posiadania wielu baz danych z różnymi wzorcami użycia.
Scenariusze użycia elastycznej puli z bazami danych w warstwie Hiperskala:
- W przypadku konieczności skalowania zasobów obliczeniowych przydzielonych do elastycznej puli w górę lub w dół w przewidywalnym czasie, niezależnie od ilości przydzielonego magazynu.
- Jeśli chcesz skalować zasoby obliczeniowe przydzielone do puli elastycznej, dodając co najmniej jedną replikę skalowania do odczytu.
- Jeśli chcesz używać wysokiej przepływności dziennika transakcji dla obciążeń intensywnie korzystających z zapisu, nawet w przypadku mniejszych zasobów obliczeniowych.
Dodanie baz danych innych niż Hiperskala do elastycznej puli hiperskala konwertuje bazy danych na warstwę usługi Hiperskala.
Architektura
Tradycyjnie architektura autonomicznej bazy danych w warstwie Hiperskala składa się z trzech głównych niezależnych składników: Compute, Storage ("Page Servers") i dziennika ("Log Service"). Podczas tworzenia elastycznej puli dla baz danych w warstwie Hiperskala bazy danych w puli współużytkują zasoby obliczeniowe i zasoby dziennika. Ponadto jeśli zdecydujesz się skonfigurować wysoką dostępność, każda pula wysokiej dostępności zostanie utworzona z równoważnym i niezależnym zestawem zasobów obliczeniowych i dzienników.
Poniżej opisano architekturę elastycznej puli baz danych w warstwie Hiperskala:
- Elastyczna pula hiperskala składa się z puli podstawowej, która hostuje podstawowe bazy danych w warstwie Hiperskala i, jeśli została skonfigurowana, do czterech dodatkowych pul wysokiej dostępności.
- Podstawowe bazy danych hiperskala hostowane w podstawowej elastycznej puli współużytkuje proces obliczeniowy aparatu bazy danych programu SQL Server (sqlservr.exe), rdzenie wirtualne, pamięć i pamięć podręczną SSD.
- Skonfigurowanie wysokiej dostępności dla puli podstawowej powoduje utworzenie dodatkowych pul wysokiej dostępności zawierających repliki bazy danych tylko do odczytu dla baz danych w puli podstawowej. Każda pula podstawowa może mieć maksymalnie cztery pule replik o wysokiej dostępności. Każda pula o wysokiej dostępności współdzieli zasoby obliczeniowe, pamięć podręczną SSD i pamięć dla wszystkich pomocniczych baz danych tylko do odczytu w puli.
- Bazy danych hiperskala w podstawowej elastycznej puli współużytkują tę samą usługę dziennika. Ponieważ bazy danych w pulach wysokiej dostępności nie mają obciążenia zapisu, nie korzystają z usługi dziennika.
- Każda baza danych w warstwie Hiperskala ma własny zestaw serwerów stron, a te serwery stron są współużytkowane przez podstawową bazę danych w puli podstawowej oraz wszystkie pomocnicze bazy danych replik w puli o wysokiej dostępności.
- Pomocnicze pomocnicze bazy danych w warstwie Hiperskala replikowane geograficznie można umieścić w innej elastycznej puli.
- Określenie
ApplicationIntent=ReadOnlyw bazie danych parametry połączenia kieruje cię do bazy danych repliki tylko do odczytu w jednej z pul wysokiej dostępności.
Na poniższym diagramie przedstawiono architekturę elastycznej puli baz danych w warstwie Hiperskala:
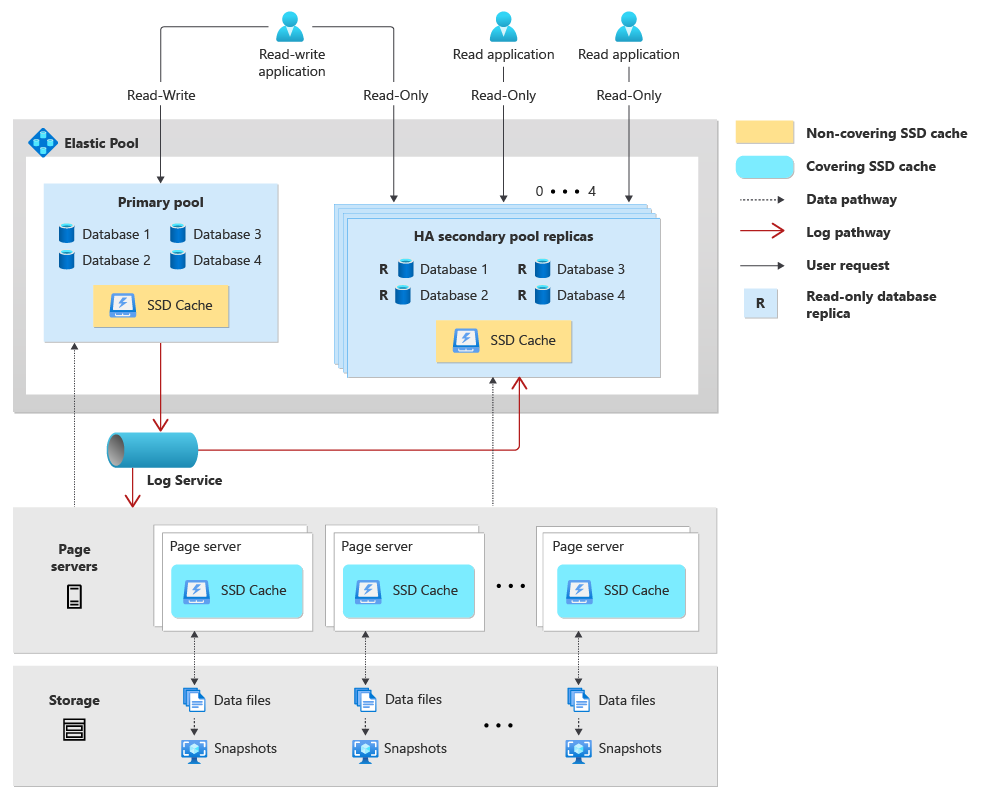
Zarządzanie bazami danych elastycznej puli hiperskala
Możesz użyć tych samych poleceń, aby zarządzać bazami danych hiperskala w puli jako bazami danych w puli w innych warstwach usług. Pamiętaj o określeniu Hyperscale wersji podczas tworzenia elastycznej puli hiperskala.
Jedyną różnicą jest możliwość modyfikowania liczby replik wysokiej dostępności (H/A) dla istniejącej elastycznej puli hiperskala. Aby to zrobić:
HighAvailabilityReplicaCountUżyj parametru polecenia Set-AzSqlElasticPool programu Azure PowerShell.--ha-replicasUżyj parametru polecenia interfejsu wiersza polecenia platformy Azure az sql elastic-pool update.
Do zarządzania bazami danych hiperskali w elastycznej puli można użyć następujących narzędzi klienckich:
- Azure PowerShell: Az.Sql.3.11.0 lub nowszy. Moduł AzureRM.Sql programu PowerShell nie jest obsługiwany.
- Interfejs wiersza polecenia platformy Azure: Az w wersji 2.40.0 lub nowszej.
- Język Transact-SQL (T-SQL) rozpoczynający się od: SQL Server Management Studio (SSMS) v18.12.1 lub Azure Data Studio w wersji 1.39.1.
Konwertowanie baz danych innych niż Hiperskala na elastyczne pule hiperskala
Podczas konwertowania bazy danych na hiperskala można dodać bazę danych do istniejącej elastycznej puli hiperskala. W przypadku tych konwersji elastyczna pula hiperskala musi istnieć na tym samym serwerze logicznym co źródłowa baza danych.
Podczas konwertowania baz danych na elastyczne pule hiperskala należy pamiętać o maksymalnej liczbie baz danych na elastyczną pulę hiperskala.
