Model zakupów rdzeni wirtualnych — Azure SQL Database
Dotyczy: ![]() Azure SQL Database
Azure SQL Database
W tym artykule przedstawiono model zakupów rdzeni wirtualnych dla usługi Azure SQL Database.
Omówienie
Rdzeń wirtualny (rdzeń wirtualny) reprezentuje procesor logiczny i oferuje opcję wyboru właściwości fizycznych sprzętu (na przykład liczby rdzeni, pamięci i rozmiaru magazynu). Model zakupów oparty na rdzeniach wirtualnych zapewnia elastyczność, kontrolę, przejrzystość użycia poszczególnych zasobów oraz prosty sposób tłumaczenia wymagań dotyczących obciążeń lokalnych na chmurę. Ten model optymalizuje cenę i umożliwia wybór zasobów obliczeniowych, pamięci i magazynu na podstawie potrzeb związanych z obciążeniem.
W modelu zakupów opartym na rdzeniach wirtualnych koszty zależą od wyboru i użycia:
- Warstwa usług
- Zapisz konfigurację sprzętu
- Zasoby obliczeniowe (liczba rdzeni wirtualnych i ilość pamięci)
- Magazyn zarezerwowanej bazy danych
- Rzeczywisty magazyn kopii zapasowych
Ważne
Za zasoby obliczeniowe, we/wy i magazyn danych i dzienników są naliczane opłaty za bazę danych lub elastyczną pulę. Opłata za magazyn kopii zapasowych jest naliczana za każdą bazę danych. Aby uzyskać szczegółowe informacje o cenach, zobacz stronę cennika usługi Azure SQL Database.
Porównanie modeli zakupów rdzeni wirtualnych i jednostek DTU
Model zakupów oparty na rdzeniach wirtualnych używany przez usługę Azure SQL Database zapewnia kilka korzyści w modelu zakupów opartym na jednostkach DTU:
- Wyższe limity mocy obliczeniowej, pamięci, operacji we/wy i magazynu.
- Wybór konfiguracji sprzętu w celu lepszego dopasowania wymagań obliczeniowych i pamięci obciążenia.
- Rabaty cenowe za Korzyść użycia hybrydowego platformy Azure (AHB).
- Większa przejrzystość szczegółów sprzętu, które zasilają obliczenia, co ułatwia planowanie migracji z wdrożeń lokalnych.
- Cennik wystąpień zarezerwowanych jest dostępny tylko dla modelu zakupów rdzeni wirtualnych.
- Wyższy stopień szczegółowości skalowania z dostępnymi wieloma rozmiarami obliczeniowymi.
Aby uzyskać pomoc dotyczącą wybierania między modelami zakupów rdzeni wirtualnych i jednostek DTU, zobacz różnice między modelami zakupów opartymi na rdzeniach wirtualnych i jednostkach DTU
Compute
Model zakupów oparty na rdzeniach wirtualnych ma aprowizowaną warstwę obliczeniową i warstwę obliczeniową bezserwerową . W aprowizowanej warstwie obliczeniowej koszt obliczeniowy odzwierciedla łączną pojemność obliczeniową w sposób ciągły aprowizowany dla aplikacji niezależnie od działania obciążenia. Wybierz alokację zasobów, która najlepiej odpowiada potrzebom biznesowym na podstawie wymagań dotyczących rdzeni wirtualnych i pamięci, a następnie skaluj zasoby w górę i w dół zgodnie z potrzebami obciążenia. W bezserwerowej warstwie obliczeniowej dla usługi Azure SQL Database zasoby obliczeniowe są skalowane automatycznie na podstawie pojemności obciążenia i rozliczane za ilość używanej mocy obliczeniowej na sekundę.
Podsumowując:
- Podczas gdy aprowizowana warstwa obliczeniowa zapewnia określoną ilość zasobów obliczeniowych, które są stale aprowidowane niezależnie od działania obciążenia, bezserwerowa warstwa obliczeniowa automatycznie skaluje zasoby obliczeniowe na podstawie działania obciążenia.
- Podczas gdy aprowizowana warstwa obliczeniowa nalicza opłaty za ilość zasobów obliczeniowych aprowizowanych w stałej cenie za godzinę, bezserwerowa warstwa obliczeniowa nalicza opłaty za ilość używanej mocy obliczeniowej na sekundę.
Niezależnie od warstwy obliczeniowej trzy dodatkowe repliki pomocnicze o wysokiej dostępności są automatycznie przydzielane w warstwie usługi Krytyczne dla działania firmy w celu zapewnienia wysokiej odporności na awarie i szybkie przełączanie w tryb failover. Te dodatkowe repliki stanowią koszt około 2,7 razy wyższy niż w warstwie usługi Ogólnego przeznaczenia. Podobnie wyższy koszt magazynowania na GB w warstwie usługi Krytyczne dla działania firmy odzwierciedla wyższe limity operacji we/wy i mniejsze opóźnienie lokalnego magazynu SSD.
W warstwie Hiperskala klienci kontrolują liczbę dodatkowych replik wysokiej dostępności z zakresu od 0 do 4, aby uzyskać poziom odporności wymaganej przez aplikacje podczas kontrolowania kosztów.
Aby uzyskać więcej informacji na temat obliczeń w usłudze Azure SQL Database, zobacz Zasoby obliczeniowe (procesor CPU i pamięć).
Limity zasobów
W przypadku limitów zasobów rdzeni wirtualnych przejrzyj dostępne konfiguracje sprzętu, a następnie przejrzyj limity zasobów dla:
Magazyn danych i dzienników
Następujące czynniki wpływają na ilość miejsca do magazynowania używanego na potrzeby plików danych i dzienników oraz mają zastosowanie do warstw Ogólnego przeznaczenia i Krytyczne dla działania firmy.
- Każdy rozmiar obliczeniowy obsługuje konfigurowalny maksymalny rozmiar danych z domyślnym rozmiarem 32 GB.
- Podczas konfigurowania maksymalnego rozmiaru danych dodatkowe 30 procent rozliczanego magazynu jest automatycznie dodawane dla pliku dziennika.
- W warstwie
tempdbusługi Ogólnego przeznaczenia używa lokalnego magazynu SSD, a ten koszt magazynu jest uwzględniony w cenie rdzeni wirtualnych. - W warstwie usługi
tempdbKrytyczne dla działania firmy udziały lokalnego magazynu SSD z plikami danych i dziennika, atempdbkoszt magazynowania jest uwzględniany w cenie rdzeni wirtualnych. - W warstwach Ogólnego przeznaczenia i Krytyczne dla działania firmy opłaty są naliczane za maksymalny rozmiar magazynu skonfigurowany dla bazy danych lub elastycznej puli.
- W przypadku usługi SQL Database można wybrać dowolny maksymalny rozmiar danych z zakresu od 1 GB do obsługiwanego rozmiaru magazynu w przyrostach 1 GB.
Następujące zagadnienia dotyczące magazynu mają zastosowanie do warstwy Hiperskala:
- Maksymalny rozmiar magazynu danych jest ustawiony na 100 TB i nie można go skonfigurować.
- Opłaty są naliczane tylko za przydzielony magazyn danych, a nie za maksymalny magazyn danych.
- Nie są naliczane opłaty za magazyn dzienników.
tempdbużywa lokalnego magazynu SSD, a jego koszt jest uwzględniony w cenie rdzeni wirtualnych. Aby monitorować bieżący przydzielony i używany rozmiar magazynu danych w usłudze SQL Database, użyj odpowiednio metryk usługi Azure Monitor allocated_data_storage i magazynu.
Aby monitorować bieżący przydzielony i używany rozmiar magazynu poszczególnych plików danych i dzienników w bazie danych przy użyciu języka T-SQL, użyj widoku sys.database_files i funkcji FILEPROPERTY(... , 'SpaceUsed').
Napiwek
W pewnych okolicznościach może być konieczne zmniejszenie bazy danych w celu odzyskania nieużywanego miejsca. Aby uzyskać więcej informacji, zobacz Zarządzanie miejscem na pliki w usłudze Azure SQL Database.
Magazyn kopii zapasowych
Magazyn kopii zapasowych bazy danych jest przydzielany do obsługi funkcji przywracania do punktu w czasie (PITR) i długoterminowego przechowywania (LTR) usługi SQL Database. Ten magazyn jest oddzielony od magazynu danych i plików dziennika i jest rozliczany oddzielnie.
- PitR: w warstwach Ogólnego przeznaczenia i Krytyczne dla działania firmy poszczególne kopie zapasowe bazy danych są automatycznie kopiowane do usługi Azure Storage. Rozmiar magazynu zwiększa się dynamicznie w miarę tworzenia nowych kopii zapasowych. Magazyn jest używany przez pełne, różnicowe i transakcyjne kopie zapasowe dziennika. Użycie magazynu zależy od szybkości zmiany bazy danych i okresu przechowywania skonfigurowanego dla kopii zapasowych. Można skonfigurować oddzielny okres przechowywania dla każdej bazy danych z zakresu od 1 do 35 dni dla usługi SQL Database. Ilość magazynu kopii zapasowych równa skonfigurowanemu maksymalnemu rozmiarowi danych nie jest naliczana za dodatkową opłatę.
- LTR: Można również skonfigurować długoterminowe przechowywanie pełnych kopii zapasowych przez maksymalnie 10 lat. Jeśli skonfigurujesz zasady LTR, te kopie zapasowe są przechowywane automatycznie w usłudze Azure Blob Storage, ale możesz kontrolować częstotliwość kopiowania kopii zapasowych. Aby spełnić różne wymagania dotyczące zgodności, możesz wybrać różne okresy przechowywania dla cotygodniowych, miesięcznych i/lub corocznych kopii zapasowych. Wybrana konfiguracja określa ilość miejsca do magazynowania na potrzeby kopii zapasowych LTR. Aby uzyskać więcej informacji, zobacz Długoterminowe przechowywanie kopii zapasowych.
Aby uzyskać informacje na temat magazynu kopii zapasowych w warstwie Hiperskala, zobacz Automatyczne kopie zapasowe baz danych w warstwie Hiperskala.
Warstwy usług
Opcje warstwy usług w modelu zakupów rdzeni wirtualnych obejmują ogólnego przeznaczenia, Krytyczne dla działania firmy i hiperskala. Warstwa usługi zazwyczaj określa typ magazynu i wydajność, wysoką dostępność i opcje odzyskiwania po awarii oraz dostępność niektórych funkcji, takich jak OLTP w pamięci.
| Przypadek użycia | Ogólnego przeznaczenia | Krytyczne dla działania firmy | Hiperskala |
|---|---|---|---|
| Najlepsze dla | Większość obciążeń biznesowych. Oferuje zorientowane na budżet, zrównoważone i skalowalne opcje zasobów obliczeniowych i magazynowych. | Oferuje aplikacjom biznesowym najwyższą odporność na awarie przy użyciu kilku replik pomocniczych o wysokiej dostępności i zapewnia najwyższą wydajność operacji we/wy. | Najróżniejsze obciążenia, w tym obciążenia z wysoce skalowalnymi wymaganiami dotyczącymi magazynu i skali odczytu. Zapewnia większą odporność na awarie, umożliwiając konfigurację więcej niż jednej repliki pomocniczej o wysokiej dostępności. |
| Rozmiar obliczeniowy | Od 2 do 128 rdzeni wirtualnych | Od 2 do 128 rdzeni wirtualnych | Od 2 do 128 rdzeni wirtualnych |
| Typ magazynu | Magazyn zdalny w warstwie Premium (na wystąpienie) | Superszybkie lokalny magazyn SSD (na wystąpienie) | Oddzielony magazyn z lokalną pamięcią podręczną SSD (na replikę obliczeniową) |
| Rozmiar magazynu | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 100 TB |
| Liczba operacji we/wy na sekundę | 320 operacji we/wy na sekundę na rdzeń wirtualny z maksymalną 16 000 operacji we/wy na sekundę | 4000 operacji we/wy na sekundę na rdzeń wirtualny z maksymalną 327 680 operacjami we/wy na sekundę | 327 680 operacji we/wy na sekundę z maksymalnym lokalnym dyskiem SSD Hiperskala to wielowarstwowa architektura z buforowaniem na wielu poziomach. Efektywne operacje we/wy na sekundę zależą od obciążenia. |
| Pamięć/rdzeń wirtualny | 5,1 GB | 5,1 GB | 5,1 GB lub 10,2 GB |
| Tworzenie kopii zapasowych | Wybór geograficznie nadmiarowego, strefowo nadmiarowego lub lokalnie nadmiarowego magazynu kopii zapasowych, przechowywania 1–35 dni (domyślnie 7 dni) Długoterminowe przechowywanie dostępne do 10 lat |
Wybór geograficznie nadmiarowego, strefowo nadmiarowego lub lokalnie nadmiarowego magazynu kopii zapasowych, przechowywania 1–35 dni (domyślnie 7 dni) Długoterminowe przechowywanie dostępne do 10 lat |
Wybór magazynu lokalnie nadmiarowego (LRS), strefowo nadmiarowego (ZRS) lub magazynu geograficznie nadmiarowego (GRS) Przechowywanie przez 1–35 dni (domyślnie 7 dni) z dostępnym okresem przechowywania długoterminowego do 10 lat |
| Dostępność | Jedna replika, bez replik w skali odczytu, strefowo nadmiarowa wysoka dostępność (HA) |
Trzy repliki, jedna replika skalowania do odczytu, strefowo nadmiarowa wysoka dostępność (HA) |
strefowo nadmiarowa wysoka dostępność (HA) |
| Cennik/rozliczenia | Opłaty za rdzenie wirtualne, magazyn zarezerwowany i magazyn kopii zapasowych są naliczane. Nie są naliczane opłaty za operacje we/wy na sekundę. |
Opłaty za rdzenie wirtualne, magazyn zarezerwowany i magazyn kopii zapasowych są naliczane. Nie są naliczane opłaty za operacje we/wy na sekundę. |
Opłaty za rdzeń wirtualny dla każdej repliki i używanego magazynu są naliczane. Nie są naliczane opłaty za operacje we/wy na sekundę. |
| Modele rabatów | Wystąpienia zarezerwowane Korzyść użycia hybrydowego platformy Azure (niedostępne w subskrypcjach tworzenia i testowania) Subskrypcje ofert enterprise i Płatność zgodnie z rzeczywistym użyciem — tworzenie i testowanie |
Wystąpienia zarezerwowane Korzyść użycia hybrydowego platformy Azure (niedostępne w subskrypcjach tworzenia i testowania) Subskrypcje ofert enterprise i Płatność zgodnie z rzeczywistym użyciem — tworzenie i testowanie |
Korzyść użycia hybrydowego platformy Azure (niedostępne w subskrypcjach tworzenia i testowania) 1 Subskrypcje ofert enterprise i Płatność zgodnie z rzeczywistym użyciem — tworzenie i testowanie |
| Tabele OLTP w pamięci | Nie. | Tak | Nie |
1 Uproszczony cennik hiperskala usługi SQL Database wkrótce. Aby uzyskać szczegółowe informacje, zapoznaj się z blogiem dotyczącym cennika hiperskala.
Aby uzyskać więcej informacji, zapoznaj się z limitami zasobów dla serwerów logicznych, pojedynczych baz danych i baz danych w puli.
Uwaga
Aby uzyskać więcej informacji na temat umowy dotyczącej poziomu usług (SLA), zobacz Umowa SLA dla usługi Azure SQL Database
Ogólnego przeznaczenia
Model architektury dla warstwy usługi Ogólnego przeznaczenia jest oparty na rozdzieleniu zasobów obliczeniowych i magazynu. Ten model architektury opiera się na wysokiej dostępności i niezawodności usługi Azure Blob Storage, która w sposób niewidoczny replikuje pliki bazy danych i gwarantuje brak utraty danych, jeśli wystąpi awaria podstawowej infrastruktury.
Na poniższej ilustracji przedstawiono cztery węzły w standardowym modelu architektury z oddzielonymi warstwami obliczeniowymi i magazynowymi.
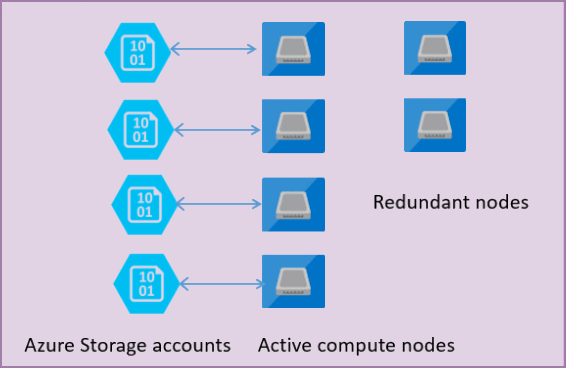
W modelu architektonicznym dla warstwy usługi Ogólnego przeznaczenia istnieją dwie warstwy:
- Bezstanowa warstwa obliczeniowa, która uruchamia
sqlservr.exeproces i zawiera tylko dane przejściowe i buforowane (na przykład — pamięć podręczna planu, pula, pula magazynu kolumn). Ten bezstanowy węzeł jest obsługiwany przez usługę Azure Service Fabric, która inicjuje proces, kontroluje kondycję węzła i wykonuje przejście w tryb failover do innego miejsca w razie potrzeby. - Stanowa warstwa danych z plikami bazy danych (.mdf/.ldf), które są przechowywane w usłudze Azure Blob Storage. Usługa Azure Blob Storage gwarantuje, że nie ma utraty danych żadnego rekordu umieszczonego w dowolnym pliku bazy danych. Usługa Azure Storage ma wbudowaną dostępność/nadmiarowość danych, która zapewnia zachowanie każdego rekordu w pliku dziennika lub na stronie w pliku danych, nawet jeśli proces ulegnie awarii.
Za każdym razem, gdy aparat bazy danych lub system operacyjny zostanie uaktualniony, część podstawowej infrastruktury ulegnie awarii lub jeśli w procesie zostanie wykryty sqlservr.exe jakiś krytyczny problem, usługa Azure Service Fabric przenosi bezstanowy proces do innego bezstanowego węzła obliczeniowego. Istnieje zestaw węzłów zapasowych oczekujących na uruchomienie nowej usługi obliczeniowej, jeśli nastąpi przejście węzła podstawowego w tryb failover w celu zminimalizowania czasu pracy w trybie failover. Nie ma to wpływu na dane w warstwie magazynu platformy Azure, a pliki danych/dziennika są dołączane do nowo zainicjowanego procesu. Ten proces gwarantuje domyślnie dostępność na 99,99% i dostępność na 99,995% po włączeniu nadmiarowości strefy. Może wystąpić pewien wpływ na wydajność dużych obciążeń, które są w locie z powodu czasu przejścia, a fakt, że nowy węzeł zaczyna się od zimnej pamięci podręcznej.
Kiedy wybrać tę warstwę usługi
Warstwa usługi Ogólnego przeznaczenia to domyślna warstwa usługi w usłudze Azure SQL Database przeznaczona dla większości obciążeń ogólnych. Jeśli potrzebujesz w pełni zarządzanego aparatu bazy danych z domyślną umową SLA i opóźnieniem magazynu z zakresu od 5 ms do 10 ms, warstwa Ogólnego przeznaczenia jest dla Ciebie opcją.
Krytyczne dla działania firmy
Model warstwy usługi Krytyczne dla działania firmy jest oparty na klastrze procesów aparatu bazy danych. Ten model architektury opiera się na kworum węzłów aparatu bazy danych, aby zminimalizować wpływ wydajności na obciążenie, nawet podczas działań konserwacyjnych. Uaktualnienia i poprawki podstawowego systemu operacyjnego, sterowników i aparatu bazy danych są wykonywane w sposób niewidoczny, przy minimalnym czasie przestoju dla użytkowników końcowych.
W modelu Krytyczne dla działania firmy zasoby obliczeniowe i magazyn są zintegrowane w każdym węźle. Replikacja danych między procesami aparatu bazy danych w każdym węźle klastra z czterema węzłami zapewnia wysoką dostępność, a każdy węzeł używa lokalnie dołączonego dysku SSD jako magazynu danych. Na poniższym diagramie pokazano, jak warstwa usługi Krytyczne dla działania firmy organizuje klaster węzłów aparatu bazy danych w replikach grup dostępności.

Zarówno proces aparatu bazy danych, jak i bazowe pliki .mdf/.ldf są umieszczane w tym samym węźle z lokalnie dołączonym magazynem SSD, co zapewnia małe opóźnienie obciążenia. Wysoka dostępność jest implementowana przy użyciu technologii podobnej do zawsze włączonych grup dostępności programu SQL Server. Każda baza danych to klaster węzłów bazy danych z jedną repliką podstawową, która jest dostępna dla obciążeń klientów, oraz trzy repliki pomocnicze zawierające kopie danych. Replika podstawowa stale wypycha zmiany do replik pomocniczych, aby upewnić się, że dane są dostępne w replikach pomocniczych, jeśli z jakiegokolwiek powodu podstawowy ulegnie awarii. Tryb failover jest obsługiwany przez usługę Service Fabric, a aparat bazy danych — jedna replika pomocnicza staje się podstawowa, a nowa replika pomocnicza jest tworzona w celu zapewnienia wystarczającej liczby węzłów w klastrze. Obciążenie jest automatycznie przekierowywane do nowej repliki podstawowej.
Ponadto klaster Krytyczne dla działania firmy ma wbudowaną funkcję skalowania odczytu w poziomie, która zapewnia bezpłatną replikę tylko do odczytu używaną do uruchamiania zapytań tylko do odczytu (takich jak raporty), które nie wpłyną na wydajność obciążenia w repliki podstawowej.
Kiedy wybrać tę warstwę usługi
Warstwa usługi Krytyczne dla działania firmy jest przeznaczona dla aplikacji wymagających odpowiedzi o małych opóźnieniach z bazowego magazynu SSD (średnio 1–2 ms), szybszego odzyskiwania w przypadku awarii podstawowej infrastruktury lub konieczności odciążania raportów, analiz i zapytań tylko do odczytu do bezpłatnej pomocniczej repliki podstawowej bazy danych z możliwością odczytu.
Najważniejsze przyczyny, dla których należy wybrać warstwę usługi Krytyczne dla działania firmy zamiast warstwy Ogólnego przeznaczenia, to:
- Wymagania dotyczące małych opóźnień we/wy — obciążenia wymagające stale szybkiej reakcji warstwy magazynowania (średnio 1–2 milisekundy) powinny używać warstwy Krytyczne dla działania firmy.
- Obciążenie z raportowaniem i zapytaniami analitycznymi, w których wystarczająca jest pojedyncza bezpłatna pomocnicza replika tylko do odczytu.
- Większa odporność i szybsze odzyskiwanie po awariach. W przypadku awarii systemu baza danych w wystąpieniu podstawowym jest wyłączona, a jedna z replik pomocniczych natychmiast staje się nową podstawową bazą danych odczytu i zapisu, gotową do przetwarzania zapytań.
- Zaawansowana ochrona przed uszkodzeniem danych. Ponieważ warstwa Krytyczne dla działania firmy używa replik baz danych w tle, usługa używa automatycznej naprawy strony dostępnej z dublowaniem i grupami dostępności, aby pomóc w ograniczeniu uszkodzenia danych. Jeśli replika nie może odczytać strony z powodu problemu z integralnością danych, nowa kopia strony zostanie pobrana z innej repliki, zastępując nieczytelną stronę bez utraty danych lub przestoju klienta. Ta funkcja jest dostępna w warstwie Ogólnego przeznaczenia, jeśli baza danych ma replikę pomocniczą geograficzną.
- Wyższa dostępność — warstwa Krytyczne dla działania firmy w konfiguracji strefy z wieloma dostępnościami zapewnia odporność na awarie strefowe i wyższą dostępność umowy SLA.
- Szybkie odzyskiwanie geograficzne — po skonfigurowaniu aktywnej replikacji geograficznej warstwa Krytyczne dla działania firmy ma gwarantowany cel punktu odzyskiwania (RPO) 5 sekund i cel czasu odzyskiwania (RTO) 30 sekund dla 100% wdrożonych godzin.
Hiperskala
Warstwa usługi Hiperskala jest odpowiednia dla wszystkich typów obciążeń. Architektura natywna dla chmury zapewnia niezależne skalowalne zasoby obliczeniowe i magazynowe do obsługi najszerszej gamy tradycyjnych i nowoczesnych aplikacji. Zasoby obliczeniowe i magazynowe w warstwie Hiperskala znacznie przekraczają zasoby dostępne w warstwach Ogólnego przeznaczenia i Krytyczne dla działania firmy.
Aby dowiedzieć się więcej, zapoznaj się z tematem Warstwa usługi Hiperskala dla usługi Azure SQL Database.
Kiedy wybrać tę warstwę usługi
Warstwa usługi Hiperskala usuwa wiele praktycznych limitów tradycyjnie spotykanych w bazach danych w chmurze. Jeśli większość innych baz danych jest ograniczona przez zasoby dostępne w jednym węźle, bazy danych w warstwie usługi Hiperskala nie mają takich limitów. Dzięki elastycznej architekturze magazynu baza danych w warstwie Hiperskala rośnie zgodnie z potrzebami — a opłaty są naliczane tylko za używaną pojemność magazynu.
Oprócz zaawansowanych możliwości skalowania hiperskala jest doskonałym rozwiązaniem dla każdego obciążenia, a nie tylko dla dużych baz danych. W warstwie Hiperskala można wykonywać następujące czynności:
- Osiągnij wysoką odporność i szybkie odzyskiwanie po awarii przy jednoczesnym kontrolowaniu kosztów, wybierając liczbę replik o wysokiej dostępności z zakresu od 0 do 4.
- Zwiększ wysoką dostępność , włączając nadmiarowość stref dla zasobów obliczeniowych i magazynu.
- Osiągnij małe opóźnienie we/wy (średnio od 1 do 2 milisekund) dla często używanej części bazy danych. W przypadku mniejszych baz danych może to dotyczyć całej bazy danych.
- Zaimplementuj wiele różnych scenariuszy skalowania odczytu w poziomie z nazwanymi replikami.
- Korzystaj z szybkiego skalowania bez oczekiwania na skopiowanie danych do magazynu lokalnego w nowych węzłach.
- Korzystaj z ciągłej kopii zapasowej bazy danych o zerowym wpływie i szybkiego przywracania.
- Obsługa wymagań dotyczących ciągłości działalności biznesowej przy użyciu grup trybu failover i replikacji geograficznej.
Zapisz konfigurację sprzętu
Typowe konfiguracje sprzętowe w modelu rdzeni wirtualnych obejmują serię standardowa (Gen5), serię Fsv2 i serię DC. Hiperskala oferuje również opcję sprzętu zoptymalizowanego pod kątem pamięci w warstwie Premium i serii Premium. Konfiguracja sprzętu definiuje limity mocy obliczeniowej i pamięci oraz inne cechy wpływające na wydajność obciążenia.
Niektóre konfiguracje sprzętu, takie jak standardowa seria (Gen5) mogą używać więcej niż jednego typu procesora (CPU), zgodnie z opisem w temacie Zasoby obliczeniowe (procesor i pamięć). Chociaż dana baza danych lub elastyczna pula zwykle pozostają na sprzęcie o tym samym typie procesora CPU przez długi czas (często przez wiele miesięcy), istnieją pewne zdarzenia, które mogą spowodować przeniesienie bazy danych lub puli na sprzęt, który używa innego typu procesora CPU.
Bazę danych lub pulę można przenieść w różnych scenariuszach, w tym między innymi w następujących sytuacjach:
- Cel usługi jest zmieniany
- Bieżąca infrastruktura w centrum danych zbliża się do limitów pojemności
- Obecnie używany sprzęt jest likwidowany ze względu na jego koniec
- Konfiguracja strefowo nadmiarowa jest włączona, przechodząc do innego sprzętu ze względu na dostępną pojemność
W przypadku niektórych obciążeń przejście do innego typu procesora CPU może zmienić wydajność. Usługa SQL Database konfiguruje sprzęt w celu zapewnienia przewidywalnej wydajności obciążenia, nawet jeśli typ procesora CPU ulegnie zmianie, zachowując zmiany wydajności w wąskim pasmie. Jednak w szerokim spektrum obciążeń klientów w usłudze SQL Database i w miarę dostępności nowych typów procesorów CPU od czasu do czasu można zobaczyć bardziej zauważalne zmiany wydajności, jeśli baza danych lub pula zostanie przeniesiona do innego typu procesora CPU.
Niezależnie od używanego typu procesora CPU limity zasobów dla bazy danych lub elastycznej puli (takie jak liczba rdzeni, pamięć, maksymalna liczba operacji we/wy na sekundę danych, maksymalna szybkość rejestrowania i maksymalna liczba współbieżnych procesów roboczych) pozostają takie same, jak długo baza danych pozostaje w tym samym celu usługi.
Zasoby obliczeniowe (procesor CPU i pamięć)
W poniższej tabeli porównaliśmy zasoby obliczeniowe w różnych konfiguracjach sprzętu i warstwach obliczeniowych:
| Zapisz konfigurację sprzętu | Procesor CPU | Memory (Pamięć) |
|---|---|---|
| Seria Standardowa (Gen5) | Aprowidowane obliczenia - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel Xeon® Platinum 8370C (Ice Lake)*, AMD® EPYC 7763v (Milan) procesory - Aprowizuj maksymalnie 128 rdzeni wirtualnych (hiperwątkowy) Bezserwerowe usługi obliczeniowe - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel Xeon® Platinum 8370C (Ice Lake)*, AMD® EPYC 7763v (Milan) procesory - Autoskaluj do 80 rdzeni wirtualnych (hiperwątkowa) - Stosunek pamięci do rdzeni wirtualnych dynamicznie dostosowuje się do użycia pamięci i procesora CPU na podstawie zapotrzebowania na obciążenie i może wynosić nawet 24 GB na rdzeń wirtualny. Na przykład w danym momencie obciążenie może używać i być rozliczane za 240 GB pamięci i tylko 10 rdzeni wirtualnych. |
Aprowidowane obliczenia - 5,1 GB na rdzeń wirtualny - Aprowizuj do 625 GB Bezserwerowe usługi obliczeniowe - Autoskaluj do 24 GB na rdzeń wirtualny - Autoskaluj maksymalnie 240 GB |
| Seria Fsv2 | - Procesory Intel® 8168 (Skylake) - Wyposażony w trwałą całą prędkość zegara turbo rdzenia 3,4 GHz i maksymalną szybkość zegara 3,7 GHz. - Aprowizuj maksymalnie 72 rdzenie wirtualne (hiperwątkowa) |
- 1,9 GB na rdzeń wirtualny - Aprowizuj do 136 GB |
| Seria DC | - Procesory Intel® Xeon® E-2288G - Featuring Intel Software Guard Extension (Intel SGX) — Aprowizuj maksymalnie 8 rdzeni wirtualnych (fizycznych) |
4,5 GB na rdzeń wirtualny |
* W widoku zarządzania dynamicznego sys.dm_user_db_resource_governance generowanie sprzętu dla baz danych przy użyciu procesorów Intel® SP-8160 (Skylake) jest wyświetlane jako Gen6, generacja sprzętu dla baz danych korzystających z technologii Intel® 8272CL (Cascade Lake) jest wyświetlana jako Gen7, a generacja sprzętu dla baz danych korzystających z technologii Intel® Xeon® Platinum 8370C (Ice Lake) lub AMD® EPYC® 7763v (Milan) jest wyświetlana jako Gen8. W przypadku danego rozmiaru obliczeniowego i konfiguracji sprzętu limity zasobów są takie same niezależnie od typu procesora (Intel Broadwell, Skylake, Ice Lake, Cascade Lake lub AMD Milan).
Aby uzyskać więcej informacji, zobacz Limity zasobów dla pojedynczych baz danych i pul elastycznych.
Aby uzyskać informacje na temat zasobów obliczeniowych i specyfikacji bazy danych w warstwie Hiperskala, zobacz Zasoby obliczeniowe w warstwie Hiperskala.
Seria Standardowa (Gen5)
- Sprzęt z serii Standardowa (Gen5) zapewnia zrównoważone zasoby obliczeniowe i pamięci oraz jest odpowiedni dla większości obciążeń bazy danych.
Sprzęt z serii Standardowa (Gen5) jest dostępny we wszystkich regionach publicznych na całym świecie.
Seria Premium w warstwie Hiperskala
- Opcje sprzętu z serii Premium korzystają z najnowszej technologii procesora CPU i pamięci firmy Intel i AMD. Seria Premium zapewnia zwiększenie wydajności obliczeniowej względem sprzętu z serii Standardowa.
- Opcja serii Premium oferuje szybszą wydajność procesora w porównaniu z serią Standardowa i większą liczbą maksymalnych rdzeni wirtualnych.
- Opcja zoptymalizowana pod kątem pamięci serii Premium oferuje dwukrotnie większą ilość pamięci względem serii Standardowa.
- Zoptymalizowane pod kątem pamięci w warstwie Standardowa, serii Premium i premium są dostępne dla elastycznych pul hiperskala.
Aby uzyskać więcej informacji, zobacz ogłoszenie w blogu serii Hiperskala Premium.
Aby zapoznać się z dostępnymi regionami, zobacz Dostępność w warstwie Premium w warstwie Hiperskala.
Seria Fsv2
- Fsv2-series to zoptymalizowana pod kątem obliczeń konfiguracja sprzętowa zapewniająca małe opóźnienia procesora CPU i dużą szybkość zegara dla najbardziej wymagających obciążeń procesora CPU. Podobnie jak w przypadku konfiguracji sprzętu z serii Hiperskala w warstwie Premium, seria Fsv2 jest obsługiwana przez najnowszą technologię procesora CPU i pamięci firmy Intel i AMD, umożliwiając klientom korzystanie z najnowszego sprzętu podczas korzystania z baz danych i pul elastycznych w warstwie usługi Ogólnego przeznaczenia.
- W zależności od obciążenia seria Fsv2 może zapewnić większą wydajność procesora CPU na rdzeń wirtualny niż inne typy sprzętu. Na przykład rozmiar obliczeniowy 72 rdzeni wirtualnych Fsv2 może zapewnić większą wydajność niż 80 rdzeni wirtualnych w warstwie Standardowa (Gen5) przy niższych kosztach.
- Fsv2 zapewnia mniej pamięci i
tempdbna rdzeń wirtualny niż inny sprzęt, więc obciążenia wrażliwe na te limity mogą działać lepiej w przypadku serii standardowej (Gen5).
Serie Fsv2 obsługiwane tylko w warstwie Ogólnego przeznaczenia. W przypadku regionów, w których jest dostępna seria Fsv2, zobacz Dostępność serii Fsv2.
Seria DC
- Sprzęt z serii DC używa procesorów Intel z technologią Software Guard Extensions (Intel SGX).
- Seria DC jest wymagana w przypadku funkcji Always Encrypted z bezpiecznymi obciążeniami enklaw, które wymagają silniejszej ochrony zabezpieczeń enklaw sprzętowych, w porównaniu z enklawami zabezpieczeń opartymi na wirtualizacji (VBS).
- Seria DC jest przeznaczona dla obciążeń, które przetwarzają poufne dane i wymagają poufnych możliwości przetwarzania zapytań, zapewnianych przez funkcję Always Encrypted z bezpiecznymi enklawami.
- Sprzęt z serii DC zapewnia zrównoważone zasoby obliczeniowe i pamięci.
Seria DC jest obsługiwana tylko w przypadku aprowizowanych obliczeń (bezserwerowa nie jest obsługiwana) i nie obsługuje nadmiarowości strefy. W przypadku regionów, w których jest dostępna seria DC, zobacz Dostępność serii DC.
Typy ofert platformy Azure obsługiwane przez serię DC
Aby utworzyć bazy danych lub pule elastyczne na sprzęcie serii DC, subskrypcja musi być płatnym typem oferty, w tym płatnością zgodnie z rzeczywistym użyciem lub Umowa Enterprise (EA). Aby uzyskać pełną listę typów ofert platformy Azure obsługiwanych przez serię DC, zobacz bieżące oferty bez limitów wydatków.
Wybieranie konfiguracji sprzętu
Podczas tworzenia bazy danych lub elastycznej puli w usłudze SQL Database można wybrać konfigurację sprzętu. Można również zmienić konfigurację sprzętową istniejącej bazy danych lub elastycznej puli.
Aby wybrać konfigurację sprzętu podczas tworzenia bazy danych SQL Database lub puli
Aby uzyskać szczegółowe informacje, zobacz Tworzenie bazy danych SQL Database.
Na karcie Podstawy wybierz link Konfiguruj bazę danych w sekcji Obliczenia i magazyn, a następnie wybierz link Zmień konfigurację:

Wybierz żądaną konfigurację sprzętu:

Aby zmienić konfigurację sprzętową istniejącej bazy danych SQL Database lub puli
W przypadku bazy danych na stronie Przegląd wybierz link Warstwa cenowa:

W przypadku puli na stronie Przegląd wybierz pozycję Konfiguruj.
Wykonaj kroki, aby zmienić konfigurację i wybrać konfigurację sprzętu zgodnie z opisem w poprzednich krokach.
Dostępność sprzętu
Aby uzyskać informacje na temat sprzętu poprzedniej generacji, zobacz Dostępność sprzętu poprzedniej generacji.
Seria Standardowa (Gen5)
Sprzęt z serii Standardowa (Gen5) jest dostępny we wszystkich regionach publicznych na całym świecie.
Seria Premium w warstwie Hiperskala
Sprzęt zoptymalizowany pod kątem pamięci w warstwie Hiperskala w warstwie Premium i premium jest dostępny dla pojedynczych baz danych i elastycznych pul w następujących regionach:
- Australia Wschodnia **
- Australia Południowo-Wschodnia
- Brazylia Południowa **
- Kanada Środkowa **
- Kanada Wschodnia
- Azja Wschodnia
- Europa Północna **
- Europa Zachodnia **
- Francja Środkowa
- Niemcy Środkowo-Zachodnie
- Indie Środkowe
- Indie południowe
- Japonia Wschodnia **
- Japonia Zachodnia
- Azja Południowo-Wschodnia**
- Szwajcaria Północna
- Szwecja Środkowa **,*
- Południowe Zjednoczone Królestwo **
- Zachodnie Zjednoczone Królestwo *
- Środkowe stany USA **
- Wschodnie stany USA **
- Wschodnie stany USA 2 **
- Północno-środkowe stany USA
- Południowo-środkowe stany USA
- Zachodnio-środkowe stany USA
- Zachodnie stany USA 1
- Zachodnie stany USA 2 **
- Zachodnie stany USA 3 **
* Sprzęt zoptymalizowany pod kątem pamięci serii Premium nie jest obecnie dostępny.
** Obejmuje obsługę nadmiarowości strefy.
Seria Fsv2
Seria Fsv2 jest dostępna w następujących regionach:
- Australia Środkowa
- Australia Środkowa 2
- Australia Wschodnia
- Australia Południowo-Wschodnia
- Brazylia Południowa
- Kanada Środkowa
- Azja Wschodnia
- Europa Północna
- Europa Zachodnia
- Francja Środkowa
- Indie Środkowe
- Korea Środkowa
- Korea Południowa
- Północna Republika Południowej Afryki
- Southeast Asia
- Południowe Zjednoczone Królestwo
- Zachodnie Zjednoczone Królestwo
- Wschodnie stany USA
- Zachodnie stany USA 2
Seria DC
Seria DC jest dostępna w następujących regionach:
- Kanada Środkowa
- Europa Zachodnia
- Europa Północna
- Southeast Asia
- Południowe Zjednoczone Królestwo
- Zachodnie stany USA
- Wschodnie stany USA
Jeśli potrzebujesz serii DC w aktualnie nieobsługiwanym regionie, prześlij wniosek o pomoc techniczną. Na stronie Podstawy podaj następujące informacje:
- W polu Typ problemu wybierz pozycję Techniczny.
- Podaj żądaną subskrypcję sprzętu. Wybierz Dalej.
- W polu Typ usługi wybierz pozycję SQL Database.
- W polu Zasób wybierz pozycję Ogólne pytanie.
- W obszarze Podsumowanie podaj żądaną dostępność sprzętu i region.
- W polu Typ problemu wybierz pozycję Zabezpieczenia, Prywatne i Zgodność.
- W obszarze Podtyp problemu wybierz pozycję Always Encrypted.

Sprzęt poprzedniej generacji
4. generacji
Sprzęt 4. generacji został wycofany i nie jest dostępny do aprowizacji, skalowania upscalingowego ani skalowania w dół. Przeprowadź migrację bazy danych do obsługiwanej generacji sprzętu w celu uzyskania szerszego zakresu skalowalności rdzeni wirtualnych i magazynu, przyspieszonej sieci, najlepszej wydajności operacji we/wy i minimalnego opóźnienia. Zapoznaj się z opcjami sprzętowymi dla pojedynczych baz danych i opcji sprzętowych dla pul elastycznych. Aby uzyskać więcej informacji, zobacz Temat Pomoc techniczna zakończyła się dla sprzętu 4. generacji w usłudze Azure SQL Database.