Konfigurowanie własnego środowiska Integration Runtime (SHIR) na potrzeby zbierania danych usługi Log Analytics
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Wymagania wstępne
W tym podejściu jest wymagany dostępny obszar roboczy usługi Log Analytics. Zalecamy zanotowanie identyfikatora obszaru roboczego i klucza uwierzytelniania obszaru roboczego usługi Log Analytics, ponieważ może być potrzebne w niektórych scenariuszach. To rozwiązanie zwiększy dane, które zostaną wysłane do obszaru roboczego usługi Log Analytics i będzie miało niewielki wpływ na całkowity koszt. Przeczytaj, aby uzyskać szczegółowe informacje na temat utrzymywania ilości danych do minimum.
Cele i scenariusze
Scentralizowanie zdarzeń i danych licznika wydajności w obszarze roboczym usługi Log Analytics, najpierw maszyna wirtualna hostująca SHIR musi być odpowiednio instrumentowana. Wybierz między dwoma głównymi scenariuszami poniżej.
Instrumentacja lokalnych maszyn wirtualnych
W artykule Instalowanie agenta usługi Log Analytics na komputerach z systemem Windows opisano sposób instalowania klienta na maszynie wirtualnej zwykle hostowanej lokalnie. Może to być serwer fizyczny lub maszyna wirtualna hostowana w funkcji hypervisor zarządzanej przez klienta. Jak wspomniano w sekcji wymagań wstępnych, podczas instalowania agenta usługi Log Analytics należy podać identyfikator obszaru roboczego usługi Log Analytics i klucz obszaru roboczego, aby sfinalizować połączenie.
Instrumentacja maszyn wirtualnych platformy Azure
Zalecane podejście do instrumentacji SHIR opartej na maszynie wirtualnej platformy Azure polega na używaniu szczegółowych informacji o maszynach wirtualnych zgodnie z opisem w artykule Włączanie szczegółowych informacji o maszynach wirtualnych. Istnieje wiele sposobów konfigurowania agenta usługi Log Analytics, gdy środowisko SHIR jest hostowane na maszynie wirtualnej platformy Azure. Wszystkie opcje zostały opisane w artykule Omówienie agenta usługi Log Analytics.
Konfigurowanie przechwytywania dziennika zdarzeń i licznika wydajności
W tym kroku przedstawiono sposób konfigurowania dzienników podglądu zdarzeń i liczników wydajności, które mają być wysyłane do usługi Log Analytics. Kroki opisane poniżej są typowe niezależnie od sposobu wdrożenia agenta.
Wybieranie dzienników podglądu zdarzeń
Najpierw należy zebrać dzienniki podglądu zdarzeń związane z usługą SHIR zgodnie z opisem w artykule Zbieranie źródeł danych dziennika zdarzeń systemu Windows za pomocą agenta usługi Log Analytics w usłudze Azure Monitor.
Należy pamiętać, że podczas wybierania dzienników zdarzeń przy użyciu interfejsu normalne jest, że nie zobaczysz wszystkich dzienników, które mogą istnieć na maszynie. Tak więc dwa dzienniki, których potrzebujemy do monitorowania SHIR, nie będą wyświetlane na tej liście. Jeśli wpiszesz nazwę dziennika dokładnie tak, jak na lokalnej maszynie wirtualnej, zostanie ona przechwycona i wysłana do obszaru roboczego usługi Log Analytics.
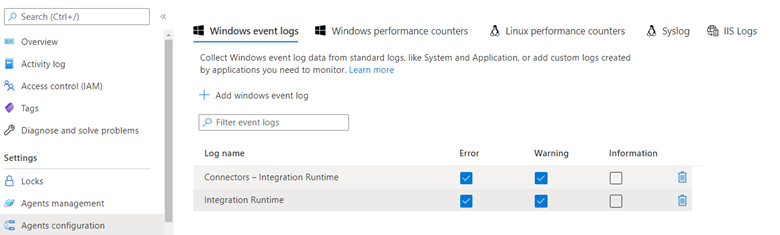
Nazwa dziennika zdarzeń, który musimy skonfigurować, to:
- Połączenie ors — Integration Runtime
- Środowisko Integration Runtime
Ważne
Pozostawienie zaznaczonego poziomu informacji znacznie zwiększy ilość danych, jeśli wdrożono wiele hostów SHIR i większą liczbę skanowań. Zdecydowanie zalecamy zachowanie tylko błędów i ostrzeżeń.
Wybieranie liczników wydajności
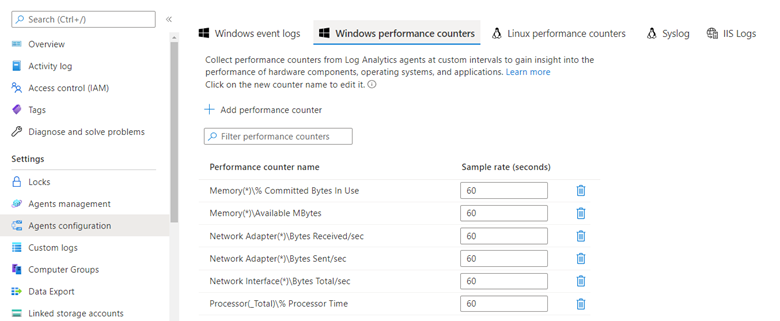
W tym samym okienku konfiguracji możesz kliknąć pozycję Liczniki wydajności systemu Windows, aby wybrać poszczególne liczniki wydajności, które mają być wysyłane do analizy dzienników.
Ważne
Należy pamiętać, że liczniki wydajności są ze swej natury ciągłym strumieniem danych. Dlatego ważne jest, aby wziąć pod uwagę wpływ zbierania danych na całkowity koszt wdrożenia usługi Azure Monitor/Log Analytics. O ile nie udzielono dozwolonego budżetu pozyskiwania danych, a stałe pozyskiwanie danych zostało dozwolone i budżetowane, zbieranie liczników wydajności powinno być skonfigurowane tylko dla zdefiniowanego okresu w celu ustalenia punktu odniesienia wydajności.
Podczas pierwszego konfigurowania interfejsu zaleca się sugerowany zestaw liczników. Wybierz te, które mają zastosowanie do typu analizy wydajności, którą chcesz wykonać. %CPU i Dostępna pamięć są często monitorowane liczniki, ale inne, takie jak Zużycie przepustowości sieci, mogą być przydatne w scenariuszach, w których ilość danych jest duża, a przepustowość lub czas wykonywania są ograniczone.
Wyświetlanie danych licznika zdarzeń i wydajności w usłudze Log Analytics
Zapoznaj się z tym samouczkiem dotyczącym wykonywania zapytań dotyczących danych w usłudze Log Analytics. Dwie tabele, w których są zapisywane dane telemetryczne, są nazywane odpowiednio wydajnością i zdarzeniem. Poniższe zapytanie sprawdzi liczbę wierszy, aby sprawdzić, czy dane przepływają. Potwierdziłoby to, że instrumentacja opisana powyżej działa.
Przykładowe zapytania KQL
Sprawdzanie liczby wierszy
(
Event
| extend TableName = "Event"
| summarize count() by TableName
)
| union
(
Perf
| extend TableName = "Perf"
| summarize count() by TableName
)
Zdarzenia zapytań
Pobieranie pierwszych 10 wierszy zdarzeń
Event
| take 10
Pobieranie liczby zdarzeń według ważności komunikatu
Event
| summarize count() by EventLevelName
Renderowanie wykresu kołowego liczby według ważności komunikatu
Event
| summarize count() by EventLevelName
| render piechart
Pobieranie wszystkich błędów z określonym ciągiem tekstowym
W tym miejscu wyszukujemy wszystkie komunikaty, które mają w nich rozłączone słowo.
Event
| where RenderedDescription has "disconnected"
Wyszukiwanie słów kluczowych w wielu tabelach bez znajomości schematu
Polecenie wyszukiwania jest przydatne, gdy nie wiadomo, w której kolumnie znajdują się informacje. To zapytanie zwraca wszystkie wiersze z określonych tabel, które zawierają co najmniej jedną kolumnę zawierającą termin wyszukiwania. Wyraz jest odłączony w tym przykładzie.
search in (Perf, Event) "disconnected"
Pobieranie wszystkich zdarzeń z jednego określonego dziennika
W tym przykładzie zawężamy zapytanie do dziennika o nazwie Połączenie ors — Integration Runtime.
Event
| where EventLog == "Connectors - Integration Runtime"
Użyj przedziałów czasu, aby ograniczyć wyniki zapytania
To zapytanie używa tego samego zapytania co powyżej, ale ogranicza wyniki do tych występujących 2 dni temu lub ostatnio.
Event
| where EventLog == "Connectors - Integration Runtime"
and TimeGenerated >= ago(2d)
Dane licznika wydajności zapytań
Pobieranie pierwszych 10 odczytów licznika wydajności
Perf
| take 10
Pobieranie określonego licznika z ograniczeniami czasu
Perf
| where TimeGenerated >= ago(24h)
and ObjectName == "Network Adapter"
and InstanceName == "Mellanox ConnectX-4 Lx Virtual Ethernet Adapter"
and CounterName == "Bytes Received/sec"
Liczniki wydajności mają charakter hierarchiczny, dlatego należy pamiętać, aby mieć wystarczającą liczbę predykatów w zapytaniu, aby wybrać tylko odpowiedni licznik.
Pobieranie 95. percentyla dla danego licznika binned przez 30 minut wycinków z ostatnich 24 godzin
W tym przykładzie są wszystkie liczniki dla określonej karty sieciowej.
Perf
| where TimeGenerated >= ago(24h)
and ObjectName == "Network Adapter"
and InstanceName == "Mellanox ConnectX-4 Lx Virtual Ethernet Adapter"
| project TimeGenerated, Computer, ObjectName, InstanceName, CounterName, CounterValue
| summarize percentile(CounterValue, 95) by bin(TimeGenerated, 30m), Computer, ObjectName, InstanceName, CounterName
Używanie zmiennych do ponownego użycia kodu
W tym miejscu wprowadzamy nazwę obiektu i nazwę licznika jako zmienną, więc nie musimy zmieniać treści zapytania KQL, aby później wprowadzić zmiany w tych wyborach.
let pObjectName = "Memory"; // Required to select the right counter
let pCounterName = "Available MBytes"; // Required to select the right counter
Perf
| where Type == "Perf" and ObjectName == pObjectName and CounterName == pCounterName
| project TimeGenerated, Computer, CounterName, CounterValue
| order by TimeGenerated asc
| summarize Value=max(CounterValue) by CounterName, TimeStamps=TimeGenerated