Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Azure Data Lake Storage Gen2 (ADLS Gen2) to zestaw funkcji przeznaczonych do analizy danych big data wbudowanych w usługę Azure Blob Storage. Można ją wykorzystać do połączenia interfejsem z danymi przy użyciu zarówno paradygmatów systemu plików, jak i magazynu obiektów.
W tym artykule opisano sposób używania działania kopiowania do kopiowania danych z usługi Azure Data Lake Storage Gen2 i używania Przepływ danych do przekształcania danych w usłudze Azure Data Lake Storage Gen2. Aby dowiedzieć się więcej, przeczytaj artykuł wprowadzający dotyczący usługi Azure Data Factory lub Azure Synapse Analytics.
Napiwek
W przypadku scenariusza migracji magazynu danych lub usługi Data Lake dowiedz się więcej w artykule Migrowanie danych z magazynu danych lub magazynu danych do platformy Azure.
Obsługiwane możliwości
Ten łącznik usługi Azure Data Lake Storage Gen2 jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR | Zarządzany prywatny punkt końcowy |
|---|---|---|
| działanie Kopiuj (źródło/ujście) | (1) (2) | ✓ |
| Przepływ danych mapowania (źródło/ujście) | (1) | ✓ |
| Działanie Lookup | (1) (2) | ✓ |
| Działanie GetMetadata | (1) (2) | ✓ |
| Działanie usuwania | (1) (2) | ✓ |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
W przypadku działanie Kopiuj za pomocą tego łącznika można wykonywać następujące czynności:
- Kopiowanie danych z/do usługi Azure Data Lake Storage Gen2 przy użyciu klucza konta, jednostki usługi lub tożsamości zarządzanych na potrzeby uwierzytelniania zasobów platformy Azure.
- Kopiowanie plików w stanie rzeczywistym lub analizowanie lub generowanie plików z obsługiwanymi formatami plików i koderami kompresji.
- Zachowaj metadane pliku podczas kopiowania.
- Zachowaj listy ACL podczas kopiowania z usługi Azure Data Lake Storage Gen1/Gen2.
Rozpocznij
Napiwek
Aby zapoznać się z instrukcjami dotyczącymi używania łącznika usługi Data Lake Storage Gen2, zobacz Ładowanie danych do usługi Azure Data Lake Storage Gen2.
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi Azure Data Lake Storage Gen2 przy użyciu interfejsu użytkownika
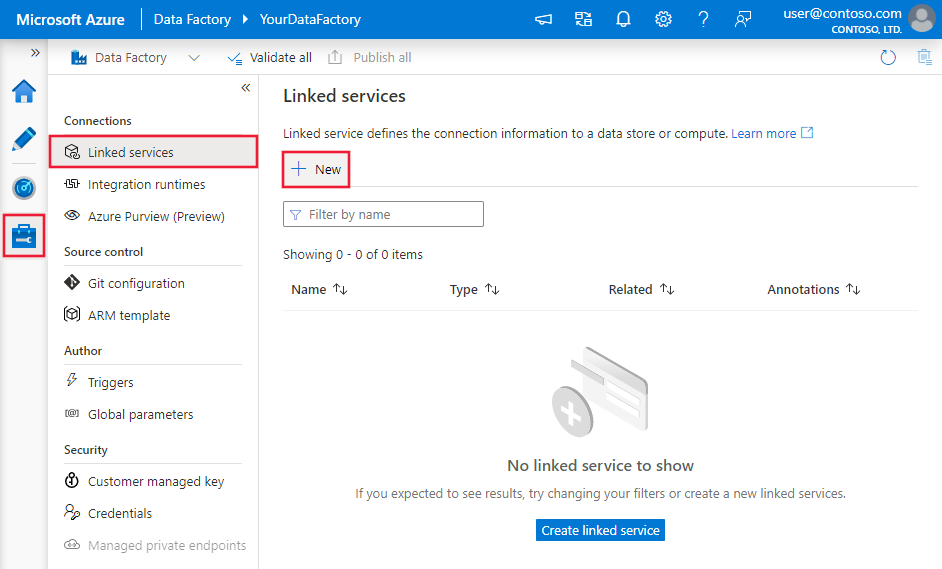
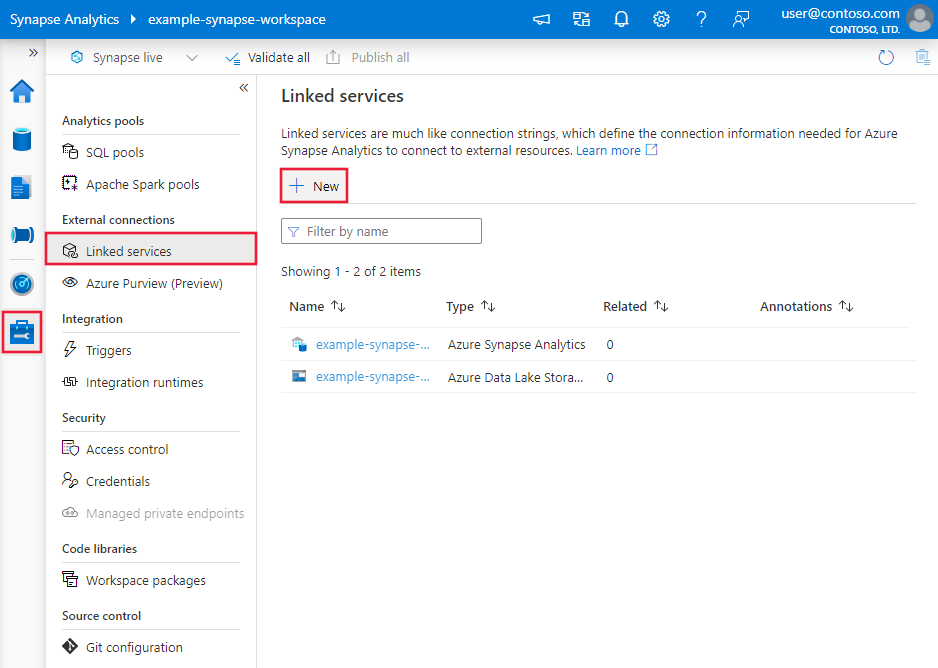
Wykonaj poniższe kroki, aby utworzyć połączoną usługę Azure Data Lake Storage Gen2 w interfejsie użytkownika witryny Azure Portal.
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj usługę Azure Data Lake Storage Gen2 i wybierz łącznik Usługi Azure Data Lake Storage Gen2.
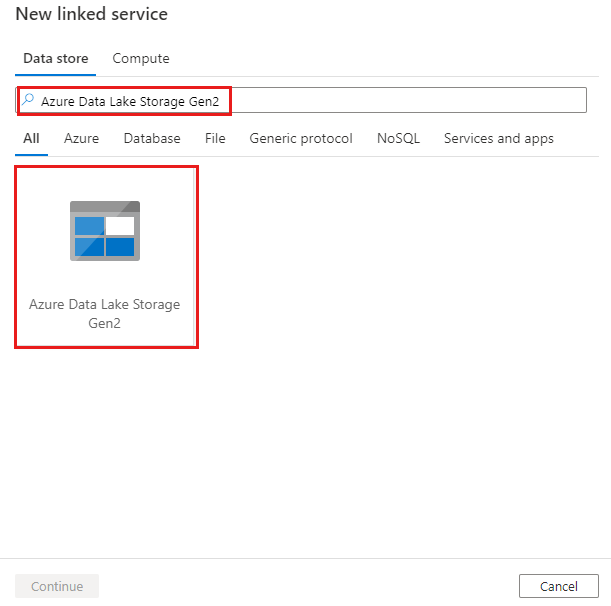
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
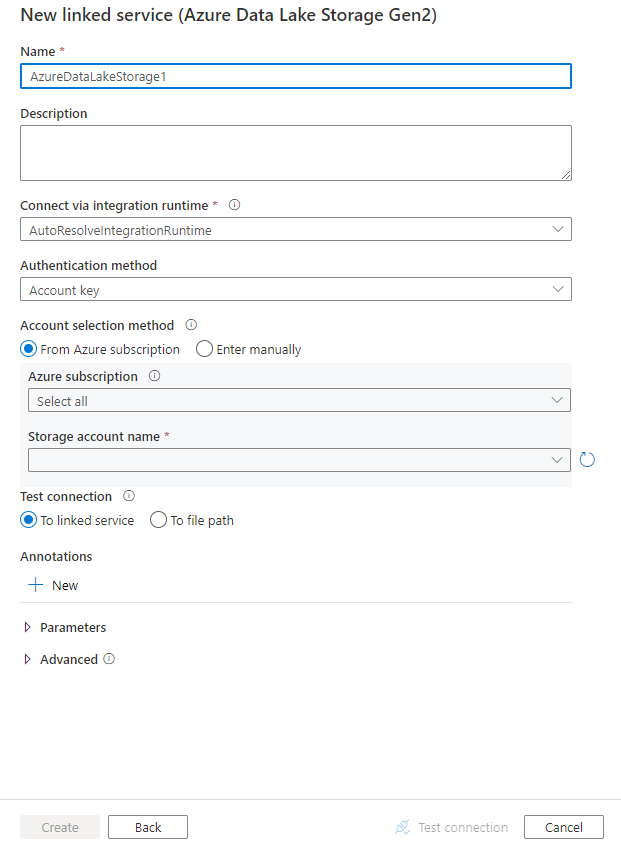
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają informacje o właściwościach używanych do definiowania jednostek potoków usługi Data Factory i Synapse specyficznych dla usługi Data Lake Storage Gen2.
Właściwości połączonej usługi
Łącznik usługi Azure Data Lake Storage Gen2 obsługuje następujące typy uwierzytelniania. Aby uzyskać szczegółowe informacje, zobacz odpowiednie sekcje:
- Uwierzytelnianie klucza konta
- Uwierzytelnianie sygnatury dostępu współdzielonego
- Uwierzytelnianie jednostki usługi
- Uwierzytelnianie tożsamości zarządzanej przypisanej przez system
- Uwierzytelnianie tożsamości zarządzanej przypisanej przez użytkownika
Uwaga
- Jeśli chcesz użyć publicznego środowiska Azure Integration Runtime do nawiązania połączenia z usługą Data Lake Storage Gen2, korzystając z opcji Zezwalaj na zaufane usługi firmy Microsoft na dostęp do tego konta magazynu włączonej w zaporze usługi Azure Storage, musisz użyć uwierzytelniania tożsamości zarządzanej. Aby uzyskać więcej informacji na temat ustawień zapór usługi Azure Storage, zobacz Konfigurowanie zapór i sieci wirtualnych usługi Azure Storage.
- Jeśli używasz instrukcji PolyBase lub COPY do ładowania danych do usługi Azure Synapse Analytics, jeśli źródło lub przemieszczanie usługi Data Lake Storage Gen2 jest skonfigurowane z punktem końcowym usługi Azure Virtual Network, musisz użyć uwierzytelniania tożsamości zarządzanej zgodnie z wymaganiami usługi Azure Synapse. Zobacz sekcję Uwierzytelnianie tożsamości zarządzanej, aby uzyskać więcej wymagań wstępnych dotyczących konfiguracji.
Uwierzytelnianie klucza konta
Aby użyć uwierzytelniania klucza konta magazynu, obsługiwane są następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na Wartość AzureBlobFS. | Tak |
| Adres URL | Punkt końcowy dla usługi Data Lake Storage Gen2 ze wzorcem https://<accountname>.dfs.core.windows.net. |
Tak |
| accountKey | Klucz konta dla usługi Data Lake Storage Gen2. Oznacz to pole jako element SecureString w celu bezpiecznego przechowywania go lub odwołuj się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. | Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime, jeśli magazyn danych znajduje się w sieci prywatnej. Jeśli ta właściwość nie zostanie określona, zostanie użyte domyślne środowisko Azure Integration Runtime. | Nie. |
Uwaga
Pomocniczy punkt końcowy systemu plików usługi ADLS nie jest obsługiwany podczas korzystania z uwierzytelniania klucza konta. Możesz użyć innych typów uwierzytelniania.
Przykład:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"accountkey": {
"type": "SecureString",
"value": "<accountkey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uwierzytelnianie sygnatury dostępu współdzielonego
Sygnatura dostępu współdzielonego zapewnia delegowany dostęp do zasobów na koncie magazynu. Sygnatura dostępu współdzielonego umożliwia przyznanie klientowi ograniczonych uprawnień do obiektów na koncie magazynu przez określony czas.
Nie musisz udostępniać kluczy dostępu do konta. Sygnatura dostępu współdzielonego to identyfikator URI, który zawiera w parametrach zapytania wszystkie informacje niezbędne do uwierzytelnionego dostępu do zasobu magazynu. Aby uzyskać dostęp do zasobów magazynu za pomocą sygnatury dostępu współdzielonego, klient musi przekazać tylko sygnaturę dostępu współdzielonego do odpowiedniego konstruktora lub metody.
Aby uzyskać więcej informacji na temat sygnatur dostępu współdzielonego, zobacz Sygnatury dostępu współdzielonego: Omówienie modelu sygnatury dostępu współdzielonego.
Uwaga
- Usługa obsługuje teraz zarówno sygnatury dostępu współdzielonego usługi, jak i sygnatury dostępu współdzielonego konta. Aby uzyskać więcej informacji na temat sygnatur dostępu współdzielonego, zobacz Udzielanie ograniczonego dostępu do zasobów usługi Azure Storage przy użyciu sygnatur dostępu współdzielonego.
- W późniejszych konfiguracjach zestawu danych ścieżka folderu jest ścieżką bezwzględną rozpoczynającą się od poziomu kontenera. Musisz skonfigurować jedną ścieżkę zgodną ze ścieżką w identyfikatorze URI sygnatury dostępu współdzielonego.
Następujące właściwości są obsługiwane w przypadku korzystania z uwierzytelniania za pomocą sygnatury dostępu współdzielonego:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość musi być ustawiona type na AzureBlobFS (sugerowana) |
Tak |
| sasUri | Określ identyfikator URI sygnatury dostępu współdzielonego do zasobów magazynu, takich jak obiekt blob lub kontener. Oznacz to pole jako SecureString , aby bezpiecznie je przechowywać. Możesz również umieścić token SAS w usłudze Azure Key Vault, aby użyć automatycznego obracania i usunąć część tokenu. Aby uzyskać więcej informacji, zobacz następujące przykłady i Przechowywanie poświadczeń w usłudze Azure Key Vault. |
Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime (jeśli magazyn danych znajduje się w sieci prywatnej). Jeśli ta właściwość nie zostanie określona, usługa używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Uwaga
Jeśli używasz połączonej AzureStorage usługi typu, nadal jest obsługiwana w ten sposób. Sugerujemy jednak użycie nowego AzureDataLakeStorageGen2 typu połączonej usługi w przyszłości.
Przykład:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource e.g. https://<accountname>.blob.core.windows.net/?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład: przechowywanie klucza konta w usłudze Azure Key Vault
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<accountname>.blob.core.windows.net/>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName with value of SAS token e.g. ?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Podczas tworzenia identyfikatora URI sygnatury dostępu współdzielonego należy wziąć pod uwagę następujące kwestie:
- Ustaw odpowiednie uprawnienia do odczytu/zapisu dla obiektów na podstawie sposobu użycia połączonej usługi (odczyt, zapis, odczyt/zapis).
- Odpowiednio ustaw czas wygaśnięcia. Upewnij się, że dostęp do obiektów magazynu nie wygasa w aktywnym okresie potoku.
- Identyfikator URI powinien zostać utworzony w odpowiednim kontenerze lub obiekcie blob w zależności od potrzeb. Identyfikator URI sygnatury dostępu współdzielonego do obiektu blob umożliwia usłudze Data Factory lub potokowi usługi Synapse dostęp do tego określonego obiektu blob. Identyfikator URI sygnatury dostępu współdzielonego do kontenera usługi Blob Storage umożliwia usłudze Data Factory lub potokowi usługi Synapse iterowanie za pośrednictwem obiektów blob w tym kontenerze. Aby zapewnić dostęp do większej liczby obiektów później lub zaktualizować identyfikator URI sygnatury dostępu współdzielonego, pamiętaj, aby zaktualizować połączoną usługę przy użyciu nowego identyfikatora URI.
Uwierzytelnianie nazwy głównej usługi
Aby użyć uwierzytelniania jednostki usługi, wykonaj następujące kroki.
Zarejestruj aplikację w Platforma tożsamości Microsoft. Aby dowiedzieć się, jak to zrobić, zobacz Szybki start: rejestrowanie aplikacji przy użyciu Platforma tożsamości Microsoft. Zanotuj te wartości, których użyjesz do zdefiniowania połączonej usługi:
- Application ID
- Klucz aplikacji
- Identyfikator dzierżawy
Przyznaj jednostce usługi odpowiednie uprawnienie. Zobacz przykłady działania uprawnień w usłudze Data Lake Storage Gen2 z list kontroli dostępu w plikach i katalogach
- Jako źródło: W Eksploratorze usługi Storage przyznaj co najmniej uprawnienie Wykonywanie do WSZYSTKICH folderów nadrzędnych i systemu plików, a także uprawnienie Odczyt do plików do skopiowania. Alternatywnie w sekcji Kontrola dostępu (zarządzanie dostępem i tożsamościami) przyznaj co najmniej rolę Czytelnik danych obiektu blob usługi Storage.
- Jako ujście: W Eksploratorze usługi Storage przyznaj co najmniej uprawnienie Wykonywanie do WSZYSTKICH folderów nadrzędnych i systemu plików, a także uprawnienie Zapis do folderu ujścia. Alternatywnie w sekcji Kontrola dostępu (zarządzanie dostępem i tożsamościami) przyznaj co najmniej rolę Współautor danych obiektu blob usługi Storage.
Uwaga
Jeśli używasz interfejsu użytkownika do tworzenia, a jednostka usługi nie jest ustawiona z rolą "Czytelnik/współautor danych obiektu blob usługi Storage" w funkcji Zarządzanie dostępem i tożsamościami, podczas testowania połączenia lub przeglądania/nawigacji folderów wybierz pozycję "Testuj połączenie ze ścieżką pliku" lub "Przeglądaj z określonej ścieżki" i określ ścieżkę z uprawnieniem Odczyt i wykonywanie , aby kontynuować.
Te właściwości są obsługiwane w przypadku połączonej usługi:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na Wartość AzureBlobFS. | Tak |
| Adres URL | Punkt końcowy dla usługi Data Lake Storage Gen2 ze wzorcem https://<accountname>.dfs.core.windows.net. |
Tak |
| servicePrincipalId | Określ identyfikator klienta aplikacji. | Tak |
| servicePrincipalCredentialType | Typ poświadczeń do użycia na potrzeby uwierzytelniania jednostki usługi. Dozwolone wartości to ServicePrincipalKey i ServicePrincipalCert. | Tak |
| servicePrincipalCredential | Poświadczenie jednostki usługi. W przypadku użycia klucza ServicePrincipalKey jako typu poświadczeń określ klucz aplikacji. Oznacz to pole jako SecureString , aby bezpiecznie je przechowywać lub odwołuje się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. Jeśli używasz klasy ServicePrincipalCert jako poświadczenia, odwołaj się do certyfikatu w usłudze Azure Key Vault i upewnij się, że typ zawartości certyfikatu to PKCS #12. |
Tak |
| servicePrincipalKey | Określ klucz aplikacji. Oznacz to pole jako SecureString , aby bezpiecznie je przechowywać lub odwołuje się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. Ta właściwość jest nadal obsługiwana w przypadku elementu servicePrincipalId + servicePrincipalKey. Ponieważ usługa ADF dodaje nowe uwierzytelnianie certyfikatu jednostki usługi, nowy model uwierzytelniania jednostki usługi to servicePrincipalId + + servicePrincipalCredentialTypeservicePrincipalCredential. |
Nie. |
| tenant | Określ informacje o dzierżawie (nazwę domeny lub identyfikator dzierżawy), w ramach których znajduje się aplikacja. Pobierz go, umieszczając wskaźnik myszy w prawym górnym rogu witryny Azure Portal. | Tak |
| azureCloudType | W przypadku uwierzytelniania jednostki usługi określ typ środowiska chmury platformy Azure, do którego zarejestrowano aplikację Firmy Microsoft Entra. Dozwolone wartości to AzurePublic, AzureChina, AzureUsGovernment i AzureGermany. Domyślnie jest używane środowisko chmury potoku usługi Synapse lub fabryki danych. |
Nie. |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime, jeśli magazyn danych znajduje się w sieci prywatnej. Jeśli nie zostanie określony, zostanie użyte domyślne środowisko Azure Integration Runtime. | Nie. |
Przykład: używanie uwierzytelniania klucza jednostki usługi
Klucz jednostki usługi można również przechowywać w usłudze Azure Key Vault.
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład: używanie uwierzytelniania certyfikatu jednostki usługi
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalCredential": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<AKV reference>",
"type": "LinkedServiceReference"
},
"secretName": "<certificate name in AKV>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uwierzytelnianie tożsamości zarządzanej przypisanej przez system
Fabrykę danych lub obszar roboczy usługi Synapse można skojarzyć z tożsamością zarządzaną przypisaną przez system. Tę tożsamość zarządzaną przypisaną przez system można bezpośrednio użyć do uwierzytelniania usługi Data Lake Storage Gen2, podobnie jak w przypadku własnej jednostki usługi. Umożliwia to wyznaczonej fabryce lub obszarowi roboczemu uzyskiwanie dostępu do danych i kopiowanie ich do lub z usługi Data Lake Storage Gen2.
Aby użyć uwierzytelniania tożsamości zarządzanej przypisanej przez system, wykonaj następujące kroki.
Pobierz informacje o tożsamości zarządzanej przypisanej przez system, kopiując wartość identyfikatora obiektu tożsamości zarządzanej wygenerowaną wraz z fabryką danych lub obszarem roboczym usługi Synapse.
Przyznaj przypisanej przez system tożsamości zarządzanej odpowiednie uprawnienia. Zobacz przykłady działania uprawnień w usłudze Data Lake Storage Gen2 z list kontroli dostępu w plikach i katalogach.
- Jako źródło: W Eksploratorze usługi Storage przyznaj co najmniej uprawnienie Wykonywanie do WSZYSTKICH folderów nadrzędnych i systemu plików, a także uprawnienie Odczyt do plików do skopiowania. Alternatywnie w sekcji Kontrola dostępu (zarządzanie dostępem i tożsamościami) przyznaj co najmniej rolę Czytelnik danych obiektu blob usługi Storage.
- Jako ujście: W Eksploratorze usługi Storage przyznaj co najmniej uprawnienie Wykonywanie do WSZYSTKICH folderów nadrzędnych i systemu plików, a także uprawnienie Zapis do folderu ujścia. Alternatywnie w sekcji Kontrola dostępu (zarządzanie dostępem i tożsamościami) przyznaj co najmniej rolę Współautor danych obiektu blob usługi Storage.
Te właściwości są obsługiwane w przypadku połączonej usługi:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na Wartość AzureBlobFS. | Tak |
| Adres URL | Punkt końcowy dla usługi Data Lake Storage Gen2 ze wzorcem https://<accountname>.dfs.core.windows.net. |
Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime, jeśli magazyn danych znajduje się w sieci prywatnej. Jeśli nie zostanie określony, zostanie użyte domyślne środowisko Azure Integration Runtime. | Nie. |
Przykład:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uwierzytelnianie tożsamości zarządzanej przypisanej przez użytkownika
Fabrykę danych można przypisać za pomocą jednej lub wielu tożsamości zarządzanych przypisanych przez użytkownika. Tej tożsamości zarządzanej przypisanej przez użytkownika można użyć do uwierzytelniania usługi Blob Storage, które umożliwia dostęp do danych i kopiowanie ich z usługi Data Lake Storage Gen2 lub do usługi Data Lake Storage Gen2. Aby dowiedzieć się więcej o tożsamościach zarządzanych dla zasobów platformy Azure, zobacz Tożsamości zarządzane dla zasobów platformy Azure
Aby użyć uwierzytelniania tożsamości zarządzanej przypisanej przez użytkownika, wykonaj następujące kroki:
Utwórz jedną lub wiele tożsamości zarządzanych przypisanych przez użytkownika i przyznaj dostęp do usługi Azure Data Lake Storage Gen2. Zobacz przykłady działania uprawnień w usłudze Data Lake Storage Gen2 z list kontroli dostępu w plikach i katalogach.
- Jako źródło: W Eksploratorze usługi Storage przyznaj co najmniej uprawnienie Wykonywanie do WSZYSTKICH folderów nadrzędnych i systemu plików, a także uprawnienie Odczyt do plików do skopiowania. Alternatywnie w sekcji Kontrola dostępu (zarządzanie dostępem i tożsamościami) przyznaj co najmniej rolę Czytelnik danych obiektu blob usługi Storage.
- Jako ujście: W Eksploratorze usługi Storage przyznaj co najmniej uprawnienie Wykonywanie do WSZYSTKICH folderów nadrzędnych i systemu plików, a także uprawnienie Zapis do folderu ujścia. Alternatywnie w sekcji Kontrola dostępu (zarządzanie dostępem i tożsamościami) przyznaj co najmniej rolę Współautor danych obiektu blob usługi Storage.
Przypisz jedną lub wiele tożsamości zarządzanych przypisanych przez użytkownika do fabryki danych i utwórz poświadczenia dla każdej tożsamości zarządzanej przypisanej przez użytkownika.
Te właściwości są obsługiwane w przypadku połączonej usługi:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na Wartość AzureBlobFS. | Tak |
| Adres URL | Punkt końcowy dla usługi Data Lake Storage Gen2 ze wzorcem https://<accountname>.dfs.core.windows.net. |
Tak |
| poświadczenia | Określ tożsamość zarządzaną przypisaną przez użytkownika jako obiekt poświadczeń. | Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime, jeśli magazyn danych znajduje się w sieci prywatnej. Jeśli nie zostanie określony, zostanie użyte domyślne środowisko Azure Integration Runtime. | Nie. |
Przykład:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uwaga
Jeśli używasz interfejsu użytkownika usługi Data Factory do tworzenia i tożsamość zarządzana nie jest ustawiona z rolą "Czytelnik/współautor danych obiektu blob usługi Storage" w usłudze IAM, podczas testowania połączenia lub przeglądania/nawigacji folderów wybierz pozycję "Testuj połączenie ze ścieżką pliku" lub "Przeglądaj z określonej ścieżki" i określ ścieżkę z uprawnieniem Odczyt i wykonywanie , aby kontynuować.
Ważne
Jeśli używasz instrukcji PolyBase lub COPY do ładowania danych z usługi Data Lake Storage Gen2 do usługi Azure Synapse Analytics, podczas korzystania z uwierzytelniania tożsamości zarządzanej dla usługi Data Lake Storage Gen2 upewnij się, że wykonasz również kroki od 1 do 3 w tych wskazówkach. Te kroki spowodują zarejestrowanie serwera przy użyciu identyfikatora Entra firmy Microsoft i przypisanie roli Współautor danych obiektu blob usługi Storage do serwera. Usługa Data Factory obsługuje resztę. Jeśli skonfigurujesz usługę Blob Storage przy użyciu punktu końcowego usługi Azure Virtual Network, musisz również mieć opcję Zezwalaj na zaufane usługi firmy Microsoft uzyskiwania dostępu do tego konta magazynu włączonego w obszarze Zapory konta usługi Azure Storage i menu ustawień sieci wirtualnych zgodnie z wymaganiami usługi Azure Synapse.
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz Zestawy danych.
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format programu Excel
- Format góry lodowej
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Następujące właściwości są obsługiwane w przypadku usługi Data Lake Storage Gen2 w obszarze location ustawień w zestawie danych opartym na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze location w zestawie danych musi być ustawiona na Wartość AzureBlobFSLocation. |
Tak |
| fileSystem | Nazwa systemu plików usługi Data Lake Storage Gen2. | Nie. |
| folderPath | Ścieżka do folderu w danym systemie plików. Jeśli chcesz używać symbolu wieloznakowego do filtrowania folderów, pomiń to ustawienie i określ je w ustawieniach źródła działań. | Nie. |
| fileName | Nazwa pliku pod danym plikiemSystem + folderPath. Jeśli chcesz używać symbolu wieloznakowego do filtrowania plików, pomiń to ustawienie i określ je w ustawieniach źródła działań. | Nie. |
Przykład:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Data Lake Storage Gen2 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobFSLocation",
"fileSystem": "filesystemname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz działanie Kopiuj konfiguracje i potoki i działania. Ta sekcja zawiera listę właściwości obsługiwanych przez źródło i ujście usługi Data Lake Storage Gen2.
Usługa Azure Data Lake Storage Gen2 jako typ źródła
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format programu Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Istnieje kilka opcji kopiowania danych z usługi ADLS Gen2:
- Skopiuj z podanej ścieżki określonej w zestawie danych.
- Filtr wieloznaczny względem ścieżki folderu lub nazwy pliku, zobacz
wildcardFolderPathiwildcardFileName. - Skopiuj pliki zdefiniowane w danym pliku tekstowym jako zestaw plików, zobacz
fileListPath.
Następujące właściwości są obsługiwane w przypadku usługi Data Lake Storage Gen2 w ustawieniach storeSettings w źródle kopiowania opartym na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze storeSettings musi być ustawiona na Wartość AzureBlobFSReadSettings. |
Tak |
| Znajdź pliki do skopiowania: | ||
| OPCJA 1: ścieżka statyczna |
Skopiuj z danego systemu plików lub ścieżki folderu/pliku określonego w zestawie danych. Jeśli chcesz skopiować wszystkie pliki z systemu plików/folderu, dodatkowo określ wildcardFileName wartość *. |
|
| OPCJA 2: symbol wieloznaczny - symbol wieloznacznyFolderPath |
Ścieżka folderu z symbolami wieloznacznymi w danym systemie plików skonfigurowanym w zestawie danych do filtrowania folderów źródłowych. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku); użyj ^ , aby uniknąć, jeśli rzeczywista nazwa folderu ma symbol wieloznaczny lub znak ucieczki wewnątrz. Zobacz więcej przykładów w przykładach filtru folderów i plików. |
Nie. |
| OPCJA 2: symbol wieloznaczny - symbol wieloznacznyFileName |
Nazwa pliku z symbolami wieloznacznymi w danym systemie plików + folderPath/symbol wieloznacznyFolderPath do filtrowania plików źródłowych. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku); użyj ^ , aby uniknąć, jeśli rzeczywista nazwa pliku ma symbol wieloznaczny lub znak ucieczki wewnątrz. Zobacz więcej przykładów w przykładach filtru folderów i plików. |
Tak |
| OPCJA 3: lista plików - fileListPath |
Wskazuje, aby skopiować dany zestaw plików. Wskaż plik tekstowy zawierający listę plików, które chcesz skopiować, jeden plik na wiersz, czyli ścieżkę względną do ścieżki skonfigurowanej w zestawie danych. W przypadku korzystania z tej opcji nie należy określać nazwy pliku w zestawie danych. Zobacz więcej przykładów na przykładach na liście plików. |
Nie. |
| Dodatkowe ustawienia: | ||
| Cykliczne | Wskazuje, czy dane są odczytywane rekursywnie z podfolderów, czy tylko z określonego folderu. Należy pamiętać, że gdy rekursywna ma wartość true, a ujście jest magazynem opartym na plikach, pusty folder lub podfolder nie jest kopiowany ani tworzony w ujściu. Dozwolone wartości to true (wartość domyślna) i false. Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| deleteFilesAfterCompletion | Wskazuje, czy pliki binarne zostaną usunięte z magazynu źródłowego po pomyślnym przeniesieniu do magazynu docelowego. Usunięcie pliku jest na plik, więc gdy działanie kopiowania nie powiedzie się, zobaczysz, że niektóre pliki zostały już skopiowane do miejsca docelowego i usunięte ze źródła, podczas gdy inne nadal pozostają w magazynie źródłowym. Ta właściwość jest prawidłowa tylko w scenariuszu kopiowania plików binarnych. Wartość domyślna: false. |
Nie. |
| modifiedDatetimeStart | Filtr plików na podstawie atrybutu: Ostatnia modyfikacja. Pliki zostaną wybrane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie "2018-12-01T05:00:00Z". Właściwości mogą mieć wartość NULL, co oznacza, że do zestawu danych nie zostanie zastosowany filtr atrybutu pliku. Jeśli modifiedDatetimeStart ma wartość datetime, ale modifiedDatetimeEnd ma wartość NULL, oznacza to, że zostaną wybrane pliki, których ostatni zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość data/godzina, ale modifiedDatetimeStart ma wartość NULL, oznacza to, że pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość daty/godziny, zostanie wybrana.Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| modifiedDatetimeEnd | Jak wyżej. | Nie. |
| enablePartitionDiscovery | W przypadku plików podzielonych na partycje określ, czy analizować partycje ze ścieżki pliku i dodać je jako dodatkowe kolumny źródłowe. Dozwolone wartości to false (wartość domyślna) i true. |
Nie. |
| partitionRootPath | Po włączeniu odnajdywania partycji określ bezwzględną ścieżkę katalogu głównego, aby odczytywać foldery podzielone na partycje jako kolumny danych. Jeśli nie zostanie określony, domyślnie, — Jeśli używasz ścieżki pliku w zestawie danych lub liście plików w źródle, ścieżka główna partycji jest ścieżką skonfigurowaną w zestawie danych. — W przypadku używania filtru folderów wieloznacznych ścieżka główna partycji jest ścieżką podrzędną przed pierwszym symbolem wieloznacznymi. Załóżmy na przykład, że ścieżka w zestawie danych zostanie skonfigurowana jako "root/folder/year=2020/month=08/day=27": - Jeśli określisz ścieżkę główną partycji jako "root/folder/year=2020", działanie kopiowania wygeneruje dwie kolejne kolumny month i day z wartością "08" i "27" odpowiednio, oprócz kolumn wewnątrz plików.— Jeśli nie określono ścieżki głównej partycji, nie zostanie wygenerowana żadna dodatkowa kolumna. |
Nie. |
| maxConcurrentConnections | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Przykład:
"activities":[
{
"name": "CopyFromADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureBlobFSReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Usługa Azure Data Lake Storage Gen2 jako typ ujścia
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format góry lodowej
- Format JSON
- Format ORC
- Format Parquet
Następujące właściwości są obsługiwane w przypadku usługi Data Lake Storage Gen2 w ustawieniach storeSettings ujścia kopiowania opartego na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze storeSettings musi być ustawiona na Wartość AzureBlobFSWriteSettings. |
Tak |
| copyBehavior | Definiuje zachowanie kopiowania, gdy źródłem są pliki z magazynu danych opartego na plikach. Dozwolone wartości to: - PreserveHierarchy (wartość domyślna): Zachowuje hierarchię plików w folderze docelowym. Ścieżka względna pliku źródłowego do folderu źródłowego jest identyczna ze ścieżką względną pliku docelowego do folderu docelowego. - FlattenHierarchy: Wszystkie pliki z folderu źródłowego znajdują się na pierwszym poziomie folderu docelowego. Pliki docelowe mają automatycznie wygenerowane nazwy. - MergeFiles: Scala wszystkie pliki z folderu źródłowego do jednego pliku. Jeśli określono nazwę pliku, scalona nazwa pliku jest określoną nazwą. W przeciwnym razie jest to automatycznie wygenerowana nazwa pliku. |
Nie. |
| blockSizeInMB | Określ rozmiar bloku w MB używany do zapisywania danych w usłudze ADLS Gen2. Dowiedz się więcej o blokowych obiektach blob. Dozwolona wartość wynosi od 4 MB do 100 MB. Domyślnie usługa ADF automatycznie określa rozmiar bloku na podstawie typu magazynu źródłowego i danych. W przypadku kopiowania nie binarnego do usługi ADLS Gen2 domyślny rozmiar bloku wynosi 100 MB, tak aby mieścił się w danych o rozmiarze co najwyżej 4,75 TB. Może to nie być optymalne, gdy dane nie są duże, zwłaszcza w przypadku korzystania z własnego środowiska Integration Runtime z słabą siecią, co powoduje przekroczenie limitu czasu operacji lub problem z wydajnością. Można jawnie określić rozmiar bloku, podczas gdy upewnij się, że parametr blockSizeInMB*50000 jest wystarczająco duży, aby przechowywać dane, w przeciwnym razie uruchomienie działania kopiowania zakończy się niepowodzeniem. |
Nie. |
| maxConcurrentConnections | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
| metadane | Ustaw metadane niestandardowe podczas kopiowania do ujścia. Każdy obiekt w tablicy metadata reprezentuje dodatkową kolumnę. Element name definiuje nazwę klucza metadanych i value wskazuje wartość danych tego klucza. Jeśli jest używana funkcja zachowania atrybutów, określone metadane będą union/overwrite z metadanymi pliku źródłowego.Dozwolone wartości danych to: - $$LASTMODIFIED: zmienna zarezerwowana wskazuje czas ostatniej modyfikacji plików źródłowych. Zastosuj do źródła opartego na plikach tylko z formatem binarnym.-Wyrażenie - Wartość statyczna |
Nie. |
Przykład:
"activities":[
{
"name": "CopyToADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureBlobFSWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
},
{
"name": "lastModifiedKey",
"value": "$$LASTMODIFIED"
}
]
}
}
}
}
]
Przykłady filtrów folderów i plików
W tej sekcji opisano wynikowe zachowanie ścieżki folderu i nazwy pliku z filtrami wieloznacznymi.
| folderPath | fileName | Cykliczne | Struktura folderu źródłowego i wynik filtru (pobierane są pliki pogrubione ) |
|---|---|---|---|
Folder* |
(Puste, użyj wartości domyślnej) | fałsz | FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
Folder* |
(Puste, użyj wartości domyślnej) | prawda | FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
Folder* |
*.csv |
fałsz | FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
Folder* |
*.csv |
prawda | FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
Przykłady listy plików
W tej sekcji opisano wynikowe zachowanie używania ścieżki listy plików w źródle działania kopiowania.
Zakładając, że masz następującą strukturę folderów źródłowych i chcesz skopiować pliki pogrubioną:
| Przykładowa struktura źródła | Zawartość w FileListToCopy.txt | Konfiguracja usługi ADF |
|---|---|---|
| System plików FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv Metadane FileListToCopy.txt |
File1.csv Podfolder1/File3.csv Podfolder1/File5.csv |
W zestawie danych: - System plików: filesystem- Ścieżka folderu: FolderAW źródle działania kopiowania: - Ścieżka listy plików: filesystem/Metadata/FileListToCopy.txt Ścieżka listy plików wskazuje plik tekstowy w tym samym magazynie danych, który zawiera listę plików, które chcesz skopiować, jeden plik na wiersz ze ścieżką względną do ścieżki skonfigurowanej w zestawie danych. |
Niektóre przykłady rekursywne i copyBehavior
W tej sekcji opisano wynikowe zachowanie operacji kopiowania dla różnych kombinacji wartości cyklicznych i copyBehavior.
| Cykliczne | copyBehavior | Struktura folderu źródłowego | Wynikowy element docelowy |
|---|---|---|---|
| prawda | preserveHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z taką samą strukturą jak źródło: Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
| prawda | flattenHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 automatycznie wygenerowana nazwa pliku File1 automatycznie wygenerowana nazwa dla pliku File2 automatycznie wygenerowana nazwa dla pliku File3 automatycznie wygenerowana nazwa dla pliku File4 automatycznie wygenerowana nazwa dla pliku File5 |
| prawda | mergeFiles | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 Plik1 + Plik2 + Plik3 + Plik4 + Zawartość pliku5 są scalane w jeden plik z automatycznie wygenerowaną nazwą pliku. |
| fałsz | preserveHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 Plik1 Plik2 Podfolder1 z plikiem File3, File4 i File5 nie jest pobierany. |
| fałsz | flattenHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 automatycznie wygenerowana nazwa pliku File1 automatycznie wygenerowana nazwa dla pliku File2 Podfolder1 z plikiem File3, File4 i File5 nie jest pobierany. |
| fałsz | mergeFiles | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 Zawartość file1 + File2 jest scalona z jednym plikiem z automatycznie wygenerowaną nazwą pliku. automatycznie wygenerowana nazwa pliku File1 Podfolder1 z plikiem File3, File4 i File5 nie jest pobierany. |
Zachowywanie metadanych podczas kopiowania
Podczas kopiowania plików z usługi Amazon S3/Azure Blob/Azure Data Lake Storage Gen2 do usługi Azure Data Lake Storage Gen2/Azure Blob można zachować metadane pliku wraz z danymi. Dowiedz się więcej na temat zachowywania metadanych.
Zachowywanie list ACL z usługi Data Lake Storage Gen1/Gen2
Podczas kopiowania plików z usługi Azure Data Lake Storage Gen1/Gen2 do usługi Gen2 można zachować listy kontroli dostępu (ACL) POSIX wraz z danymi. Dowiedz się więcej z tematu Preserve ACL from Data Lake Storage Gen1/Gen2 to Gen2 (Zachowywanie list ACL z usługi Data Lake Storage Gen1/Gen2 do gen2).
Napiwek
Aby skopiować dane z usługi Azure Data Lake Storage Gen1 do generacji 2, zobacz Kopiowanie danych z usługi Azure Data Lake Storage Gen1 do generacji 2 , aby zapoznać się z instrukcjami i najlepszymi rozwiązaniami.
Właściwości przepływu mapowania danych
Podczas przekształcania danych w przepływach mapowania danych można odczytywać i zapisywać pliki z usługi Azure Data Lake Storage Gen2 w następujących formatach:
Ustawienia specyficzne dla formatu znajdują się w dokumentacji dla tego formatu. Aby uzyskać więcej informacji, zobacz Przekształcanie źródła w przepływie mapowania danych i Przekształcanie ujścia w przepływie danych mapowania.
Przekształcanie źródła
W transformacji źródłowej można odczytać z kontenera, folderu lub pojedynczego pliku w usłudze Azure Data Lake Storage Gen2. Karta Opcje źródła umożliwia zarządzanie sposobem odczytu plików.
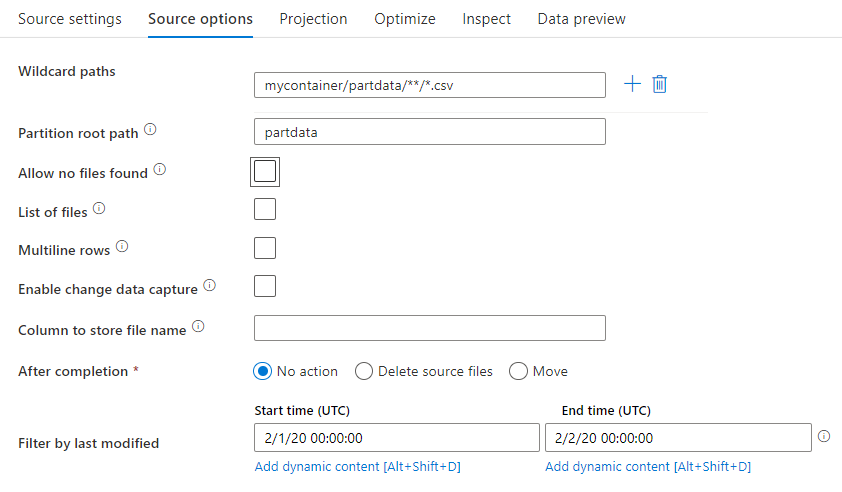
Ścieżka z symbolami wieloznacznymi: użycie wzorca z symbolami wieloznacznymi spowoduje, że usługa ADF przeprowadzi pętlę do każdego pasującego folderu i pliku w ramach pojedynczej transformacji źródłowej. Jest to skuteczny sposób przetwarzania wielu plików w ramach jednego przepływu. Dodaj wiele wzorców dopasowania symboli wieloznacznych za pomocą znaku + wyświetlanego podczas umieszczania wskaźnika myszy na istniejącym wzorcu wieloznacznymi.
W kontenerze źródłowym wybierz serię plików pasujących do wzorca. W zestawie danych można określić tylko kontener. W związku z tym ścieżka wieloznaczny musi zawierać również ścieżkę folderu z folderu głównego.
Przykłady symboli wieloznacznych:
*Reprezentuje dowolny zestaw znaków**Reprezentuje zagnieżdżanie katalogów cyklicznych?Zamienia jeden znak[]Pasuje do jednego z więcej znaków w nawiasach kwadratowych/data/sales/**/*.csvPobiera wszystkie pliki CSV w obszarze /data/sales/data/sales/20??/**/Pobiera wszystkie pliki w XX wieku/data/sales/*/*/*.csvPobiera pliki CSV na dwóch poziomach w obszarze /data/sales/data/sales/2004/*/12/[XY]1?.csvPobiera wszystkie pliki CSV w 2004 r. w grudniu, począwszy od X lub Y poprzedzonego dwucyfrowym numerem
Ścieżka główna partycji: jeśli foldery partycjonowane w źródle key=value pliku mają format (na przykład year=2019), możesz przypisać najwyższy poziom drzewa folderów partycji do nazwy kolumny w strumieniu danych przepływu danych.
Najpierw ustaw symbol wieloznaczny, aby zawierał wszystkie ścieżki, które są folderami podzielonymi na partycje oraz plikami liścia, które chcesz odczytać.
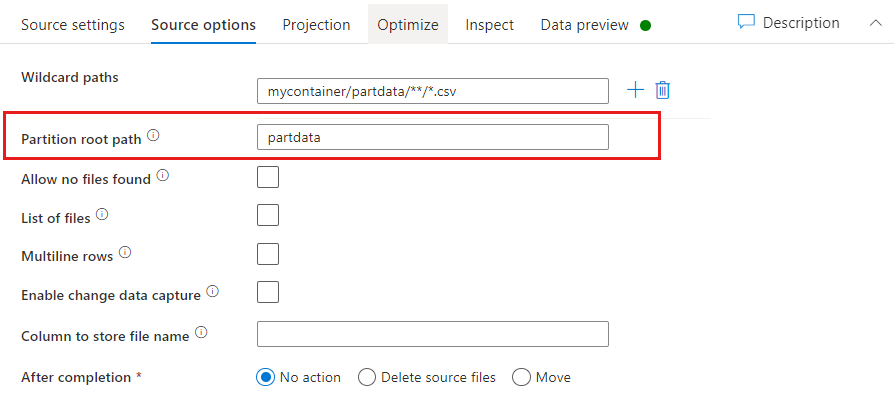
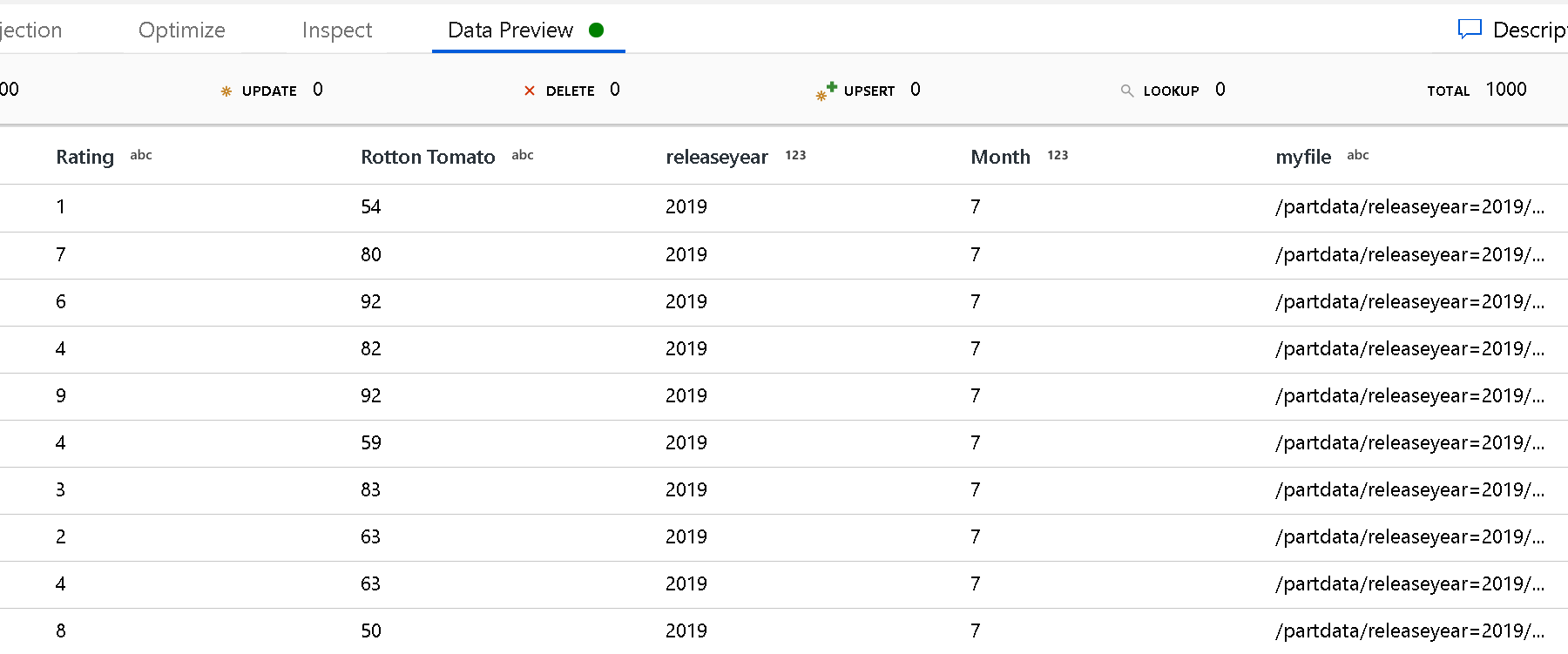
Użyj ustawienia Ścieżka główna partycji, aby zdefiniować, jaki jest najwyższy poziom struktury folderów. Gdy wyświetlisz zawartość danych za pośrednictwem podglądu danych, zobaczysz, że usługa ADF doda rozpoznane partycje znalezione na każdym z poziomów folderów.
Lista plików: jest to zestaw plików. Utwórz plik tekstowy zawierający listę plików ścieżki względnej do przetworzenia. Wskaż ten plik tekstowy.
Kolumna do przechowywania nazwy pliku: zapisz nazwę pliku źródłowego w kolumnie w danych. Wprowadź tutaj nową nazwę kolumny, aby zapisać ciąg nazwy pliku.
Po zakończeniu: wybierz opcję wykonania niczego z plikiem źródłowym po uruchomieniu przepływu danych, usunięciu pliku źródłowego lub przeniesieniu pliku źródłowego. Ścieżki przenoszenia są względne.
Aby przenieść pliki źródłowe do innej lokalizacji po przetworzeniu, najpierw wybierz pozycję "Przenieś" dla operacji na plikach. Następnie ustaw katalog "from". Jeśli nie używasz żadnych symboli wieloznacznych dla ścieżki, ustawienie "from" będzie tym samym folderem co folder źródłowy.
Jeśli masz ścieżkę źródłową z symbolami wieloznacznymi, składnia będzie wyglądać następująco:
/data/sales/20??/**/*.csv
Możesz określić wartość "from" jako
/data/sales
I "do" jako
/backup/priorSales
W takim przypadku wszystkie pliki, które zostały pozyskane w obszarze /data/sales, są przenoszone do /backup/priorSales.
Uwaga
Operacje na plikach są uruchamiane tylko po uruchomieniu przepływu danych z uruchomienia potoku (przebiegu debugowania lub wykonywania potoku), które używa działania Wykonaj Przepływ danych w potoku. Operacje na plikach nie są uruchamiane w trybie debugowania Przepływ danych.
Filtruj według ostatniej modyfikacji: możesz filtrować, które pliki są przetwarzane, określając zakres dat ostatniej modyfikacji. Wszystkie daty i godziny są w formacie UTC.
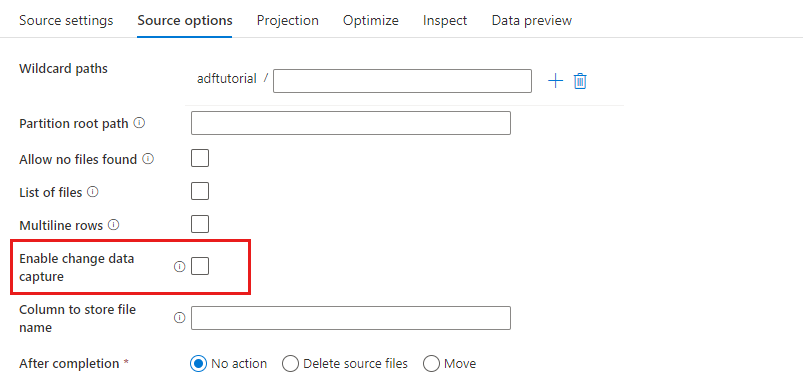
Włącz przechwytywanie danych zmian: jeśli wartość true, otrzymasz nowe lub zmienione pliki tylko z ostatniego uruchomienia. Początkowe ładowanie pełnych danych migawki będzie zawsze uzyskiwane w pierwszym uruchomieniu, a następnie przechwytywanie nowych lub zmienionych plików tylko w następnych uruchomieniach. Aby uzyskać więcej informacji, zobacz Zmienianie przechwytywania danych.
Właściwości ujścia
W transformacji ujścia można zapisać w kontenerze lub folderze w usłudze Azure Data Lake Storage Gen2. Karta Ustawienia umożliwia zarządzanie sposobem zapisywania plików.
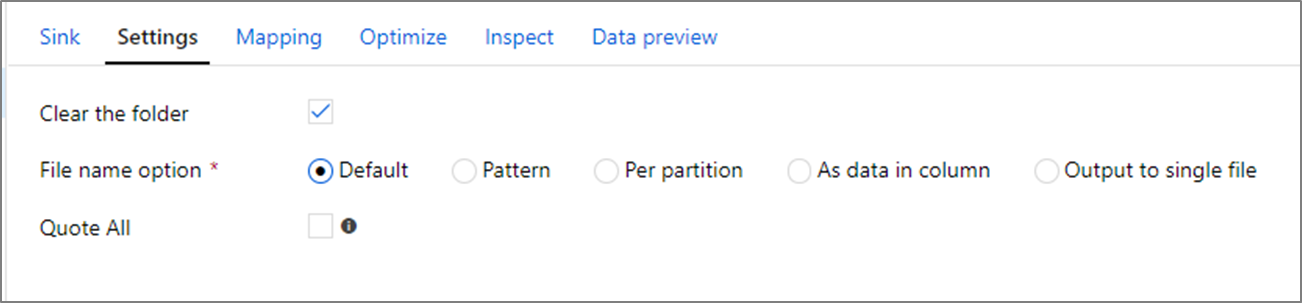
Wyczyść folder: określa, czy folder docelowy zostanie wyczyszczone przed zapisem danych.
Opcja nazwy pliku: określa, w jaki sposób pliki docelowe są nazwane w folderze docelowym. Opcje nazwy pliku to:
- Ustawienie domyślne: Zezwalaj platformie Spark na nadawanie nazw plikom na podstawie wartości domyślnych PART.
- Wzorzec: wprowadź wzorzec wyliczający pliki wyjściowe na partycję. Na przykład pożyczki[n].csv będą tworzyć loans1.csv, loans2.csv itd.
- Na partycję: wprowadź jedną nazwę pliku na partycję.
- Jako dane w kolumnie: ustaw plik wyjściowy na wartość kolumny. Ścieżka jest względna względem kontenera zestawu danych, a nie folderu docelowego. Jeśli masz ścieżkę folderu w zestawie danych, zostanie ona zastąpiona.
- Dane wyjściowe do pojedynczego pliku: połącz partycjonowane pliki wyjściowe w jeden nazwany plik. Ścieżka jest względna względem folderu zestawu danych. Należy pamiętać, że operacja scalania może zakończyć się niepowodzeniem na podstawie rozmiaru węzła. Ta opcja nie jest zalecana w przypadku dużych zestawów danych.
Cudzysłowy: określa, czy należy ująć wszystkie wartości w cudzysłowie
umask
Opcjonalnie można ustawić umask dla plików przy użyciu funkcji odczytu, zapisu, wykonywania flag dla właściciela, użytkownika i grupy.
Polecenia przetwarzania wstępnego i przetwarzania końcowego
Opcjonalnie można wykonać polecenia systemu plików Hadoop przed zapisem w ujściu usługi ADLS Gen2 lub po nim. Obsługiwane są następujące polecenia:
cpmvrmmkdir
Przykłady:
mkdir /folder1mkdir -p folder1mv /folder1/*.* /folder2/cp /folder1/file1.txt /folder2rm -r /folder1
Parametry są również obsługiwane za pomocą konstruktora wyrażeń, na przykład:
mkdir -p {$tempPath}/commands/c1/c2
mv {$tempPath}/commands/*.* {$tempPath}/commands/c1/c2
Domyślnie foldery są tworzone jako użytkownik/katalog główny. Zapoznaj się z kontenerem najwyższego poziomu za pomocą polecenia "/".
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Właściwości działania GetMetadata
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie GetMetadata
Usuń właściwości działania
Aby dowiedzieć się więcej o właściwościach, zobacz Działanie Usuwania
Starsze modele
Uwaga
Następujące modele są nadal obsługiwane zgodnie ze zgodnością z poprzednimi wersjami. Zaleca się użycie nowego modelu wymienionego w powyższych sekcjach, a interfejs użytkownika tworzenia usługi ADF przeszedł na generowanie nowego modelu.
Starszy model zestawu danych
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na Wartość AzureBlobFSFile. | Tak |
| folderPath | Ścieżka do folderu w usłudze Data Lake Storage Gen2. Jeśli nie zostanie określony, wskazuje on katalog główny. Obsługiwany jest filtr wieloznaczny. Dozwolone symbole wieloznaczne to * (dopasowywały zero lub więcej znaków) i ? (dopasowywały zero lub pojedynczy znak). Użyj ^ polecenia , aby uniknąć, jeśli rzeczywista nazwa folderu ma symbol wieloznaczny lub ten znak ucieczki znajduje się wewnątrz. Przykłady: system plików/folder/. Zobacz więcej przykładów w przykładach filtru folderów i plików. |
Nie. |
| fileName | Nazwa lub filtr symboli wieloznacznych dla plików w ramach określonego "folderPath". Jeśli nie określisz wartości dla tej właściwości, zestaw danych wskazuje wszystkie pliki w folderze. W przypadku filtru dozwolone symbole wieloznaczne są * (dopasowywały zero lub więcej znaków) i ? (dopasowywały zero lub pojedynczy znak).- Przykład 1: "fileName": "*.csv"— Przykład 2: "fileName": "???20180427.txt"Użyj ^ polecenia , aby uniknąć, jeśli rzeczywista nazwa pliku ma symbol wieloznaczny lub ten znak ucieczki znajduje się wewnątrz.Jeśli parametr fileName nie jest określony dla wyjściowego zestawu danych i parametr preserveHierarchy nie jest określony w ujściu działania działania kopiowania, działanie kopiowania automatycznie generuje nazwę pliku z następującym wzorcem: "Dane.[ identyfikator GUID przebiegu działania]. [IDENTYFIKATOR GUID, jeśli FlattenHierarchy]. [format, jeśli został skonfigurowany]. [kompresja, jeśli skonfigurowano]", na przykład "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". Jeśli kopiujesz ze źródła tabelarycznego przy użyciu nazwy tabeli zamiast zapytania, wzorzec nazwy to "[nazwa tabeli].[ format]. [kompresja, jeśli została skonfigurowana]", na przykład "MyTable.csv". |
Nie. |
| modifiedDatetimeStart | Filtr plików na podstawie atrybutu Ostatnia modyfikacja. Pliki są wybierane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie "2018-12-01T05:00:00Z". Ogólna wydajność przenoszenia danych ma wpływ na włączenie tego ustawienia, gdy chcesz filtrować pliki z ogromnymi ilościami plików. Właściwości mogą mieć wartość NULL, co oznacza, że do zestawu danych nie jest stosowany filtr atrybutu pliku. Jeśli modifiedDatetimeStart ma wartość typu data/godzina, ale modifiedDatetimeEnd ma wartość NULL, oznacza to, że wybrano pliki, których ostatnio zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość data/godzina, ale modifiedDatetimeStart ma wartość NULL, oznacza to, że pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość daty/godziny, są zaznaczone. |
Nie. |
| modifiedDatetimeEnd | Filtr plików na podstawie atrybutu Ostatnia modyfikacja. Pliki są wybierane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie "2018-12-01T05:00:00Z". Ogólna wydajność przenoszenia danych ma wpływ na włączenie tego ustawienia, gdy chcesz filtrować pliki z ogromnymi ilościami plików. Właściwości mogą mieć wartość NULL, co oznacza, że do zestawu danych nie jest stosowany filtr atrybutu pliku. Jeśli modifiedDatetimeStart ma wartość typu data/godzina, ale modifiedDatetimeEnd ma wartość NULL, oznacza to, że wybrano pliki, których ostatnio zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość data/godzina, ale modifiedDatetimeStart ma wartość NULL, oznacza to, że pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość daty/godziny, są zaznaczone. |
Nie. |
| format | Jeśli chcesz skopiować pliki w postaci między magazynami opartymi na plikach (kopiowanie binarne), pomiń sekcję formatowania zarówno w definicjach zestawu danych wejściowych, jak i wyjściowych. Jeśli chcesz przeanalizować lub wygenerować pliki w określonym formacie, obsługiwane są następujące typy formatów plików: TextFormat, JsonFormat, AvroFormat, OrcFormat i ParquetFormat. Ustaw właściwość type w formacie na jedną z tych wartości. Aby uzyskać więcej informacji, zobacz sekcje Format tekstu, Format JSON, Format Avro, FORMAT ORC i Parquet Format. |
Nie (tylko w scenariuszu kopiowania binarnego) |
| kompresja | Określ typ i poziom kompresji danych. Aby uzyskać więcej informacji, zobacz Obsługiwane formaty plików i koderów kompresji. Obsługiwane typy to **GZip**, **Deflate**, **BZip2**, and **ZipDeflate**.Obsługiwane poziomy są optymalne i najszybsze. |
Nie. |
Napiwek
Aby skopiować wszystkie pliki w folderze, określ tylko folderPath .
Aby skopiować pojedynczy plik o podanej nazwie, określ folderPath ze częścią folderu i fileName nazwą pliku.
Aby skopiować podzbiór plików w folderze, określ folderPath ze częścią folderu i fileName z filtrem wieloznacznymi.
Przykład:
{
"name": "ADLSGen2Dataset",
"properties": {
"type": "AzureBlobFSFile",
"linkedServiceName": {
"referenceName": "<Azure Data Lake Storage Gen2 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "myfilesystem/myfolder",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Starszy model źródła działania kopiowania
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na Wartość AzureBlobFSSource. | Tak |
| Cykliczne | Wskazuje, czy dane są odczytywane rekursywnie z podfolderów, czy tylko z określonego folderu. Gdy rekursywna jest ustawiona na wartość true, a ujście jest magazynem opartym na plikach, pusty folder lub podfolder nie jest kopiowany ani tworzony w ujściu. Dozwolone wartości to true (wartość domyślna) i false. |
Nie. |
| maxConcurrentConnections | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Przykład:
"activities":[
{
"name": "CopyFromADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<ADLS Gen2 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureBlobFSSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Starszy model ujścia działania kopiowania
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type ujścia działania kopiowania musi być ustawiona na Wartość AzureBlobFSSink. | Tak |
| copyBehavior | Definiuje zachowanie kopiowania, gdy źródłem są pliki z magazynu danych opartego na plikach. Dozwolone wartości to: - PreserveHierarchy (wartość domyślna): Zachowuje hierarchię plików w folderze docelowym. Ścieżka względna pliku źródłowego do folderu źródłowego jest identyczna ze ścieżką względną pliku docelowego do folderu docelowego. - FlattenHierarchy: Wszystkie pliki z folderu źródłowego znajdują się na pierwszym poziomie folderu docelowego. Pliki docelowe mają automatycznie wygenerowane nazwy. - MergeFiles: Scala wszystkie pliki z folderu źródłowego do jednego pliku. Jeśli określono nazwę pliku, scalona nazwa pliku jest określoną nazwą. W przeciwnym razie jest to automatycznie wygenerowana nazwa pliku. |
Nie. |
| maxConcurrentConnections | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Przykład:
"activities":[
{
"name": "CopyToADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ADLS Gen2 output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureBlobFSSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Przechwytywanie danych dotyczących zmian
Usługa Azure Data Factory może pobrać nowe lub zmienione pliki tylko z usługi Azure Data Lake Storage Gen2, włączając włączanie przechwytywania zmian danych w przekształceniu źródła przepływu danych mapowania. Dzięki tej opcji łącznika można odczytywać tylko nowe lub zaktualizowane pliki i stosować przekształcenia przed załadowaniem przekształconych danych do docelowych zestawów danych.
Upewnij się, że nazwa potoku i działania pozostaje niezmieniona, aby zawsze można było rejestrować punkt kontrolny z ostatniego uruchomienia w celu pobrania zmian z tego miejsca. Jeśli zmienisz nazwę potoku lub nazwę działania, punkt kontrolny zostanie zresetowany i rozpoczniesz od początku w następnym uruchomieniu.
Podczas debugowania potoku działa również opcja Włącz przechwytywanie danych zmian. Pamiętaj, że punkt kontrolny zostanie zresetowany podczas odświeżania przeglądarki podczas uruchamiania debugowania. Po zadowoleniu z wyniku przebiegu debugowania możesz opublikować i wyzwolić potok. Zawsze zaczyna się od początku niezależnie od poprzedniego punktu kontrolnego zarejestrowanego przez przebieg debugowania.
W sekcji monitorowania zawsze masz możliwość ponownego uruchomienia potoku. W ten sposób zmiany są zawsze wprowadzane z rekordu punktu kontrolnego w wybranym przebiegu potoku.
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz Obsługiwane magazyny danych.