Konwertowanie baz danych innych niż Hiperskala na elastyczne pule hiperskala przy użyciu języka T-SQL
Polecenia języka T-SQL umożliwiają konwertowanie wielu baz danych ogólnego przeznaczenia i dodawanie ich do istniejącej elastycznej puli hiperskala o nazwie hsep1:
ALTER DATABASE gpepdb1 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb2 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb3 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb4 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
W tym przykładzie niejawnie żądasz konwersji z warstwy Ogólnego przeznaczenia na Hiperskala, określając, że element docelowy SERVICE_OBJECTIVE jest elastyczną pulą hiperskala. Każde z powyższych poleceń rozpoczyna konwertowanie odpowiedniej bazy danych ogólnego przeznaczenia na warstwę Hiperskala. Te ALTER DATABASE polecenia zwracają się szybko i nie czekają na zakończenie konwersji. W przedstawionym przykładzie będziesz mieć cztery takie konwersje z warstwy Ogólnego przeznaczenia na Hiperskala uruchomione równolegle.
Możesz wykonać zapytanie dotyczące dynamicznego widoku zarządzania sys.dm_operation_status , aby monitorować stan tych operacji konwersji w tle.
Konwertowanie baz danych innych niż Hiperskala na elastyczne pule hiperskala przy użyciu programu PowerShell
Polecenia programu PowerShell umożliwiają konwertowanie wielu baz danych ogólnego przeznaczenia i dodawanie ich do istniejącej elastycznej puli hiperskala o nazwie hsep1. Na przykład następujący przykładowy skrypt wykonuje następujące kroki:
- Użyj polecenia cmdlet Get-AzSqlElasticPoolDatabase, aby wyświetlić listę wszystkich baz danych w elastycznej puli ogólnego przeznaczenia o nazwie
gpep1. - Polecenie
Where-Objectcmdlet filtruje listę tylko do tych nazw baz danych rozpoczynających się odgpepdb. - Dla każdej bazy danych polecenie cmdlet Set-AzSqlDatabase uruchamia konwersję. W takim przypadku niejawnie żądasz konwersji do warstwy usługi Hiperskala, określając docelową elastyczną pulę hiperskala o nazwie
hsep1.- Parametr
-AsJobumożliwia równoległe uruchamianie poszczególnychSet-AzSqlDatabaseżądań. Jeśli wolisz uruchomić konwersje jeden po jednym, możesz usunąć-AsJobparametr .
- Parametr
$dbs = Get-AzSqlElasticPoolDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -ElasticPoolName "gpep1"
$dbs | Where-Object { $_.DatabaseName -like "gpepdb*" } | % { Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -DatabaseName ($_.DatabaseName) -ElasticPoolName "hsep1" -AsJob }
Oprócz dynamicznego widoku zarządzania sys.dm_operation_status można użyć polecenia cmdlet programu PowerShell Get-AzSqlDatabaseActivity , aby monitorować stan tych operacji konwersji w tle.
Limity zasobów
Poniżej wymieniono obsługiwane limity pracy z bazami danych w warstwie Hiperskala w pulach elastycznych:
- Obsługiwane generowanie sprzętu: zoptymalizowane pod kątem pamięci serii Standardowa (Gen5), serii Premium i premium.
- Maksymalna liczba rdzeni wirtualnych na pulę: 80 lub 128 rdzeni wirtualnych, w zależności od celu poziomu usługi.
- Maksymalny obsługiwany rozmiar danych na bazę danych: 100 TB.
- Maksymalny obsługiwany całkowity rozmiar danych w bazach danych w puli: 100 TB.
- Maksymalna obsługiwana przepływność dziennika transakcji na bazę danych: 100 MB.
- Maksymalna obsługiwana łączna przepływność dziennika transakcji w bazach danych w puli: 131,25 MB/s.
- Każda elastyczna pula hiperskala może mieć maksymalnie 25 baz danych.
Aby uzyskać więcej szczegółów, zobacz limity zasobów elastycznych pul hiperskala dla standardowa serii, serii Premium i zoptymalizowanych pod kątem pamięci w warstwie Premium.
Uwaga
Profile wydajności, obsługiwane możliwości i opublikowane limity mogą ulec zmianie, gdy funkcja jest dostępna w wersji zapoznawczej. W związku z tym najlepiej zweryfikować przypadek użycia przy użyciu regularnego działania, wydajności i testowania skalowania obciążeń.
Ograniczenia
Rozważ następujące ograniczenia:
- Zmiana istniejącej elastycznej puli innej niż Hiperskala na wersję Hiperskala nie jest obsługiwana. Sekcja konwersji zawiera kilka alternatyw, których można użyć.
- Zmiana wersji elastycznej puli hiperskala na wersję inną niż Hiperskala nie jest obsługiwana.
- Aby "cofnąć migrację" kwalifikującej się bazy danych, która znajduje się w elastycznej puli hiperskala, należy najpierw usunąć ją z elastycznej puli Hiperskala. Autonomiczna baza danych w warstwie Hiperskala może następnie zostać "zmigrowana odwrotnie" do autonomicznej bazy danych ogólnego przeznaczenia.
- W przypadku warstwy usługi Hiperskala obsługę nadmiarowości strefy można określić tylko podczas tworzenia bazy danych lub puli elastycznej i nie można jej modyfikować po aprowizacji zasobu. Aby uzyskać więcej informacji, zobacz Migrowanie usługi Azure SQL Database do obsługi stref dostępności.
- Dodawanie nazwanej repliki do elastycznej puli hiperskala nie jest obsługiwane. Próba dodania nazwanej repliki bazy danych hiperskala do elastycznej puli hiperskala powoduje wystąpienie
UnsupportedReplicationOperationbłędu. Zamiast tego utwórz nazwaną replikę jako pojedynczą bazę danych w warstwie Hiperskala.
Zagadnienia dotyczące strefowo nadmiarowych elastycznych pul
Poniżej przedstawiono niektóre zagadnienia dotyczące strefowo nadmiarowych elastycznych pul w warstwie Hiperskala:
Uwaga
Elastyczne pule w warstwie Hiperskala z nadmiarowością stref są dostępne obecnie w wersji zapoznawczej. Aby uzyskać więcej informacji, zobacz wpis w blogu: elastyczne pule hiperskala z nadmiarowością strefy.
- Do elastycznych pul w warstwie Hiperskala można dodawać tylko bazy danych z nadmiarowością magazynu strefowo nadmiarowego (ZRS lub GZRS).
- Autonomiczna baza danych w warstwie Hiperskala musi zostać utworzona z nadmiarowością strefy i strefowo nadmiarowym magazynem kopii zapasowych (ZRS lub GZRS), aby dodać ją do elastycznej puli strefowo nadmiarowej w warstwie Hiperskala. W przypadku baz danych w warstwie Hiperskala bez nadmiarowości strefy wykonaj transfer danych do nowej bazy danych w warstwie Hiperskala z włączoną opcją nadmiarowości strefy. Klon musi zostać utworzony przy użyciu funkcji kopiowania bazy danych, przywracania do punktu w czasie lub repliki geograficznej. Aby uzyskać więcej informacji, zobacz Ponowne wdrażanie (Hiperskala).
- Aby przenieść bazę danych w warstwie Hiperskala z jednej elastycznej puli do innej, ustawienia magazynu kopii zapasowych strefowo nadmiarowe i strefowo nadmiarowe muszą być zgodne.
- Aby przekonwertować bazę danych z innej warstwy usługi innej niż Hiperskala na elastyczną pulę hiperskala z nadmiarowością strefy:
- W witrynie Azure Portal najpierw włącz nadmiarowość strefy i strefowo nadmiarowy magazyn kopii zapasowych (ZRS). Następnie możesz dodać bazę danych do strefowo nadmiarowej elastycznej puli hiperskala.
- Za pomocą programu PowerShell najpierw włącz nadmiarowość strefy. Następnie za pomocą polecenia Set-AzSqlDatabase upewnij się, że
-BackupStorageRedundancyparametr jest używany do określania strefowo nadmiarowego magazynu kopii zapasowych (ZRS lub GZRS).
Znane problemy
| Problem | Zalecenie |
|---|---|
Podczas dodawania wielu baz danych innych niż Hiperskala do elastycznej puli hiperskala może zostać wyświetlony błąd Could not perform the operation because server would exceed the allowed Database Throughput Unit quota of 54000. (Code: ServerDtuQuotaExceeded). Chociaż komunikat odnosi się do jednostek przepływności bazy danych (DTU), jest powiązany z udostępnionym limitem przydziału jednostek DTU/rdzeni wirtualnych wymuszanych na każdym serwerze logicznym. Ten problem jest spowodowany wadą, w której rdzenie wirtualne są niepoprawnie obliczane na poziomie pojedynczej bazy danych. |
Poniżej przedstawiono kilka opcji obejścia problemu: • Dodaj bazy danych pojedynczo do elastycznej puli Hiperskala. • Najpierw przekonwertuj bazę danych na autonomiczną bazę danych hiperskala przed dodaniem jej do elastycznej puli Hiperskala. • Zażądaj zwiększenia limitu przydziału na poziomie serwera zgodnie z opisem w tym miejscu. |
Konfigurowanie replikacji geograficznej bazy danych ze strefowo nadmiarowej elastycznej puli hiperskala do nadmiarowej elastycznej puli hiperskala w innym regionie kończy się niepowodzeniem z powodu błędu Provisioning of zone redundant Hyperscale database with local backup redundancy is not supported. Zone redundant Hyperscale databases must use either zone or geo zone backup redundancy. Ten błąd nie występuje, jeśli druga elastyczna pula hiperskala jest strefowo nadmiarowa lub znajduje się w tym samym regionie. |
Aby obejść ten problem, możesz użyć programu Azure PowerShell i jawnie określić strefę nadmiarową w wierszu polecenia New-AzSqlDatabaseSecondary -ResourceGroupName "primary-rg" -ServerName "primary-server" -DatabaseName "hsdb1" -PartnerResourceGroupName "secondary-rg" -PartnerServerName "secondary-server" -AllowConnections "All" -SecondaryElasticPoolName "secondary-nonzr-pool" -BackupStorageRedundancy Local -ZoneRedundant:$false |
| Dodanie bazy danych ze strefowo nadmiarowej elastycznej puli hiperskala do grupy trybu failover z nadmiarową elastyczną pulą hiperskala w innym regionie zakończy się niepowodzeniem, ale operacja może być uruchomiona bez żadnego postępu. Pomocnicza baza danych geograficzna może być widoczna w przypadku korzystania z narzędzi takich jak program SSMS, ale nie można nawiązać połączenia z bazą danych pomocniczych geograficznych i korzystać z jej pomocniczej bazy danych. Grupa trybu failover może zawierać stan "Rozmieszczanie 0%" dla pomocniczej bazy danych geograficznej. Ten problem nie występuje, jeśli druga elastyczna pula hiperskala jest strefowo nadmiarowa. | Aby obejść ten problem, skonfiguruj replikację geograficzną poza grupą trybu failover przy użyciu programu Azure PowerShell, jawnie określając strefę nadmiarową w wierszu New-AzSqlDatabaseSecondary -ResourceGroupName "primary-rg" -ServerName "primary-server" -DatabaseName "hsdb1" -PartnerResourceGroupName "secondary-rg" -PartnerServerName "secondary-server" -AllowConnections "All" -SecondaryElasticPoolName "secondary-nonzr-pool" -BackupStorageRedundancy Local -ZoneRedundant:$falsepolecenia . Następnie możesz dodać bazę danych do grupy trybu failover. |
W rzadkich przypadkach może wystąpić błąd 45122 - This Hyperscale database cannot be added into an elastic pool at this time. In case of any questions, please contact Microsoft support, podczas próby przeniesienia/przywrócenia/skopiowania bazy danych w warstwie Hiperskala do puli elastycznej. |
To ograniczenie jest spowodowane szczegółami specyficznymi dla implementacji. Jeśli ten błąd blokuje Cię, zgłoś zdarzenie pomocy technicznej i poproś o pomoc. |
Powiązana zawartość
- Praca z elastycznymi pulami hiperskala przy użyciu narzędzi wiersza polecenia
- Ceny puli elastycznej
- Skalowanie zasobów elastycznej puli w usłudze Azure SQL Database
- Monitorowanie i skalowanie elastycznej puli w usłudze Azure SQL Database za pomocą programu PowerShell
- Wielodostępne wzorce dzierżawy bazy danych SaaS
- Wprowadzenie do wielodostępnej aplikacji SaaS korzystającej ze wzorca bazy danych na dzierżawę z usługą Azure SQL Database
- Zarządzanie zasobami w ramach gęstych pul elastycznych
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla