Bezserwerowa warstwa obliczeniowa dla bazy danych Azure SQL
Dotyczy: ![]() Azure SQL Database
Azure SQL Database
Bezserwerowa warstwa obliczeniowa dla pojedynczych baz danych w usłudze Azure SQL Database, która automatycznie skaluje obliczenia na podstawie zapotrzebowania na obciążenie i opłaty za ilość używanej mocy obliczeniowej na sekundę. Ponadto warstwa bezserwerowych usług obliczeniowych automatycznie wstrzymuje bazy danych w okresach nieaktywności, gdy są naliczane opłaty tylko za magazyn, oraz automatycznie wznawia bazy danych po ponownym pojawieniu się aktywności. Warstwa obliczeniowa bezserwerowa jest dostępna w warstwie usługi Ogólnego przeznaczenia i warstwie usługi Hiperskala .
Uwaga
Automatyczne wstrzymanie i automatyczne wznawianie jest obecnie obsługiwane tylko w warstwie usługi Ogólnego przeznaczenia.
Omówienie
Zakres skalowania automatycznego obliczeń i opóźnienie automatycznego wstrzymywania są ważnymi parametrami dla bezserwerowej warstwy obliczeniowej. Konfiguracja tych parametrów kształtuje środowisko wydajności bazy danych i koszt obliczeniowy.
Konfiguracja wydajności
- Minimalne rdzenie wirtualne i maksymalne rdzenie wirtualne są konfigurowalnymi parametrami, które definiują zakres pojemności obliczeniowej dostępnej dla bazy danych. Limity pamięci i operacji we/wy są proporcjonalne do określonego zakresu rdzeni wirtualnych.
- Opóźnienie automatycznego wstrzymania jest konfigurowalnym parametrem, który definiuje czas, przez który baza danych musi być nieaktywna, zanim zostanie automatycznie wstrzymana. Baza danych jest automatycznie wznawiana po następnym logowaniu lub innym działaniu. Alternatywnie można wyłączyć automatyczne wstrzymanie.
Koszt
- Koszt bezserwerowej bazy danych to suma kosztów obliczeniowych i kosztów magazynu.
- Jeśli użycie zasobów obliczeniowych mieści się między minimalnym i maksymalnym skonfigurowanym limitem, koszt obliczeniowy jest oparty na rdzeniach wirtualnych i używanej pamięci.
- Jeśli użycie zasobów obliczeniowych jest niższe od skonfigurowanych minimalnych limitów, koszt obliczeniowy jest oparty na minimalnych rdzeniach wirtualnych i minimalnej skonfigurowanej pamięci.
- Po wstrzymaniu bazy danych koszt obliczeniowy wynosi zero i są naliczane tylko koszty magazynowania.
- Koszt magazynowania jest określany w taki sam sposób, jak w aprowizowanej warstwie obliczeniowej.
Aby uzyskać więcej szczegółów kosztów, zobacz Rozliczenia.
Scenariusze
Opcja bezserwerowa jest zoptymalizowana pod kątem stosunku ceny do wydajności i jest przeznaczona dla pojedynczych baz danych wykorzystywanych sporadycznie i mających nieprzewidywalne wzorce użycia zezwalające na niewielkie opóźnienia wynikające z konieczności przygotowania do obliczeń po okresach bezczynności. Z kolei aprowizowana warstwa obliczeniowa jest zoptymalizowana pod kątem wydajności cenowej dla pojedynczych baz danych lub wielu baz danych w elastycznych pulach z wyższym średnim użyciem, które nie może pozwolić na opóźnienia w rozgrzewce obliczeniowej.
Scenariusze odpowiednie dla obliczeń bezserwerowych
- Pojedyncze bazy danych wykorzystywane sporadycznie i mające nieprzewidywalne wzorce użycia przeplatane okresami braku aktywności i niższym średnim wykorzystaniem obliczeń w czasie.
- Pojedyncze bazy danych w aprowizowanej warstwie obliczeniowej, które są często przeskalowywane, a ich klienci preferują delegowanie ponownego skalowania obliczeń do usługi.
- Nowe pojedyncze bazy danych bez historii użycia, w których ustalanie rozmiaru zasobów obliczeniowych jest trudne lub nie jest możliwe do oszacowania przed wdrożeniem w usłudze Azure SQL Database.
Scenariusze odpowiednie do aprowizowania zasobów obliczeniowych
- Pojedyncze bazy danych z bardziej regularnymi, przewidywalnymi wzorcami użycia i wyższym średnim wykorzystaniem zasobów obliczeniowych w czasie.
- Bazy danych, które nie mogą tolerować kompromisów wydajności wynikających z częstszego przycinania pamięci lub opóźnień wznawiania ze stanu wstrzymania.
- Wiele baz danych z sporadycznymi, nieprzewidywalnymi wzorcami użycia, które można skonsolidować w elastyczne pule w celu uzyskania lepszej optymalizacji wydajności cen.
Porównanie warstw obliczeniowych
W poniższej tabeli przedstawiono podsumowanie różnic między warstwą obliczeniową bezserwerową a aprowizowaną warstwą obliczeniową:
| Bezserwerowe usługi obliczeniowe | Aprowidowane obliczenia | |
|---|---|---|
| Wzorzec użycia bazy danych | Sporadyczne, nieprzewidywalne użycie z niższym średnim użyciem obliczeniowym w czasie. | Bardziej regularne wzorce użycia z wyższym średnim wykorzystaniem zasobów obliczeniowych w czasie lub wieloma bazami danych korzystającymi z elastycznych pul. |
| Nakład pracy związane z zarządzaniem wydajnością | Lower | Wyższa |
| Skalowanie zasobów obliczeniowych | Automatyczne | Ręcznie |
| Czas odpowiedzi obliczeń | Niższa po nieaktywnych okresach | Natychmiastowe |
| Stopień szczegółowości rozliczeń | Sekundę | Za godzinę |
Model zakupów i warstwa usług
W poniższej tabeli opisano obsługę bezserwerową opartą na modelu zakupów, warstwach usług i sprzęcie:
| Kategoria | Obsługiwane | Nieobsługiwane |
|---|---|---|
| Model zakupów | Rdzeń wirtualny | DTU |
| Warstwa usług | Ogólnego przeznaczenia Hiperskala |
Krytyczne dla działania firmy |
| Sprzęt | Seria Standardowa (Gen5) | Wszystkie inne sprzęty |
Skalowanie automatyczne
Szybkość reakcji skalowania
Bezserwerowe bazy danych są uruchamiane na maszynie z wystarczającą pojemnością, aby zaspokoić zapotrzebowanie na zasoby bez przerwy dla dowolnej ilości zasobów obliczeniowych żądanych w ramach limitów ustawionych przez maksymalną wartość rdzeni wirtualnych. Czasami równoważenie obciążenia odbywa się automatycznie, jeśli maszyna nie może zaspokoić zapotrzebowania na zasoby w ciągu kilku minut. Jeśli na przykład zapotrzebowanie na zasoby wynosi 4 rdzenie wirtualne, ale dostępne są tylko 2 rdzenie wirtualne, równoważenie obciążenia może potrwać do kilku minut przed udostępnieniem 4 rdzeni wirtualnych. Baza danych pozostaje w trybie online podczas równoważenia obciążenia z wyjątkiem krótkiego okresu na końcu operacji, gdy połączenia zostaną porzucone.
Zarządzanie pamięcią
W warstwach usług Ogólnego przeznaczenia i Hiperskala pamięć dla baz danych bezserwerowych jest odzyskiwane częściej niż w przypadku aprowizowanych baz danych obliczeniowych. To zachowanie jest ważne, aby kontrolować koszty bezserwerowe i może mieć wpływ na wydajność.
Odzyskiwanie pamięci podręcznej
W przeciwieństwie do aprowizowanych baz danych obliczeniowych pamięć z pamięci podręcznej SQL jest odzyskiwane z bezserwerowej bazy danych, gdy wykorzystanie procesora CPU lub aktywnej pamięci podręcznej jest niskie.
- Wykorzystanie aktywnej pamięci podręcznej jest uznawane za niskie, gdy łączny rozmiar ostatnio używanych wpisów pamięci podręcznej spadnie poniżej progu przez pewien czas.
- Po wyzwoleniu odzyskiwania pamięci podręcznej docelowy rozmiar pamięci podręcznej jest zmniejszany przyrostowo do ułamka poprzedniego rozmiaru i odzyskiwanie będzie kontynuowane tylko wtedy, gdy użycie pozostanie niskie.
- W przypadku odzyskiwania pamięci podręcznej zasady wybierania wpisów pamięci podręcznej do wykluczenia są tymi samymi zasadami wyboru co w przypadku aprowizowania baz danych obliczeniowych, gdy wysokie jest wykorzystanie pamięci.
- Rozmiar pamięci podręcznej nigdy nie jest niższy niż minimalny limit pamięci zdefiniowany przez minimalną liczbę rdzeni wirtualnych.
W bazach danych obliczeniowych bezserwerowych i aprowizowanych można eksmitować wpisy pamięci podręcznej, jeśli jest używana cała dostępna pamięć.
Gdy wykorzystanie procesora CPU jest niskie, wykorzystanie aktywnej pamięci podręcznej może pozostać wysokie w zależności od wzorca użycia i zapobiec odzyskianiu pamięci. Ponadto mogą wystąpić inne opóźnienia po zatrzymaniu aktywności użytkownika przed odzyskaniem pamięci z powodu okresowych procesów w tle odpowiadających wcześniejszej aktywności użytkownika. Na przykład operacje usuwania i zadania oczyszczania magazynu zapytań generują rekordy duchów oznaczone do usunięcia, ale nie są fizycznie usuwane do momentu uruchomienia procesu oczyszczania duchów. Oczyszczanie duchów może obejmować odczytywanie stron danych w pamięci podręcznej.
Nawodnienie pamięci podręcznej
Pamięć podręczna SQL rośnie w miarę pobierania danych z dysku w taki sam sposób i z taką samą szybkością jak w przypadku aprowizowania baz danych. Gdy baza danych jest zajęta, pamięć podręczna może rosnąć bez ograniczeń, gdy jest dostępna pamięć.
Zarządzanie pamięcią podręczną dysku
W warstwie usługi Hiperskala dla warstw obliczeniowych bezserwerowych i aprowizowanych każda replika obliczeniowa używa pamięci podręcznej RBPEX (Resilient Buffer Pool Extension), która przechowuje strony danych na lokalnym dysku SSD w celu zwiększenia wydajności operacji we/wy. Jednak w bezserwerowej warstwie obliczeniowej dla warstwy Hiperskala pamięć podręczna RBPEX dla każdej repliki obliczeniowej automatycznie rośnie i zmniejsza się w odpowiedzi na rosnące i malejące zapotrzebowanie na obciążenie. Maksymalny rozmiar pamięci podręcznej RBPEX może wzrosnąć do trzech razy większej niż maksymalna ilość pamięci skonfigurowanej dla bazy danych. Aby uzyskać szczegółowe informacje na temat maksymalnej ilości pamięci i limitów automatycznego skalowania RBPEX w przypadku bezserwerowych, zobacz Bezserwerowe limity zasobów w warstwie Hiperskala.
Automatyczne wstrzymywanie i automatyczne wznawianie
Obecnie bezserwerowe automatyczne wstrzymanie i automatyczne wznawianie są obsługiwane tylko w warstwie Ogólnego przeznaczenia.
