Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Uruchom potoki Azure Machine Learning jako krok w potokach Azure Data Factory i Synapse Analytics. Działanie wykonania potoku Machine Learning umożliwia scenariusze przewidywania wsadowego, takie jak identyfikowanie możliwych niewywiązań się z pożyczek, określanie nastrojów i analizowanie wzorców zachowań klientów.
Poniższy film wideo zawiera sześciominutowe wprowadzenie i pokaz tej funkcji.
Utwórz działanie potoku wykonawczego uczenia maszynowego za pomocą interfejsu użytkownika
Aby użyć aktywności 'Wykonaj potok' uczenia maszynowego w ramach potoku, wykonaj następujące kroki:
Wyszukaj Machine Learning w okienku Aktywności potoku i przeciągnij aktywność Uruchomienie potoku Machine Learning na kanwę potoku.
Wybierz nowe działanie Machine Learning Execute Pipeline na płótnie, jeśli nie jest jeszcze wybrane, oraz jego kartę Settings, aby edytować jego szczegóły.
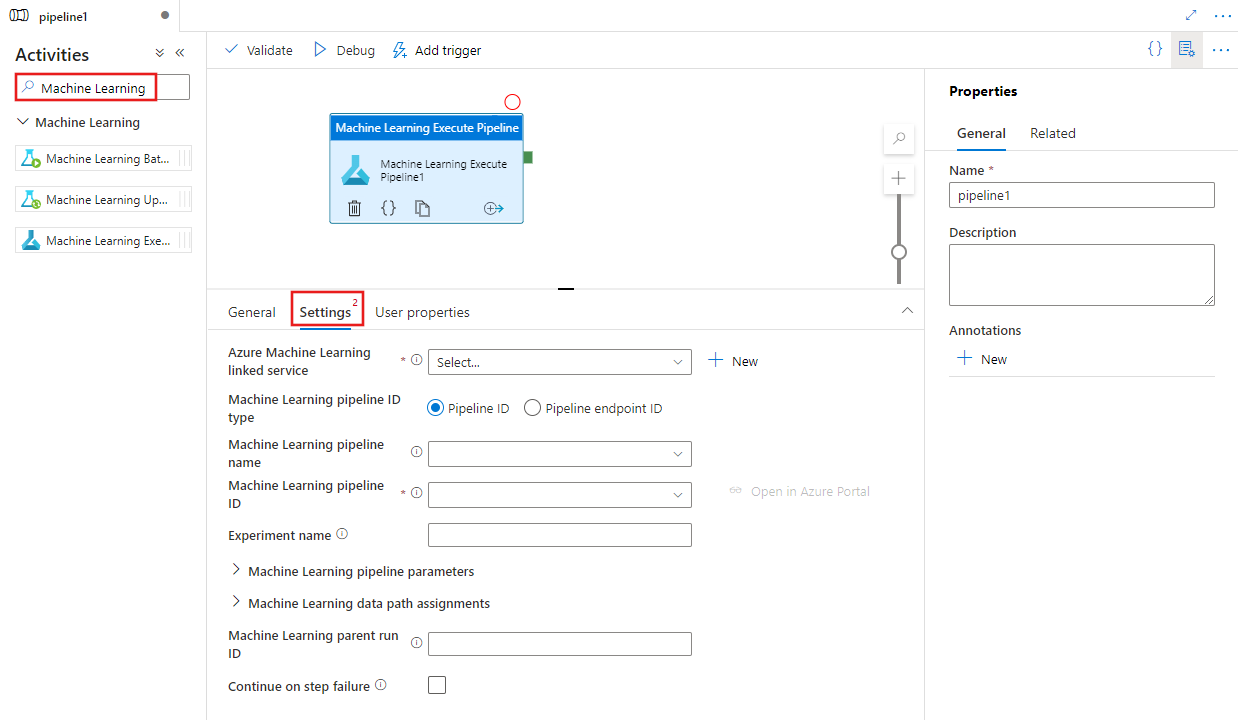
Wybierz istniejącą lub utwórz nową związaną usługę Azure Machine Learning i podaj szczegóły potoku oraz eksperymentu, a także wszelkie parametry potoku i/lub przypisania ścieżki danych wymagane dla potoku.
Składnia
{
"name": "Machine Learning Execute Pipeline",
"type": "AzureMLExecutePipeline",
"linkedServiceName": {
"referenceName": "AzureMLService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mlPipelineId": "machine learning pipeline ID",
"experimentName": "experimentName",
"mlPipelineParameters": {
"mlParameterName": "mlParameterValue"
}
}
}
Właściwości typu
| Właściwości | opis | Dozwolone wartości | Wymagane |
|---|---|---|---|
| nazwa | Nazwa aktywności w pipeline | String | Tak |
| typ | Typ działania to "AzureMLExecutePipeline" | String | Tak |
| linkedServiceName | Połączona usługa z usługą Azure Machine Learning | Dokumentacja połączonej usługi | Tak |
| mlPipelineId | Identyfikator opublikowanego pipeline’u Azure Machine Learning | Ciąg (lub wyrażenie z wartością resultType ciągu) | Tak |
| nazwaEksperymentu | Nazwa eksperymentu w historii przebiegów potoku Machine Learning | Ciąg (lub wyrażenie z wartością resultType ciągu) | Nie. |
| mlPipelineParameters | Pary klucz i wartość, które mają być przekazane do opublikowanego punktu końcowego potoku Azure Machine Learning. Klucze muszą odpowiadać nazwom parametrów potoku zdefiniowanych w opublikowanym potoku uczenia maszynowego. | Obiekt z parami wartości klucza (lub wyrażenie z obiektem resultType) | Nie. |
| mlParentRunId | Identyfikator uruchomienia potoku nadrzędnego Azure Machine Learning | Ciąg (lub wyrażenie z wartością resultType ciągu) | Nie. |
| dataPathAssignments | Słownik używany do zmieniania ścieżek danych w Azure Machine Learning. Umożliwia przełączanie ścieżek danych | Obiekt z parami wartości klucza | Nie. |
| continueOnStepFailure | Czy kontynuować wykonywanie innych kroków w przebiegu potoku Machine Learning, jeśli krok zakończy się niepowodzeniem | boolean | Nie. |
Uwaga
Aby wypełnić elementy listy rozwijanej nazwą i identyfikatorem potoku uczenia maszynowego, użytkownik musi mieć uprawnienia do wyświetlania listy takich potoków. Interfejs użytkownika wywołuje API usługi AzureMLService bezpośrednio przy użyciu poświadczeń zalogowanego użytkownika. Czas odnajdywania elementów listy rozwijanej będzie znacznie dłuższy w przypadku korzystania z prywatnych punktów końcowych.
Powiązana zawartość
Zapoznaj się z następującymi artykułami, które wyjaśniają sposób przekształcania danych na inne sposoby: