Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Przepływy mapowania danych w potokach Azure Data Factory i Synapse zapewniają interfejs bezkodowy do projektowania i uruchamiania przekształceń danych w dużej skali. Jeśli nie znasz przepływów mapowania danych, zobacz Mapping Data Flow Overview . W tym artykule przedstawiono różne sposoby dostosowywania i optymalizowania przepływów danych w celu spełnienia testów porównawczych wydajności.
Obejrzyj poniższy film, aby zobaczyć kilka przykładowych czasów przekształcania danych przy użyciu przepływów danych.
Monitorowanie wydajności przepływu danych
Po zweryfikowaniu logiki transformacji przy użyciu trybu debugowania uruchom przepływ danych end-to-end jako działania w ramach potoku. Przepływy danych są operacjonalizowane w potoku przy użyciu działania wykonywania przepływu danych. Działanie przepływu danych ma unikatowe środowisko monitorowania w porównaniu z innymi działaniami, które wyświetlają szczegółowy plan wykonania i profil wydajności logiki przekształcania. Aby wyświetlić szczegółowe informacje o monitorowaniu przepływu danych, wybierz symbol okularów w danych wyjściowych przebiegu potoku. Aby uzyskać więcej informacji, zobacz Monitorowanie przepływów danych mapowania.

Gdy monitorujesz wydajność przepływu danych, należy mieć na uwadze cztery możliwe wąskie gardła:
- Czas uruchamiania klastra
- Odczytywanie ze źródła
- Czas przekształcania
- Zapisywanie w ujściu
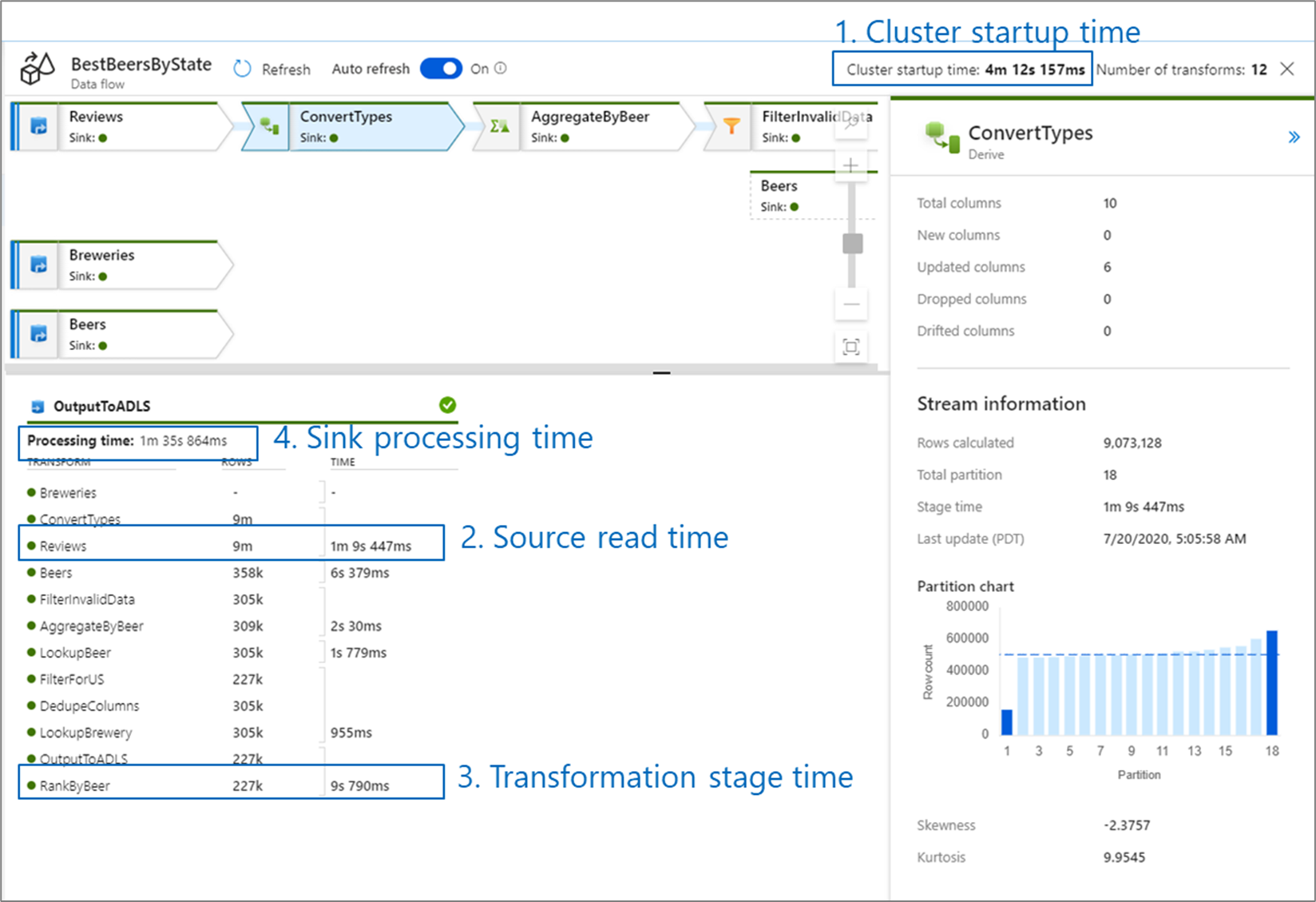
Czas uruchamiania klastra to czas potrzebny na uruchomienie klastra Apache Spark. Ta wartość znajduje się w prawym górnym rogu ekranu monitorowania. Przepływy danych działają w modelu just-in-time, w którym każde zadanie korzysta z izolowanego klastra. Ten czas uruchamiania zazwyczaj trwa od 3 do 5 minut. W przypadku zadań sekwencyjnych czas uruchamiania można zmniejszyć, włączając wartość czasu życia. Aby uzyskać więcej informacji, zobacz sekcję Time to live w Integration Runtime performance.
Przepływy danych korzystają z optymalizatora Spark, który zmienia kolejność i uruchamia logikę biznesową w formie 'etapów', aby działać możliwie najszybciej. Dla każdego ujścia, do którego zapisuje się przepływ danych, dane wyjściowe monitorowania zawierają listę czasu trwania każdego etapu transformacji wraz z czasem zapisywania danych w ujściu. Czas o największym znaczeniu może stanowić wąskie gardło przepływu danych. Jeśli etap transformacji, który zajmuje najwięcej zasobów, obejmuje źródło, powinieneś rozważyć dalszą optymalizację czasu odczytu danych. Jeśli transformacja trwa długo, może być konieczne ponowne partycjonowanie lub zwiększenie rozmiaru środowiska Integration Runtime. Jeśli czas przetwarzania odbiornika jest długi, może być konieczne zwiększenie skali bazy danych lub sprawdzenie, czy dane wyjściowe nie są zapisywane do pojedynczego pliku.
Po zidentyfikowaniu wąskiego gardła przepływu danych użyj poniższych strategii optymalizacji, aby poprawić wydajność.
Testowanie logiki przepływu danych
Podczas projektowania i testowania przepływów danych z interfejsu użytkownika tryb debugowania umożliwia interakcyjne testowanie względem dynamicznego klastra Spark, co umożliwia wyświetlanie podglądu danych i wykonywanie przepływów danych bez oczekiwania na rozgrzanie klastra. Aby uzyskać więcej informacji, zobacz Tryb debugowania.
Zakładka optymalizacji
Karta Optymalizacja zawiera ustawienia służące do konfigurowania schematu partycjonowania klastra Spark. Ta karta istnieje w każdej transformacji przepływu danych i określa, czy chcesz ponownie partycjonować dane po zakończeniu transformacji. Dostosowanie partycjonowania zapewnia kontrolę nad rozkładem danych między węzłami obliczeniowymi i optymalizacjami lokalności danych, które mogą mieć pozytywny i negatywny wpływ na ogólną wydajność przepływu danych.
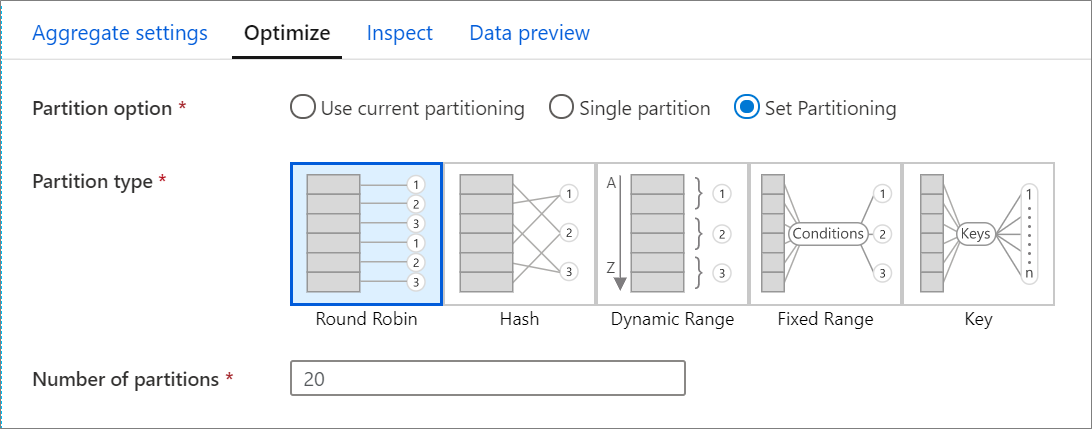
Domyślnie wybrano opcję Użyj bieżącego partycjonowania, która instruuje usługę, aby zachowywała bieżące partycjonowanie danych wyjściowych przekształcenia. Ponieważ ponowne partycjonowanie danych zajmuje trochę czasu, w większości scenariuszy zaleca się używanie bieżącego partycjonowania . Scenariusze, w których można chcieć przepartycjonować dane, obejmują sytuacje po zastosowaniu agregacji i sprzężeń, które znacząco wpływają na asymetrię danych, lub przy użyciu partycjonowania źródłowego w bazie danych SQL.
Aby zmienić partycjonowanie w dowolnej transformacji, wybierz kartę Optymalizowanie i wybierz przycisk radiowy Ustaw partycjonowanie . Zostanie wyświetlona seria opcji partycjonowania. Najlepsza metoda partycjonowania różni się w zależności od objętości danych, kluczy kandydujących, wartości null i kardynalności.
Ważne
Pojedyncza partycja łączy wszystkie rozproszone dane w jedną partycję. Jest to bardzo wolna operacja, która również znacząco wpływa na następujące przekształcenia i zapisy. Ta opcja jest zdecydowanie zniechęcona, chyba że istnieje jawny powód biznesowy, aby go użyć.
Następujące opcje partycjonowania są dostępne w każdej transformacji:
Działanie okrężne
Round robin rozdziela dane równomiernie między partycjami. Używaj algorytmu rotacyjnego, gdy nie masz dobrych kluczowych kandydatów do zaimplementowania inteligentnej strategii partycjonowania. Można ustawić liczbę partycji fizycznych.
Hasz
Usługa tworzy skrót kolumn w celu utworzenia równomiernych partycji, tak aby wiersze z podobnymi wartościami znajdowały się w tej samej partycji. Jeśli używasz opcji rozproszenia, przetestuj możliwe skew partycji. Można ustawić liczbę partycji fizycznych.
Zakres dynamiczny
Zakres dynamiczny używa zakresów dynamicznych platformy Spark na podstawie kolumn lub wyrażeń, które podajesz. Można ustawić liczbę partycji fizycznych.
Stały zakres
Utwórz wyrażenie, które zapewnia stały zakres wartości w kolumnach danych partycjonowanych. Aby uniknąć niesymetryczności partycji, przed użyciem tej opcji należy dobrze zrozumieć dane. Wartości wprowadzone dla wyrażenia są używane jako część funkcji partycji. Można ustawić liczbę partycji fizycznych.
Klucz
Jeśli dobrze rozumiesz kardynalność danych, partycjonowanie według klucza może być dobrą strategią. Partycjonowanie kluczy tworzy partycje dla każdej unikatowej wartości w kolumnie. Nie można ustawić liczby partycji, ponieważ liczba jest oparta na unikatowych wartościach w danych.
Wskazówka
Ręczne ustawianie schematu partycjonowania powoduje przetasowanie danych i może zrównoważyć korzyści optymalizatora platformy Spark. Zaleca się unikanie ręcznego ustawiania partycjonowania, chyba że jest to konieczne.
Poziom rejestrowania
Jeśli nie potrzebujesz, aby każde wykonanie potoku przepływu danych rejestrowało szczegółowe dzienniki telemetrii, możesz ustawić poziom rejestrowania na "Podstawowy" lub "Brak". Podczas wykonywania przepływów danych w trybie szczegółowym (ustawienie domyślne) żądasz, aby usługa w pełni rejestrowała aktywność na poziomie poszczególnych partycji podczas przekształcania danych. Może to być kosztowna operacja, dlatego warto włączać tryb szczegółowy tylko podczas rozwiązywania problemów, co może poprawić ogólny przepływ danych i wydajność potoku. Tryb "Podstawowy" rejestruje tylko czasy trwania transformacji, podczas gdy "Brak" podaje tylko podsumowanie czasów trwania transformacji.

Powiązana zawartość
- Optymalizowanie źródeł
- Optymalizowanie ujść
- Optymalizowanie przekształceń
- Używanie przepływów danych w potokach
Zobacz inne artykuły Data Flow związane z wydajnością: