Eksplorowanie galerii przykładów
Internetowy interfejs użytkownika usługi Azure Data Explorer zawiera galerię przykładów, w której możesz ćwiczyć pisanie zapytań i poleceń język zapytań Kusto (KQL). Ta galeria zawiera przykładowe dane z samouczkami z przewodnikiem w klastrze pomocy bezpłatnie i publicznie dostępnym.
Wymagania wstępne
Konto Microsoft lub tożsamość użytkownika Microsoft Entra, aby zalogować się do klastra pomocy. Subskrypcja platformy Azure nie jest wymagana.
Rozpocznij
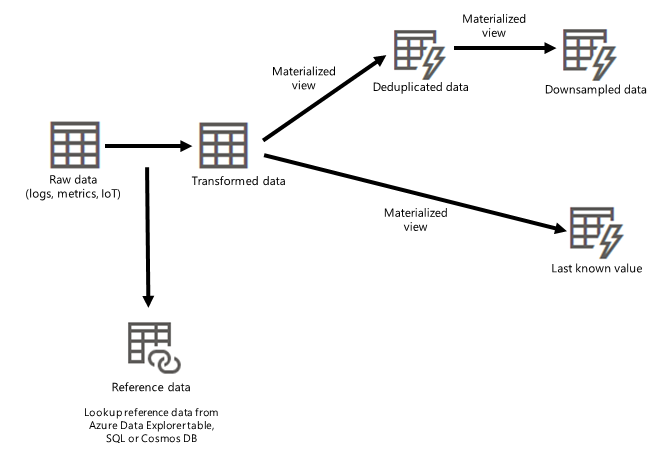
Na poniższym diagramie przedstawiono ogólny widok baz danych dostępnych w galerii przykładów.
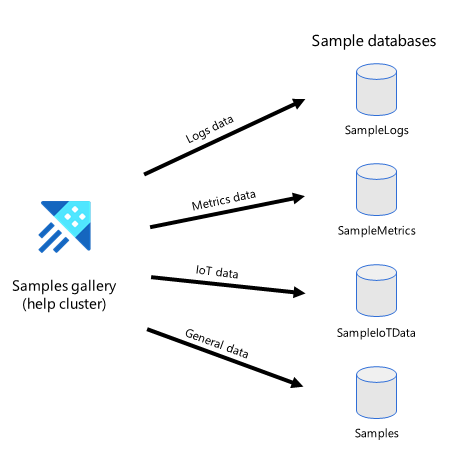
Wykonywanie akcji na przykładowych danych
Rozpocznij naukę na temat zapytań KQL za pomocą zestawu danych z galerii przykładów.
Zaloguj się do internetowego interfejsu użytkownika usługi Azure Data Explorer przy użyciu konta Microsoft lub tożsamości użytkownika Microsoft Entra.
Na stronie głównej wybierz pozycję Eksploruj przykładowe dane za pomocą języka KQL.
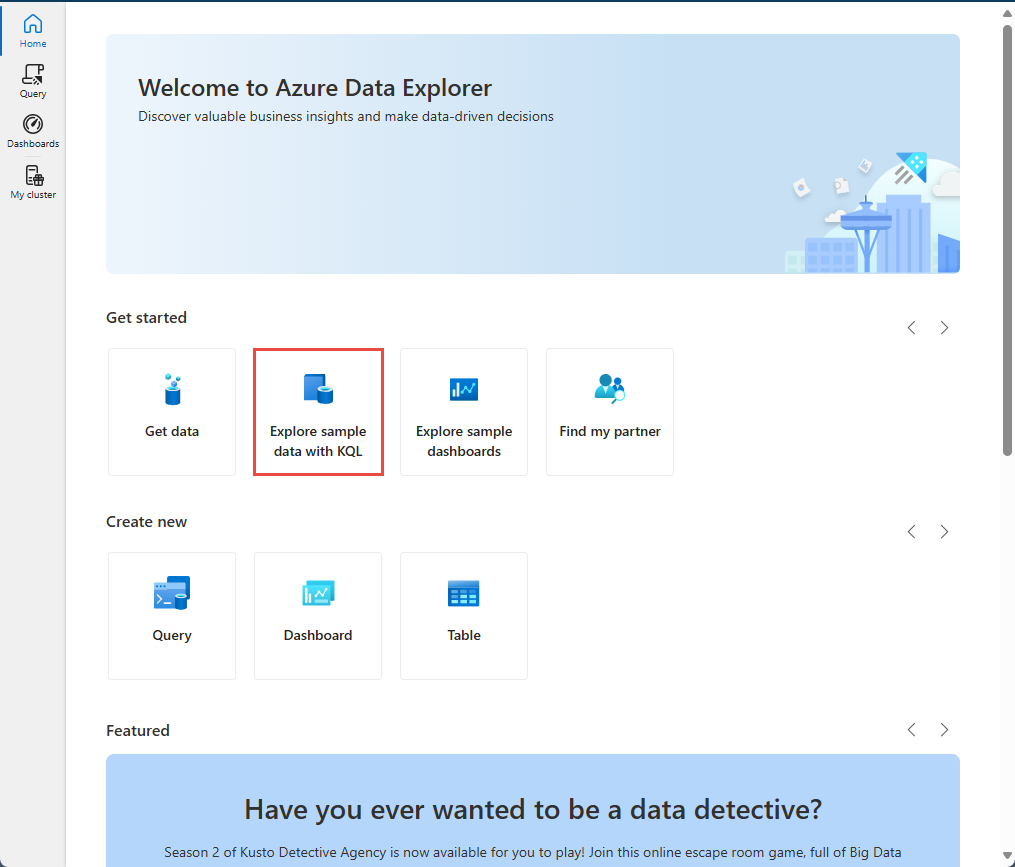
W oknie dialogowym Eksploruj przykłady danych wybierz przykładowy zestaw danych, a następnie wybierz pozycję Eksploruj.
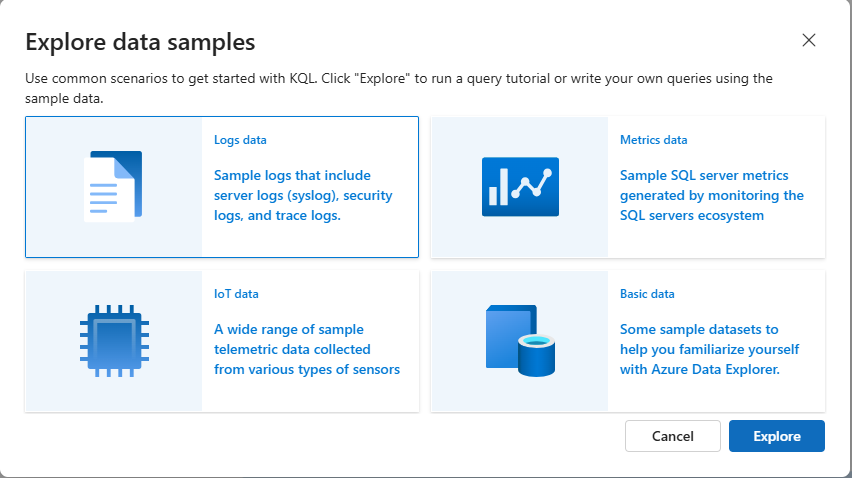
W okienku połączenia klastra klaster pomocy jest wyświetlany z przykładowymi bazami danych przedstawiającymi przechowywane funkcje, tabele zewnętrzne, zmaterializowane widoki i tabele bazy danych. Baza danych wybrana w oknie dialogowym przykładowych danych jest wyróżniona.
Ten diagram przedstawia ogólny widok przepływu danych architektonicznych, od danych pierwotnych przez pozyskiwanie, przetwarzanie i zmaterializowane widoki.

Postępuj zgodnie z samouczkami
Okno edytora zapytań znajdujące się po prawej stronie okienka połączeń klastra zawiera przydatne samouczki w postaci często używanych zapytań wraz ze szczegółowymi wyjaśnieniami.
Przyjrzymy się bazie danych Metryk z etykietą SampleMetrics w okienku połączeń klastra.
Zestaw danych SampleMetrics składa się z następujących tabel:
- RawServerMetrics: gdzie nieprzetworzone dane są pozyskiwane na potrzeby magazynu tymczasowego.
- TransformedServerMetrics: gdzie są przechowywane przeanalizowane i przetworzone dane.
- SQLServersLocation: zawierające dane referencyjne lokalizacji serwerów.
Napiwek
Możesz przejść do innych samouczków w oknie edytora zapytań. Wybierz pozycję Otwórz samouczki,>a następnie wybierz konkretny samouczek, który chcesz eksplorować.
Uruchamianie zapytania
W oknie edycji zapytania umieść kursor w zapytaniu i wybierz pozycję Uruchom w górnej części okna lub naciśnij Shift + Enter, aby uruchomić zapytanie. Wyniki są wyświetlane w okienku wyników zapytania bezpośrednio poniżej okna edytora zapytań.
Przed uruchomieniem dowolnego zapytania lub polecenia pośmiń chwilę na przeczytanie powyższych komentarzy. Komentarze zawierają ważne informacje. Na przykład dlaczego niektóre polecenia zarządzania nie będą działać w klastrze pomocy z powodu braku uprawnień. Edytor zapytań udostępnia sugestie i ostrzeżenia podczas pisania zapytań. Aby dostosować otrzymywane sugestie i ostrzeżenia, zobacz Ustawianie zaleceń dotyczących zapytań.

Polecenia zarządzania usługą Learn
Ponieważ niektórych poleceń zarządzania nie można uruchomić w klastrze pomocy , możesz utworzyć własny bezpłatny klaster , aby dokładniej zapoznać się z tymi poleceniami. Niektóre przykłady tych poleceń opisano w poniższej tabeli.
| Table | opis | Command |
|---|---|---|
| RawServerMetrics | Zasady dzielenia na partie pozyskiwania można skonfigurować tak, aby zmniejszyć domyślne opóźnienie pozyskiwania z 5 minut do 20 sekund, zgodnie z opisem. | .alter table RawServerMetrics policy ingestionbatching @'{"MaximumBatchingTimeSpan": "00:00:20", "MaximumNumberOfItems": 500,"MaximumRawDataSizeMB": 1024}' |
| RawServerMetrics | Zasady przechowywania danych można skonfigurować na 10 dni, aby uniknąć duplikowania danych w tabelach pierwotnych i przekształconych. W razie potrzeby można przechowywać nieprzetworzone dane dłużej. Jeśli na przykład występują problemy z tabelą TransformedServerMetrics , zamiast wracać do danych źródłowych, możesz odwołać się do danych w tabeli RawServerMetrics . | .alter table RawServerMetrics policy retention '{"SoftDeletePeriod": "10.00:00:00", "Recoverability": "Enabled"}' |
| TransformedServerMetrics | Zasady aktualizacji można zastosować do przekształcania i analizowania danych pierwotnych. | .alter table TransformedServerMetrics policy update @'[{"IsEnabled": true, "Source": "RawServerMetrics", "Query": "Transform_RawServerMetrics()", "IsTransactional": true, "PropagateIngestionProperties": false}]' |