Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym samouczku utworzysz fabrykę danych za pomocą witryny Azure Portal. Następnie użyj narzędzia do kopiowania danych, aby utworzyć potok, który kopiuje dane z usługi Azure Blob Storage do usługi SQL Database.
Uwaga
Jeśli jesteś nowym użytkownikiem usługi Azure Data Factory, zobacz Wprowadzenie do usługi Azure Data Factory.
Ten samouczek obejmuje wykonanie następujących kroków:
- Tworzenie fabryki danych.
- Tworzenie potoku za pomocą narzędzia do kopiowania danych.
- Monitorowanie uruchomień potoku i działań.
Wymagania wstępne
- Subskrypcja platformy Azure: jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
- Konto usługi Azure Storage: użyj usługi Blob Storage jako źródłowego magazynu danych. Jeśli nie masz konta usługi Azure Storage, zapoznaj się z instrukcjami w temacie Tworzenie konta magazynu.
- Azure SQL Database: użyj usługi SQL Database jako magazynu danych ujścia. Jeśli nie masz bazy danych SQL Database, zapoznaj się z instrukcjami w temacie Tworzenie bazy danych SQL Database.
Przygotowywanie bazy danych SQL
Zezwól usługom platformy Azure na dostęp do logicznego programu SQL Server usługi Azure SQL Database.
Sprawdź, czy ustawienie Zezwalaj usługom i zasobom platformy Azure na dostęp do tego serwera jest włączone dla serwera z uruchomioną usługą SQL Database. To ustawienie umożliwia usłudze Data Factory zapisywanie danych w danym wystąpieniu bazy danych. Aby zweryfikować i włączyć to ustawienie, przejdź do pozycji Logiczne zapory zabezpieczeń i sieci wirtualne serwera > SQL ustaw > w pozycji >.
Uwaga
Opcja Zezwalaj usługom i zasobom platformy Azure na dostęp do tego serwera umożliwia dostęp sieciowy do programu SQL Server z dowolnego zasobu platformy Azure, a nie tylko tych w ramach subskrypcji. Może to nie być odpowiednie dla wszystkich środowisk, ale jest odpowiednie dla tego ograniczonego samouczka. Aby uzyskać więcej informacji, zobacz Reguły zapory programu Azure SQL Server. Zamiast tego możesz użyć prywatnych punktów końcowych, aby nawiązać połączenie z usługami PaaS platformy Azure bez korzystania z publicznych adresów IP.
Tworzenie obiektu blob i tabeli SQL
Przygotuj usługę Blob Storage i usługę SQL Database na potrzeby samouczka, wykonując następujące kroki.
Tworzenie źródłowego obiektu Blob
Uruchom program Notatnik. Skopiuj poniższy tekst i zapisz go na dysku w pliku o nazwie inputEmp.txt:
FirstName|LastName John|Doe Jane|DoeUtwórz kontener o nazwie adfv2tutorial i przekaż plik inputEmp.txt do kontenera. Do wykonywania tych zadań można użyć witryny Azure Portal lub różnych narzędzi, takich jak Eksplorator usługi Azure Storage.
Tworzenie tabeli SQL ujścia
Użyj następującego skryptu SQL, aby utworzyć tabelę o nazwie
dbo.empw usłudze SQL Database:CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Tworzenie fabryki danych
W górnym menu wybierz pozycję Utwórz zasób>Analityka>Fabryka Danych :
Na stronie Nowa fabryka danych w polu Nazwa wprowadź wartość ADFTutorialDataFactory.
Nazwa Twojej fabryki danych musi być globalnie unikatowa. Może zostać wyświetlony następujący komunikat o błędzie:
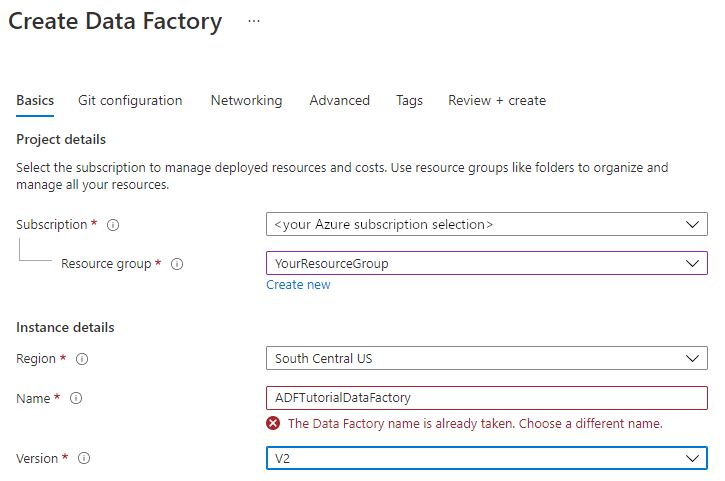
Jeśli zostanie wyświetlony komunikat o błędzie dotyczącym wartości nazwy, wprowadź inną nazwę dla fabryki danych. Na przykład użyj nazwy twojanazwaADFTutorialDataFactory. Artykuł Data Factory naming rules (Zasady nazewnictwa fabryki danych) zawiera zasady nazewnictwa artefaktów usługi Data Factory.
Wybierz subskrypcję platformy Azure, w której utworzysz nową fabrykę danych.
W obszarze Grupa zasobów wykonaj jedną z następujących czynności:
a. Wybierz pozycję Użyj istniejącej, a następnie wybierz istniejącą grupę zasobów z listy rozwijanej.
b. Wybierz pozycję Utwórz nową, a następnie wprowadź nazwę grupy zasobów.
Informacje na temat grup zasobów znajdują się w artykule Using resource groups to manage your Azure resources (Używanie grup zasobów do zarządzania zasobami platformy Azure).
W obszarze Wersja wybierz wersję V2.
W obszarze lokalizacja wybierz lokalizację fabryki danych. Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (np. usługi Azure Storage i SQL Database) oraz jednostki obliczeniowe (np. usługa Azure HDInsight) używane przez Twoją fabrykę danych mogą mieścić się w innych lokalizacjach i regionach.
Wybierz pozycję Utwórz.
Po zakończeniu tworzenia zostanie wyświetlona strona główna usługi Data Factory.

Aby uruchomić interfejs użytkownika usługi Azure Data Factory na osobnej karcie, wybierz pozycję Otwórz na kafelku Otwórz usługę Azure Data Factory Studio .
Tworzenie potoku za pomocą narzędzia do kopiowania danych
Na stronie głównej usługi Azure Data Factory wybierz kafelek Pozyskiwanie , aby uruchomić narzędzie do kopiowania danych.
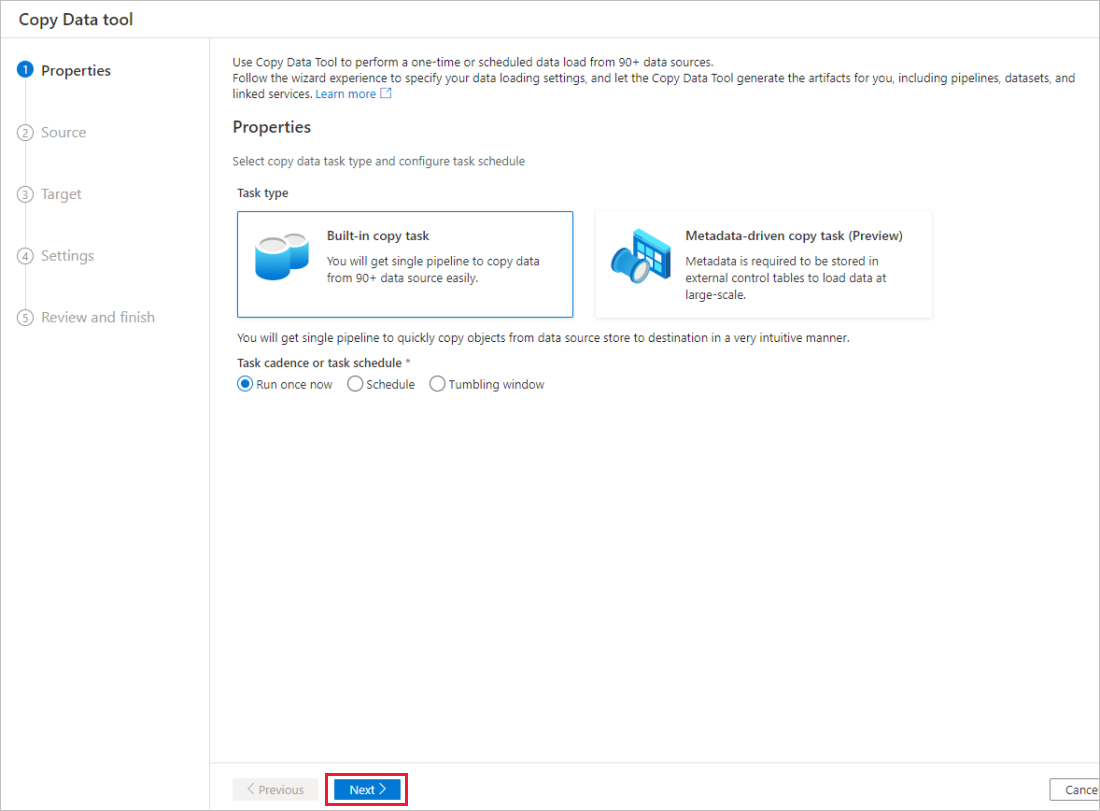
Na stronie Właściwości narzędzia do kopiowania danych wybierz pozycję Wbudowane zadanie kopiowania w obszarze Typ zadania, a następnie wybierz pozycję Dalej.
Na stronie Źródłowy magazyn danych wykonaj następujące czynności:
a. Wybierz pozycję + Utwórz nowe połączenie , aby dodać połączenie.
b. Wybierz pozycję Azure Blob Storage z galerii, a następnie wybierz pozycję Kontynuuj.
c. Na stronie Nowe połączenie (Azure Blob Storage) wybierz subskrypcję platformy Azure z listy subskrypcji platformy Azure i wybierz konto magazynu z listy Nazwa konta usługi Storage. Przetestuj połączenie, a następnie wybierz pozycję Utwórz.
d. Wybierz nowo utworzoną połączoną usługę jako źródło w bloku Połączenie .
e. W sekcji Plik lub folder wybierz pozycję Przeglądaj, aby przejść do folderu adfv2tutorial, wybierz plik inputEmp.txt, a następnie wybierz przycisk OK.
f. Wybierz przycisk Dalej , aby przejść do następnego kroku.
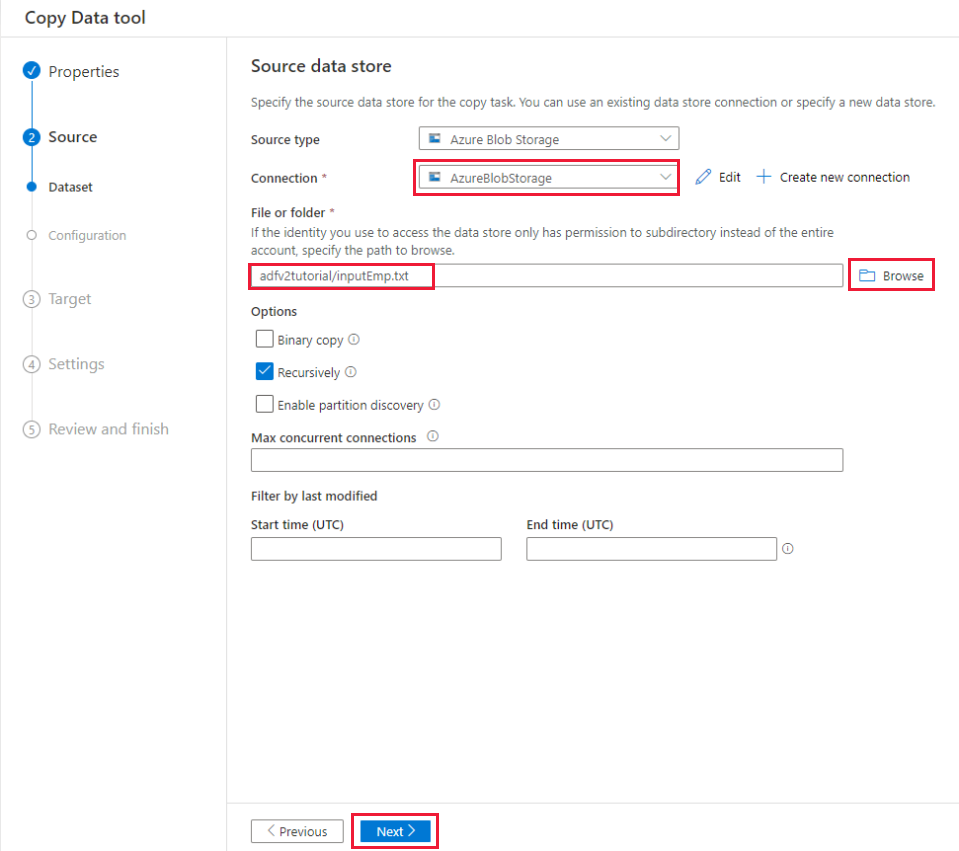
Na stronie Ustawienia formatu pliku włącz pole wyboru Pierwszy wiersz jako nagłówek. Zwróć uwagę, że narzędzie automatycznie wykrywa ograniczniki kolumn i wierszy. Możesz wyświetlić podgląd danych i wyświetlić schemat danych wejściowych, wybierając przycisk Podgląd danych na tej stronie. Następnie kliknij przycisk Dalej.
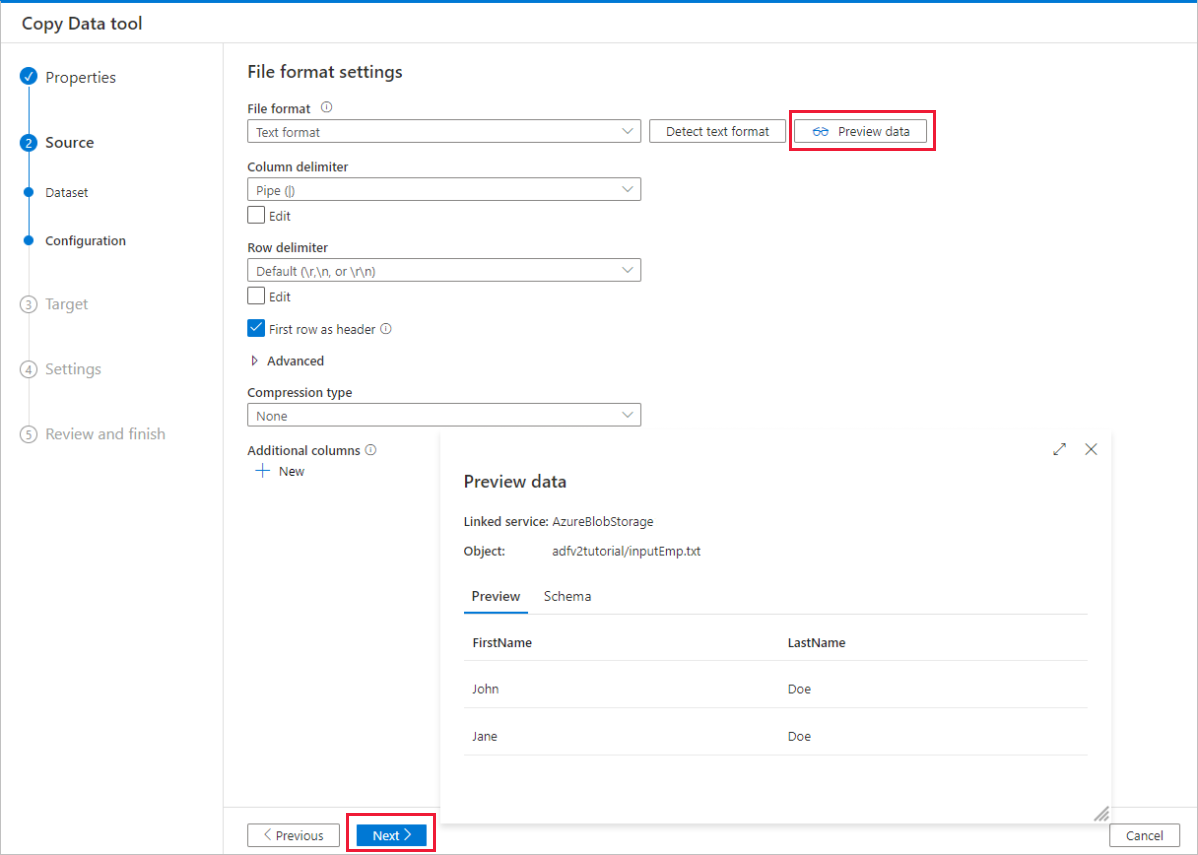
Na stronie Docelowy magazyn danych wykonaj następujące czynności:
a. Wybierz pozycję + Utwórz nowe połączenie , aby dodać połączenie.
b. Wybierz pozycję Azure SQL Database z galerii, a następnie wybierz pozycję Kontynuuj.
c. Na stronie Nowe połączenie (Azure SQL Database) wybierz swoją subskrypcję platformy Azure, nazwę serwera i nazwę bazy danych z listy rozwijanej. Następnie wybierz pozycję Uwierzytelnianie SQL w obszarze Typ uwierzytelniania, określ nazwę użytkownika i hasło. Przetestuj połączenie i wybierz pozycję Utwórz.
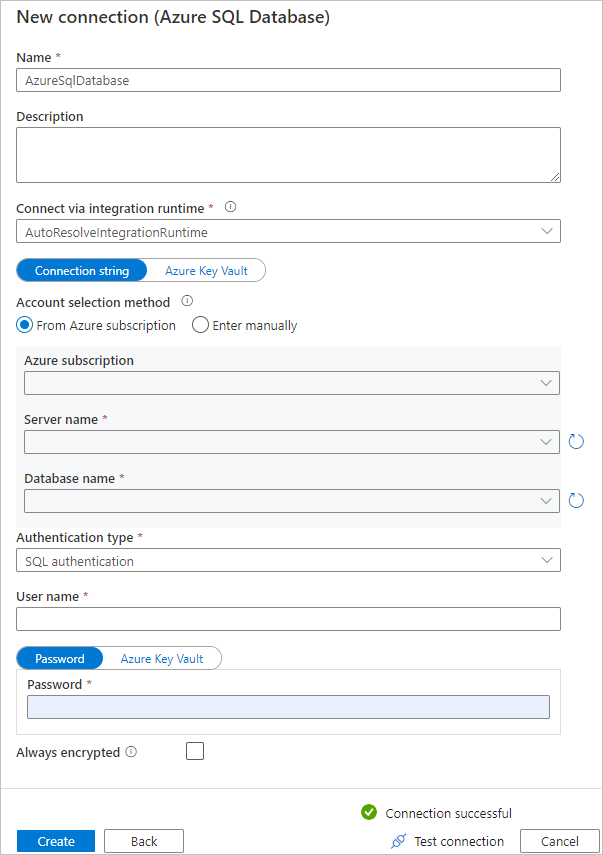
d. Wybierz nowo utworzoną połączoną usługę jako ujście, a następnie wybierz pozycję Dalej.
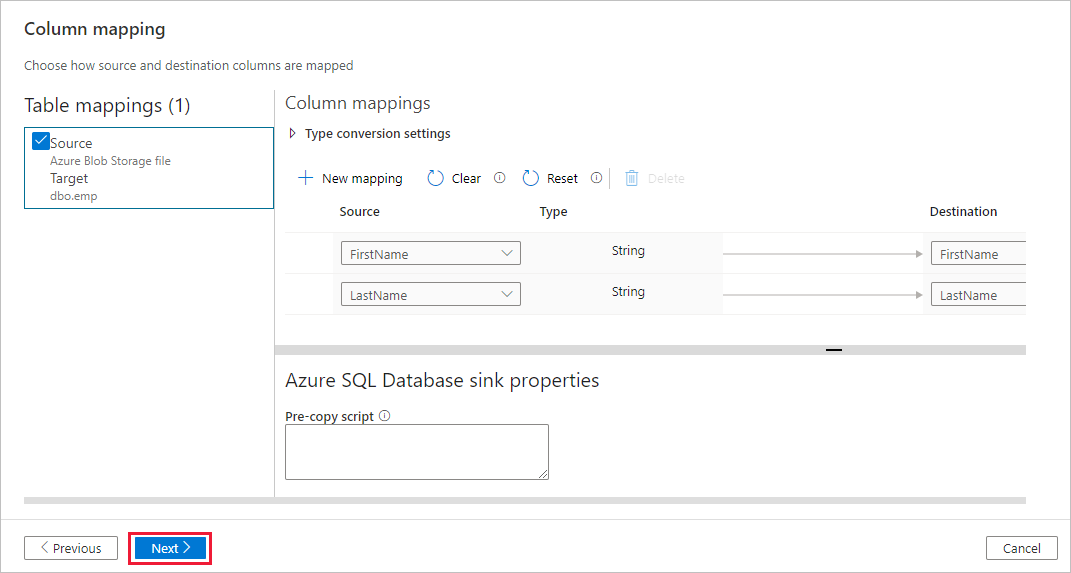
Na stronie Docelowy magazyn danych wybierz pozycję Użyj istniejącej tabeli i wybierz tabelę
dbo.emp. Następnie kliknij przycisk Dalej.Na stronie Mapowanie kolumn zwróć uwagę, że druga i trzecia kolumna w pliku wejściowym są mapowane na kolumny FirstName i LastName tabeli emp. Dostosuj mapowanie, aby upewnić się, że nie ma błędu, a następnie wybierz przycisk Dalej.
Na stronie Ustawienia w obszarze Nazwa zadania wprowadź wartość CopyFromBlobToSqlPipeline, a następnie wybierz pozycję Dalej.
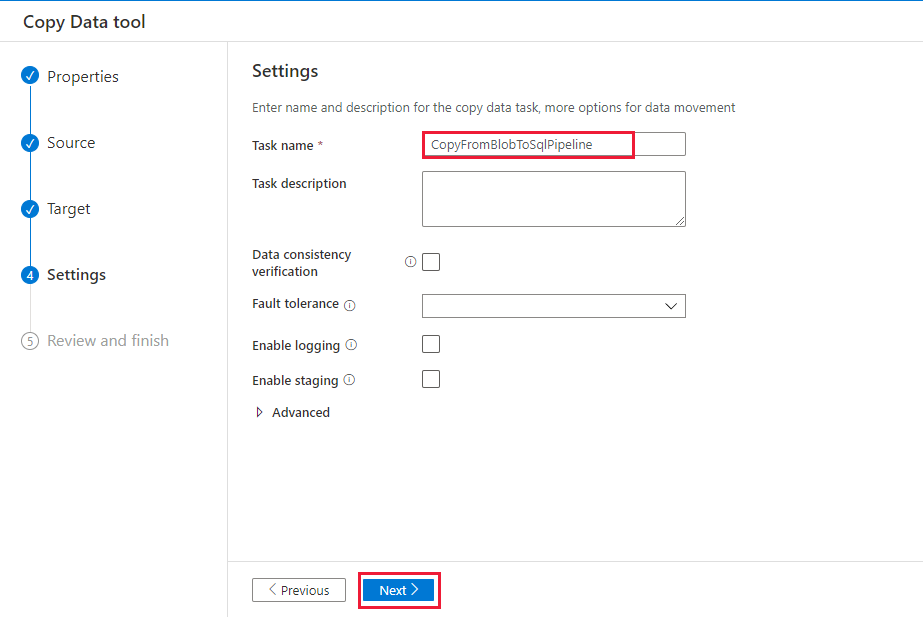
Na stronie Podsumowanie sprawdź ustawienia, a następnie kliknij przycisk Dalej.
Na stronie Wdrażanie wybierz pozycję Monitorowanie, aby monitorować potok (zadanie).
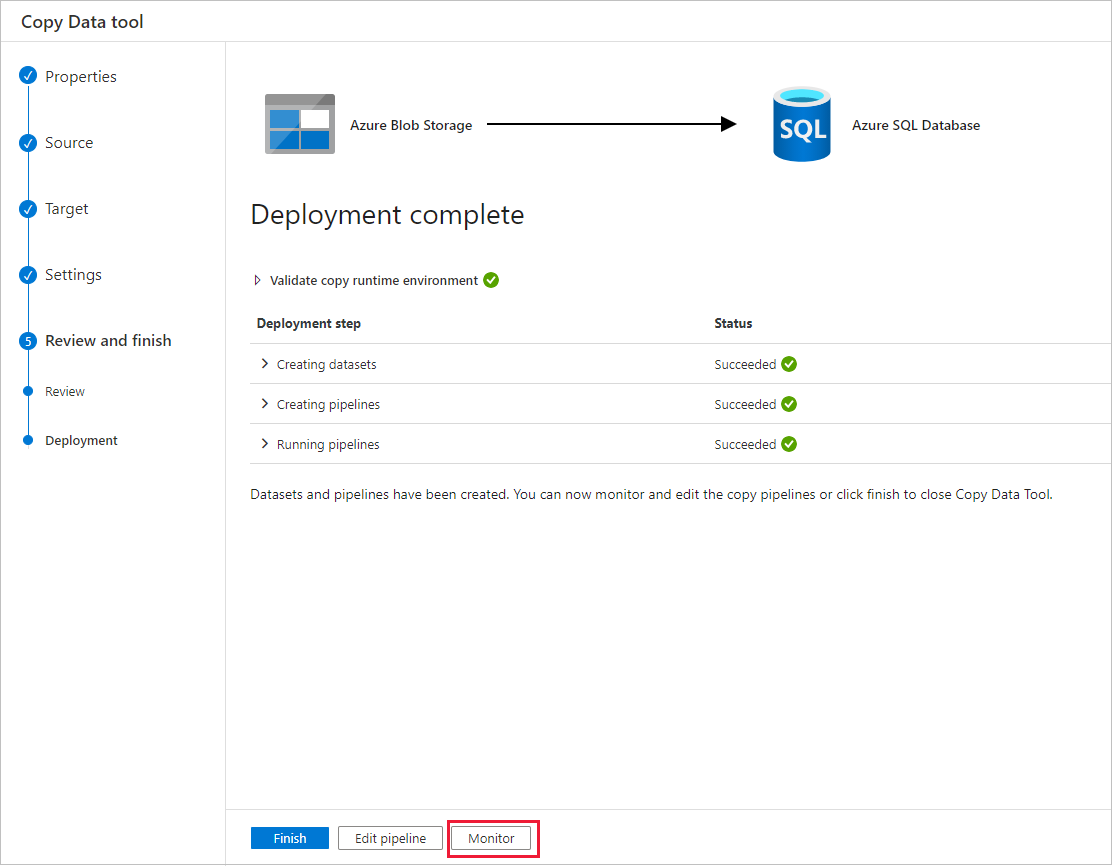
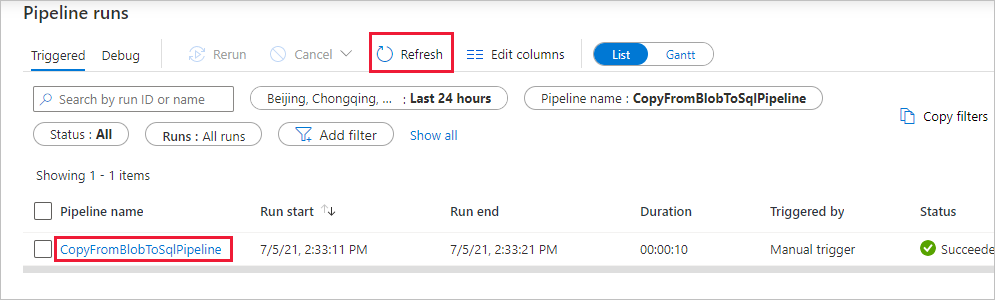
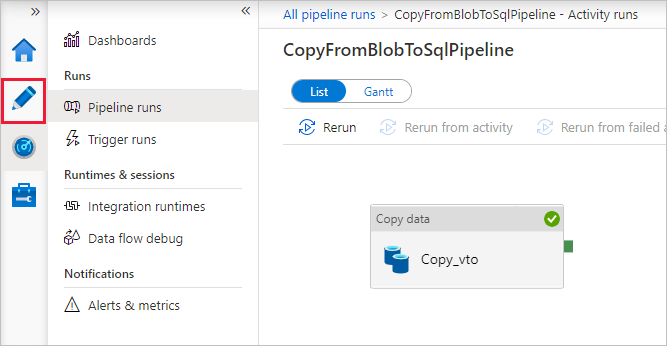
Na stronie Uruchomienia potoku wybierz pozycję Odśwież , aby odświeżyć listę. Wybierz link w obszarze Nazwa potoku, aby wyświetlić szczegóły przebiegu działania lub ponownie uruchomić potok.
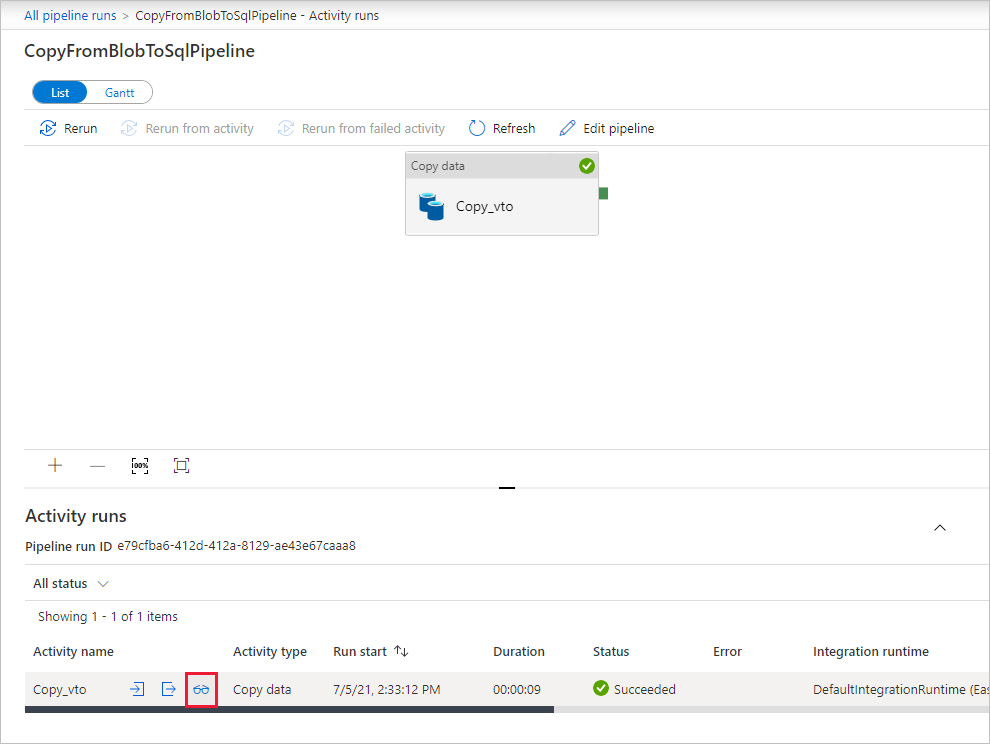
Na stronie "Uruchomienia działań" wybierz link Szczegóły (ikona okularów) w kolumnie Nazwa działania, aby uzyskać więcej informacji na temat operacji kopiowania. Aby wrócić do widoku "Uruchomienia potoku", wybierz link Wszystkie uruchomienia potoku w menu stron nadrzędnych. Aby odświeżyć widok, wybierz pozycję Odśwież.
Sprawdź, czy dane są wstawione do tabeli dbo.emp w usłudze SQL Database.
Wybierz kartę Autor po lewej stronie, aby przełączyć się w tryb edytora. Za pomocą edytora można zaktualizować usługi połączone, zestawy danych i potoki utworzone przez narzędzie. Aby uzyskać szczegółowe informacje dotyczące edytowania tych jednostek w interfejsie użytkownika usługi Data Factory, zobacz wersję witryny Azure Portal używaną w tym samouczku.
Powiązana zawartość
Potok w tym przykładzie kopiuje dane z usługi Blob Storage do usługi SQL Database. W tym samouczku omówiono:
- Tworzenie fabryki danych.
- Tworzenie potoku za pomocą narzędzia do kopiowania danych.
- Monitorowanie uruchomień potoku i działań.
Aby dowiedzieć się, jak kopiować dane ze środowiska lokalnego do chmury, przejdź do następującego samouczka: