Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Przepływy danych są dostępne zarówno w potokach Azure Data Factory, jak i w potokach Azure Synapse Analytics. Ten artykuł dotyczy przepływów danych mapowania. Jeśli dopiero zaczynasz z przekształceń danych, zapoznaj się z artykułem wprowadzającym Przekształcanie danych przy użyciu przepływów mapowania danych.
Wskazówka
Aby uzyskać równoważną transformację (Reference) w przepływie danych Gen2, zobacz Przewodnik po Gen2 przepływie danych dla użytkowników mapowania przepływu danych.
Warunkowy podział kieruje wiersze danych na różne strumienie w oparciu o spełnione warunki. Transformacja podziału warunkowego jest podobna do struktury decyzyjnej CASE w języku programowania. Przekształcenie oblicza wyrażenia i na podstawie wyników kieruje wiersz danych do określonego strumienia.
Konfigurowanie
Ustawienie Podziel według określa, czy wiersz danych przepływa do pierwszego pasującego strumienia, czy do każdego pasującego strumienia.
Użyj konstruktora wyrażeń przepływu danych, aby wprowadzić wyrażenie dla warunku podziału. Aby dodać nowy warunek, kliknij ikonę znaku plus w istniejącym wierszu. Można również dodać strumień domyślny dla wierszy, które nie są zgodne z żadnym warunkiem.
Skrypt przepływu danych
Składnia
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
Przykład
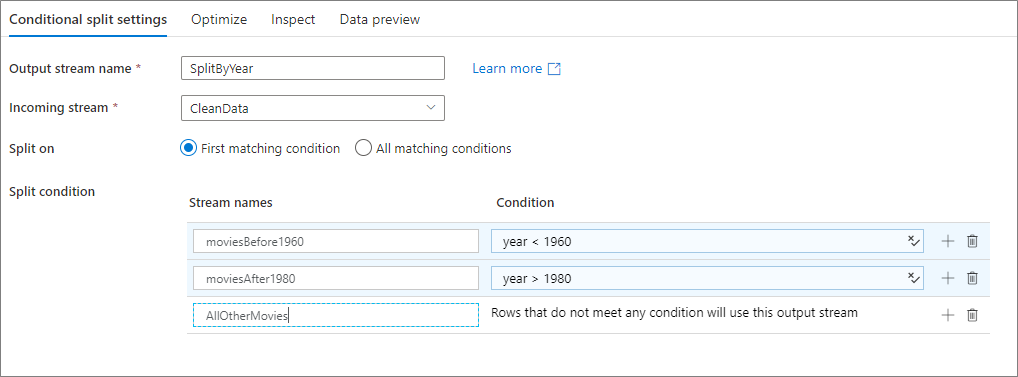
Poniższy przykład to warunkowa transformacja podziału o nazwie SplitByYear, która przyjmuje przychodzący strumień CleanData. Ta transformacja ma dwa podziału warunki year < 1960 i year > 1980.
disjoint jest fałszywy, ponieważ dane przechodzą do pierwszego pasującego warunku, a nie do wszystkich pasujących warunków. Każdy wiersz pasujący do pierwszego warunku przechodzi do strumienia moviesBefore1960wyjściowego . Wszystkie pozostałe wiersze pasujące do drugiego warunku przechodzą do strumienia moviesAFter1980wyjściowego . Wszystkie inne wiersze przepływają przez strumień AllOtherMoviesdomyślny .
W interfejsie użytkownika usługi ta transformacja wygląda jak na poniższej ilustracji:
Skrypt przepływu danych dla tej transformacji znajduje się w poniższym fragmencie kodu:
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)
Powiązana zawartość
Typowe przekształcenia przepływu danych używane z podziałem warunkowym to przekształcenie sprzężenia, przekształcenie odnośnika i przekształcenie wybierania.