Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Szukasz łatwego sposobu przenoszenia danych? Zadanie kopiowania w usłudze Microsoft Fabric zapewnia prosty, skalowalny sposób ładowania danych bez tworzenia potoku. Dowiedz się, jak go utworzyć.
W tym samouczku utworzysz fabrykę danych, korzystając z interfejsu użytkownika Azure Data Factory. Potok przetwarzania w tej fabryce danych kopiuje dane z usługi Azure Blob Storage do bazy danych w usłudze Azure SQL Database. Wzorzec konfiguracji w tym samouczku ma zastosowanie do kopiowania danych ze składnicy opartej na plikach do relacyjnej składnicy danych. Aby zapoznać się z listą magazynów danych obsługiwanych jako źródła i ujścia, zobacz tabelę zawierającą obsługiwane magazyny danych.
Uwaga
Jeśli jesteś nowym użytkownikiem usługi Data Factory, zobacz Wprowadzenie do usługi Azure Data Factory.
Ten samouczek obejmuje wykonanie następujących kroków:
- Tworzenie fabryki danych.
- Utwórz przepływ danych z czynnością kopiowania.
- Testowe uruchamianie potoku.
- Wyzwól potok ręcznie.
- Uruchom potok zgodnie z harmonogramem.
- Monitoruj potok i uruchomienia działań.
- Wyłącz lub usuń zaplanowany wyzwalacz.
Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto platformy Azure.
- Konto usługi Azure Storage. Używasz magazynu obiektów blob jako magazynu danych będącego źródłem. Jeśli nie masz konta magazynu, utwórz je, wykonując czynności przedstawione w artykule Tworzenie konta magazynu platformy Azure.
- Azure SQL Database Baza danych jest używana jako magazyn danych będący ujściem. Jeśli nie masz bazy danych w usłudze Azure SQL Database, zobacz Tworzenie bazy danych w usłudze Azure SQL Database , aby uzyskać instrukcje tworzenia bazy danych.
Utwórz obiekt blob i tabelę SQL
Teraz przygotuj swój magazyn obiektów blob i bazę danych SQL na potrzeby tego samouczka, wykonując następujące kroki.
Utwórz źródłowy obiekt Blob
Uruchom program Notatnik. Skopiuj następujący tekst i zapisz go jako plik emp.txt :
FirstName,LastName John,Doe Jane,DoePrzenieś ten plik do folderu o nazwie input.
Utwórz kontener o nazwie adftutorial w magazynie obiektów BLOB. Prześlij folder wejściowy wraz z plikiem emp.txt do tego kontenera. Aby wykonać te zadania, możesz użyć witryny Azure Portal lub narzędzi, takich jak Eksplorator usługi Azure Storage .
Utwórz docelową tabelę SQL
Użyj następującego skryptu SQL, aby utworzyć tabelę dbo.emp w bazie danych:
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);Zezwól usługom platformy Azure na dostęp do programu SQL Server. Upewnij się, że ustawienie Zezwalaj na dostęp do usług platformy Azure jest ON dla SQL Server, aby usługa Data Factory mogła zapisywać dane w SQL Server. Aby zweryfikować i włączyć to ustawienie, przejdź do swojego SQL Server w portalu Azure, wybierz pozycję zabezpieczeń>Sieć> włącz wybrane sieci> zaznacz opcję Zezwalaj usługom i zasobom platformy Azure na dostęp do tego serwera w obszarze Wyjątki.
Tworzenie fabryki danych
W tym kroku utworzysz fabrykę danych i uruchomisz interfejs użytkownika usługi Data Factory, aby utworzyć potok w fabryce danych.
Otwórz przeglądarkę Microsoft Edge lub Google Chrome. Obecnie interfejs użytkownika usługi Data Factory jest obsługiwany tylko przez przeglądarki internetowe Microsoft Edge i Google Chrome.
W menu po lewej stronie wybierz Utwórz zasób>Analiza>Fabryka danych.
Na stronie Tworzenie fabryki danych na karcie Podstawy wybierz subskrypcję platformy Azure, w której chcesz utworzyć fabrykę danych.
W obszarze Grupa zasobów wykonaj jedną z następujących czynności:
a. Wybierz istniejącą grupę zasobów z listy rozwijanej.
b. Wybierz pozycję Utwórz nową i wprowadź nazwę nowej grupy zasobów.
Informacje na temat grup zasobów znajdują się w artykule Using resource groups to manage your Azure resources (Używanie grup zasobów do zarządzania zasobami platformy Azure).
W obszarze Region wybierz lokalizację fabryki danych. Magazyny danych mogą znajdować się w innym regionie niż w fabryce danych, jeśli zajdzie taka potrzeba.
W obszarze Nazwa nazwa fabryki danych Azure musi być unikalna na całym świecie. Jeśli zostanie wyświetlony komunikat o błędzie dotyczącym wartości nazwy, wprowadź inną nazwę dla fabryki danych. (na przykład twoja nazwa ADF Demo). Reguły nazewnictwa dla artefaktów usługi Data Factory można znaleźć w artykule Data Factory — reguły nazewnictwa.
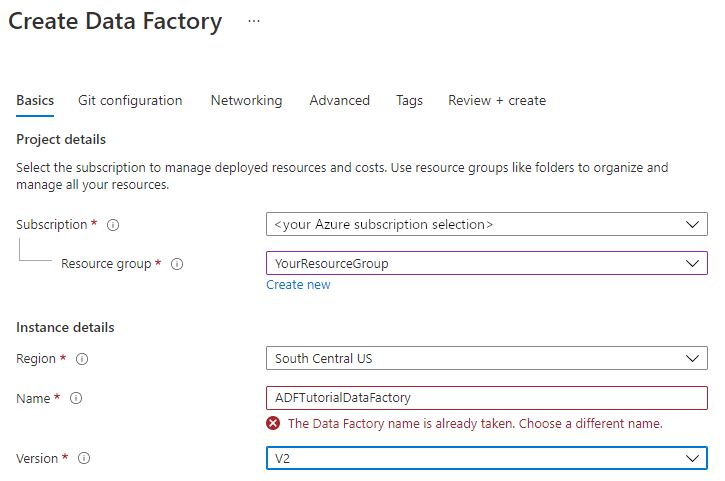
W obszarze Wersja wybierz pozycję V2.
Wybierz kartę Konfiguracja usługi Git u góry, a następnie zaznacz pole wyboru Konfiguruj usługę Git później .
Wybierz pozycję Przejrzyj i utwórz, a następnie wybierz pozycję Utwórz po zakończeniu walidacji.
Po zakończeniu tworzenia zostanie wyświetlone powiadomienie w Centrum powiadomień. Wybierz Przejdź do zasobu, aby otworzyć stronę Data Factory.
Wybierz Launch Studio na kafelku Azure Data Factory Studio.
Tworzenie pipeline'u
W tym kroku utworzysz potok z działaniem kopiowania w fabryce danych. Działanie kopiowania kopiuje dane z magazynu Blobs do bazy danych SQL.
Na stronie głównej wybierz pozycję Orkiestruj.
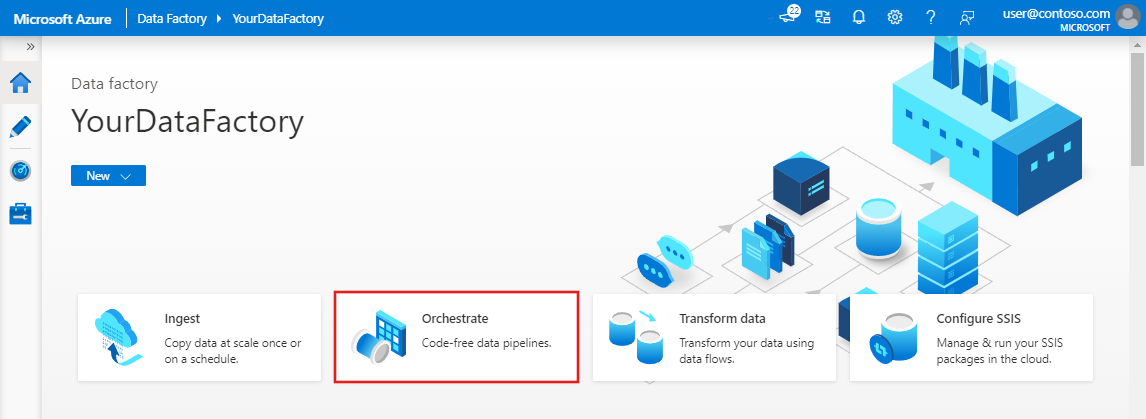
W panelu Ogólne w obszarze Właściwości określ CopyPipeline dla Nazwa. Następnie zwiń panel, klikając ikonę Właściwości w prawym górnym rogu.
W narzędziowniku Działania rozwiń kategorię Przenieś i Przekształć, a następnie przeciągnij i upuść Kopiuj Dane z narzędziownika do powierzchni projektanta potoku. Wprowadź wartość CopyFromBlobToSql w polu Nazwa.
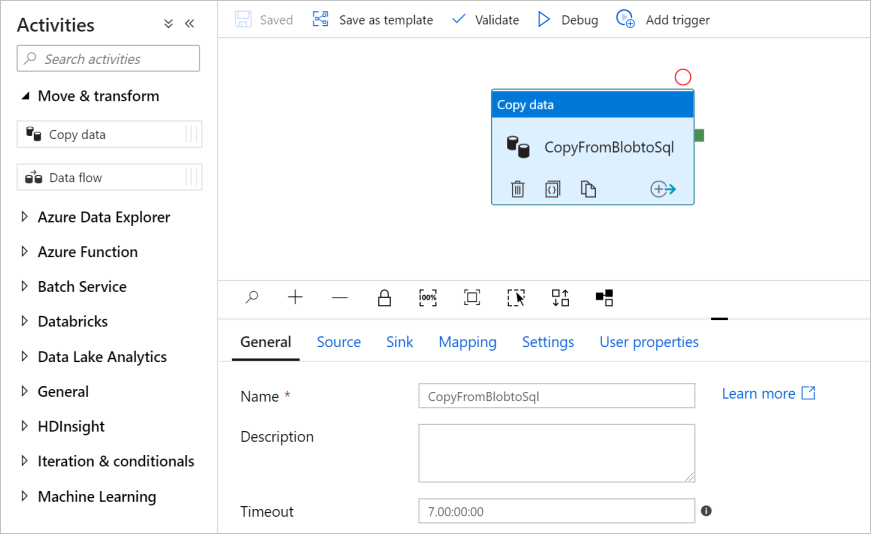
Konfigurowanie źródła
Wskazówka
W tym samouczku użyjesz klucza konta jako typu uwierzytelniania dla źródłowego magazynu danych, ale w razie potrzeby możesz wybrać inne obsługiwane metody uwierzytelniania: SAS URI, główna aplikacja usługi i tożsamość zarządzana. Aby uzyskać szczegółowe informacje, zapoznaj się z odpowiednimi sekcjami w tym artykule . Aby bezpiecznie przechowywać tajne dane w magazynach danych, zaleca się również używanie Azure Key Vault. Zapoznaj się z tym artykułem, aby uzyskać szczegółowe ilustracje.
Przejdź do karty Źródło . Wybierz pozycję + Nowy , aby utworzyć źródłowy zestaw danych.
W oknie dialogowym Nowy zestaw danych wybierz pozycję Azure Blob Storage, a następnie wybierz pozycję Kontynuuj. Dane źródłowe znajdują się w Blob Storage, ponieważ należy wybrać usługę Azure Blob Storage dla źródłowego zestawu danych.
W oknie dialogowym Wybieranie formatu wybierz pozycję Rozdzielany tekst, a następnie wybierz pozycję Kontynuuj.
W oknie dialogowym Ustawianie właściwości w polu Nazwa wprowadź wartość SourceBlobDataset. Zaznacz pole wyboru Pierwszy wiersz jako nagłówek. W polu Usługi powiązanej wybierz + Nowy.
W oknie dialogowym Nowa połączona usługa (Azure Blob Storage) wprowadź AzureStorageLinkedService jako nazwę, wybierz konto magazynu z listy Nazwa konta magazynu. Przetestuj połączenie, wybierz pozycję Utwórz , aby wdrożyć połączoną usługę.
Po utworzeniu połączonej usługi użytkownik zostaje przeniesiony z powrotem do strony ustawień właściwości. Wybierz przycisk Przeglądaj obok pozycji Ścieżka pliku.
Przejdź do folderu adftutorial/input , wybierz plik emp.txt , a następnie wybierz przycisk OK.
Wybierz przycisk OK. Automatycznie przechodzi do strony pipeline. Na karcie Źródło upewnij się, że wybrano pozycję SourceBlobDataset . Aby wyświetlić podgląd danych na tej stronie, wybierz pozycję Podgląd danych.
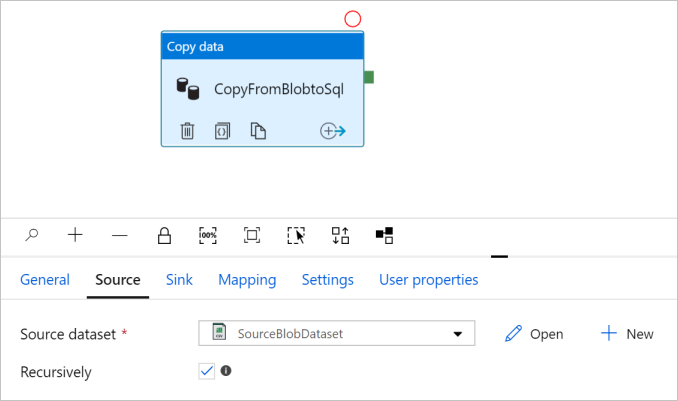
Konfigurowanie ujścia
Wskazówka
W tym samouczku używasz uwierzytelniania SQL jako typu dla magazynu danych ujścia, ale w razie potrzeby możesz wybrać inne obsługiwane metody uwierzytelniania: Jednostkę usługi i Tożsamość zarządzaną. Aby uzyskać szczegółowe informacje, zapoznaj się z odpowiednimi sekcjami w tym artykule . Aby bezpiecznie przechowywać tajne dane dla magazynów danych, zaleca się również używanie usługi Azure Key Vault. Zapoznaj się z tym artykułem, aby uzyskać szczegółowe ilustracje.
Przejdź do karty Ujście, a następnie wybierz pozycję + Nowy, aby utworzyć zestaw danych będący ujściem.
W oknie dialogowym Nowy zestaw danych wprowadź ciąg "SQL" w polu wyszukiwania, aby filtrować łączniki, wybierz pozycję Azure SQL Database, a następnie wybierz pozycję Kontynuuj.
W oknie dialogowym Ustawianie właściwości wprowadź wartość OutputSqlDataset w polu Nazwa. Z listy rozwijanej Usługa połączona wybierz + Nowy. Zestaw danych musi być skojarzony z połączoną usługą. Połączona usługa ma parametry połączenia używane przez usługę Data Factory do nawiązywania połączenia z usługą SQL Database w czasie wykonywania i określa, gdzie będą kopiowane dane.
W oknie dialogowym Nowa połączona usługa (Azure SQL Database) wykonaj następujące kroki:
a. W obszarze Nazwa wprowadź wartość AzureSqlDatabaseLinkedService.
b. W polu Nazwa serwera wybierz wystąpienie programu SQL Server.
c. W obszarze Nazwa bazy danych wybierz bazę danych.
d. W polu Nazwa użytkownika wprowadź nazwę użytkownika.
e. W polu Hasło wprowadź hasło użytkownika.
f. Wybierz pozycję Testuj połączenie, aby przetestować połączenie.
g. Wybierz pozycję Utwórz , aby wdrożyć połączoną usługę.
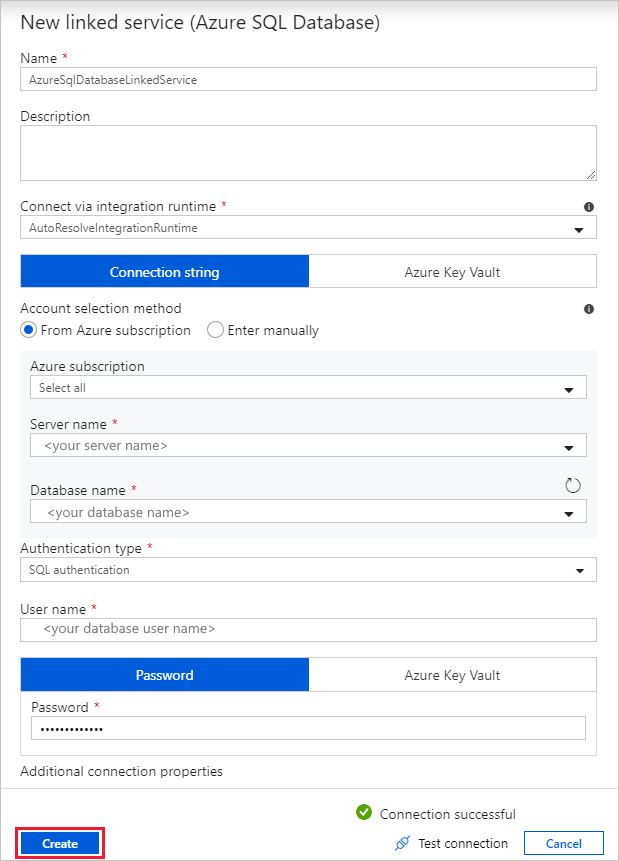
Automatycznie przechodzi do okna dialogowego Ustawianie właściwości . W obszarze Tabela wybierz pozycję Wprowadź ręcznie, a następnie wprowadź [dbo].[emp]. Następnie wybierz opcję OK.
Przejdź do karty z potokiem i upewnij się, że w Zestawie danych wynikowych wybrano OutputSqlDataset.
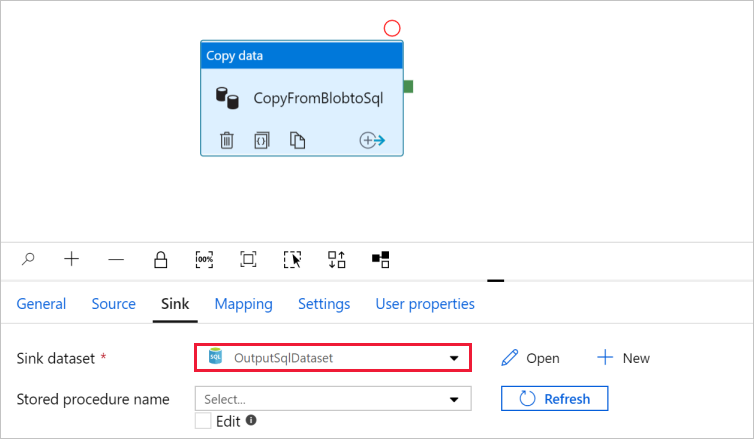
Opcjonalnie można mapować schemat źródła na odpowiedni schemat docelowy, postępując zgodnie z mapowaniem schematu w działaniu kopiowania.
Zweryfikuj rurociąg
Wybierz na pasku narzędzi pozycję Weryfikuj, aby zweryfikować potok.
Kod JSON skojarzony z potokiem można wyświetlić, klikając pozycję Kod w prawym górnym rogu.
Debuguj i opublikuj potok
Przed opublikowaniem artefaktów (połączone usługi, zestawy danych i potok) w usłudze Data Factory lub własnym repozytorium Git usługi Azure Repos możesz debugować potok.
Aby debugować potok, wybierz na pasku narzędzi pozycję Debuguj. Stan uruchomienia potoku jest widoczny na karcie Dane wyjściowe na dole okna.
Gdy potok zostanie pomyślnie uruchomiony, na górnym pasku narzędzi wybierz pozycję Opublikuj wszystko. Ta akcja powoduje opublikowanie utworzonych jednostek (zestawy danych i potok) w usłudze Data Factory.
Zaczekaj, aż zobaczysz komunikat o pomyślnym opublikowaniu. Aby wyświetlić komunikaty powiadomień, wybierz pozycję Pokaż powiadomienia w prawym górnym rogu (przycisk dzwonka).
Ręczne uruchamianie pipeline'u
W tym kroku ręcznie zainicjujesz potok, który został opublikowany w poprzednim kroku.
Wybierz pozycję Dodaj wyzwalacz na pasku narzędzi, a następnie wybierz pozycję Wyzwól teraz.
Na stronie Uruchamianie potoku wybierz OK.
Przejdź do karty Monitorowanie po lewej stronie. Widoczne jest uruchomienie potoku, które zostało wyzwolone za pomocą wyzwalacza ręcznego. Możesz użyć linków w kolumnie NAZWA POTOKU, aby wyświetlić szczegóły aktywności i ponownie uruchomić potok.

Aby wyświetlić uruchomienia działań skojarzone z uruchomieniem potoku, wybierz link CopyPipeline w kolumnie NAZWA POTOKU. W tym przykładzie istnieje tylko jedno działanie, dlatego na liście jest widoczny tylko jeden wpis. Aby uzyskać szczegółowe informacje o operacji kopiowania, umieść kursor nad tą operacją i
wybierz link Szczegóły (ikona okularów) w kolumnie NAZWA DZIAŁANIA . Wybierz pozycję Wszystkie uruchomienia potoku u góry, aby wrócić do widoku Uruchomienia potoku. Aby odświeżyć widok, wybierz pozycję Odśwież.

Sprawdź, czy do tabeli emp w bazie danych są dodawane jeszcze dwa wiersze.

Wyzwalanie potoku zgodnie z harmonogramem
W tym harmonogramie utworzysz wyzwalacz dla potoku. Wyzwalacz uruchamia potok według określonego harmonogramu, na przykład co godzinę lub codziennie. W tym miejscu ustawisz wyzwalacz tak, aby był uruchamiany co minutę do określonej daty/godziny zakończenia.
Przejdź do karty Autor po lewej, powyżej karty Monitor.
Przejdź do potoku, wybierz Wyzwalacz na pasku narzędzi, a następnie wybierz Nowy lub Edytuj.
W oknie dialogowym Dodawanie wyzwalaczy wybierz pozycję Wybierz wyzwalacz i wybierz pozycję + Nowy.
W oknie Nowy wyzwalacz wykonaj następujące czynności:
a. W obszarze Nazwa wprowadź wartość RunEveryMinute.
b. Zaktualizuj datę początkową wyzwalacza. Jeśli data przypada przed bieżącą datą/godziną, wyzwalacz zacznie obowiązywać po opublikowaniu zmiany.
c. W obszarze Strefa czasowa wybierz listę rozwijaną.
d. Ustaw wartość Cykl na co 1 minutę.
e. Zaznacz pole wyboru w polu Określ datę zakończenia i zaktualizuj część End On ( Koniec) w ciągu kilku minut po bieżącej dacie/godzinie. Wyzwalacz zostanie aktywowany tylko w przypadku, gdy opublikujesz zmiany. Jeśli ustawisz odstęp na zaledwie kilka minut, a nie opublikujesz go w tym czasie, nie zobaczysz uruchomienia wyzwalacza.
f. W obszarze Aktywowano wybierz pozycję Tak.
g. Wybierz przycisk OK.
Ważne
Za każde uruchomienie potoku naliczany jest koszt, zatem określ odpowiednią datę zakończenia.
Na stronie Edytowanie wyzwalacza przejrzyj ostrzeżenie, a następnie wybierz pozycję Zapisz. Przepływ w tym przykładzie nie przyjmuje żadnych parametrów.
Wybierz pozycję Opublikuj wszystko , aby opublikować zmianę.
Przejdź do karty Monitorowanie po lewej stronie, aby zobaczyć wyzwolone uruchomienia potoku.

Aby przełączyć się z widoku Uruchomienia potoku do widoku Uruchomienia wyzwalacza, wybierz pozycję Uruchomienia wyzwalacza po lewej stronie okna.
Uruchomienia wyzwalacza znajdują się na liście.
Sprawdź, czy do tabeli emp są wstawiane dwa wiersze na minutę (dla każdego uruchomienia potoku), aż do określonego czasu zakończenia.
Wyłącz wyzwalacz
Aby wyłączyć utworzony wyzwalacz co minutę, wykonaj następujące kroki:
Wybierz okienko Zarządzanie po lewej stronie.
W obszarze Autor wybierz pozycję Wyzwalacze.
Zatrzymaj wskaźnik myszy na utworzonym wyzwalaczu RunEveryMinute .
- Wybierz przycisk Zatrzymaj , aby wyłączyć wyzwalacz z uruchamiania.
- Wybierz przycisk Usuń , aby wyłączyć i usunąć wyzwalacz.
Wybierz pozycję Opublikuj wszystko , aby zapisać zmiany.
Powiązana zawartość
Potok danych w tym przykładzie kopiuje dane z jednej lokalizacji do innej lokalizacji w magazynie Blob. Nauczyłeś się, jak:
- Tworzenie fabryki danych.
- Utwórz potok z działalnością kopiowania.
- Testowe uruchamianie potoku.
- Uruchom potok ręcznie.
- Uruchom potok według harmonogramu.
- Monitoruj potok i uruchomienia działań.
- Wyłącz lub usuń zaplanowany wyzwalacz.
Aby dowiedzieć się, jak kopiować dane ze środowiska lokalnego do chmury, przejdź do następującego samouczka:
Aby uzyskać więcej informacji na temat kopiowania danych do lub z usługi Azure Blob Storage i usługi Azure SQL Database, zobacz następujące przewodniki dotyczące łączników: