Tworzenie potoków kopiowania danych na dużą skalę za pomocą podejścia opartego na metadanych w narzędziu do kopiowania danych
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Jeśli chcesz skopiować ogromne ilości obiektów (na przykład tysięcy tabel) lub załadować dane z wielu różnych źródeł, odpowiednim podejściem jest wprowadzenie listy nazw obiektów z wymaganymi zachowaniami kopiowania w tabeli kontrolnej, a następnie użycie sparametryzowanych potoków w celu odczytania tego samego z tabeli kontrolnej i zastosowania ich odpowiednio do zadań. Dzięki temu można zachować (na przykład dodać/usunąć) listę obiektów do łatwego skopiowania, aktualizując nazwy obiektów w tabeli kontrolnej zamiast ponownie wdrażać potoki. Co więcej, będziesz mieć jedno miejsce, aby łatwo sprawdzić, które obiekty kopiowane przez potoki/wyzwalacze ze zdefiniowanymi zachowaniami kopiowania.
Narzędzie do kopiowania danych w usłudze ADF ułatwia tworzenie takich potoków kopiowania danych opartych na metadanych. Po wykonaniu intuicyjnego przepływu z poziomu środowiska opartego na kreatorze narzędzie może generować sparametryzowane potoki i skrypty SQL, aby odpowiednio tworzyć tabele kontroli zewnętrznej. Po uruchomieniu wygenerowanych skryptów w celu utworzenia tabeli sterowania w bazie danych SQL potoki będą odczytywać metadane z tabeli kontrolek i automatycznie stosować je w zadaniach kopiowania.
Tworzenie zadań kopiowania opartych na metadanych na podstawie narzędzia do kopiowania danych
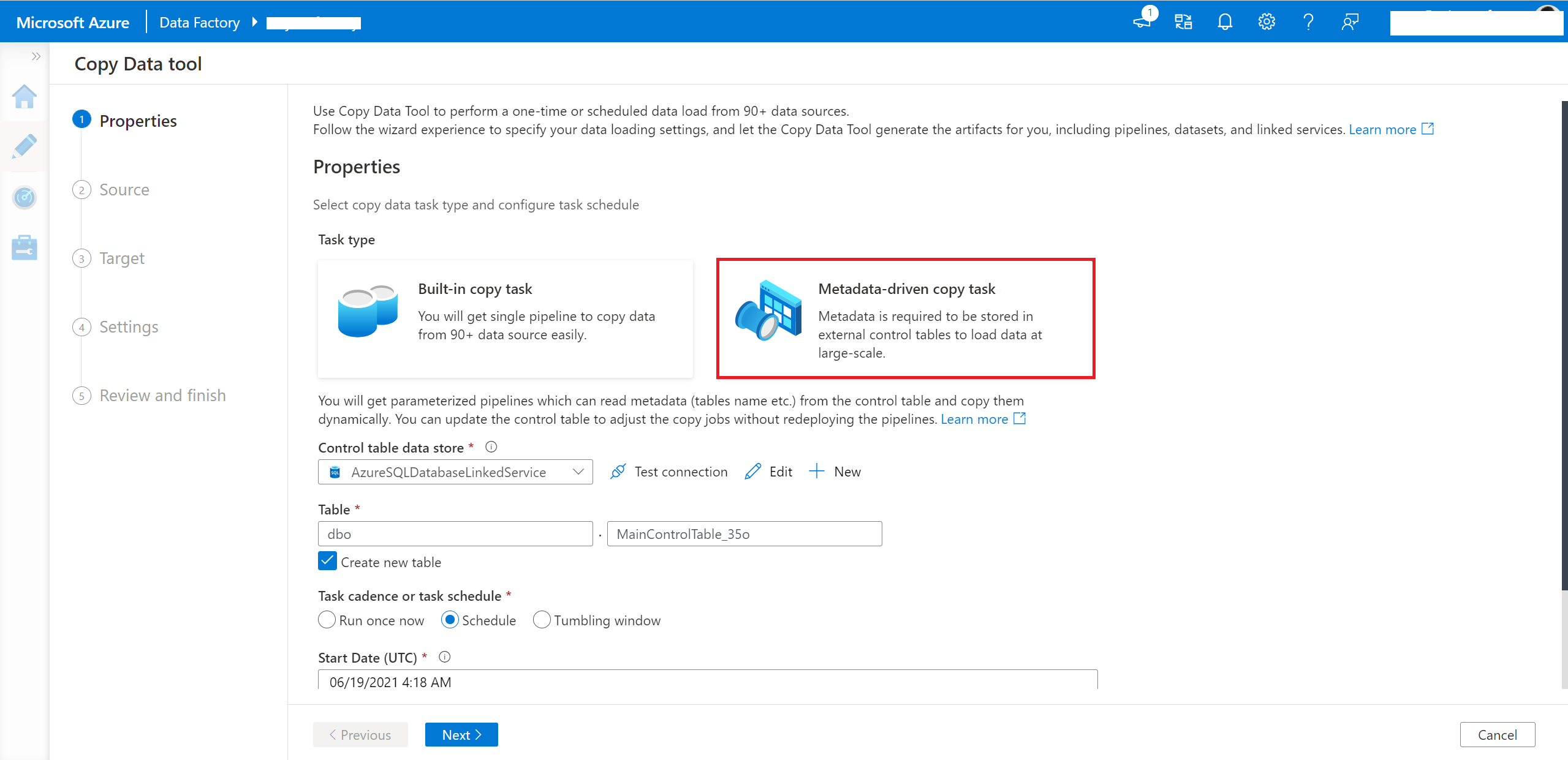
Wybierz zadanie kopiowania oparte na metadanych w narzędziu do kopiowania danych.
Musisz wprowadzić połączenie i nazwę tabeli sterowania, aby wygenerowany potok odczytał metadane z tej tabeli.
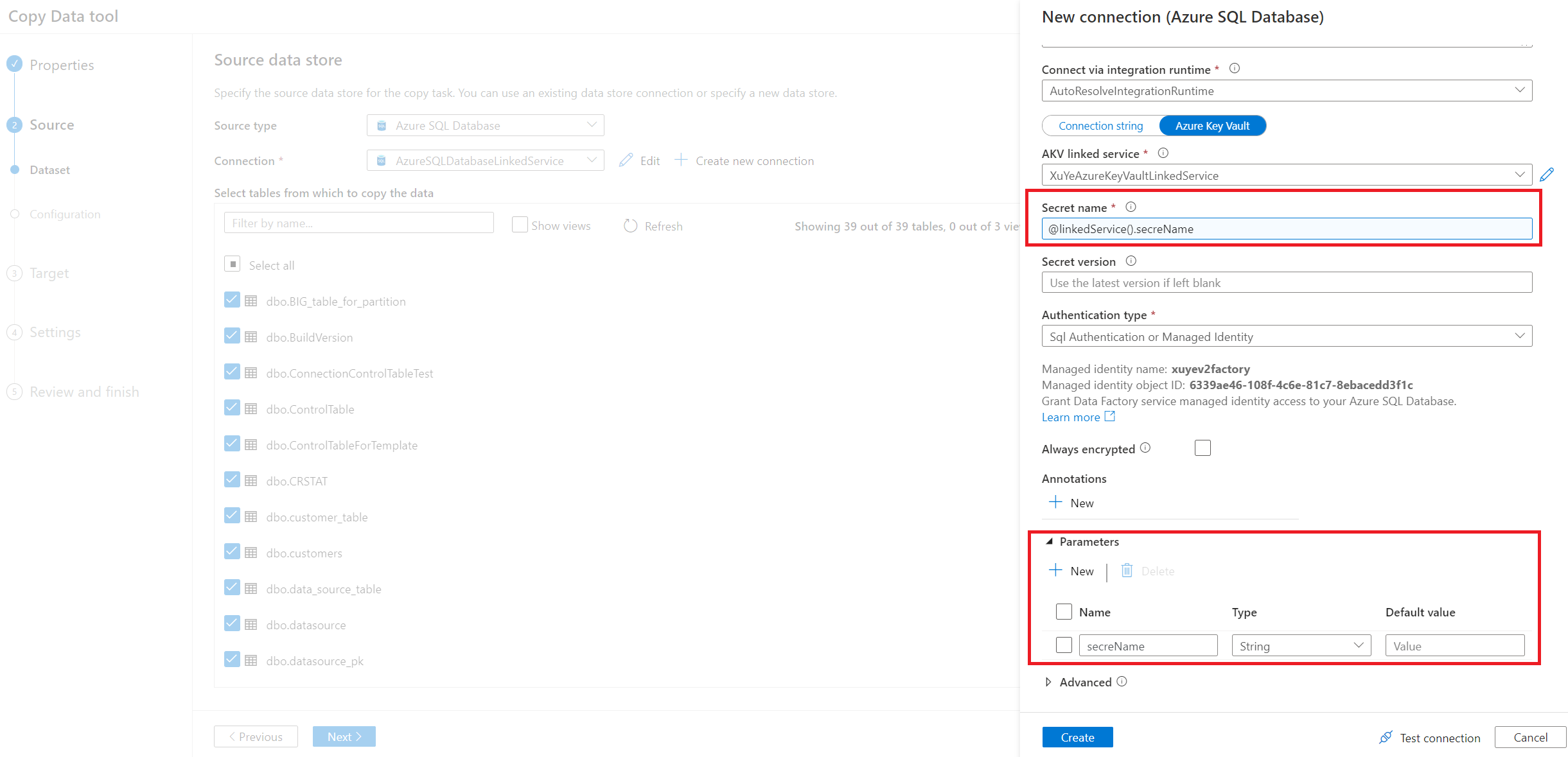
Wprowadź połączenie źródłowej bazy danych. Można również użyć sparametryzowanej połączonej usługi .
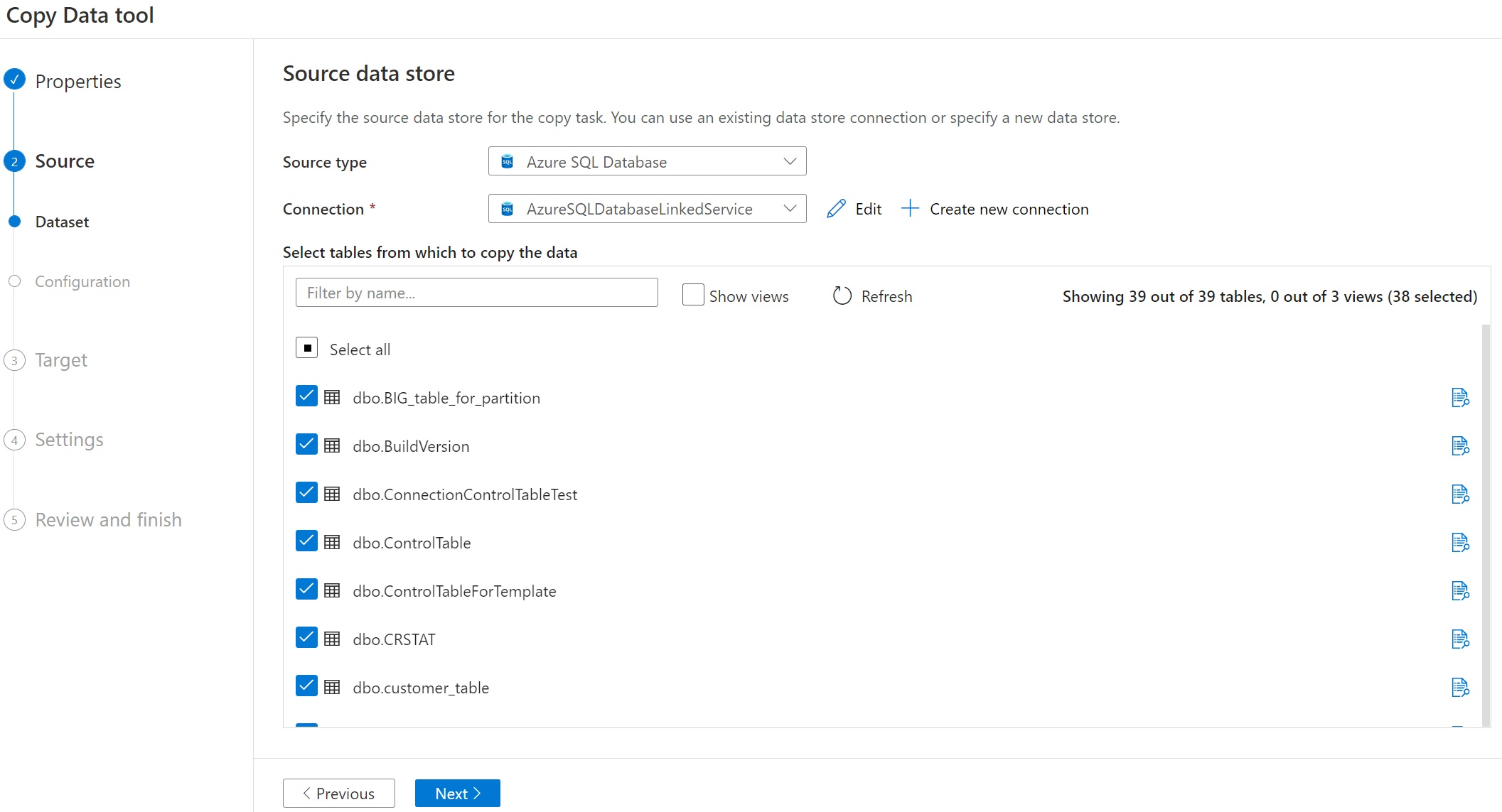
Wybierz nazwę tabeli, aby skopiować.
Uwaga
Jeśli wybierzesz magazyn danych tabelarycznych, będziesz mieć możliwość dalszego wybrania pełnego obciążenia lub obciążenia różnicowego na następnej stronie. Jeśli wybierzesz magazyn magazynu, możesz dodatkowo wybrać pełne ładowanie tylko na następnej stronie. Przyrostowe ładowanie nowych plików tylko z magazynu magazynu nie jest obecnie obsługiwane.
Wybierz zachowanie ładowania.
Napiwek
Jeśli chcesz wykonać pełną kopię we wszystkich tabelach, wybierz pozycję Pełne ładowanie wszystkich tabel. Jeśli chcesz wykonać kopiowanie przyrostowe, możesz wybrać opcję konfiguruj dla każdej tabeli osobno, a następnie wybrać opcję Ładowanie różnicowe, a także nazwę i wartość kolumny limitu, aby rozpocząć dla każdej tabeli.
Wybierz pozycję Docelowy magazyn danych.
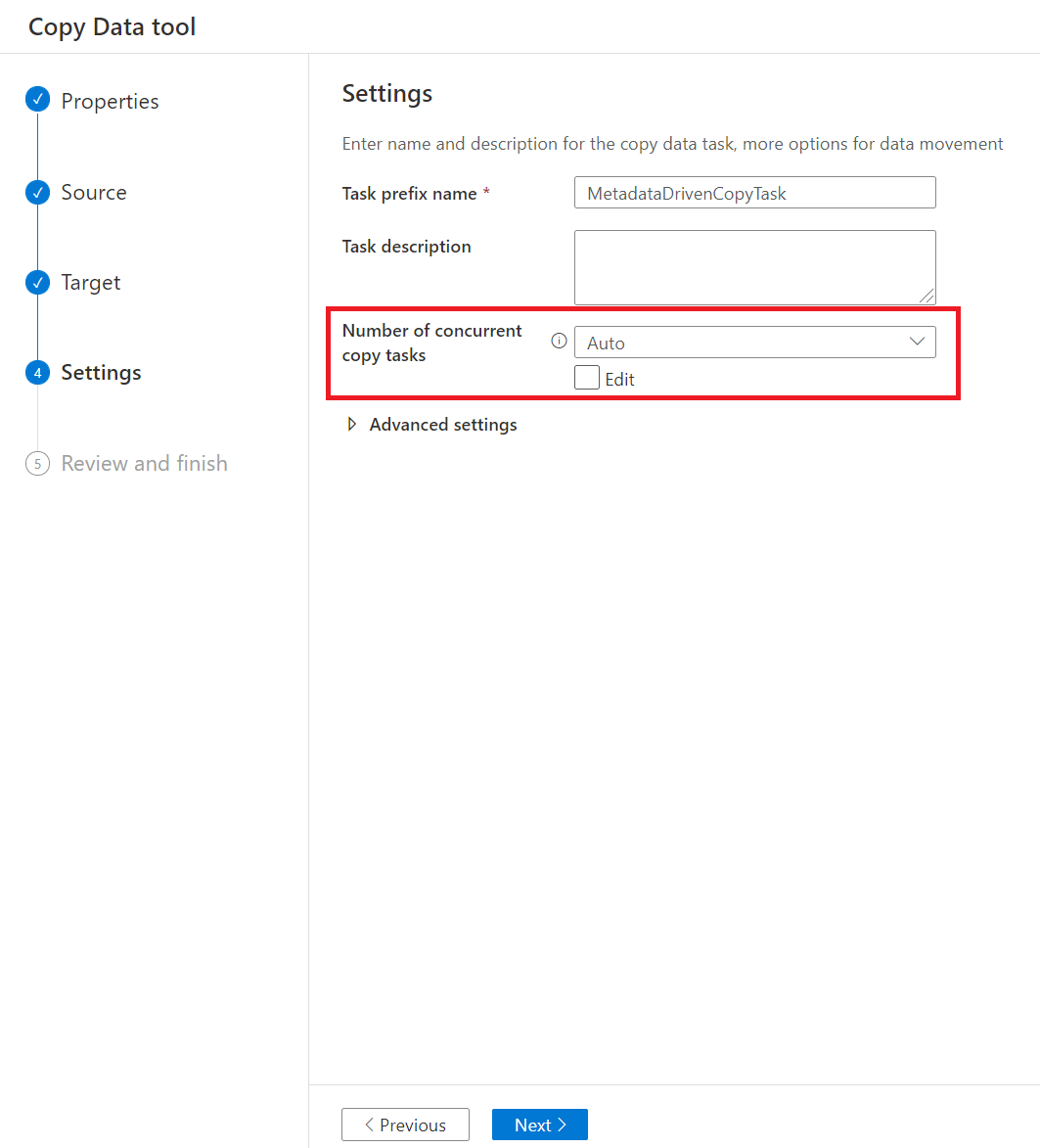
Na stronie Ustawienia możesz wybrać maksymalną liczbę działań kopiowania w celu jednoczesnego kopiowania danych z magazynu źródłowego za pośrednictwem liczby współbieżnych zadań kopiowania. Wartość domyślna to 20.
Po wdrożeniu potoku można skopiować lub pobrać skrypty SQL z interfejsu użytkownika na potrzeby tworzenia tabeli sterowania i procedury przechowywania.
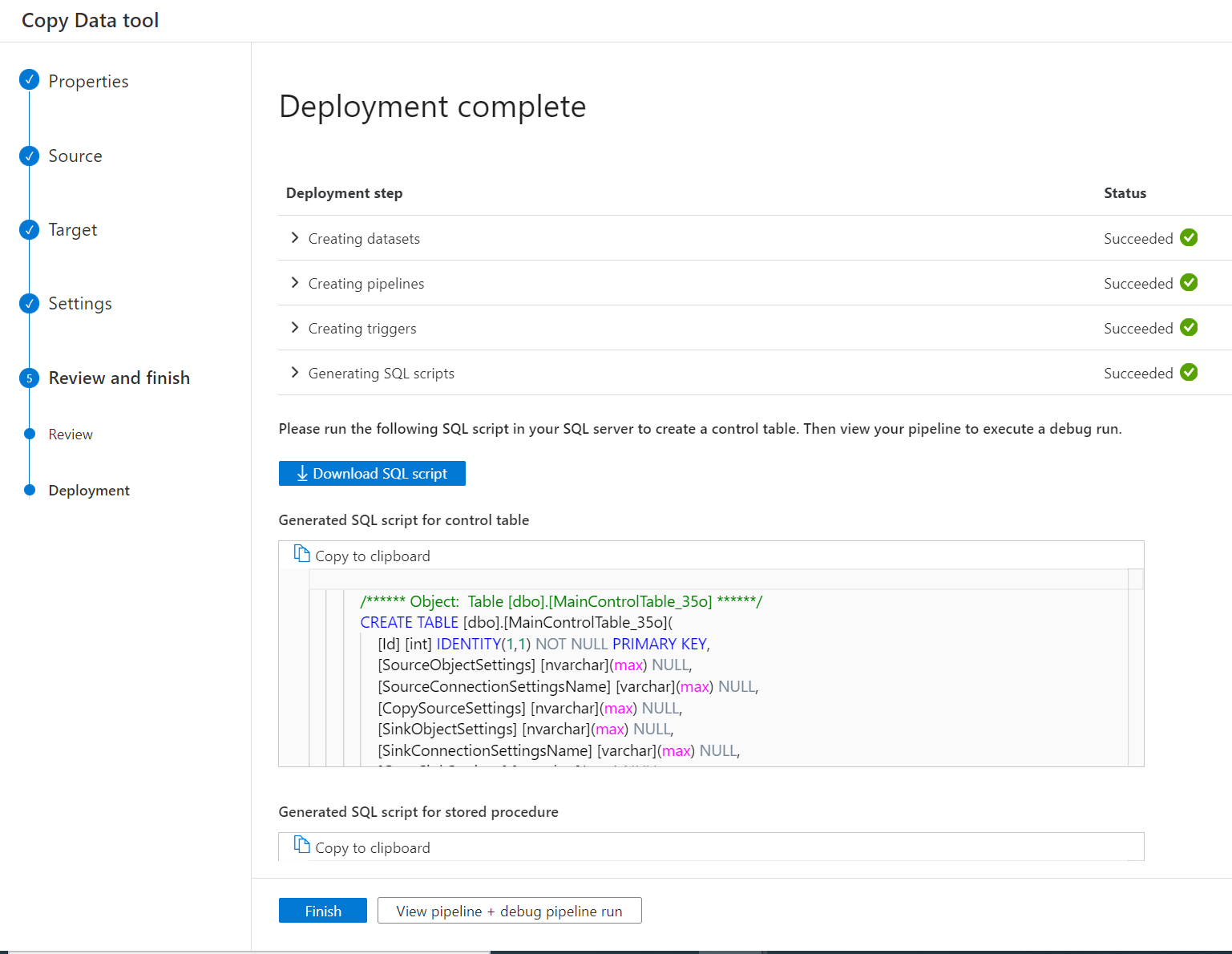
Zostaną wyświetlone dwa skrypty SQL.
- Pierwszy skrypt SQL służy do tworzenia dwóch tabel kontrolek. Główna tabela sterowania przechowuje zachowanie listy tabel, ścieżki pliku lub kopiowania. Tabela kontroli połączenia przechowuje wartość połączenia magazynu danych, jeśli użyto sparametryzowanej połączonej usługi.
- Drugi skrypt SQL służy do tworzenia procedury magazynu. Służy do aktualizowania wartości limitu w głównej tabeli sterowania, gdy zadania kopiowania przyrostowego są wykonywane za każdym razem.
Otwórz program SSMS , aby nawiązać połączenie z serwerem tabel sterowania, i uruchom dwa skrypty SQL, aby utworzyć tabele kontrolek i procedurę przechowywania.
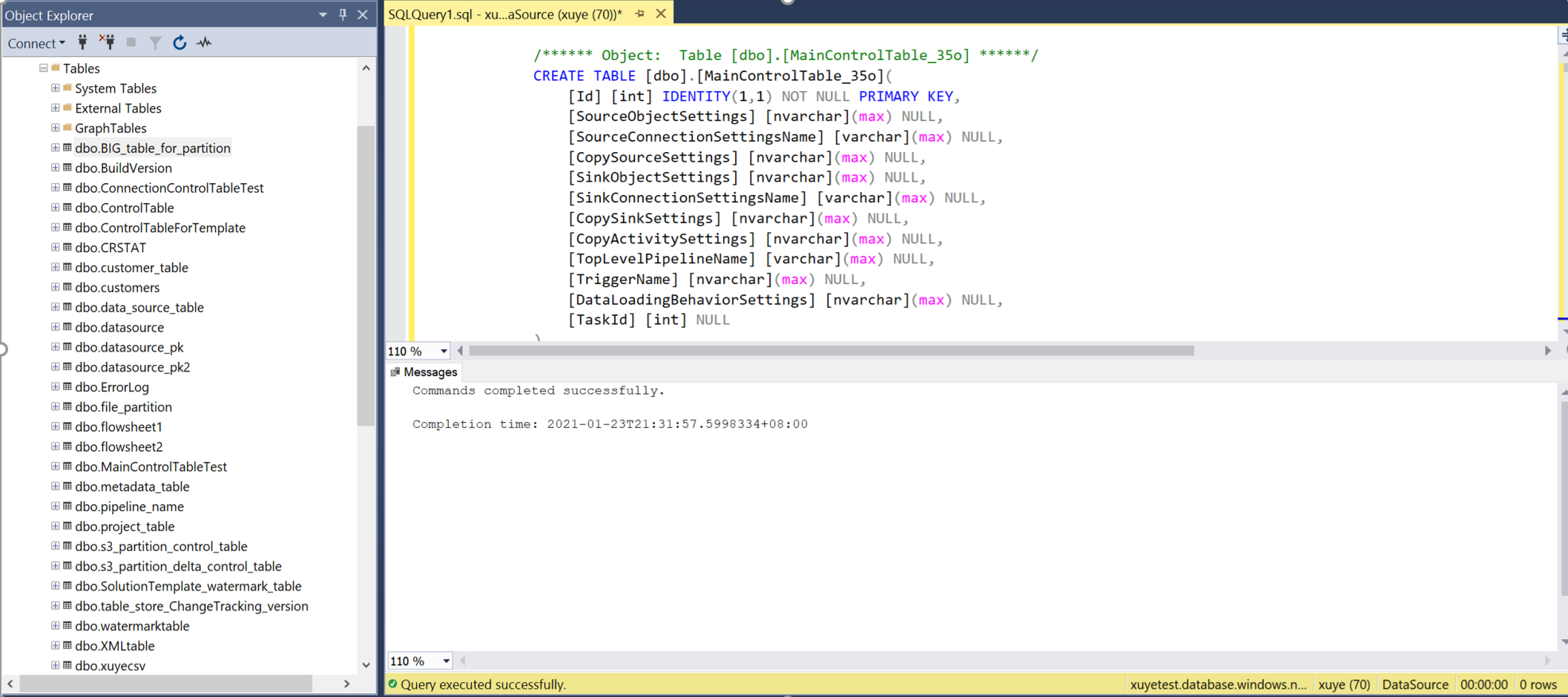
Wykonaj zapytanie względem głównej tabeli kontrolek i tabeli sterowania połączeniami, aby przejrzeć metadane w niej.
Tabela kontrolki głównej
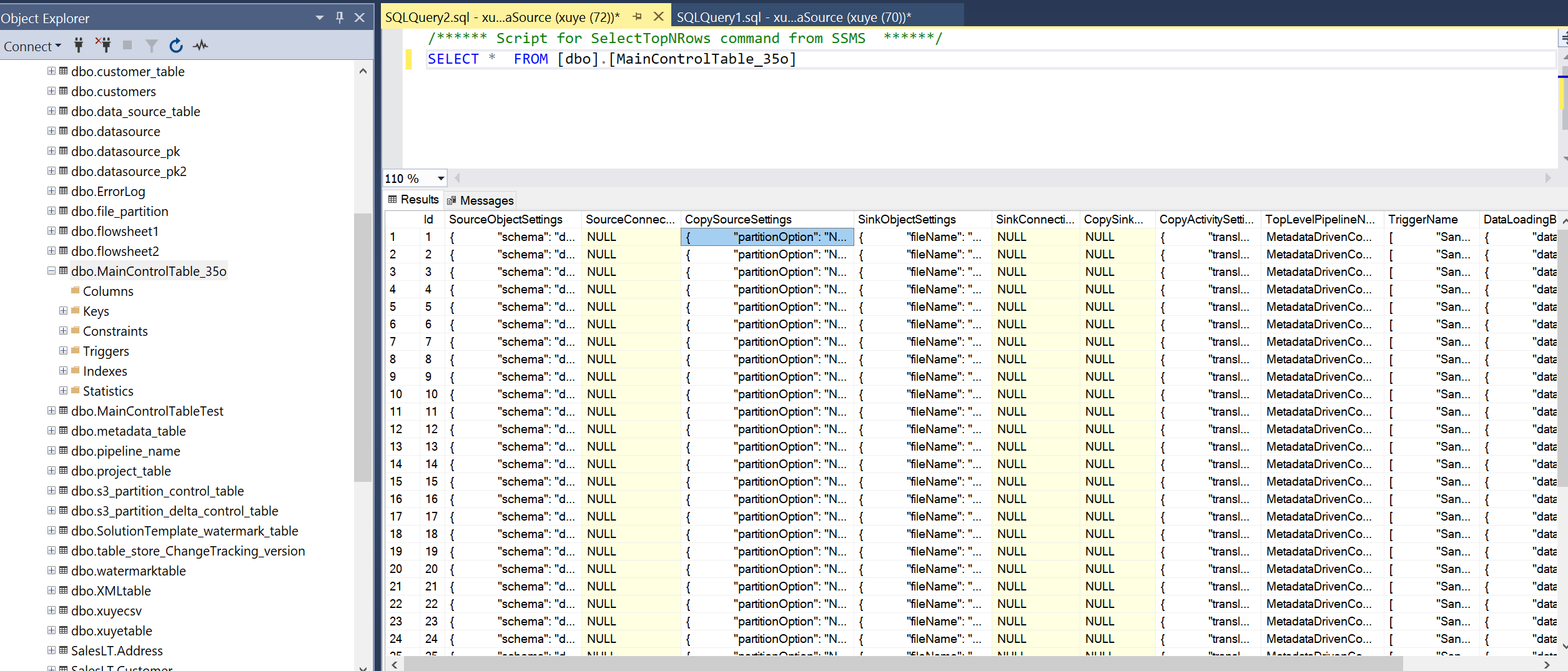
Tabela kontroli połączenia

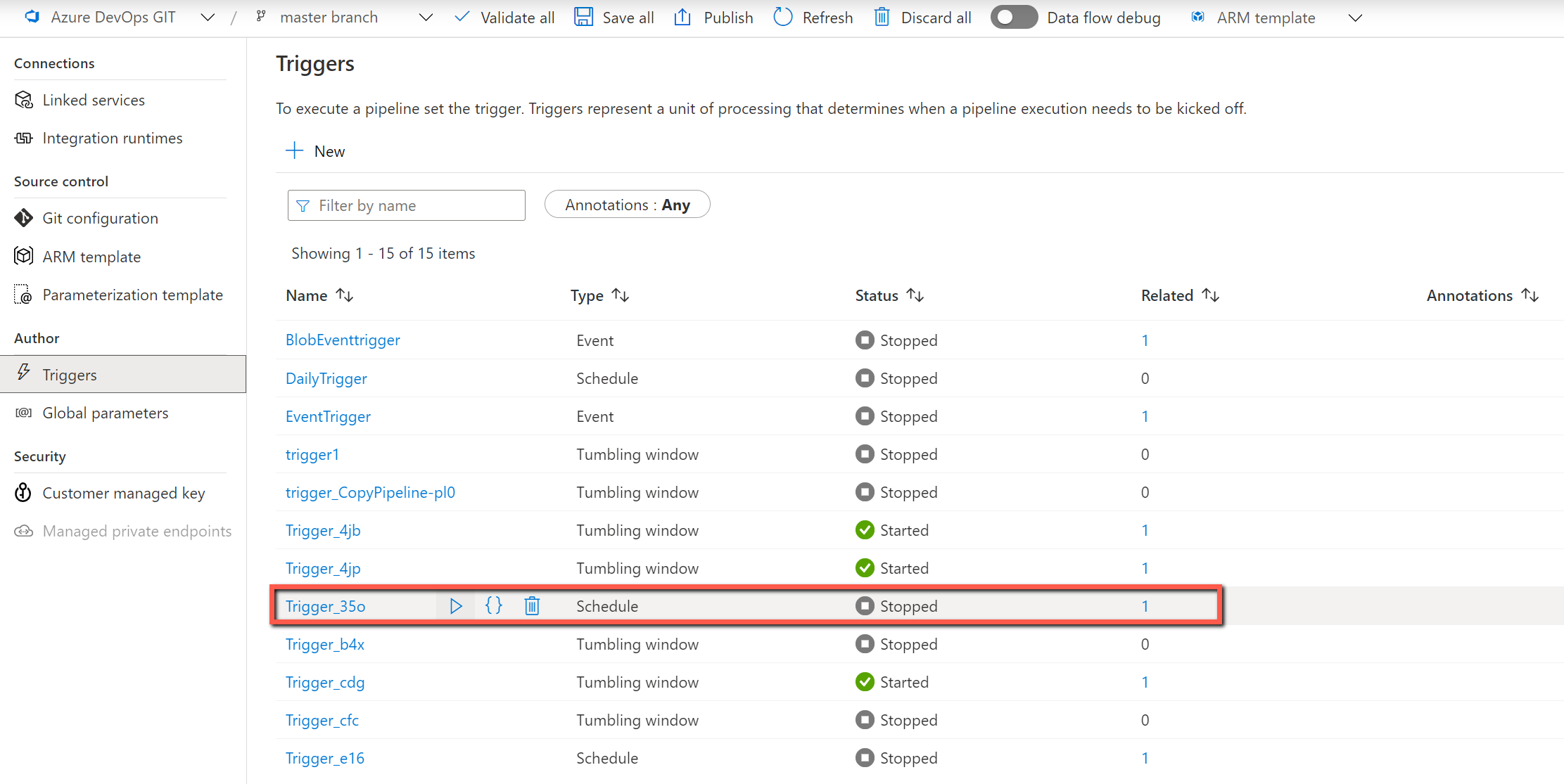
Wróć do portalu usługi ADF, aby wyświetlić i debugować potoki. Zostanie wyświetlony folder utworzony przez nadanie nazwy "MetadataDrivenCopyTask_#########". Kliknij nazwę potoku za pomocą polecenia "MetadataDrivenCopyTask###_TopLevel", a następnie kliknij pozycję Uruchom debugowanie.
Wymagane jest wprowadzenie następujących parametrów:
Nazwa parametrów opis MaxNumberOfConcurrentTasks Przed uruchomieniem potoku zawsze można zmienić maksymalną liczbę współbieżnych działań kopiowania. Wartość domyślna będzie wartością wejściową w narzędziu do kopiowania danych. MainControlTableName Zawsze można zmienić nazwę głównej tabeli sterowania, aby potok pobierał metadane z tej tabeli przed uruchomieniem. ConnectionControlTableName Zawsze można zmienić nazwę tabeli sterowania połączenia (opcjonalnie), aby potok pobierał metadane związane z połączeniem magazynu danych przed uruchomieniem. MaxNumberOfObjectsReturnedFromLookupActivity Aby uniknąć osiągnięcia limitu działania wyszukiwania danych wyjściowych, istnieje sposób definiowania maksymalnej liczby obiektów zwracanych przez działanie wyszukiwania. W większości przypadków wartość domyślna nie jest wymagana do zmiany. oknoStart Podczas wprowadzania wartości dynamicznej (na przykład rrrr/mm/dd) jako ścieżki folderu parametr jest używany do przekazywania bieżącego czasu wyzwalacza do potoku w celu wypełnienia ścieżki folderu dynamicznego. Gdy potok jest wyzwalany przez wyzwalacz harmonogramu lub wyzwalacz okien stałoczasowych, użytkownicy nie muszą wprowadzać wartości tego parametru. Przykładowa wartość: 2021-01-25T01:49:28Z Włącz wyzwalacz, aby operacjonalizować potoki.
Aktualizowanie tabeli kontrolek za pomocą narzędzia do kopiowania danych
Zawsze można bezpośrednio zaktualizować tabelę sterowania, dodając lub usuwając obiekt do skopiowania lub zmieniając zachowanie kopiowania dla każdej tabeli. Tworzymy również środowisko interfejsu użytkownika w narzędziu do kopiowania danych, aby ułatwić edytowanie tabeli sterowania.
Kliknij prawym przyciskiem myszy potok najwyższego poziomu: MetadataDrivenCopyTask_xxx_TopLevel, a następnie wybierz polecenie Edytuj tabelę sterowania.
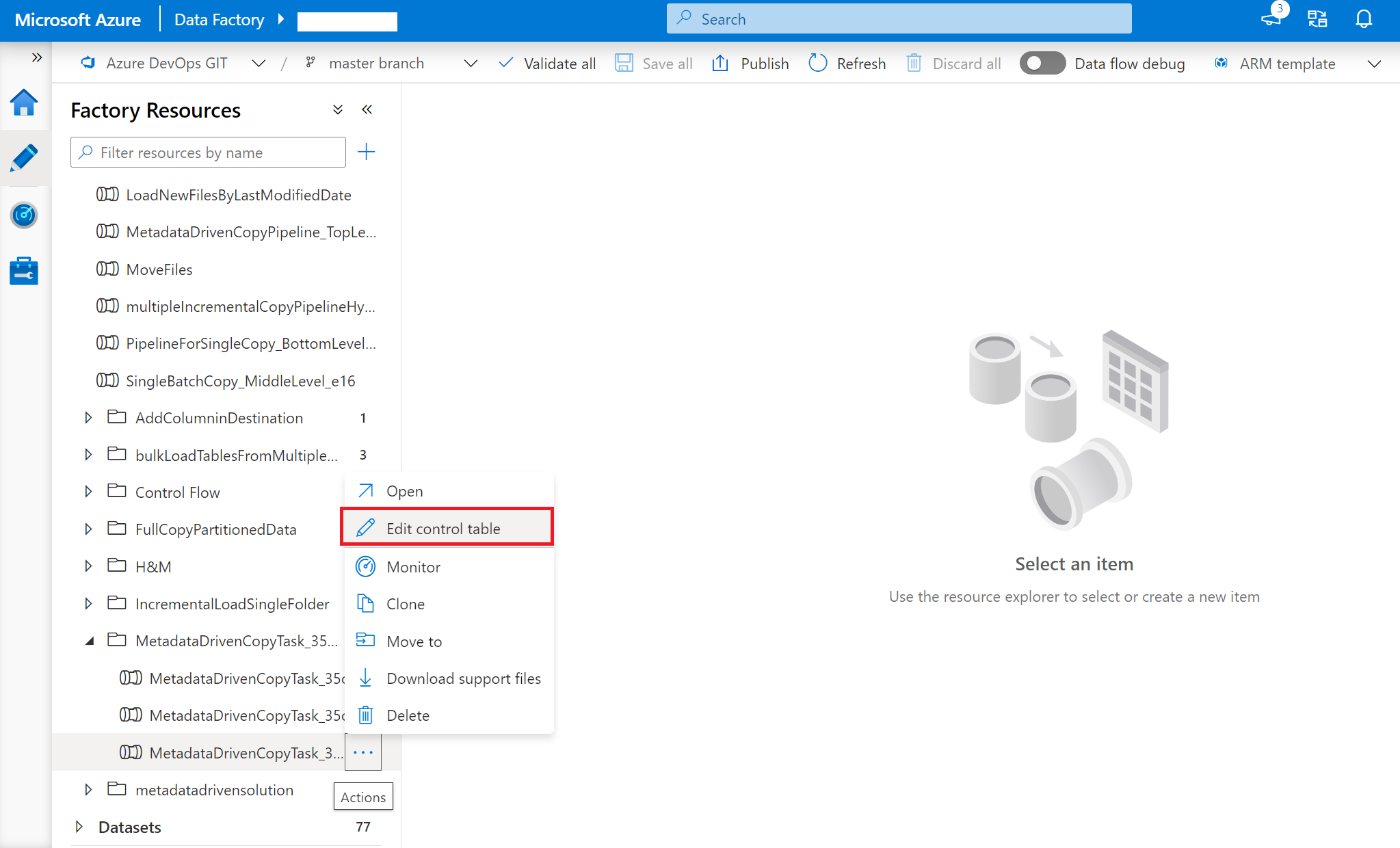
Wybierz wiersze z tabeli sterującej do edycji.
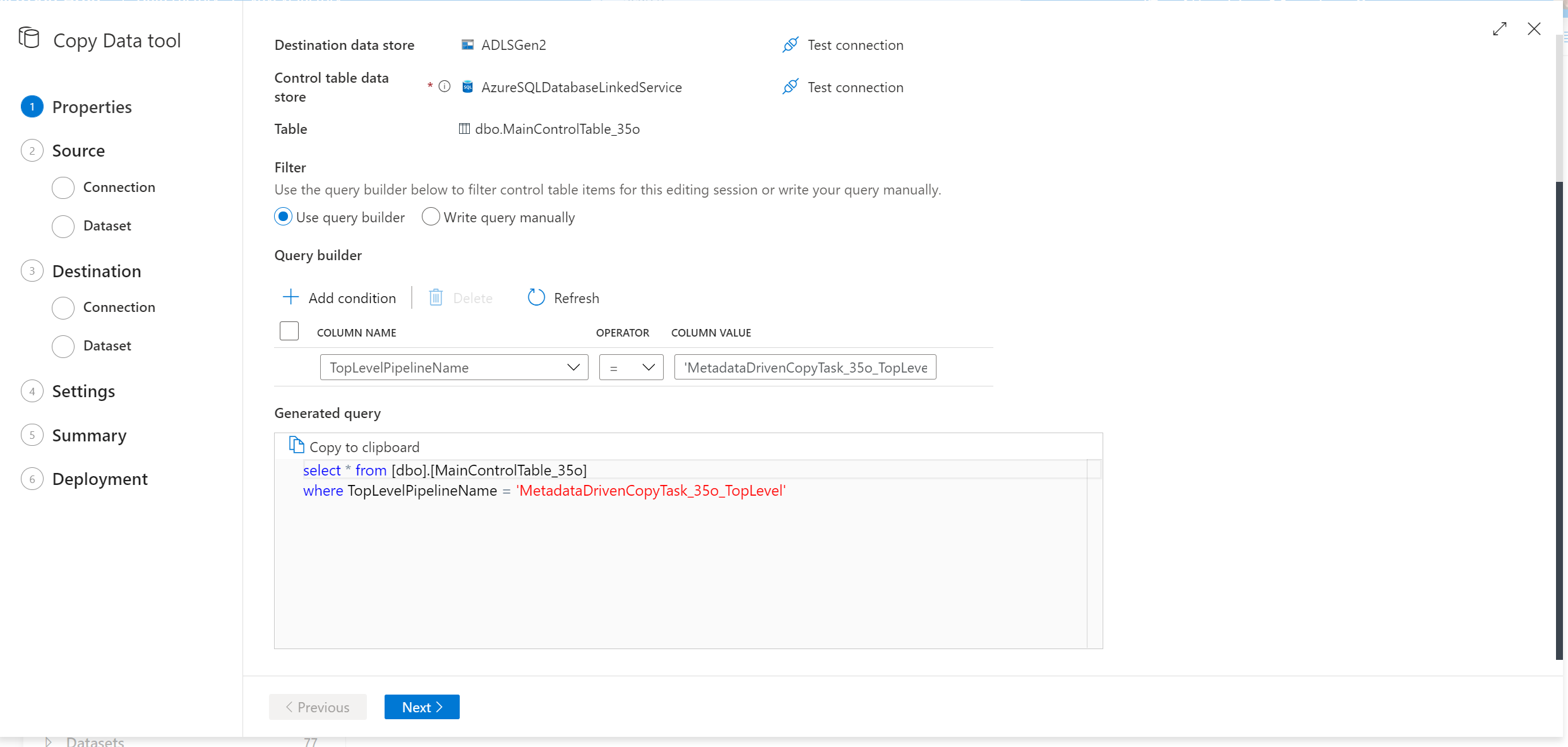
Przejdź do przepływności narzędzia do kopiowania danych i zostanie wyświetlony nowy skrypt SQL. Uruchom ponownie skrypt SQL, aby zaktualizować tabelę kontrolek.
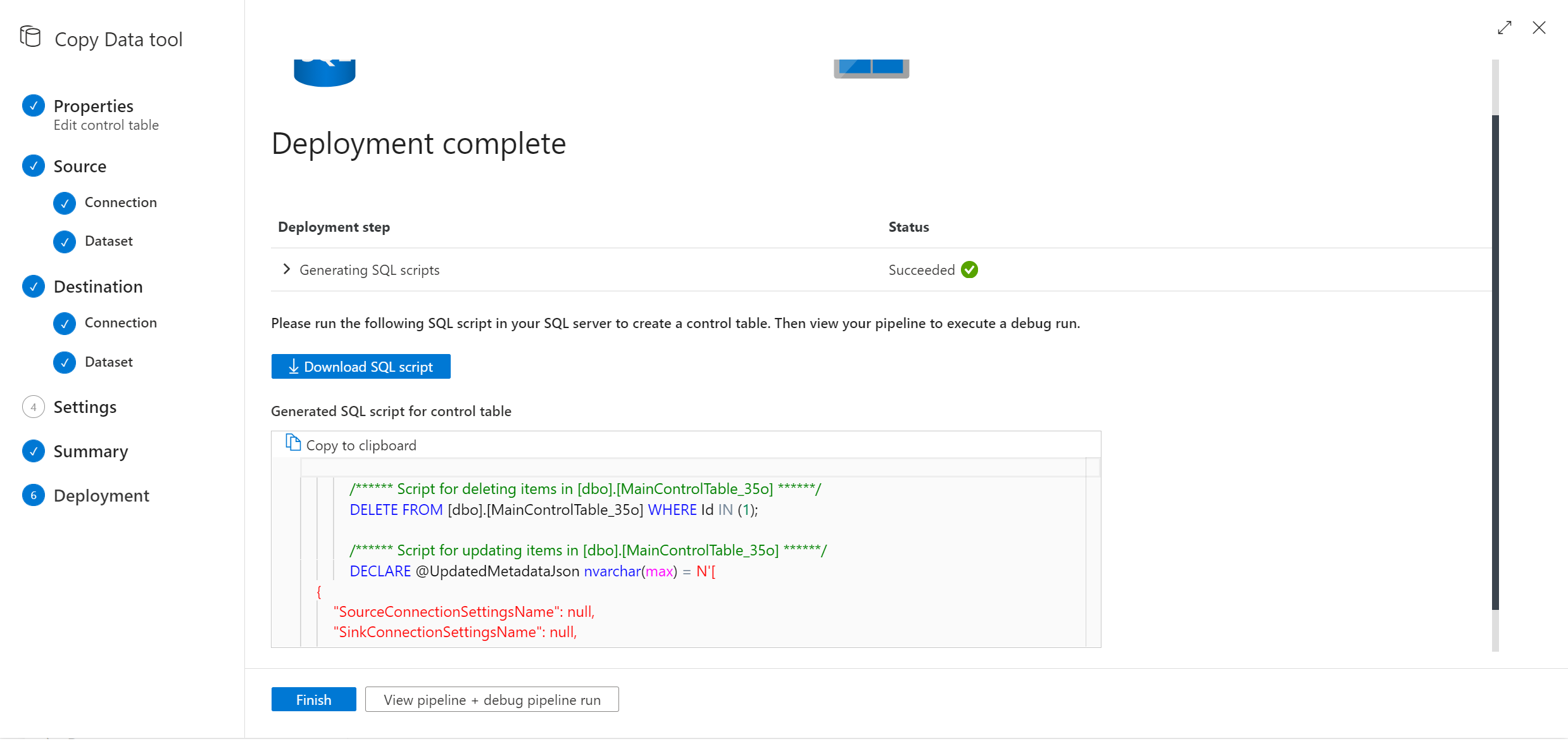
Uwaga
Potok nie zostanie wdrożony ponownie. Nowy utworzony skrypt SQL ułatwia aktualizowanie tylko tabeli kontrolnej.
Tabele kontrolek
Tabela kontrolki głównej
Każdy wiersz w tabeli kontrolnej zawiera metadane dla jednego obiektu (na przykład jednej tabeli) do skopiowania.
| Nazwa kolumny | Opis |
|---|---|
| ID | Unikatowy identyfikator obiektu do skopiowania. |
| SourceObjectSettings | Metadane źródłowego zestawu danych. Może to być nazwa schematu, nazwa tabeli itp. Oto przykład. |
| SourceConnectionSettingsName | Nazwa ustawienia połączenia źródłowego w tabeli kontroli połączenia. Jest to pozycja opcjonalna. |
| CopySourceSettings | Metadane właściwości źródłowej w działaniu kopiowania. Może to być zapytanie, partycje itp. Oto przykład. |
| SinkObjectSettings | Metadane docelowego zestawu danych. Może to być nazwa pliku, ścieżka folderu, nazwa tabeli itp. Oto przykład. Jeśli określono ścieżkę folderu dynamicznego, wartość zmiennej nie zostanie zapisana tutaj w tabeli sterującej. |
| SinkConnectionSettingsName | Nazwa ustawienia połączenia docelowego w tabeli kontroli połączenia. Jest to pozycja opcjonalna. |
| CopySinkSettings | Metadane właściwości ujścia w działaniu kopiowania. Może to być preCopyScript, tableOption itp. Oto przykład. |
| CopyActivitySettings | Metadane właściwości translatora w działaniu kopiowania. Służy do definiowania mapowania kolumn. |
| TopLevelPipelineName | Górna nazwa potoku, która może skopiować ten obiekt. |
| Nazwa wyzwalacza | Nazwa wyzwalacza, która może wyzwolić potok w celu skopiowania tego obiektu. W przypadku uruchomienia debugowania nazwa to Piaskownica. W przypadku ręcznego wykonywania nazwa to Ręczne. Jeśli zaplanowano przebieg, nazwa jest skojarzona nazwa wyzwalacza. Może to być wiele nazw wejściowych. |
| DataLoadingBehaviorSettings | Pełne obciążenie a obciążenie różnicowe. |
| Identyfikator zadania | Kolejność obiektów do skopiowania po identyfikatorze TaskId w tabeli kontrolnej (ORDER BY [TaskId] DESC). Jeśli masz ogromne ilości obiektów do skopiowania, ale tylko ograniczona liczba współbieżnych kopiowanych dozwolonych, możesz zmienić identyfikator TaskId dla każdego obiektu, aby zdecydować, które obiekty można skopiować wcześniej. Wartość domyślna to 0. |
| CopyEnabled | Określ, czy element jest włączony w procesie pozyskiwania danych. Dozwolone wartości: 1 (włączone), 0 (wyłączone). Wartość domyślna to 1. |
Tabela kontroli połączenia
Każdy wiersz w tabeli kontrolnej zawiera jedno ustawienie połączenia dla magazynu danych.
| Nazwa kolumny | opis |
|---|---|
| Nazwa/nazwisko | Nazwa sparametryzowanego połączenia w głównej tabeli sterowania. |
| ConnectionSettings | Ustawienia połączenia. Może to być nazwa bazy danych, nazwa serwera itd. |
Pipelines
Zobaczysz, że trzy poziomy potoków są generowane przez narzędzie do kopiowania danych.
MetadataDrivenCopyTask_xxx_TopLevel
Ten potok obliczy łączną liczbę obiektów (tabel itp.), które mają zostać skopiowane w tym przebiegu, wymyśli liczbę sekwencyjnych partii na podstawie maksymalnej dozwolonej liczby współbieżnych zadań kopiowania, a następnie wykonaj inny potok, aby skopiować różne partie sekwencyjnie.
Parametry
| Nazwa parametrów | opis |
|---|---|
| MaxNumberOfConcurrentTasks | Przed uruchomieniem potoku zawsze można zmienić maksymalną liczbę współbieżnych działań kopiowania. Wartość domyślna będzie wartością wejściową w narzędziu do kopiowania danych. |
| MainControlTableName | Nazwa tabeli głównej tabeli sterującej. Potok pobierze metadane z tej tabeli przed uruchomieniem |
| ConnectionControlTableName | Nazwa tabeli tabeli kontroli połączenia (opcjonalnie). Potok pobierze metadane związane z połączeniem magazynu danych przed uruchomieniem |
| MaxNumberOfObjectsReturnedFromLookupActivity | Aby uniknąć osiągnięcia limitu działania wyszukiwania danych wyjściowych, istnieje sposób definiowania maksymalnej liczby obiektów zwracanych przez działanie wyszukiwania. W większości przypadków wartość domyślna nie jest wymagana do zmiany. |
| oknoStart | Podczas wprowadzania wartości dynamicznej (na przykład rrrr/mm/dd) jako ścieżki folderu parametr jest używany do przekazywania bieżącego czasu wyzwalacza do potoku w celu wypełnienia ścieżki folderu dynamicznego. Gdy potok jest wyzwalany przez wyzwalacz harmonogramu lub wyzwalacz okien stałoczasowych, użytkownicy nie muszą wprowadzać wartości tego parametru. Przykładowa wartość: 2021-01-25T01:49:28Z |
Działania
| Nazwa działania | Typ działania | opis |
|---|---|---|
| GetSumOfObjectsToCopy | Lookup | Oblicz całkowitą liczbę obiektów (tabel itp.) wymaganych do skopiowania w tym przebiegu. |
| CopyBatchesOfObjectsSequentially | ForEach | Utwórz liczbę partii sekwencyjnych na podstawie maksymalnej dozwolonej liczby współbieżnych zadań kopiowania, a następnie wykonaj kolejny potok w celu sekwencyjnego kopiowania różnych partii. |
| CopyObjectsInOneBtach | Wykonywanie potoku | Wykonaj inny potok, aby skopiować jedną partię obiektów. Obiekty należące do tej partii zostaną skopiowane równolegle. |
MetadataDrivenCopyTask_xxx_ MiddleLevel
Ten potok skopiuje jedną partię obiektów. Obiekty należące do tej partii zostaną skopiowane równolegle.
Parametry
| Nazwa parametrów | opis |
|---|---|
| MaxNumberOfObjectsReturnedFromLookupActivity | Aby uniknąć osiągnięcia limitu działania wyszukiwania danych wyjściowych, istnieje sposób definiowania maksymalnej liczby obiektów zwracanych przez działanie wyszukiwania. W większości przypadków wartość domyślna nie jest wymagana do zmiany. |
| TopLevelPipelineName | Nazwa potoku warstwy górnej. |
| Nazwa wyzwalacza | Nazwa wyzwalacza. |
| CurrentSequentialNumberOfBatch | Identyfikator partii sekwencyjnej. |
| SumOfObjectsToCopy | Całkowita liczba obiektów do skopiowania. |
| SumOfObjectsToCopyForCurrentBatch | Liczba obiektów do skopiowania w bieżącej partii. |
| MainControlTableName | Nazwa głównej tabeli kontrolek. |
| ConnectionControlTableName | Nazwa tabeli kontroli połączenia. |
Działania
| Nazwa działania | Typ działania | opis |
|---|---|---|
| DivideOneBatchIntoMultipleGroups | ForEach | Podziel obiekty z jednej partii na wiele grup równoległych, aby uniknąć osiągnięcia limitu danych wyjściowych działania wyszukiwania. |
| GetObjectsPerGroupToCopy | Lookup | Pobierz obiekty (tabele itp.) z tabeli sterującej wymaganej do skopiowania w tej grupie. Kolejność obiektów do skopiowania po identyfikatorze TaskId w tabeli kontrolnej (ORDER BY [TaskId] DESC). |
| CopyObjectsInOneGroup | Wykonywanie potoku | Wykonaj inny potok, aby skopiować obiekty z jednej grupy. Obiekty należące do tej grupy zostaną skopiowane równolegle. |
MetadataDrivenCopyTask_xxx_ BottomLevel
Ten potok będzie kopiować obiekty z jednej grupy. Obiekty należące do tej grupy zostaną skopiowane równolegle.
Parametry
| Nazwa parametrów | opis |
|---|---|
| ObjectsPerGroupToCopy | Liczba obiektów do skopiowania w bieżącej grupie. |
| ConnectionControlTableName | Nazwa tabeli kontroli połączenia. |
| oknoStart | Użyto go do przekazania bieżącego czasu wyzwalacza do potoku w celu wypełnienia ścieżki folderu dynamicznego, jeśli został skonfigurowany przez użytkownika. |
Działania
| Nazwa działania | Typ działania | opis |
|---|---|---|
| ListObjectsFromOneGroup | ForEach | Wyświetlanie listy obiektów z jednej grupy i iterowanie każdego z nich do działań podrzędnych. |
| RouteJobsBasedOnLoadingBehavior | Switch | Sprawdź zachowanie ładowania dla każdego obiektu. Jeśli jest to przypadek domyślny lub FullLoad, wykonaj pełne ładowanie. Jeśli jest to przypadek deltaLoad, wykonaj obciążenie przyrostowe za pośrednictwem kolumny limitu wodnego, aby zidentyfikować zmiany |
| FullLoadOneObject | Kopiuj | Wykonaj pełną migawkę tego obiektu i skopiuj go do miejsca docelowego. |
| DeltaLoadOneObject | Kopiuj | Skopiuj zmienione dane tylko z ostatniego czasu, porównując wartość w kolumnie limitu, aby zidentyfikować zmiany. |
| GetMaxWatermarkValue | Lookup | Wykonaj zapytanie względem obiektu źródłowego, aby uzyskać maksymalną wartość z kolumny limitu. |
| UpdateWatermarkColumnValue | StoreProcedure | Zanotuj nową wartość limitu, aby kontrolować tabelę, która ma być używana następnym razem. |
Znane ograniczenia
- Nazwa środowiska IR, typ bazy danych, typ formatu pliku nie może być sparametryzowany w usłudze ADF. Jeśli na przykład chcesz pozyskać dane zarówno z programu Oracle Server, jak i programu SQL Server, potrzebne będą dwa różne potoki sparametryzowane. Jednak pojedyncza tabela sterowania może być współdzielona przez dwa zestawy potoków.
- Plik OPENJSON jest używany w wygenerowanych skryptach SQL przez narzędzie do kopiowania danych. Jeśli używasz programu SQL Server do hostowania tabeli sterowania, musi to być program SQL Server 2016 (13.x) i nowsze, aby obsługiwać funkcję OPENJSON.
Powiązana zawartość
Wypróbuj następujące samouczki, które używają narzędzia do kopiowania danych:
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla