Przekształcenia odnośników w przepływie danych mapowania
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Przepływy danych są dostępne zarówno w usłudze Azure Data Factory, jak i w potokach usługi Azure Synapse. Ten artykuł dotyczy przepływów danych mapowania. Jeśli dopiero zaczynasz transformacje, zapoznaj się z artykułem wprowadzającym Przekształcanie danych przy użyciu przepływu danych mapowania.
Użyj przekształcenia odnośnika, aby odwołać się do danych z innego źródła w strumieniu przepływu danych. Przekształcenie odnośnika dołącza kolumny z dopasowanych danych do danych źródłowych.
Przekształcenie odnośnika jest podobne do lewego sprzężenia zewnętrznego. Wszystkie wiersze ze strumienia podstawowego będą istnieć w strumieniu wyjściowym z dodatkowymi kolumnami ze strumienia odnośników.
Konfigurowanie
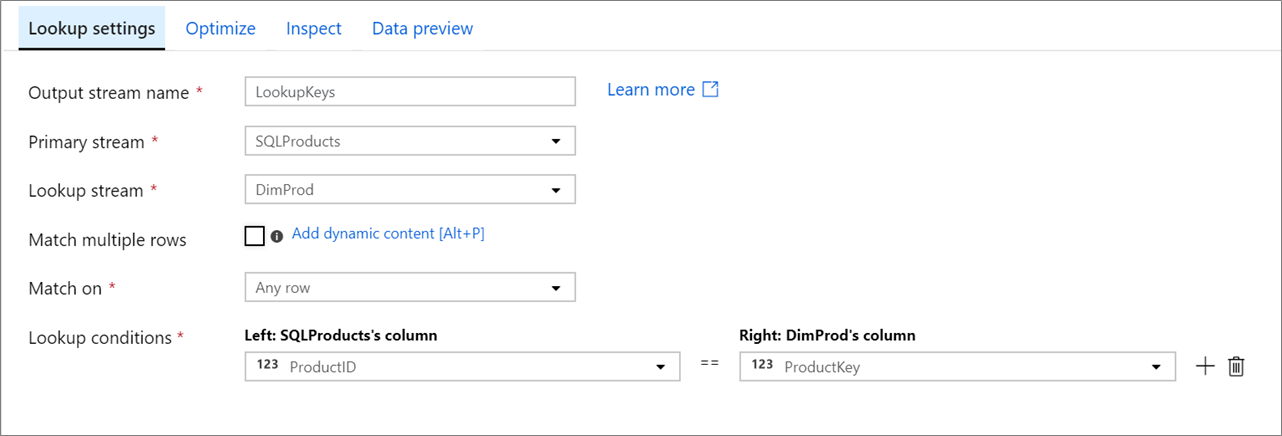
Strumień podstawowy: przychodzący strumień danych. Ten strumień jest odpowiednikiem lewej strony sprzężenia.
Strumień odnośnika: dane dołączone do strumienia podstawowego. Które dane są dodawane, są określane przez warunki wyszukiwania. Ten strumień jest odpowiednikiem prawej strony sprzężenia.
Dopasuj wiele wierszy: jeśli jest włączona, wiersz z wieloma dopasowaniami w strumieniu podstawowym zwróci wiele wierszy. W przeciwnym razie zostanie zwrócony tylko jeden wiersz na podstawie warunku "Dopasuj do".
Dopasowanie do: widoczne tylko wtedy, gdy opcja "Dopasuj wiele wierszy" nie jest zaznaczona. Wybierz, czy mają być zgodne w dowolnym wierszu, pierwszym dopasowaniu, czy ostatnim meczu. Każdy wiersz jest zalecany, ponieważ wykonuje najszybszy. Jeśli wybrano pierwszy wiersz lub ostatni wiersz, musisz określić warunki sortowania.
Warunki wyszukiwania: wybierz kolumny do dopasowania. Jeśli warunek równości zostanie spełniony, wiersze zostaną uznane za zgodne. Zatrzymaj wskaźnik myszy i wybierz pozycję "Obliczona kolumna", aby wyodrębnić wartość przy użyciu języka wyrażeń przepływu danych.
Wszystkie kolumny z obu strumieni są uwzględniane w danych wyjściowych. Aby usunąć zduplikowane lub niechciane kolumny, dodaj transformację wybierania po przekształceniu odnośnika. Kolumny mogą być również porzucane lub zmieniane w transformacji ujścia.
Sprzężenia inne niż równocze
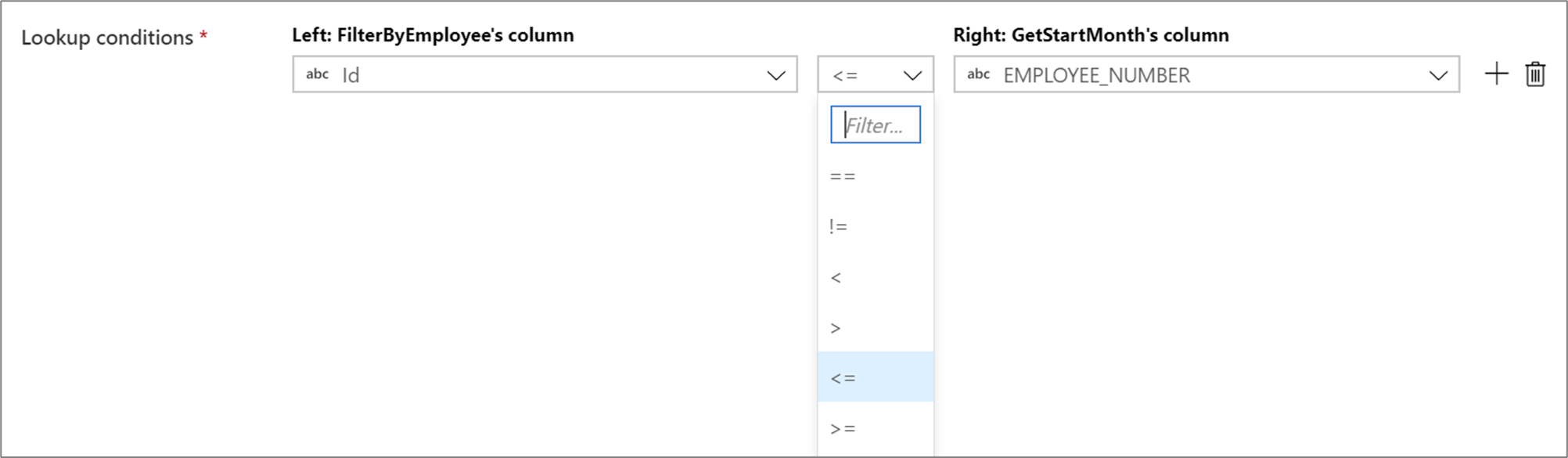
Aby użyć operatora warunkowego, takiego jak nie równe (!=) lub większe niż (>) w warunkach wyszukiwania, zmień listę rozwijaną operatora między dwiema kolumnami. Sprzężenia inne niż równoważne wymagają emisji co najmniej jednego z dwóch strumieni przy użyciu emisji stałej na karcie Optymalizacja .
Analizowanie dopasowanych wierszy
Po przekształceniu odnośnika funkcja isMatch() może służyć do sprawdzenia, czy wyszukiwanie jest dopasowane do poszczególnych wierszy.
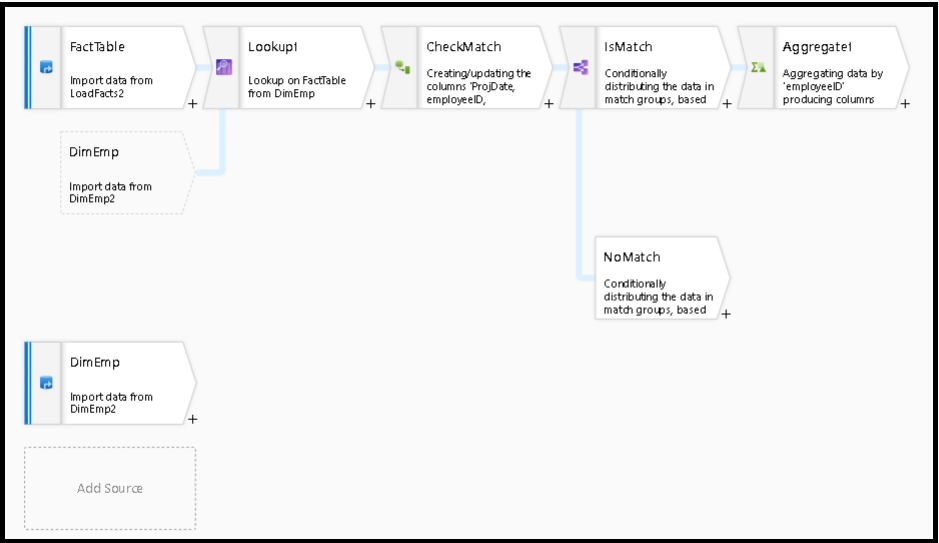
Przykładem tego wzorca jest użycie warunkowego przekształcenia podziału w celu podzielenia isMatch() funkcji. W powyższym przykładzie pasujące wiersze przechodzą przez górny strumień i nie pasujące wiersze przepływają przez NoMatch strumień.
Testowanie warunków wyszukiwania
Podczas testowania transformacji wyszukiwania za pomocą podglądu danych w trybie debugowania użyj małego zestawu znanych danych. Podczas próbkowania wierszy z dużego zestawu danych nie można przewidzieć, które wiersze i klucze będą odczytywane do testowania. Wynik nie jest deterministyczny, co oznacza, że warunki sprzężenia mogą nie zwracać żadnych dopasowań.
Optymalizacja emisji
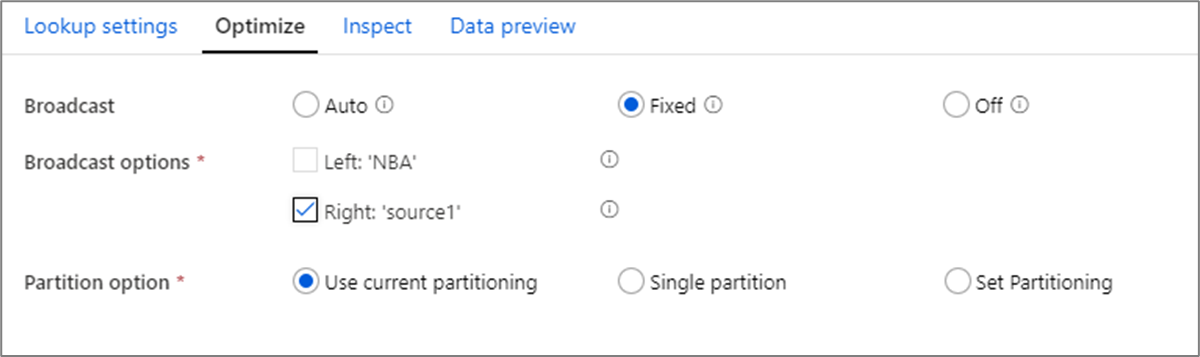
W sprzężeniach wyszukiwanie i istnieje transformacja, jeśli jeden lub oba strumienie danych mieszczą się w pamięci węzła procesu roboczego, możesz zoptymalizować wydajność, włączając funkcję Emisja. Domyślnie aparat spark automatycznie zdecyduje, czy emitować jedną stronę. Aby ręcznie wybrać stronę do emisji, wybierz pozycję Naprawiono.
Nie zaleca się wyłączania emisji za pośrednictwem opcji Wyłącz , chyba że sprzężenia występują błędy przekroczenia limitu czasu.
Buforowane wyszukiwanie
Jeśli wykonujesz wiele mniejszych odnośników w tym samym źródle, ujście buforowane i wyszukiwanie może być lepszym przypadkiem użycia niż transformacja odnośnika. Typowe przykłady, w których ujście pamięci podręcznej może być lepsze, to wyszukanie maksymalnej wartości w magazynie danych i dopasowanie kodów błędów do bazy danych komunikatów o błędach. Aby uzyskać więcej informacji, dowiedz się więcej o ujściach pamięci podręcznej i buforowanych odnośnikach.
Skrypt przepływu danych
Składnia
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
Przykład
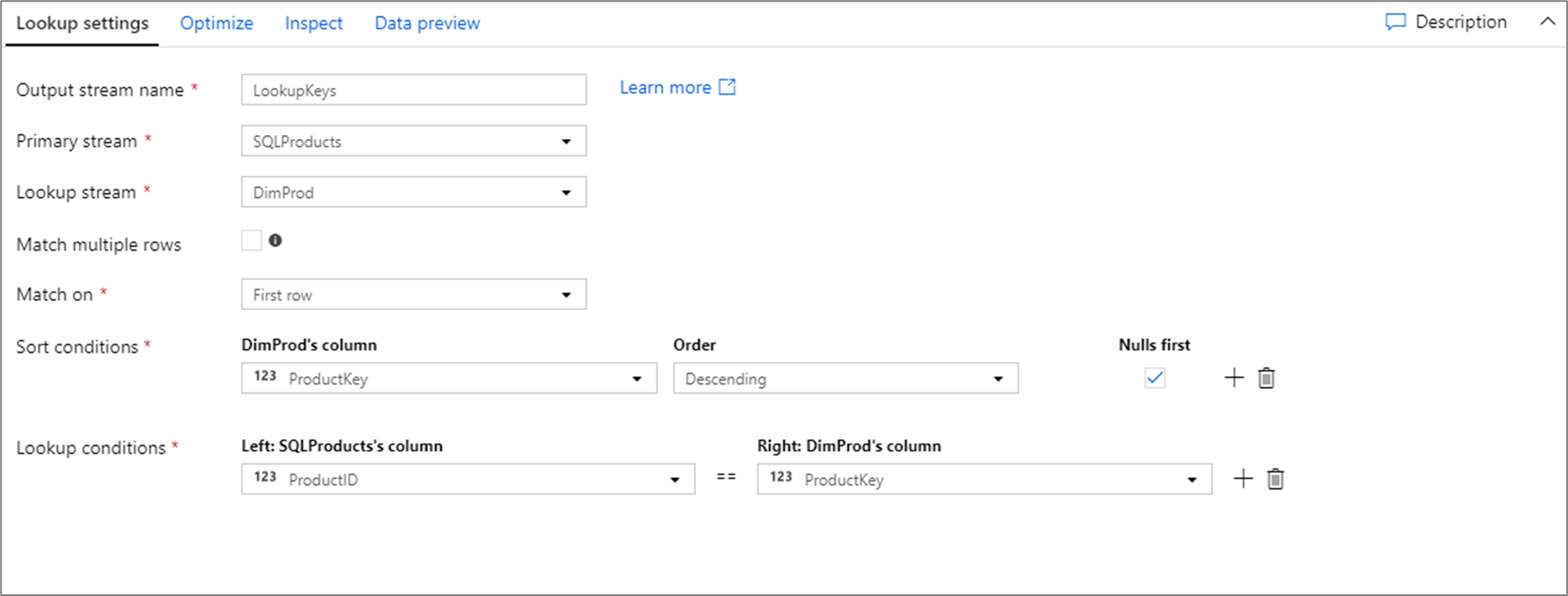
Skrypt przepływu danych dla powyższej konfiguracji odnośnika znajduje się w poniższym fragmencie kodu.
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys
Powiązana zawartość
- Sprzężenia i istnieją przekształcenia przyjmują wiele danych wejściowych strumienia
- Używanie warunkowego przekształcenia podziału z
isMatch(), aby podzielić wiersze na pasujące i niezgodne wartości
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla