Optymalizowanie ujść
Gdy przepływy danych zapisują w ujściach, wszelkie partycjonowanie niestandardowe odbywa się bezpośrednio przed zapisem. Podobnie jak w przypadku źródła, w większości przypadków zaleca się zachowanie opcji Użyj bieżącej partycji jako wybranej opcji partycji. Partycjonowane dane zapisują się znacznie szybciej niż dane niepartycyjne, nawet miejsce docelowe nie jest partycjonowane. Poniżej przedstawiono poszczególne zagadnienia dotyczące różnych typów ujścia.
Ujścia usługi Azure SQL Database
W przypadku usługi Azure SQL Database domyślne partycjonowanie powinno działać w większości przypadków. Istnieje prawdopodobieństwo, że ujście może mieć zbyt wiele partycji do obsługi bazy danych SQL. Jeśli w tym celu wystąpią błędy, zmniejsz liczbę partycji wyjściowych przez ujście usługi SQL Database.
Najlepsze rozwiązanie dotyczące usuwania wierszy w ujściu na podstawie brakujących wierszy w źródle
Oto przewodnik wideo przedstawiający sposób używania przepływów danych z istnieje, zmienia przekształcenia wierszy i ujścia w celu osiągnięcia tego wspólnego wzorca:
Wpływ obsługi wierszy błędów na wydajność
Po włączeniu obsługi wierszy błędów ("kontynuuj błąd") w przekształceniu ujścia usługa wykonuje dodatkowy krok przed zapisaniem zgodnych wierszy do tabeli docelowej. Ten dodatkowy krok ma niewielką karę za wydajność, która może być w zakresie 5% dodanych do tego kroku z dodatkowym małym trafieniem wydajności dodanym również w przypadku ustawienia opcji zapisywania niezgodnych wierszy w pliku dziennika.
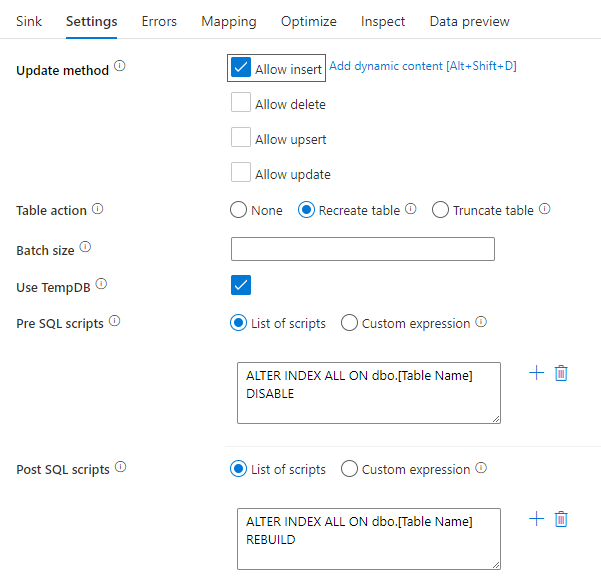
Wyłączanie indeksów przy użyciu skryptu SQL
Wyłączenie indeksów przed załadowaniem w bazie danych SQL może znacznie poprawić wydajność zapisu w tabeli. Uruchom poniższe polecenie przed zapisaniem w ujściu SQL.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
Po zakończeniu zapisu ponownie skompiluj indeksy przy użyciu następującego polecenia:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Można to zrobić natywnie przy użyciu skryptów wstępnych i Post-SQL w ramach usługi Azure SQL Database lub ujścia usługi Synapse w przepływach danych mapowania.
Ostrzeżenie
Podczas wyłączania indeksów przepływ danych skutecznie przejmuje kontrolę nad bazą danych, a zapytania prawdopodobnie nie powiedzą się w tej chwili. W rezultacie wiele zadań ETL jest wyzwalanych w środku nocy, aby uniknąć tego konfliktu. Aby uzyskać więcej informacji, dowiedz się więcej o ograniczeniach wyłączania indeksów SQL
Skalowanie bazy danych w górę
Zaplanuj zmianę rozmiaru źródłowej i ujścia usługi Azure SQL DB i DW przed uruchomieniem potoku, aby zwiększyć przepływność i zminimalizować ograniczanie przepustowości platformy Azure po osiągnięciu limitów jednostek DTU. Po zakończeniu wykonywania potoku zmień rozmiar baz danych z powrotem na normalną szybkość uruchamiania.
Ujścia usługi Azure Synapse Analytics
Podczas zapisywania w usłudze Azure Synapse Analytics upewnij się, że ustawienie Włącz przemieszczanie ma wartość true. Dzięki temu usługa może zapisywać dane za pomocą polecenia SQL COPY, które skutecznie ładuje dane zbiorczo. Musisz odwołać się do konta usługi Azure Data Lake Storage gen2 lub usługi Azure Blob Storage na potrzeby przemieszczania danych podczas korzystania z przemieszczania.
Inne niż przejściowe, te same najlepsze rozwiązania dotyczą usługi Azure Synapse Analytics jako usługi Azure SQL Database.
Ujścia oparte na plikach
Chociaż przepływy danych obsługują różne typy plików, format Parquet natywny dla platformy Spark jest zalecany w celu uzyskania optymalnego czasu odczytu i zapisu.
Jeśli dane są równomiernie dystrybuowane, użyj bieżącego partycjonowania jest najszybszą opcją partycjonowania do zapisywania plików.
Opcje nazwy pliku
Podczas pisania plików można wybrać opcje nazewnictwa, które mają wpływ na wydajność.
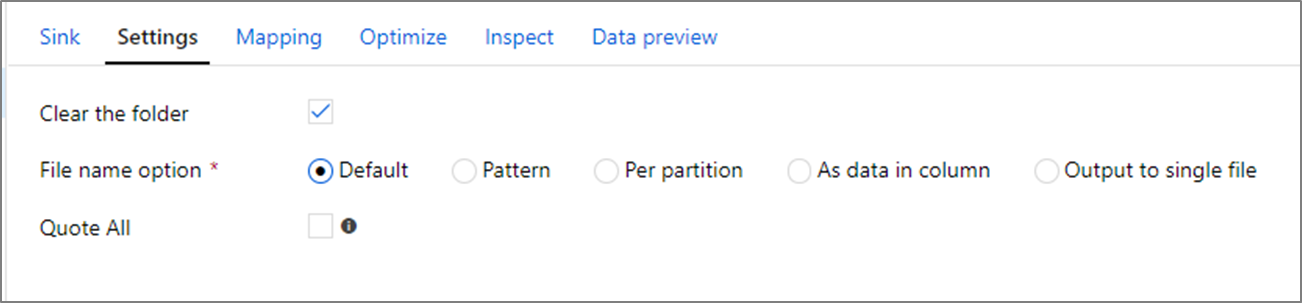
Wybranie opcji Domyślne powoduje najszybsze zapisanie. Każda partycja jest równa pliku z domyślną nazwą platformy Spark. Jest to przydatne, jeśli po prostu odczytujesz z folderu danych.
Ustawienie wzorca nazewnictwa zmienia nazwę każdego pliku partycji na bardziej przyjazną nazwę. Ta operacja odbywa się po zapisie i jest nieco wolniejsza niż wybranie wartości domyślnej.
Na partycję można ręcznie nazwać każdą pojedynczą partycję.
Jeśli kolumna odpowiada sposobie wyprowadzania danych, możesz wybrać pozycję Nazwa pliku jako dane kolumny. Spowoduje to przetasowanie danych i może mieć wpływ na wydajność, jeśli kolumny nie są równomiernie rozproszone.
Jeśli kolumna odpowiada sposobie generowania nazw folderów, wybierz pozycję Nazwa folderu jako dane kolumny.
Dane wyjściowe do pojedynczego pliku łączą wszystkie dane w jedną partycję. Prowadzi to do długich czasów zapisu, zwłaszcza w przypadku dużych zestawów danych. Ta opcja jest zniechęcona, chyba że istnieje jawny powód biznesowy, aby go użyć.
Ujścia usługi Azure Cosmos DB
Podczas pisania w usłudze Azure Cosmos DB zmiana przepływności i rozmiaru partii podczas wykonywania przepływu danych może zwiększyć wydajność. Te zmiany zostaną zastosowane tylko podczas uruchamiania działania przepływu danych i zostaną zwrócone do oryginalnych ustawień kolekcji po zakończeniu.
Rozmiar partii: zazwyczaj wystarczy domyślny rozmiar partii. Aby jeszcze bardziej dostosować tę wartość, oblicz przybliżony rozmiar obiektu danych i upewnij się, że rozmiar obiektu * rozmiar partii jest mniejszy niż 2 MB. Jeśli tak jest, możesz zwiększyć rozmiar partii, aby uzyskać lepszą przepływność.
Przepływność: ustaw tutaj ustawienie wyższej przepływności, aby umożliwić dokumentom szybsze zapisywanie w usłudze Azure Cosmos DB. Należy pamiętać o wyższych kosztach jednostek RU na podstawie ustawienia wysokiej przepływności.
Budżet przepływności zapisu: użyj wartości, która jest mniejsza niż łączna liczba jednostek RU na minutę. Jeśli masz przepływ danych z dużą liczbą partycji platformy Spark, ustawienie przepływności budżetu umożliwia większą równowagę między tymi partycjami.
Powiązana zawartość
- Omówienie wydajności przepływu danych
- Optymalizowanie źródeł
- Optymalizowanie przekształceń
- Używanie przepływów danych w potokach
Zobacz inne artykuły Przepływ danych związane z wydajnością: