Optymalizowanie przekształceń
Użyj poniższych strategii, aby zoptymalizować wydajność przekształceń w przepływach mapowania danych w potokach usługi Azure Data Factory i Azure Synapse Analytics.
Optymalizowanie sprzężeń, istnień i odnośników
Nadawania
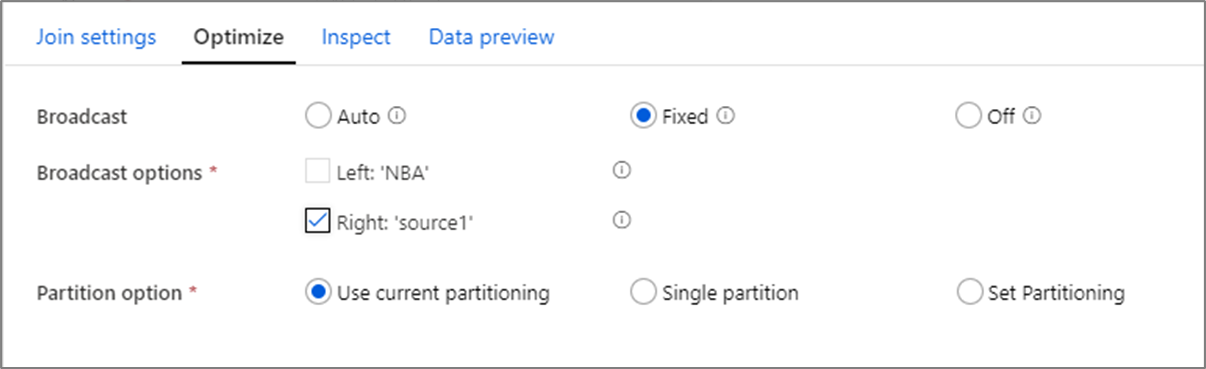
W sprzężeniach wyszukiwanie i istnieje przekształcenia, jeśli jeden lub oba strumienie danych są wystarczająco małe, aby zmieścić się w pamięci węzła roboczego, możesz zoptymalizować wydajność, włączając funkcję Emisja. Emisja polega na wysyłaniu małych ramek danych do wszystkich węzłów w klastrze. Dzięki temu aparat Spark może wykonać sprzężenie bez przetasowania danych w dużym strumieniu. Domyślnie aparat Spark automatycznie decyduje, czy emitować jedną stronę sprzężenia. Jeśli znasz dane przychodzące i wiesz, że jeden strumień jest mniejszy niż drugi, możesz wybrać opcję Emisja stała . Naprawiono emisję wymusza na platformie Spark emisję wybranego strumienia.
Jeśli rozmiar rozgłaszanych danych jest zbyt duży dla węzła Spark, może wystąpić błąd braku pamięci. Aby uniknąć błędów braku pamięci, użyj klastrów zoptymalizowanych pod kątem pamięci. Jeśli podczas wykonywania przepływu danych wystąpią przekroczenia limitu czasu emisji, możesz wyłączyć optymalizację emisji. Jednak powoduje to wolniejsze przepływy danych.
Podczas pracy ze źródłami danych, które mogą trwać dłużej, na przykład w przypadku dużych zapytań bazy danych, zaleca się wyłączenie emisji dla sprzężeń. Źródło z długimi czasami zapytań może powodować przekroczenia limitu czasu platformy Spark, gdy klaster próbuje rozgłaszać do węzłów obliczeniowych. Innym dobrym wyborem do wyłączenia emisji jest możliwość późniejszego użycia strumienia w przepływie danych, który agreguje wartości do użycia w przekształceniu odnośnika. Ten wzorzec może mylić optymalizator platformy Spark i powodować przekroczenia limitu czasu.
Sprzężenia krzyżowe
Jeśli używasz wartości literałów w warunkach sprzężenia lub masz wiele dopasowań po obu stronach sprzężenia, platforma Spark uruchamia sprzężenie jako sprzężenie krzyżowe. Sprzężenia krzyżowe to pełny produkt kartezjański, który następnie filtruje sprzężone wartości. Jest to wolniejsze niż inne typy sprzężeń. Upewnij się, że masz odwołania do kolumn po obu stronach warunków sprzężenia, aby uniknąć wpływu na wydajność.
Sortowanie przed sprzężeniami
W przeciwieństwie do łączenia scalania w narzędziach, takich jak SSIS, transformacja sprzężenia nie jest obowiązkową operacją scalania. Klucze sprzężenia nie wymagają sortowania przed przekształceniem. Używanie przekształceń sortowania w przepływach danych mapowania nie jest zalecane.
Wydajność przekształcania okien
Przekształcenie okna w przepływie mapowania danych partycjonuje dane według wartości w kolumnach wybranych jako część over() klauzuli w ustawieniach przekształcania. Istnieje wiele popularnych funkcji agregujących i analitycznych, które są widoczne w transformacji systemu Windows. Jeśli jednak twoim przypadkiem użycia jest wygenerowanie okna dla całego zestawu danych na potrzeby klasyfikacji rank() lub numeru rowNumber()wiersza, zaleca się użycie przekształcenia Ranga i przekształcenia Klucz zastępczy. Te przekształcenia lepiej wykonują pełne operacje na zestawach danych przy użyciu tych funkcji.
Ponowne partycjonowanie niesymetrycznych danych
Niektóre przekształcenia, takie jak sprzężenia i agregacje, przetasują partycje danych i mogą sporadycznie prowadzić do niesymetryczności danych. Niesymetryczne dane oznaczają, że dane nie są równomiernie dystrybuowane między partycjami. Duże niesymetryczne dane mogą prowadzić do wolniejszych przekształceń podrzędnych i zapisów ujścia. Możesz sprawdzić niesymetryczność danych w dowolnym momencie przebiegu przepływu danych, klikając przekształcenie na ekranie monitorowania.
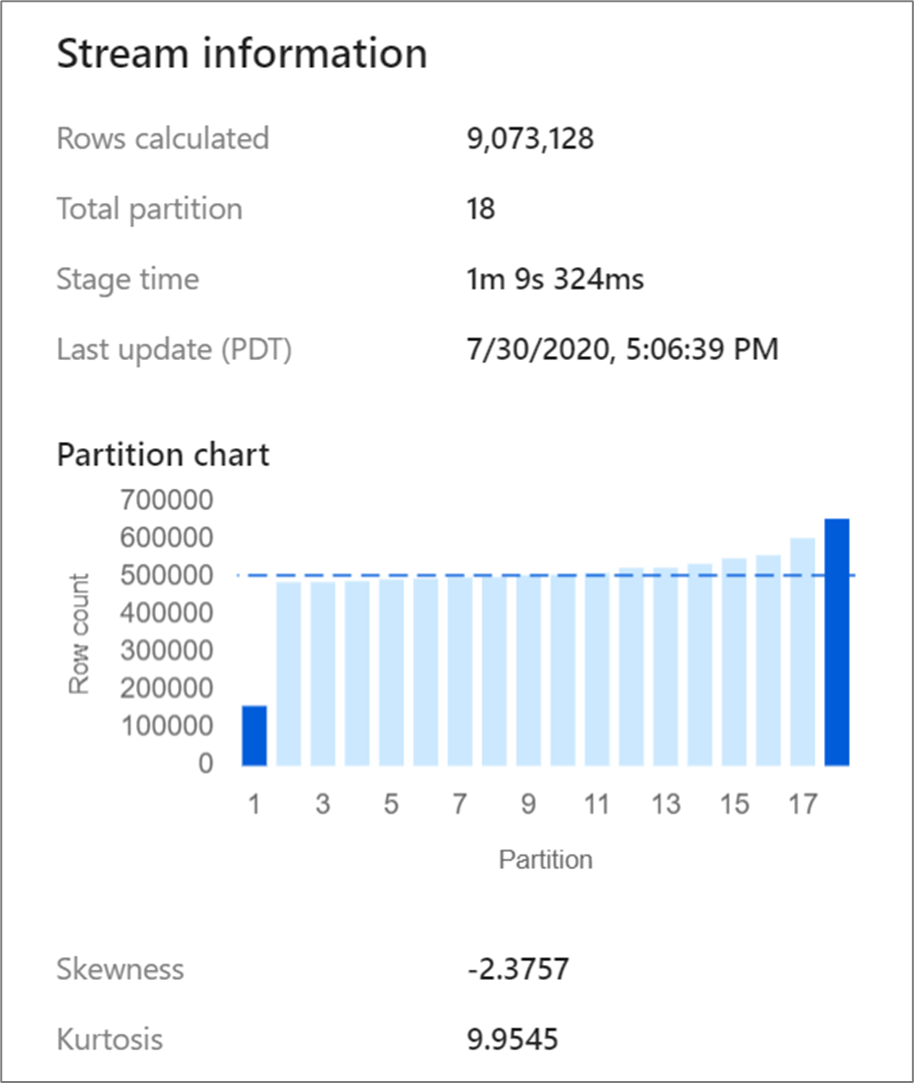
Na ekranie monitorowania pokazano, jak dane są dystrybuowane między każdą partycję wraz z dwoma metrykami, niesymetrycznością i kurtozą. Niesymetryczność to miara asymetryczności danych i może mieć dodatnią, zero, ujemną lub niezdefiniowaną wartość. Ujemne niesymetryczność oznacza, że lewy ogon jest dłuższy niż po prawej stronie. Kurtosis jest miarą tego, czy dane są ciężkie, czy lekkie. Wysokie wartości kurtozy nie są pożądane. Idealne zakresy niesymetryczności leżą między -3 i 3 i zakresy kurtozy są mniejsze niż 10. Łatwym sposobem interpretacji tych liczb jest przyjrzenie się wykresowi partycji i sprawdzanie, czy 1 słupek jest większy niż reszta.
Jeśli dane nie są równomiernie partycjonowane po przekształceniu, możesz użyć karty Optymalizowanie do ponownego partycjonowania. Przetasowanie danych zajmuje trochę czasu i może nie poprawić wydajności przepływu danych.
Napiwek
Jeśli ponownie podzielisz dane, ale masz przekształcenia podrzędne, które przetasowały dane, użyj partycjonowania skrótów w kolumnie używanej jako klucz sprzężenia.
Uwaga
Przekształcenia wewnątrz przepływu danych (z wyjątkiem przekształcenia ujścia) nie modyfikują partycjonowania plików i folderów danych magazynowanych. Partycjonowanie w każdej partycjonowaniu danych przekształcenia wewnątrz ramek danych tymczasowego bezserwerowego klastra Spark zarządzanego przez usługę ADF dla każdego wykonania przepływu danych.
Powiązana zawartość
- Omówienie wydajności przepływu danych
- Optymalizowanie źródeł
- Optymalizowanie ujść
- Używanie przepływów danych w potokach
Zobacz inne artykuły Przepływ danych związane z wydajnością: