Zarządzanie budżetami, kosztami i limitami przydziału dla usługi Azure Machine Learning w skali organizacji
W przypadku zarządzania kosztami obliczeniowymi związanymi z usługą Azure Machine Learning w skali organizacji z wieloma obciążeniami, wieloma zespołami i użytkownikami istnieje wiele wyzwań związanych z zarządzaniem i optymalizacją.
W tym artykule przedstawiono najlepsze rozwiązania dotyczące optymalizowania kosztów, zarządzania budżetami i udostępniania limitu przydziału za pomocą usługi Azure Machine Learning. Odzwierciedlają one doświadczenia i wnioski z wewnętrznych zespołów uczenia maszynowego w firmie Microsoft oraz współpracy partnerskiej z jej klientami. Omawiane tematy:
- Zoptymalizuj zasoby obliczeniowe, aby spełnić wymagania dotyczące obciążenia.
- Napędzaj najlepsze wykorzystanie budżetu zespołu.
- Planowanie i udostępnianie budżetów, kosztów i przydziałów w skali przedsiębiorstwa oraz zarządzanie nimi.
Optymalizowanie obliczeń w celu spełnienia wymagań dotyczących obciążenia
Po uruchomieniu nowego projektu uczenia maszynowego może być konieczna praca eksploracyjna, aby uzyskać dobry obraz wymagań obliczeniowych. Ta sekcja zawiera zalecenia dotyczące sposobu określania właściwego wyboru jednostki SKU maszyny wirtualnej do trenowania, wnioskowania lub pracy stacji roboczej.
Określanie rozmiaru zasobów obliczeniowych na potrzeby trenowania
Wymagania sprzętowe dotyczące obciążenia szkoleniowego mogą się różnić w zależności od projektu do projektu. Aby spełnić te wymagania, środowisko obliczeniowe usługi Azure Machine Learning oferuje różne typy maszyn wirtualnych:
- Ogólnego przeznaczenia: Zrównoważony stosunek procesora CPU do pamięci.
- Zoptymalizowane pod kątem pamięci: Stosunek pamięci do procesora CPU.
- Zoptymalizowane pod kątem obliczeń: Wysoki stosunek procesora CPU do pamięci.
- Obliczenia o wysokiej wydajności: Dostarczaj wydajność, skalowalność i wydajność klasy liderów dla różnych rzeczywistych obciążeń HPC.
- Wystąpienia z procesorami GPU: Wyspecjalizowane maszyny wirtualne przeznaczone do ciężkiego renderowania graficznego i edytowania wideo, a także trenowanie i wnioskowanie modeli (ND) przy użyciu uczenia głębokiego.
Być może nie wiesz jeszcze, jakie są wymagania obliczeniowe. W tym scenariuszu zalecamy rozpoczęcie od jednej z następujących tanich opcji domyślnych. Te opcje są przeznaczone do uproszczonego testowania i trenowania obciążeń.
| Typ | Rozmiar maszyny wirtualnej | Specyfikacje |
|---|---|---|
| Procesor CPU | Standardowa_DS3_v2 | 4 rdzenie, 14 gigabajtów (GB) pamięci RAM, 28 GB pamięci masowej |
| Procesory GPU | Standardowa_NC6 | 6 rdzeni, 56 gigabajtów (GB) pamięci RAM, 380 GB pamięci masowej, NVIDIA Tesla K80 GPU |
Aby uzyskać najlepszy rozmiar maszyny wirtualnej dla danego scenariusza, może to obejmować próbę i błąd. Oto kilka aspektów, które należy wziąć pod uwagę.
- Jeśli potrzebujesz procesora CPU:
- Jeśli trenujesz na dużych zestawach danych, użyj maszyny wirtualnej zoptymalizowanej pod kątem pamięci .
- Użyj zoptymalizowanej pod kątem obliczeń maszyny wirtualnej, jeśli wykonujesz wnioskowanie w czasie rzeczywistym lub inne zadania wrażliwe na opóźnienia.
- Użyj maszyny wirtualnej z większą ilością rdzeni i pamięci RAM, aby przyspieszyć czas trenowania.
- Jeśli potrzebujesz procesora GPU, zobacz zoptymalizowane pod kątem procesora GPU rozmiary maszyn wirtualnych , aby uzyskać informacje na temat wybierania maszyny wirtualnej.
- Jeśli wykonujesz trenowanie rozproszone, użyj rozmiarów maszyn wirtualnych, które mają wiele procesorów GPU.
- Jeśli wykonujesz trenowanie rozproszone na wielu węzłach, użyj procesorów GPU, które mają połączenia NVLink.
Podczas wybierania typu maszyny wirtualnej i jednostki SKU najlepiej dopasowanej do obciążenia należy ocenić porównywalne jednostki SKU maszyn wirtualnych jako kompromis między wydajnością procesora CPU a wydajnością procesora GPU i cenami. Z perspektywy zarządzania kosztami zadanie może działać dość dobrze na kilku jednostkach SKU.
Niektóre procesory GPU, takie jak rodzina NC, szczególnie NC_Promo jednostki SKU, mają podobne możliwości do innych procesorów GPU, takich jak małe opóźnienia i możliwość zarządzania wieloma obciążeniami obliczeniowymi równolegle. Są one dostępne w obniżonych cenach w porównaniu do niektórych innych procesorów GPU. Rozważnie wybranie jednostek SKU maszyn wirtualnych w obciążeniu może znacznie obniżyć koszty.
Przypomnienie o znaczeniu wykorzystania polega na zarejestrowaniu się w celu uzyskania większej liczby procesorów GPU, które niekoniecznie są wykonywane z szybszymi wynikami. Zamiast tego upewnij się, że procesory GPU są w pełni używane. Na przykład dokładnie sprawdź potrzebę korzystania z interfejsu NVIDIA CUDA. Chociaż może być to wymagane do wykonywania procesora GPU o wysokiej wydajności, zadanie może nie być zależne od niego.
Określanie rozmiaru obliczeń dla wnioskowania
Wymagania obliczeniowe dotyczące scenariuszy wnioskowania różnią się od scenariuszy szkoleniowych. Dostępne opcje różnią się w zależności od tego, czy scenariusz wymaga wnioskowania w trybie wsadowym w trybie offline, czy wymaga wnioskowania online w czasie rzeczywistym.
W przypadku scenariuszy wnioskowania w czasie rzeczywistym należy wziąć pod uwagę następujące sugestie:
- Użyj funkcji profilowania w modelu za pomocą usługi Azure Machine Learning, aby określić, ile procesora CPU i pamięci należy przydzielić do modelu podczas wdrażania go jako usługi internetowej.
- Jeśli korzystasz z wnioskowania w czasie rzeczywistym, ale nie potrzebujesz wysokiej dostępności, wdróż je w Azure Container Instances (bez wyboru jednostki SKU).
- Jeśli korzystasz z wnioskowania w czasie rzeczywistym, ale potrzebujesz wysokiej dostępności, wdróż je w Azure Kubernetes Service.
- Jeśli używasz tradycyjnych modeli uczenia maszynowego i otrzymujesz < 10 zapytań na sekundę, zacznij od jednostki SKU procesora CPU. Jednostki SKU serii F często działają dobrze.
- Jeśli używasz modeli uczenia głębokiego i otrzymujesz > 10 zapytań/sekund, wypróbuj jednostkę SKU procesora GPU FIRMY NVIDIA (NCasT4_v3 często działa dobrze) za pomocą rozwiązania Triton.
W przypadku scenariuszy wnioskowania wsadowego należy wziąć pod uwagę następujące sugestie:
- W przypadku korzystania z potoków usługi Azure Machine Learning na potrzeby wnioskowania wsadowego postępuj zgodnie ze wskazówkami w temacie Określanie rozmiaru obliczeniowego na potrzeby trenowania , aby wybrać początkowy rozmiar maszyny wirtualnej.
- Optymalizowanie kosztów i wydajności przez skalowanie w poziomie. Jedną z kluczowych metod optymalizacji kosztów i wydajności jest równoległość obciążenia za pomocą równoległego kroku uruchamiania w usłudze Azure Machine Learning. Ten krok potoku umożliwia równoległe wykonywanie zadania przy użyciu wielu mniejszych węzłów, co umożliwia skalowanie w poziomie. Istnieje jednak obciążenie związane z równoległym przetwarzaniem. W zależności od obciążenia i stopnia równoległości, które można osiągnąć, krok przebiegu równoległego może lub nie może być opcją.
Określanie rozmiaru wystąpienia obliczeniowego
W przypadku programowania interakcyjnego zalecane jest wystąpienie obliczeniowe usługi Azure Machine Learning. Oferta wystąpienia obliczeniowego (CI) umożliwia korzystanie z zasobów obliczeniowych z jednym węzłem powiązanych z pojedynczym użytkownikiem i może być używana jako stacja robocza w chmurze.
Niektóre organizacje nie zezwalają na korzystanie z danych produkcyjnych na lokalnych stacjach roboczych, wymuszały ograniczenia środowiska stacji roboczej lub ograniczają instalację pakietów i zależności w środowisku IT firmy. Wystąpienie obliczeniowe może służyć jako stacja robocza, aby przezwyciężyć ograniczenie. Oferuje bezpieczne środowisko z dostępem do danych produkcyjnych i działa na obrazach, które są dostarczane z popularnymi pakietami i narzędziami do nauki o danych wstępnie zainstalowanych.
Gdy wystąpienie obliczeniowe jest uruchomione, użytkownik jest rozliczany za obliczenia maszyn wirtualnych, usługa Load Balancer w warstwie Standardowa (uwzględnione reguły ruchu wychodzącego/wychodzącego i przetwarzane dane), dysk systemu operacyjnego (dysk zarządzany przez ssd w warstwie Premium P10), dysk tymczasowy (typ dysku tymczasowego zależy od wybranego rozmiaru maszyny wirtualnej) i publicznego adresu IP. Aby zaoszczędzić koszty, zalecamy, aby użytkownicy rozważyli następujące kwestie:
- Uruchom i zatrzymaj wystąpienie obliczeniowe, gdy nie jest używane.
- Praca z próbką danych w wystąpieniu obliczeniowym i skalowanie w poziomie do klastrów obliczeniowych w celu pracy z pełnym zestawem danych
- Przesyłanie zadań eksperymentowania w lokalnym trybie docelowym obliczeń w wystąpieniu obliczeniowym podczas opracowywania lub testowania lub przełączanie do udostępnionej pojemności obliczeniowej podczas przesyłania zadań na pełną skalę. Na przykład wiele epok, pełny zestaw danych i wyszukiwanie hiperparametrów.
Jeśli zatrzymasz wystąpienie obliczeniowe, zatrzymasz rozliczanie godzin obliczeniowych maszyn wirtualnych, dysku tymczasowego i usługa Load Balancer w warstwie Standardowa przetworzonych kosztów. Uwaga użytkownik nadal płaci za dysk systemu operacyjnego i usługa Load Balancer w warstwie Standardowa zawarte reguły ruchu wychodzącego/modułu równoważenia obciążenia nawet po zatrzymaniu wystąpienia obliczeniowego. Wszystkie dane zapisane na dysku systemu operacyjnego są utrwalane przez zatrzymywanie i ponowne uruchamianie.
Dostrajanie wybranego rozmiaru maszyny wirtualnej przez monitorowanie wykorzystania zasobów obliczeniowych
Informacje na temat użycia i wykorzystania zasobów obliczeniowych usługi Azure Machine Learning można wyświetlić za pośrednictwem usługi Azure Monitor. Szczegółowe informacje na temat wdrażania i rejestracji modelu, szczegółów limitu przydziału, takich jak aktywne i bezczynne węzły, szczegóły uruchamiania, takie jak anulowane i ukończone przebiegi, oraz wykorzystanie zasobów obliczeniowych dla procesora GPU i procesora CPU.
Na podstawie szczegółowych informacji dotyczących monitorowania można lepiej zaplanować lub dostosować użycie zasobów w zespole. Jeśli na przykład zauważysz wiele bezczynnych węzłów w ciągu ostatniego tygodnia, możesz pracować z odpowiednimi właścicielami obszarów roboczych, aby zaktualizować konfigurację klastra obliczeniowego, aby zapobiec tym dodatkowym kosztom. Korzyści wynikające z analizowania wzorców wykorzystania mogą pomóc w prognozowaniu kosztów i ulepszeń budżetu.
Dostęp do tych metryk można uzyskać bezpośrednio z Azure Portal. Przejdź do obszaru roboczego usługi Azure Machine Learning i wybierz pozycję Metryki w sekcji monitorowania na panelu po lewej stronie. Następnie możesz wybrać szczegóły dotyczące tego, co chcesz wyświetlić, takie jak metryki, agregacja i okres. Aby uzyskać więcej informacji, zobacz stronę dokumentacji usługi Azure Machine Learning w usłudze Azure Machine Learning .
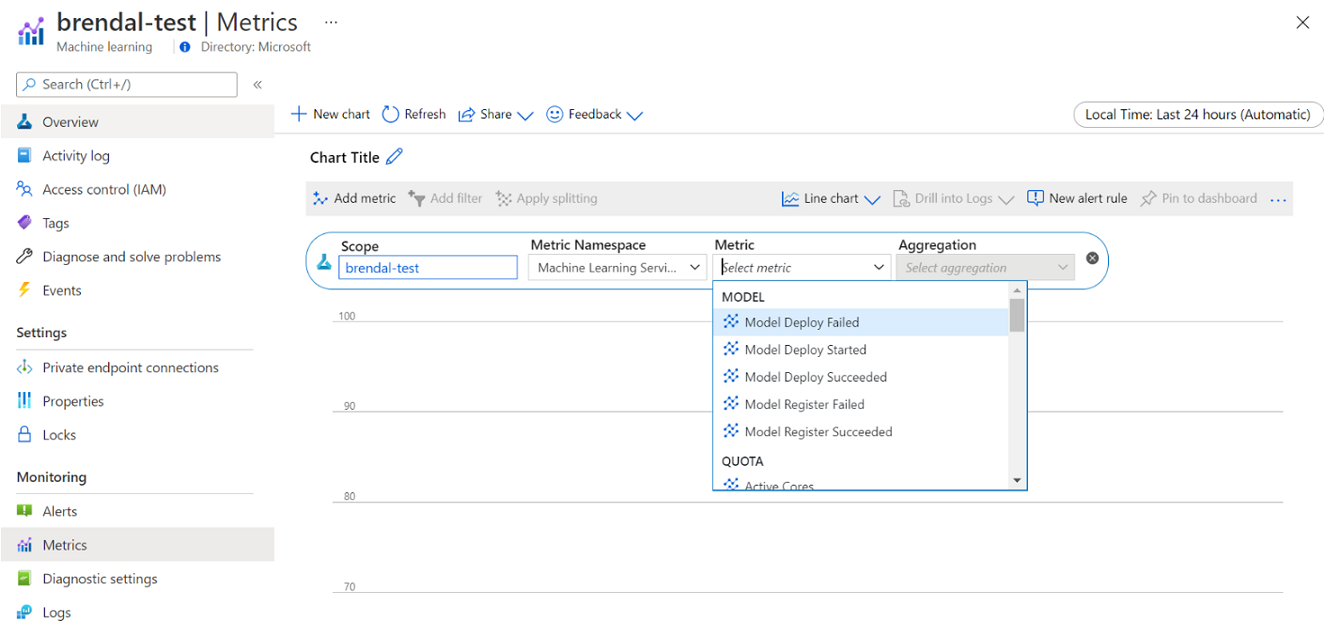
Przełączanie między obliczeniami lokalnymi, jednowęźleowymi i wielowęźleowymi w chmurze podczas opracowywania
W całym cyklu życia uczenia maszynowego istnieją różne wymagania dotyczące obliczeń i narzędzi. Usługa Azure Machine Learning może być interfejsem za pomocą zestawu SDK i interfejsu wiersza polecenia z praktycznie dowolnej preferowanej konfiguracji stacji roboczej, aby spełnić te wymagania.
Aby zaoszczędzić koszty i wydajnie pracować, zaleca się:
- Sklonuj kod eksperymentowania lokalnie przy użyciu usługi Git i prześlij zadania do zasobów obliczeniowych w chmurze przy użyciu zestawu SDK usługi Azure Machine Learning lub interfejsu wiersza polecenia.
- Jeśli zestaw danych jest duży, rozważ zarządzanie próbką danych na lokalnej stacji roboczej, zachowując pełny zestaw danych w magazynie w chmurze.
- Sparametryzuj bazę kodu eksperymentowania, aby można było skonfigurować zadania do uruchamiania z różną liczbą epok lub zestawów danych o różnych rozmiarach.
- Nie koduj twardej ścieżki folderu zestawu danych. Następnie można łatwo użyć tej samej bazy kodu z różnymi zestawami danych i w kontekście wykonywania lokalnego i w chmurze.
- Uruchamianie zadań eksperymentowania w lokalnym trybie docelowym obliczeń podczas opracowywania lub testowania lub przełączania do udostępnionej pojemności klastra obliczeniowego podczas przesyłania zadań na pełną skalę.
- Jeśli zestaw danych jest duży, współpracuj z próbką danych na lokalnej lub obliczeniowej stacji roboczej wystąpienia obliczeniowego, skalując do obliczeń w chmurze w usłudze Azure Machine Learning, aby pracować z pełnym zestawem danych.
- Gdy wykonywanie zadań zajmuje dużo czasu, rozważ optymalizację bazy kodu na potrzeby trenowania rozproszonego, aby umożliwić skalowanie w poziomie.
- Zaprojektuj obciążenia trenowania rozproszonego pod kątem elastyczności węzłów, aby umożliwić elastyczne korzystanie z zasobów obliczeniowych z jednym węzłem i wieloma węzłami oraz łatwość użycia zasobów obliczeniowych, które mogą zostać wywłaszczone.
Łączenie typów obliczeniowych przy użyciu potoków usługi Azure Machine Learning
Podczas organizowania przepływów pracy uczenia maszynowego można zdefiniować potok z wieloma krokami. Każdy krok w potoku może być uruchamiany we własnym typie obliczeniowym. Dzięki temu można zoptymalizować wydajność i koszty, aby spełnić różne wymagania obliczeniowe w całym cyklu życia uczenia maszynowego.
Dążenie do najlepszego wykorzystania budżetu zespołu
Chociaż decyzje dotyczące alokacji budżetu mogą być poza zakresem kontroli nad poszczególnymi zespołami, zespół jest zazwyczaj uprawniony do korzystania z przydzielonego budżetu do swoich najlepszych potrzeb. Dzięki rozmieszeniu priorytetu zadania w porównaniu z wydajnością i kosztami zespół może osiągnąć wyższe wykorzystanie klastra, obniżyć całkowity koszt i użyć większej liczby godzin obliczeniowych z tego samego budżetu. Może to spowodować zwiększenie produktywności zespołu.
Optymalizowanie kosztów udostępnionych zasobów obliczeniowych
Kluczem do optymalizacji kosztów udostępnionych zasobów obliczeniowych jest upewnienie się, że są one używane do pełnej pojemności. Poniżej przedstawiono kilka wskazówek dotyczących optymalizacji kosztów zasobów udostępnionych:
- Jeśli używasz wystąpień obliczeniowych, włącz je tylko wtedy, gdy masz kod do wykonania. Zamknij je, gdy nie są używane.
- W przypadku korzystania z klastrów obliczeniowych ustaw minimalną liczbę węzłów na 0 i maksymalną liczbę węzłów, która jest obliczana na podstawie ograniczeń budżetowych. Użyj kalkulatora cen platformy Azure , aby obliczyć koszt pełnego wykorzystania jednego węzła maszyny wirtualnej wybranej jednostki SKU maszyny wirtualnej. Skalowanie automatyczne spowoduje skalowanie w dół wszystkich węzłów obliczeniowych, gdy nikt go nie używa. Będzie ona skalowana tylko w górę do liczby węzłów, dla których masz budżet. Skalowanie automatyczne można skonfigurować w celu skalowania w dół wszystkich węzłów obliczeniowych.
- Monitoruj wykorzystanie zasobów, takie jak wykorzystanie procesora CPU i wykorzystanie procesora GPU podczas trenowania modeli. Jeśli zasoby nie są w pełni używane, zmodyfikuj kod, aby lepiej używać zasobów lub skalować w dół do mniejszych lub tańszych rozmiarów maszyn wirtualnych.
- Oceń, czy możesz utworzyć udostępnione zasoby obliczeniowe dla zespołu, aby uniknąć nieefektywności obliczeniowych spowodowanych operacjami skalowania klastra.
- Optymalizowanie zasad limitu czasu automatycznego skalowania klastra obliczeniowego na podstawie metryk użycia.
- Użyj limitów przydziałów obszaru roboczego, aby kontrolować ilość zasobów obliczeniowych, do których mają dostęp poszczególne obszary robocze.
Wprowadzenie priorytetu planowania przez utworzenie klastrów dla wielu jednostek SKU maszyn wirtualnych
Działając w ramach ograniczeń przydziału i budżetu, zespół musi odprzeć terminowe wykonywanie zadań w porównaniu z kosztami, aby zapewnić czas wykonywania ważnych zadań, a budżet jest używany w najlepszy możliwy sposób.
Aby zapewnić najlepsze wykorzystanie zasobów obliczeniowych, zespoły są zalecane do tworzenia klastrów o różnych rozmiarach oraz z niskim priorytetem i dedykowanymi priorytetami maszyn wirtualnych . Obliczenia o niskim priorytetach wykorzystują nadwyżkę pojemności na platformie Azure i dlatego są wyposażone w obniżone stawki. Po wadzie te maszyny mogą zostać wywłaszczone w dowolnym momencie, gdy pojawi się pytanie o wyższy priorytet.
Korzystając z klastrów o różnym rozmiarze i priorytetzie, można wprowadzić pojęcie priorytetu planowania. Na przykład gdy zadania eksperymentalne i produkcyjne rywalizują o ten sam limit przydziału procesora GPU NC , zadanie produkcyjne może mieć preferencję uruchomienia w ramach zadania eksperymentalnego. W takim przypadku uruchom zadanie produkcyjne w dedykowanym klastrze obliczeniowym i zadanie eksperymentalne w klastrze obliczeniowym o niskim priorytetu. Gdy limit przydziału spadnie, eksperymentalne zadanie zostanie wywłaszczone na rzecz zadania produkcyjnego.
Obok priorytetu maszyny wirtualnej rozważ uruchomienie zadań na różnych jednostkach SKU maszyn wirtualnych. Może to oznaczać, że zadanie trwa dłużej na wystąpieniu maszyny wirtualnej z procesorem GPU P40 niż na procesorze GPU w wersji 100. Jednak ponieważ wystąpienia maszyn wirtualnych w wersji 100 mogą być zajęte lub w pełni używane limity przydziału, czas ukończenia procesu P40 może być nadal szybszy z perspektywy przepływności zadania. Możesz również rozważyć uruchamianie zadań o niższym priorytykcie dla mniej wydajnych i tańszych wystąpień maszyn wirtualnych z perspektywy zarządzania kosztami.
Wczesne zakończenie przebiegu, gdy trenowanie nie jest zbieżne
Podczas ciągłego eksperymentowania w celu ulepszenia modelu względem punktu odniesienia możesz wykonywać różne przebiegi eksperymentów, z których każda ma nieco różne konfiguracje. W przypadku jednego przebiegu można dostosować wejściowe zestawy danych. W przypadku innego przebiegu możesz wprowadzić zmianę hiperparametru. Nie wszystkie zmiany mogą być tak skuteczne, jak inne. Na początku wykryto, że zmiana nie miała zamierzonego wpływu na jakość trenowania modelu. Aby wykryć, czy trenowanie nie jest zbieżne, monitoruj postęp trenowania podczas przebiegu. Na przykład przez rejestrowanie metryk wydajności po każdej epoki trenowania. Rozważ wczesne zakończenie zadania, aby zwolnić zasoby i budżet na inną wersję próbną.
Planowanie, zarządzanie budżetami, kosztami i limitami przydziału oraz zarządzanie nimi
Ponieważ organizacja zwiększa liczbę przypadków użycia uczenia maszynowego i zespołów, wymaga zwiększonej dojrzałości operacyjnej od działu IT i finansów, a także koordynacji między poszczególnymi zespołami uczenia maszynowego w celu zapewnienia wydajnych operacji. Zarządzanie pojemnością i limitami przydziału w skali firmy staje się ważne, aby rozwiązać problem z niedoborem zasobów obliczeniowych i przezwyciężyć nakłady pracy związane z zarządzaniem.
W tej sekcji omówiono najlepsze rozwiązania dotyczące planowania, zarządzania i udostępniania budżetów, kosztów i limitów przydziału w skali przedsiębiorstwa. Jest on oparty na uczeniu się od zarządzania wieloma zasobami szkoleniowymi procesora GPU na potrzeby uczenia maszynowego wewnętrznie w firmie Microsoft.
Omówienie wydatków na zasoby za pomocą usługi Azure Machine Learning
Jednym z największych wyzwań jako administrator planowania potrzeb obliczeniowych jest rozpoczęcie nowego z brakiem informacji historycznych jako szacowania bazowego. W praktyce większość projektów rozpocznie się od małego budżetu jako pierwszego kroku.
Aby dowiedzieć się, skąd ma miejsce budżet, ważne jest, aby wiedzieć, skąd pochodzą koszty usługi Azure Machine Learning:
- Usługa Azure Machine Learning pobiera opłaty tylko za używaną infrastrukturę obliczeniową i nie dodaje dodatkowej opłaty za koszty obliczeń.
- Po utworzeniu obszaru roboczego usługi Azure Machine Learning istnieje również kilka innych zasobów utworzonych w celu włączenia usługi Azure Machine Learning: Key Vault, usługi Application Insights, usługi Azure Storage i Azure Container Registry. Te zasoby są używane w usłudze Azure Machine Learning i płacisz za te zasoby.
- Istnieją koszty związane z zarządzanymi obliczeniami, takimi jak klastry szkoleniowe, wystąpienia obliczeniowe i zarządzane punkty końcowe wnioskowania. W przypadku tych zarządzanych zasobów obliczeniowych istnieją następujące koszty infrastruktury do uwzględnienia: maszyny wirtualne, sieć wirtualna, moduł równoważenia obciążenia, przepustowość i magazyn.
Śledzenie wzorców wydatków i lepsze raportowanie przy użyciu tagowania
Administratorzy często chcą śledzić koszty w różnych zasobach w usłudze Azure Machine Learning. Tagowanie jest naturalnym rozwiązaniem tego problemu i jest zgodne z ogólnym podejściem używanym przez platformę Azure i wieloma innymi dostawcami usług w chmurze. Dzięki obsłudze tagów można teraz zobaczyć podział kosztów na poziomie obliczeniowym, co zapewnia dostęp do bardziej szczegółowego widoku, aby ułatwić lepsze monitorowanie kosztów, lepsze raportowanie i większą przejrzystość.
Tagowanie umożliwia umieszczanie niestandardowych tagów w obszarach roboczych i obliczeniach (z szablonów usługi Azure Resource Manager i Azure Machine Learning studio) w celu dalszego filtrowania tych zasobów w usłudze Azure Cost Management na podstawie tych tagów w celu obserwowania wzorców wydatków. Ta funkcja może być najlepiej wykorzystywana w scenariuszach wewnętrznej opłaty zwrotnej. Ponadto tagi mogą być przydatne do przechwytywania metadanych lub szczegółów skojarzonych z obliczeniami, np. projektu, zespołu, określonego kodu rozliczeniowego itp. Dzięki temu tagowanie jest bardzo korzystne do mierzenia ilości pieniędzy, które wydajesz na różne zasoby, a zatem uzyskanie dokładniejszego wglądu w koszty i wzorce wydatków w zespołach lub projektach.
Istnieją również tagi wprowadzone przez system umieszczone na obliczeniach, które umożliwiają filtrowanie na stronie Analiza kosztów przez tag "Typ obliczeniowy", aby wyświetlić mądry podział zasobów obliczeniowych całkowitych wydatków i określić, która kategoria zasobów obliczeniowych może być przypisywana do większości kosztów. Jest to szczególnie przydatne w przypadku uzyskania większego wglądu w trenowanie i wnioskowanie wzorców kosztów.
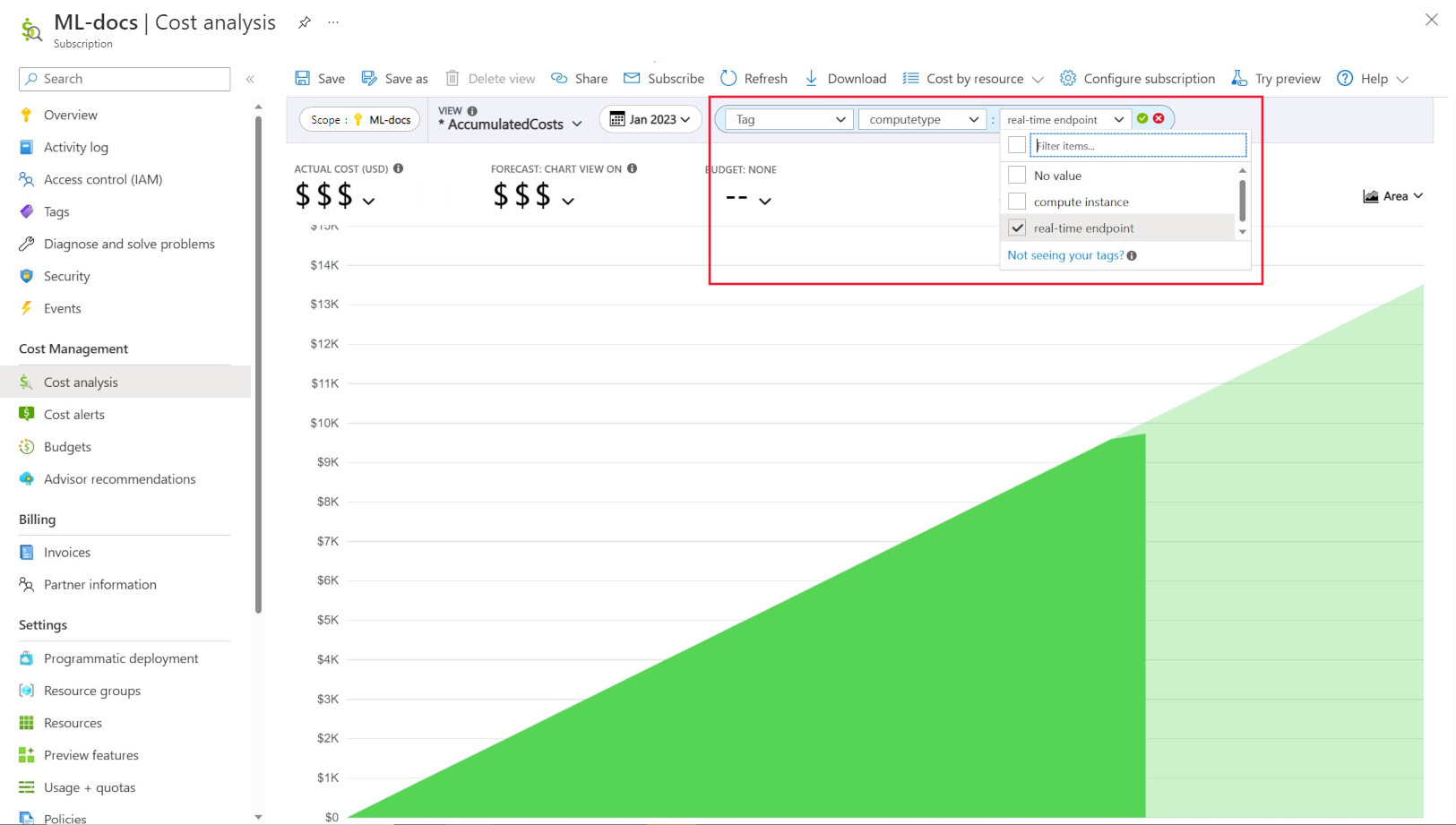
Zarządzanie i ograniczanie użycia zasobów obliczeniowych według zasad
Zarządzanie środowiskiem platformy Azure przy użyciu wielu obciążeń może stanowić wyzwanie, aby zachować przegląd wydatków na zasoby. Azure Policy może pomóc kontrolować wydatki na zasoby i zarządzać nimi, ograniczając określone wzorce użycia w środowisku platformy Azure.
W przypadku usługi Azure Machine Learning zalecamy skonfigurowanie zasad w celu zezwolenia tylko na użycie określonych jednostek SKU maszyn wirtualnych. Zasady mogą pomóc w zapobieganiu i kontrolowaniu wyboru drogich maszyn wirtualnych. Zasady mogą być również używane do wymuszania użycia jednostek SKU maszyn wirtualnych o niskim priorytcie.
Przydzielanie limitu przydziału i zarządzanie nimi na podstawie priorytetu biznesowego
Platforma Azure umożliwia ustawianie limitów przydziału na poziomie subskrypcji i obszaru roboczego usługi Azure Machine Learning. Ograniczenie, kto może zarządzać limitem przydziału za pomocą kontroli dostępu opartej na rolach (RBAC) platformy Azure , może pomóc zapewnić wykorzystanie zasobów i przewidywalność kosztów.
Dostępność limitu przydziału procesora GPU może być ograniczona w ramach subskrypcji. Aby zapewnić wysokie wykorzystanie przydziału w ramach obciążeń, zalecamy monitorowanie, czy limit przydziału jest najlepiej używany i przypisywany w ramach obciążeń.
W firmie Microsoft okresowo określa się, czy przydziały procesora GPU są najlepiej używane i przydzielane w zespołach uczenia maszynowego, oceniając wymagania dotyczące pojemności względem priorytetu biznesowego.
Zatwierdź pojemność przed upływem czasu
Jeśli masz dobre oszacowanie, ile zasobów obliczeniowych będzie używanych w przyszłym roku lub w przyszłym roku, możesz kupić wystąpienia zarezerwowanych maszyn wirtualnych platformy Azure w obniżonym koszcie. Istnieją roczne lub trzyletnie warunki zakupu. Ponieważ wystąpienia zarezerwowane maszyn wirtualnych platformy Azure są obniżone, w porównaniu z cenami płatności zgodnie z rzeczywistym użyciem mogą być znaczne oszczędności.
Usługa Azure Machine Learning obsługuje wystąpienia zarezerwowane zasobów obliczeniowych. Rabaty są automatycznie stosowane względem zasobów obliczeniowych zarządzanych przez usługę Azure Machine Learning.
Zarządzanie przechowywaniem danych
Za każdym razem, gdy potok uczenia maszynowego jest wykonywany, zestawy danych pośrednich można wygenerować w każdym kroku potoku na potrzeby buforowania i ponownego użycia danych. Wzrost danych jako danych wyjściowych tych potoków uczenia maszynowego może stać się punktem bólu dla organizacji, która uruchamia wiele eksperymentów uczenia maszynowego.
Analitycy danych zazwyczaj nie poświęcają czasu na czyszczenie pośrednich zestawów danych, które są generowane. W czasie ilość generowanych danych będzie się sumowała. Usługa Azure Storage oferuje możliwość ulepszenia zarządzania cyklem życia danych. Za pomocą Azure Blob Storage zarządzania cyklem życia można skonfigurować ogólne zasady przenoszenia danych, które są nieużywane w chłodniejszych warstwach magazynowania i oszczędzać koszty.
Zagadnienia dotyczące optymalizacji kosztów infrastruktury
Sieć
Koszt sieci platformy Azure jest naliczany z przepustowości wychodzącej z centrum danych platformy Azure. Wszystkie dane przychodzące do centrum danych platformy Azure są bezpłatne. Kluczem do zmniejszenia kosztów sieci jest wdrożenie wszystkich zasobów w tym samym regionie centrum danych, jeśli to możliwe. Jeśli możesz wdrożyć obszar roboczy usługi Azure Machine Learning i obliczenia w tym samym regionie, w którym są używane dane, możesz cieszyć się niższym kosztem i większą wydajnością.
Możesz mieć połączenie prywatne między siecią lokalną a siecią platformy Azure, aby mieć środowisko chmury hybrydowej. Usługa ExpressRoute pozwala to zrobić, ale biorąc pod uwagę wysokie koszty usługi ExpressRoute, może to być bardziej ekonomiczne, aby odejść od konfiguracji chmury hybrydowej i przenieść wszystkie zasoby do chmury platformy Azure.
Azure Container Registry
W przypadku Azure Container Registry czynniki określające optymalizację kosztów obejmują:
- Wymagana przepływność dla obrazów platformy Docker pobieranych z rejestru kontenerów do usługi Azure Machine Learning
- Wymagania dotyczące funkcji zabezpieczeń przedsiębiorstwa, takich jak Azure Private Link
W przypadku scenariuszy produkcyjnych, w których wymagana jest wysoka przepływność lub zabezpieczenia przedsiębiorstwa, zalecana jest jednostka SKU Premium Azure Container Registry.
W przypadku scenariuszy tworzenia i testowania, w których przepływność i zabezpieczenia są mniej krytyczne, zalecamy użycie jednostki SKU w warstwie Standardowa lub jednostki SKU w warstwie Premium.
Podstawowa jednostka SKU Azure Container Registry nie jest zalecana dla usługi Azure Machine Learning. Nie jest to zalecane ze względu na niską przepływność i niski poziom dołączonego magazynu, który można szybko przekroczyć przez stosunkowo duże obrazy platformy Docker usługi Azure Machine Learning (1+ GB).
Rozważ dostępność typu obliczeniowego podczas wybierania regionów platformy Azure
Po wybraniu regionu dla zasobów obliczeniowych należy pamiętać o dostępności limitu przydziału obliczeniowego. Popularne i większe regiony, takie jak Wschodnie stany USA, Zachodnie stany USA i Europa Zachodnia, mają tendencję do większej wartości przydziału domyślnego i większej dostępności większości procesorów CPU i procesorów GPU, w porównaniu z niektórymi innymi regionami z bardziej rygorystycznymi ograniczeniami pojemności.
Więcej tutaj
Następne kroki
Aby dowiedzieć się więcej na temat organizowania i konfigurowania środowisk usługi Azure Machine Learning, zobacz Organizowanie i konfigurowanie środowisk usługi Azure Machine Learning.
Aby dowiedzieć się więcej o najlepszych rozwiązaniach dotyczących metodyki DevOps usługi Machine Learning przy użyciu usługi Azure Machine Learning, zobacz Przewodnik devOps uczenia maszynowego.