Automatyczne wstrzymywanie
Automatyczne wstrzymywanie jest wyzwalane, jeśli wszystkie następujące warunki są spełnione podczas opóźnienia automatycznego wstrzymywania:
- Liczba sesji = 0
- Procesor CPU = 0 dla obciążenia użytkownika uruchomionego w puli zasobów użytkownika
Dostępna jest opcja wyłączania automatycznego wstrzymowania w razie potrzeby.
Poniższe funkcje nie obsługują automatycznego wstrzymania, ale obsługują skalowanie automatyczne. Jeśli są używane dowolne z następujących funkcji, automatyczne wstrzymanie musi być wyłączone, a baza danych pozostaje w trybie online niezależnie od czasu braku aktywności bazy danych:
- Replikacja geograficzna (aktywne grupy replikacji geograficznej i trybu failover).
- Długoterminowe przechowywanie kopii zapasowych (LTR).
- Baza danych synchronizacji używana w usłudze SQL Data Sync. W przeciwieństwie do baz danych synchronizacji bazy danych koncentratora i baz danych składowych obsługują automatyczne wstrzymanie.
- Alias DNS utworzony dla serwera logicznego zawierającego bezserwerową bazę danych.
- Zadania elastyczne, automatyczna wstrzymywanie bezserwerowej bazy danych nie jest obsługiwana jako baza danych zadań. Bezserwerowe bazy danych objęte zadaniami elastycznymi obsługują automatyczne wstrzymanie. Połączenia zadań wznawiają bazę danych.
Automatyczne wstrzymanie jest tymczasowo blokowane podczas wdrażania niektórych aktualizacji usługi, które wymagają, aby baza danych był w trybie online. W takich przypadkach automatyczne wstrzymanie staje się ponownie dozwolone po zakończeniu aktualizacji usługi.
Rozwiązywanie problemów z automatycznym wstrzymywaniem
Jeśli automatyczne wstrzymywanie jest włączone, a funkcje, które blokują automatyczne wstrzymywanie, nie są używane, ale baza danych nie jest automatycznie wstrzymywane po okresie opóźnienia, wówczas aplikacja lub sesje użytkownika mogą uniemożliwiać automatyczne wstrzymywanie.
Aby sprawdzić, czy z bazą danych są aktualnie połączone jakiekolwiek sesje aplikacji lub użytkownika, połącz się z bazą danych przy użyciu dowolnego narzędzia klienckiego i wykonaj następujące zapytanie:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Napiwek
Po uruchomieniu zapytania upewnij się, że odłącz się od bazy danych. W przeciwnym razie otwarta sesja używana przez zapytanie uniemożliwi automatyczne wstrzymywanie.
- Jeśli zestaw wyników nie jest żaden, oznacza to, że obecnie istnieją sesje uniemożliwiające automatyczne wstrzymanie.
- Jeśli zestaw wyników jest pusty, nadal jest możliwe, że w pewnym momencie w trakcie okresu opóźnienia automatycznego wstrzymania sesje były otwarte (być może przez krótki czas). Aby sprawdzić działanie w okresie opóźnienia, możesz użyć inspekcji usługi Azure SQL i zbadać dane inspekcji dla odpowiedniego okresu.
Ważne
Otwarte sesje, ze współbieżnym wykorzystaniem procesora CPU w puli zasobów użytkownika lub bez niego, to najczęstsza przyczyna braku zgodnego z oczekiwaniami automatycznego wstrzymania bezserwerowej bazy danych.
Automatyczne wznawianie
Automatyczne wznawianie jest wyzwalane, jeśli którykolwiek z następujących warunków jest spełniony w dowolnym momencie:
| Funkcja | Wyzwalacz automatycznego wznawiania |
|---|---|
| Uwierzytelnianie i autoryzacja | Zaloguj się |
| Wykrywanie zagrożeń | Włączanie/wyłączanie ustawień wykrywania zagrożeń na poziomie bazy danych lub serwera. Modyfikowanie ustawień wykrywania zagrożeń na poziomie bazy danych lub serwera. |
| Odnajdywanie i klasyfikacja danych | Dodawanie, modyfikowanie, usuwanie lub wyświetlanie etykiet poufności |
| Inspekcja | Wyświetlanie rekordów inspekcji. Aktualizowanie lub wyświetlanie zasad inspekcji. |
| Maskowanie danych | Dodawanie, modyfikowanie, usuwanie lub wyświetlanie reguł maskowania danych |
| Transparent Data Encryption | Wyświetlanie stanu lub stanu przezroczystego szyfrowania danych |
| Ocena luk w zabezpieczeniach | Skanowania ad hoc i okresowe skanowania w przypadku włączenia |
| Wykonywanie zapytań dotyczących magazynu danych (wydajności) | Modyfikowanie lub wyświetlanie ustawień magazynu zapytań |
| Zalecenia dotyczące wydajności | Wyświetlanie lub stosowanie zaleceń dotyczących wydajności |
| Automatyczne dostrajanie | Stosowanie i weryfikacja zaleceń dotyczących automatycznego dostrajania, takich jak automatyczne indeksowanie |
| Kopiowanie bazy danych | Utwórz bazę danych jako kopię. Eksportuj do pliku BACPAC. |
| Synchronizacja danych SQL | Synchronizacja między bazami danych piasty i składowych, które są uruchamiane zgodnie z konfigurowalnym harmonogramem lub są wykonywane ręcznie |
| Modyfikowanie niektórych metadanych bazy danych | Dodawanie nowych tagów bazy danych. Zmiana maksymalnej liczby rdzeni wirtualnych, minimalnych rdzeni wirtualnych lub opóźnienia automatycznego wstrzymywania. |
| SQL Server Management Studio (SSMS) | W przypadku korzystania z programu SSMS w wersjach starszych niż 18.1 i otwierania nowego okna zapytania dla dowolnej bazy danych na serwerze zostanie wznowiona każda automatycznie wstrzymana baza danych na tym samym serwerze. To zachowanie nie występuje w przypadku korzystania z programu SSMS w wersji 18.1 lub nowszej. |
Monitorowanie, zarządzanie lub inne rozwiązania wykonujące dowolną operację wymienioną powyżej spowoduje wyzwolenie automatycznego wznawiania. Automatyczne wznawianie jest również wyzwalane podczas wdrażania niektórych aktualizacji usługi, które wymagają, aby baza danych był w trybie online.
Łączność
Jeśli baza danych bezserwerowa jest wstrzymana, pierwsza próba połączenia wznawia bazę danych i zwraca błąd informujący, że baza danych jest niedostępna z kodem błędu 40613. Po wznowieniu bazy danych można ponowić próbę zalogowania w celu nawiązania łączności. Klienci bazy danych zgodnie z zaleceniami dotyczącymi logiki ponawiania próby połączenia nie powinni być modyfikowani. Aby uzyskać opcje logiki ponawiania prób połączenia i zalecenia, zobacz:
- Logika ponawiania prób połączenia w programie SqlClient
- Logika ponawiania prób połączenia w usłudze SQL Database przy użyciu platformy Entity Framework Core
- Logika ponawiania prób połączenia w usłudze SQL Database przy użyciu programu Entity Framework 6
- Logika ponawiania prób połączenia w usłudze SQL Database przy użyciu ADO.NET
Opóźnienie
Opóźnienie automatycznego wznawiania i automatycznego wstrzymywania bezserwerowej bazy danych to zazwyczaj 1 minuta automatycznego wznawiania i 1–10 minut po wygaśnięciu okresu opóźnienia w celu automatycznego wstrzymania.
Zarządzane przez klienta szyfrowanie Transparent Data Encryption (BYOK)
Usuwanie lub odwoływanie klucza
W przypadku korzystania z funkcji Transparent Data Encryption (BYOK) zarządzanego przez klienta i bezserwerowej bazy danych jest automatycznie wstrzymana po usunięciu lub odwołaniu klucza, baza danych pozostaje w stanie wstrzymania automatycznego. W takim przypadku po następnym wznowieniu bazy danych baza danych stanie się niedostępna w ciągu około 10 minut. Gdy baza danych stanie się niedostępna, proces odzyskiwania jest taki sam jak w przypadku aprowizowanych baz danych obliczeniowych. Jeśli bezserwerowa baza danych jest w trybie online w przypadku usunięcia lub odwołania klucza, baza danych stanie się również niedostępna w ciągu około 10 minut w taki sam sposób, jak w przypadku aprowizowania baz danych obliczeniowych.
Wymiana kluczy
W przypadku korzystania z funkcji Transparent Data Encryption (BYOK) zarządzanego przez klienta i automatycznego wstrzymywania bezserwerowego jest włączone, baza danych jest automatycznie wznawiana za każdym razem, gdy klucze są obracane, a następnie automatycznie wstrzymane po spełnieniu warunków automatycznego wstrzymywania.
Tworzenie nowej bezserwerowej bazy danych
Utworzenie nowej bazy danych lub przeniesienie istniejącej bazy danych do bezserwerowej warstwy obliczeniowej jest zgodne z tym samym wzorcem co utworzenie nowej bazy danych w aprowizowanej warstwie obliczeniowej i obejmuje następujące dwa kroki:
Określ cel usługi. Cel usługi określa warstwę usługi, konfigurację sprzętu i maksymalną liczbę rdzeni wirtualnych. Aby uzyskać informacje o opcjach celu usługi, zobacz Limity zasobów bezserwerowych
Opcjonalnie określ minimalną liczbę rdzeni wirtualnych i opóźnienie automatycznego wstrzymywania, aby zmienić ich wartości domyślne. W poniższej tabeli przedstawiono dostępne wartości tych parametrów.
Parametr Opcje wartości Domyślna wartość Minimalna liczba rdzeni wirtualnych Zależy od maksymalnej liczby skonfigurowanych rdzeni wirtualnych — zobacz limity zasobów. 0,5 rdzeni wirtualnych Opóźnienie automatycznego wstrzymywania Minimum: 15 minut
Maksimum: 10 080 minut (7 dni)
Przyrosty: 1 minuta
Wyłącz automatyczne wstrzymanie: -160 min
W poniższych przykładach utworzono nową bazę danych w bezserwerowej warstwie obliczeniowej.
Korzystanie z witryny Azure Portal
Użyj PowerShell
Utwórz nową bezserwerową bazę danych ogólnego przeznaczenia przy użyciu następującego przykładu programu PowerShell:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Interfejs wiersza polecenia platformy Azure
Utwórz nową bazę danych ogólnego przeznaczenia bezserwerową przy użyciu następującego przykładu interfejsu wiersza polecenia platformy Azure:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Korzystanie z języka Transact-SQL (T-SQL)
W przypadku tworzenia nowej bezserwerowej bazy danych przy użyciu języka T-SQL wartości domyślne są stosowane dla minimalnych rdzeni wirtualnych i opóźnienia automatycznego wstrzymania. Ich wartości można następnie zmienić z witryny Azure Portal lub za pośrednictwem interfejsu API, w tym programu PowerShell, interfejsu wiersza polecenia platformy Azure i interfejsu REST.
Aby uzyskać szczegółowe informacje, zobacz CREATE DATABASE (TWORZENIE BAZY DANYCH).
Utwórz nową bazę danych bezserwerowej ogólnego przeznaczenia przy użyciu następującego przykładu języka T-SQL:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Przenoszenie bazy danych między warstwami obliczeniowymi lub warstwami usług
Bazę danych można przenosić między aprowizowaną warstwą obliczeniową i bezserwerową warstwą obliczeniową.
Bazę danych bezserwerową można również przenieść z warstwy usługi Ogólnego przeznaczenia do warstwy usługi Hiperskala. Aby dowiedzieć się więcej, zobacz Zarządzanie bazami danych w warstwie Hiperskala.
Podczas przenoszenia bazy danych między warstwami obliczeniowymi określ parametr modelu obliczeniowego jako Serverless lub Provisioned w przypadku korzystania z programu PowerShell lub interfejsu wiersza polecenia platformy Azure albo SERVICE_OBJECTIVE podczas korzystania z języka T-SQL. Przejrzyj limity zasobów, aby zidentyfikować odpowiedni cel usługi.
W poniższych przykładach przeniesiono istniejącą bazę danych z aprowizowanego środowiska obliczeniowego do bezserwerowego.
Użyj PowerShell
Przenieś aprowizowaną bazę danych ogólnego przeznaczenia zasobów obliczeniowych do warstwy obliczeniowej bezserwerowej przy użyciu następującego przykładu programu PowerShell:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Interfejs wiersza polecenia platformy Azure
Przenieś aprowizowaną bazę danych ogólnego przeznaczenia obliczeniowej do warstwy obliczeniowej bezserwerowej przy użyciu następującego przykładu interfejsu wiersza polecenia platformy Azure:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Korzystanie z języka Transact-SQL (T-SQL)
W przypadku przenoszenia bazy danych między warstwami obliczeniowymi przy użyciu języka T-SQL wartości domyślne są stosowane dla minimalnych rdzeni wirtualnych i opóźnienia automatycznego wstrzymania. Ich wartości można następnie zmienić z witryny Azure Portal lub za pośrednictwem interfejsu API, w tym programu PowerShell, interfejsu wiersza polecenia platformy Azure i interfejsu REST. Aby uzyskać więcej informacji, zobacz ALTER DATABASE.
Przenieś aprowizowaną bazę danych ogólnego przeznaczenia obliczeniowej do bezserwerowej warstwy obliczeniowej przy użyciu następującego przykładu języka T-SQL:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Modyfikowanie konfiguracji bezserwerowej
Użyj PowerShell
Użyj polecenia Set-AzSqlDatabase , aby zmodyfikować maksymalną lub minimalną liczbę rdzeni wirtualnych oraz opóźnienie automatycznego wstrzymania. MaxVcoreUżyj argumentów , MinVcorei AutoPauseDelayInMinutes . Automatyczne wstrzymywanie bezserwerowe nie jest obecnie obsługiwane w warstwie Hiperskala, więc argument opóźnienia automatycznego wstrzymania ma zastosowanie tylko do warstwy Ogólnego przeznaczenia.
Interfejs wiersza polecenia platformy Azure
Użyj polecenia az sql db update , aby zmodyfikować maksymalną lub minimalną liczbę rdzeni wirtualnych oraz opóźnienie automatycznego wstrzymania. capacityUżyj argumentów , min-capacityi auto-pause-delay . Automatyczne wstrzymywanie bezserwerowe nie jest obecnie obsługiwane w warstwie Hiperskala, więc argument opóźnienia automatycznego wstrzymania ma zastosowanie tylko do warstwy Ogólnego przeznaczenia.
Monitor
Używane i rozliczane zasoby
Zasoby bezserwerowej bazy danych obejmują jednostki pakietu aplikacji, wystąpienia SQL i puli zasobów użytkownika.
Pakiet aplikacji
Pakiet aplikacji to zewnętrzna granica zarządzania zasobami dla bazy danych, niezależnie od tego, czy baza danych znajduje się w warstwie obliczeniowej bezserwerowej, czy aprowizowanej. Pakiet aplikacji zawiera wystąpienie SQL i usługi zewnętrzne, takie jak Wyszukiwanie pełnotekstowe, które łącznie zawierają zakres wszystkich zasobów użytkownika i systemu używanych przez bazę danych w usłudze SQL Database. Wystąpienie SQL zazwyczaj dominuje w ogólnym wykorzystaniu zasobów w pakiecie aplikacji.
Pula zasobów użytkownika
Pula zasobów użytkownika to wewnętrzna granica zarządzania zasobami dla bazy danych, niezależnie od tego, czy baza danych znajduje się w warstwie obliczeniowej bezserwerowej, czy aprowizowanej. Pula zasobów użytkownika określa zakresy procesora CPU i operacji we/wy dla obciążenia użytkownika generowanego przez zapytania DDL (CREATE i ALTER) oraz DML (INSERT, UPDATE, DELETE i MERGE oraz SELECT). Te zapytania zazwyczaj stanowią najbardziej znaczną część wykorzystania w pakiecie aplikacji.
Metryki
Poniższa tabela zawiera metryki monitorowania użycia zasobów pakietu aplikacji i puli zasobów użytkownika bezserwerowej bazy danych, w tym wszystkich replik geograficznych:
| Encja | Metryczne | opis | Lekcji |
|---|---|---|---|
| Pakiet aplikacji | app_cpu_percent | Procent rdzeni wirtualnych używanych przez aplikację względem maksymalnej liczby rdzeni wirtualnych dozwolonych dla aplikacji. W przypadku bezserwerowej warstwy Hiperskala ta metryka jest uwidoczniona dla wszystkich replik podstawowych, nazwanych replik i replik geograficznych. | Procent |
| Pakiet aplikacji | app_cpu_billed | Ilość zasobów obliczeniowych rozliczanych za aplikację w okresie raportowania. Kwota zapłacona w tym okresie jest produktem tej metryki i ceny jednostkowej rdzeni wirtualnych. Wartości tej metryki są określane przez agregowanie maksymalnej używanej pamięci i użycia pamięci na sekundę. Jeśli użyta kwota jest mniejsza niż minimalna ilość aprowizowana zgodnie z minimalnymi rdzeniami wirtualnymi i minimalną ilością pamięci, zostanie naliczona minimalna kwota aprowizacji. Aby porównać użycie procesora CPU i pamięci na potrzeby rozliczeń, pamięć jest normalizowana do jednostek rdzeni wirtualnych przez ponowne skalowanie ilości pamięci (w GB) do wartości 3 GB na rdzeń wirtualny. W przypadku bezserwerowej warstwy Hiperskala ta metryka jest uwidoczniona dla repliki podstawowej i wszystkich nazwanych replik. |
Sekundy rdzeni wirtualnych |
| Pakiet aplikacji | app_cpu_billed_HA_replicas | Dotyczy tylko bezserwerowej warstwy Hiperskala. Suma zasobów obliczeniowych rozliczanych we wszystkich aplikacjach dla replik wysokiej dostępności w okresie raportowania. Ta suma jest ograniczona do replik wysokiej dostępności należących do repliki podstawowej lub replik ha należących do danej nazwanej repliki. Przed obliczeniem tej sumy w replikach wysokiej dostępności ilość zasobów obliczeniowych rozliczanych dla pojedynczej repliki wysokiej dostępności jest określana w taki sam sposób jak w przypadku repliki podstawowej lub nazwanej repliki. W przypadku bezserwerowej warstwy Hiperskala ta metryka jest uwidoczniona dla wszystkich replik podstawowych, nazwanych replik i replik geograficznych. Kwota zapłacona w okresie raportowania jest produktem tej metryki i ceny jednostkowej rdzeni wirtualnych. | Sekundy rdzeni wirtualnych |
| Pakiet aplikacji | app_memory_percent | Procent pamięci używanej przez aplikację względem maksymalnej ilości pamięci dozwolonej dla aplikacji. W przypadku bezserwerowej warstwy Hiperskala ta metryka jest uwidoczniona dla wszystkich replik podstawowych, nazwanych replik i replik geograficznych. | Procent |
| Pula zasobów użytkownika | cpu_percent | Procent rdzeni wirtualnych używanych przez obciążenie użytkownika względem maksymalnej liczby rdzeni wirtualnych dozwolonych dla obciążenia użytkownika. | Procent |
| Pula zasobów użytkownika | data_IO_percent | Procent operacji we/wy na sekundę danych używanych przez obciążenie użytkownika w stosunku do maksymalnej liczby operacji we/wy na sekundę dozwolonych dla obciążenia użytkownika. | Procent |
| Pula zasobów użytkownika | log_IO_percent | Procent mb/s dziennika używanych przez obciążenie użytkownika względem maksymalnej liczby MB/s dziennika dozwolonych dla obciążenia użytkownika. | Procent |
| Pula zasobów użytkownika | workers_percent | Procent procesów roboczych używanych przez obciążenie użytkownika względem maksymalnej liczby procesów roboczych dozwolonych dla obciążenia użytkownika. | Procent |
| Pula zasobów użytkownika | sessions_percent | Procent sesji używanych przez obciążenie użytkownika względem maksymalnej liczby sesji dozwolonych dla obciążenia użytkownika. | Procent |
Wstrzymywanie i wznawianie stanu
W przypadku bezserwerowej bazy danych z włączonym automatycznym wstrzymowaniem stan raportów zawiera następujące wartości:
| Stan | opis |
|---|---|
| Tryb online | Baza danych jest w trybie online. |
| Wstrzymywanie | Baza danych przechodzi z trybu online na wstrzymaną. |
| Wstrzymana | Baza danych jest wstrzymana. |
| Wznawianie | Baza danych przechodzi z wstrzymania do trybu online. |
Korzystanie z witryny Azure Portal
W witrynie Azure Portal stan bazy danych jest wyświetlany na stronie przeglądu bazy danych i na stronie przeglądu jej serwera. Ponadto w witrynie Azure Portal można wyświetlić historię wstrzymywania i wznawiania zdarzeń bezserwerowej bazy danych w dzienniku aktywności.
Użyj PowerShell
Wyświetl bieżący stan bazy danych, korzystając z następującego przykładu programu PowerShell:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Interfejs wiersza polecenia platformy Azure
Wyświetl bieżący stan bazy danych przy użyciu następującego przykładu interfejsu wiersza polecenia platformy Azure:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Limity zasobów
Aby uzyskać informacje o limitach zasobów, zobacz warstwa obliczeniowa bezserwerowa.
Rozliczenia
Ilość zasobów obliczeniowych rozliczanych za bezserwerową bazę danych jest maksymalną ilością używanego procesora CPU i pamięci używanej w każdej sekundzie. Jeśli ilość używanego procesora CPU i pamięci jest mniejsza niż minimalna ilość aprowizowana dla każdego zasobu, zostanie naliczona aprowizowana kwota. Aby porównać procesor CPU z pamięcią na potrzeby rozliczeń, pamięć jest znormalizowana do jednostek rdzeni wirtualnych przez ponowne skalowanie liczby GB o 3 GB na rdzeń wirtualny.
- Opłaty za zasób: procesor i pamięć
- Kwota naliczana: cena jednostkowa rdzeni wirtualnych * maksymalna (minimalna liczba rdzeni wirtualnych, używane rdzenie wirtualne, minimalna ilość pamięci GB * 1/3, używana pamięć GB * 1/3)
- Częstotliwość rozliczeń: na sekundę
Cena jednostkowa rdzenia wirtualnego to koszt na rdzeń wirtualny na sekundę.
Zobacz stronę cennika usługi Azure SQL Database, aby poznać konkretne ceny jednostkowe w danym regionie.
Ilość zasobów obliczeniowych rozliczanych bezserwerowych dla bazy danych ogólnego przeznaczenia lub podstawowa lub nazwana replika w warstwie Hiperskala jest uwidoczniona przez następującą metrykę:
- Metryka: app_cpu_billed (sekundy rdzeni wirtualnych)
- Definicja: maksymalna (minimalna liczba rdzeni wirtualnych, używane rdzenie wirtualne, minimalna ilość pamięci GB * 1/3, używana pamięć GB * 1/3)
- Częstotliwość raportowania: na minutę na podstawie pomiarów na sekundę zagregowanych w ciągu 1 minuty.
Ilość zasobów obliczeniowych rozliczanych bezserwerowych dla replik wysokiej dostępności w warstwie Hiperskala należących do repliki podstawowej lub dowolnej nazwanej repliki jest uwidoczniona przez następującą metryki:
- Metryka: app_cpu_billed_HA_replicas (sekundy rdzeni wirtualnych)
- Definicja: Suma maksymalnej (minimalna liczba rdzeni wirtualnych, używane rdzenie wirtualne, minimalna ilość pamięci GB * 1/3, używana pamięć GB * 1/3) dla wszystkich replik wysokiej dostępności należących do ich zasobu nadrzędnego.
- Nadrzędny zasób i punkt końcowy metryki: replika podstawowa i każda nazwana replika oddzielnie uwidacznia tę metryki, która mierzy obliczanie rozliczane za wszystkie skojarzone repliki wysokiej dostępności.
- Częstotliwość raportowania: na minutę na podstawie pomiarów na sekundę zagregowanych w ciągu 1 minuty.
Minimalny rachunek za obliczenia
Jeśli bezserwerowa baza danych jest wstrzymana, rachunek obliczeniowy wynosi zero. Jeśli baza danych bezserwerowa nie jest wstrzymana, minimalny rachunek za obliczenia nie jest mniejszy niż maksymalna liczba rdzeni wirtualnych (minimalna liczba rdzeni wirtualnych, minimalna ilość pamięci GB * 1/3).
Przykłady:
- Załóżmy, że baza danych bezserwerowa w warstwie Ogólnego przeznaczenia nie została wstrzymana i skonfigurowana z maksymalną 8 rdzeniami wirtualnymi i minimalną 1 rdzenią wirtualną odpowiadającą minimalnej pamięci 3,0 GB. Następnie minimalny rachunek za obliczenia jest oparty na maksymalnej (1 rdzeń wirtualny, 3,0 GB * 1 rdzeń wirtualny / 3 GB) = 1 rdzeń wirtualny.
- Załóżmy, że baza danych bezserwerowa w warstwie Ogólnego przeznaczenia nie jest wstrzymana i skonfigurowana z 4 maksymalnymi rdzeniami wirtualnymi i minimalnymi rdzeniami wirtualnymi 0,5 odpowiadającymi minimalnej pamięci 2,1 GB. Następnie minimalny rachunek za obliczenia jest oparty na maksymalnej (0,5 rdzeni wirtualnych, 2,1 GB * 1 rdzeni wirtualnych / 3 GB) = 0,7 rdzeni wirtualnych.
- Załóżmy, że bezserwerowa baza danych w warstwie Hiperskala ma replikę podstawową z jedną repliką wysokiej dostępności i repliką o nazwie bez replik wysokiej dostępności. Załóżmy, że każda replika jest skonfigurowana z maksymalną 8 rdzeniami wirtualnymi i minimalną 1 rdzenią wirtualną odpowiadającą 3 GB minimalnej pamięci. Następnie minimalny rachunek za obliczenia dla repliki podstawowej, repliki wysokiej dostępności i nazwanej repliki są oparte na maksymalnej (1 rdzeń wirtualny, 3 GB * 1 rdzeń wirtualny / 3 GB) = 1 rdzeń wirtualny.
Kalkulator cen usługi Azure SQL Database dla bezserwerowych może służyć do określenia minimalnej ilości pamięci konfigurowalnej na podstawie liczby skonfigurowanych maksymalnej i minimalnej liczby rdzeni wirtualnych. Zgodnie z regułą, jeśli minimalna skonfigurowana liczba rdzeni wirtualnych jest większa niż 0,5 rdzeni wirtualnych, minimalny rachunek za obliczenia jest niezależny od minimalnej skonfigurowanej pamięci i tylko na podstawie liczby skonfigurowanych minimalnych rdzeni wirtualnych.
Przykłady scenariuszy
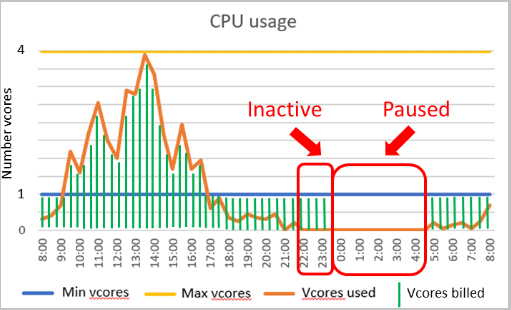
Rozważmy bezserwerową bazę danych w warstwie Ogólnego przeznaczenia skonfigurowaną z co najmniej 1 rdzeniami wirtualnymi i 4 maksymalnymi rdzeniami wirtualnymi. Ta konfiguracja odpowiada około 3 GB minimalnej pamięci i maksymalnej pamięci 12 GB. Załóżmy, że opóźnienie automatycznego wstrzymania jest ustawione na 6 godzin, a obciążenie bazy danych jest aktywne w ciągu pierwszych 24 godzin w okresie 24-godzinnym i w przeciwnym razie nieaktywne.
W takim przypadku baza danych jest rozliczana za zasoby obliczeniowe i magazyn w ciągu pierwszych 8 godzin. Mimo że baza danych jest nieaktywna po drugiej godzinie, nadal jest rozliczana za obliczenia w ciągu kolejnych 6 godzin na podstawie minimalnej aprowizowanej mocy obliczeniowej, gdy baza danych jest w trybie online. Opłaty za magazyn są naliczane tylko w pozostałej części okresu 24-godzinnego, gdy baza danych jest wstrzymana.
Dokładniej, rachunek obliczeniowy w tym przykładzie jest obliczany w następujący sposób:
| Przedział czasu | Rdzenie wirtualne używane w każdej sekundzie | Każdą sekundę użyto GB | Rozliczany wymiar obliczeniowy | Rozliczane sekundy rdzeni wirtualnych w interwale czasu |
|---|---|---|---|---|
| 0:00-1:00 | 100 | 9 | Używane rdzenie wirtualne | 4 rdzenie wirtualne * 3600 sekund = 14400 sekund wirtualnych |
| 1:00-2:00 | 1 | 12 | Użycie pamięci | 12 GB * 1/3 * 3600 sekund = 14400 sekund wirtualnych |
| 2:00-8:00 | 0 | 0 | Minimalna aprowizowana pamięć | 3 GB * 1/3 * 21600 sekund = 21600 sekund wirtualnych |
| 8:00-24:00 | 0 | 0 | Nie są naliczane opłaty za zasoby obliczeniowe podczas wstrzymania | 0 sekund wirtualnych |
| Łączna liczba sekund rdzeni wirtualnych rozliczanych w ciągu 24 godzin | 50 400 sekund wirtualnych |
Załóżmy, że cena jednostkowa obliczeń wynosi $0.000145/vCore/second. Następnie obliczanie rozliczane za ten okres 24-godzinny jest produktem ceny jednostkowej obliczeń i naliczanych sekund rdzeni wirtualnych: $0.000145/vCore/second * 50400 sekund rdzeni wirtualnych ~ $7.31.
Korzyść użycia hybrydowego platformy Azure i pojemność zarezerwowana
Korzyść użycia hybrydowego platformy Azure (AHB) i rabaty na pojemność zarezerwowaną nie mają zastosowania do warstwy obliczeniowej bezserwerowej.
Dostępne regiony
Bezserwerowe dla warstw Ogólnego przeznaczenia i Hiperskala z obsługą maksymalnie 40 rdzeni wirtualnych jest dostępne na całym świecie z wyjątkiem następujących regionów:
- Chiny Wschodnie
- Chiny Północne
- Niemcy Środkowe
- Niemcy Północno-Wschodnie
- US Gov Central (Iowa)
Regiony obsługujące maksymalnie 80 rdzeni wirtualnych bez stref dostępności dla warstw Ogólnego przeznaczenia i Hiperskala
Obecnie maksymalna liczba rdzeni wirtualnych w warstwach Ogólnego przeznaczenia i Hiperskala jest obecnie obsługiwana w następujących regionach:
- Australia Środkowa 1
- Australia Środkowa 2
- Australia Wschodnia
- Australia Południowo-Wschodnia
- Brazylia Południowa
- Brazylia Południowo–Wschodnia
- Kanada Środkowa
- Kanada Wschodnia
- Środkowe stany USA
- Chiny Wschodnie 2
- Chiny Wschodnie 3
- Chiny Północne 2
- Chiny Północne 3
- Azja Wschodnia
- East US
- Wschodnie stany USA 2
- Francja Środkowa
- Francja Południowa
- Niemcy Północne
- Niemcy Środkowo-Zachodnie
- Indie Środkowe
- Indie południowe
- Izrael Centralny
- Włochy Północne
- Japonia Wschodnia
- Japonia Zachodnia
- Jio Indie Środkowe
- Indie Zachodnie (Jio)
- Korea Środkowa
- Korea Południowa
- Maylaysia Południowa
- Meksyk Środkowy
- Północno-środkowe stany USA
- Europa Północna
- Norwegia Wschodnia
- Norwegia Zachodnia
- Polska Środkowa
- Katar Środkowy
- Północna Republika Południowej Afryki
- Zachodnia Republika Południowej Afryki
- South Central US
- Southeast Asia
- Hiszpania Środkowa
- Szwecja Środkowa
- Szwecja Południowa
- Szwajcaria Północna
- Szwajcaria Zachodnia
- Północny Tajwan
- Tajwan Północno-zachodni
- Środkowe Zjednoczone Emiraty Arabskie
- Północne Zjednoczone Emiraty Arabskie
- Południowe Zjednoczone Królestwo
- Zachodnie Zjednoczone Królestwo
- Us Gov Wschód
- US Gov Southcentral
- US Gov Southwest
- West Europe
- Zachodnio-środkowe stany USA
- Zachodnie stany USA
- Zachodnie stany USA 2
- Zachodnie stany USA 3
Regiony obsługujące maksymalnie 80 rdzeni wirtualnych ze strefami dostępności dla warstw Ogólnego przeznaczenia i Hiperskala
Obecnie 80 maksymalnych rdzeni wirtualnych z obsługą stref dostępności w bezserwerowych warstwach Ogólnego przeznaczenia i Hiperskala jest dostępnych w następujących regionach z zaplanowanymi większą regionach:
- Australia Wschodnia
- Brazylia Południowa
- Kanada Środkowa
- Central US
- Azja Wschodnia
- East US
- Wschodnie stany USA 2
- Francja Środkowa
- Niemcy Środkowo-Zachodnie
- Indie Środkowe
- Japonia Wschodnia
- Korea Środkowa
- Europa Północna
- Północna Republika Południowej Afryki
- South Central US
- Southeast Asia
- Szwecja Środkowa
- Północne Zjednoczone Emiraty Arabskie
- Południowe Zjednoczone Królestwo
- Us Gov Wschód
- West Europe
- Zachodnie stany USA 2
- Zachodnie stany USA 3
Powiązana zawartość
- Aby rozpocząć, zobacz Szybki start: tworzenie pojedynczej bazy danych — Azure SQL Database.
- Aby zapoznać się z opcjami warstwy usług bezserwerowych, zobacz Ogólnego przeznaczenia i Hiperskala.