Bezpieczne kopiowanie danych z usługi Azure Blob Storage do bazy danych SQL przy użyciu prywatnych punktów końcowych
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym samouczku utworzysz fabrykę danych przy użyciu interfejsu użytkownika usługi Azure Data Factory. Potok w tej fabryce danych kopiuje dane bezpiecznie z usługi Azure Blob Storage do bazy danych Azure SQL Database (zezwalającej na dostęp tylko do wybranych sieci) przy użyciu prywatnych punktów końcowych w zarządzanej sieci wirtualnej usługi Azure Data Factory. Wzorzec konfiguracji w tym samouczku ma zastosowanie do kopiowania danych z magazynu opartego na plikach do relacyjnego magazynu danych. Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia, zobacz tabelę Obsługiwane magazyny danych i formaty . Funkcja prywatnych punktów końcowych jest dostępna we wszystkich warstwach usługi Azure Data Factory, więc do ich korzystania nie jest wymagana żadna konkretna warstwa. Aby uzyskać więcej informacji na temat cen i warstw, zapoznaj się ze stroną cennika usługi Azure Data Factory.
Uwaga
Jeśli jesteś nowym użytkownikiem usługi Data Factory, zobacz Wprowadzenie do usługi Azure Data Factory.
W tym samouczku wykonasz następujące czynności:
- Tworzenie fabryki danych.
- Tworzenie potoku z działaniem kopiowania.
Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto platformy Azure.
- Konto usługi Azure Storage. Magazyn obiektów blob jest używany jako magazyn danych będący źródłem. Jeśli nie masz konta magazynu, utwórz je, wykonując czynności przedstawione w artykule Tworzenie konta magazynu platformy Azure. Upewnij się, że konto magazynu zezwala na dostęp tylko z wybranych sieci.
- Usługa Azure SQL Database. Baza danych jest używana jako magazyn danych będący ujściem. Jeśli nie masz bazy danych Azure SQL Database, zobacz Tworzenie bazy danych SQL, aby uzyskać instrukcje tworzenia bazy danych . Upewnij się, że konto usługi SQL Database zezwala na dostęp tylko z wybranych sieci.
Tworzenie obiektu blob i tabeli SQL
Teraz przygotuj magazyn obiektów blob i bazę danych SQL na potrzeby samouczka, wykonując następujące kroki.
Tworzenie źródłowego obiektu Blob
Otwórz Notatnik. Skopiuj poniższy tekst i zapisz go na dysku jako plik emp.txt:
FirstName,LastName John,Doe Jane,DoeUtwórz kontener o nazwie adftutorial w magazynie obiektów blob. W tym kontenerze utwórz folder o nazwie input. Następnie przekaż plik emp.txt do folderu input. Do wykonania tych zadań użyj witryny Azure Portal lub narzędzi takich jak Eksplorator usługi Azure Storage.
Tworzenie tabeli SQL ujścia
Utwórz tabelę dbo.emp w bazie danych SQL przy użyciu poniższego skryptu SQL:
CREATE TABLE dbo.emp
(
ID int IDENTITY(1,1) NOT NULL,
FirstName varchar(50),
LastName varchar(50)
)
GO
CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Tworzenie fabryki danych
W tym kroku utworzysz fabrykę danych i uruchomisz interfejs użytkownika usługi Data Factory, aby utworzyć potok w fabryce danych.
Otwórz przeglądarkę Microsoft Edge lub Google Chrome. Obecnie tylko przeglądarki internetowe Microsoft Edge i Google Chrome obsługują interfejs użytkownika usługi Data Factory.
W menu po lewej stronie wybierz pozycję Utwórz zasób>Analiza>Data Factory.
Na stronie Nowa fabryka danych w polu Nazwa wprowadź wartość ADFTutorialDataFactory.
Nazwa fabryki danych platformy Azure musi być globalnie unikatowa. Jeśli zostanie wyświetlony komunikat o błędzie dotyczący wartości nazwy, wprowadź inną nazwę fabryki danych (na przykład yournameADFTutorialDataFactory). Reguły nazewnictwa dla artefaktów usługi Data Factory można znaleźć w artykule Data Factory — reguły nazewnictwa.
Wybierz subskrypcję platformy Azure, w której chcesz utworzyć fabrykę danych.
W obszarze Grupa zasobów wykonaj jedną z następujących czynności:
- Wybierz pozycję Użyj istniejącej, a następnie wybierz istniejącą grupę zasobów z listy rozwijanej.
- Wybierz pozycję Utwórz nową, a następnie wprowadź nazwę grupy zasobów.
Informacje na temat grup zasobów znajdują się w artykule Using resource groups to manage your Azure resources (Używanie grup zasobów do zarządzania zasobami platformy Azure).
W obszarze Wersja wybierz pozycję V2.
W obszarze Lokalizacja wybierz lokalizację fabryki danych. Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (np. usługi Azure Storage i SQL Database) oraz jednostki obliczeniowe (np. usługa Azure HDInsight) używane przez fabrykę danych mogą znajdować się w innych regionach.
Wybierz pozycję Utwórz.
Po zakończeniu tworzenia zostanie wyświetlone powiadomienie w Centrum powiadomień. Wybierz pozycję Przejdź do zasobu , aby przejść do strony Fabryka danych .
Wybierz pozycję Otwórz na kafelku Otwórz usługę Azure Data Factory Studio , aby uruchomić interfejs użytkownika usługi Data Factory na osobnej karcie.
Tworzenie środowiska Azure Integration Runtime w zarządzanej sieci wirtualnej usługi Data Factory
W tym kroku utworzysz środowisko Azure Integration Runtime i włączysz zarządzaną sieć wirtualną usługi Data Factory.
W portalu usługi Data Factory przejdź do pozycji Zarządzanie i wybierz pozycję Nowy , aby utworzyć nowe środowisko Azure Integration Runtime.
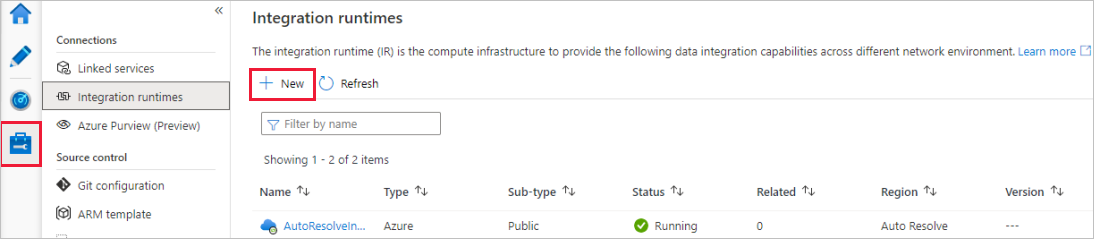
Na stronie Konfiguracja środowiska Integration Runtime wybierz środowisko Integration Runtime, które ma zostać utworzone na podstawie wymaganych możliwości. W tym samouczku wybierz pozycję Azure, Self-Hosted , a następnie kliknij przycisk Kontynuuj.
Wybierz pozycję Azure, a następnie kliknij przycisk Kontynuuj , aby utworzyć środowisko Azure Integration Runtime.
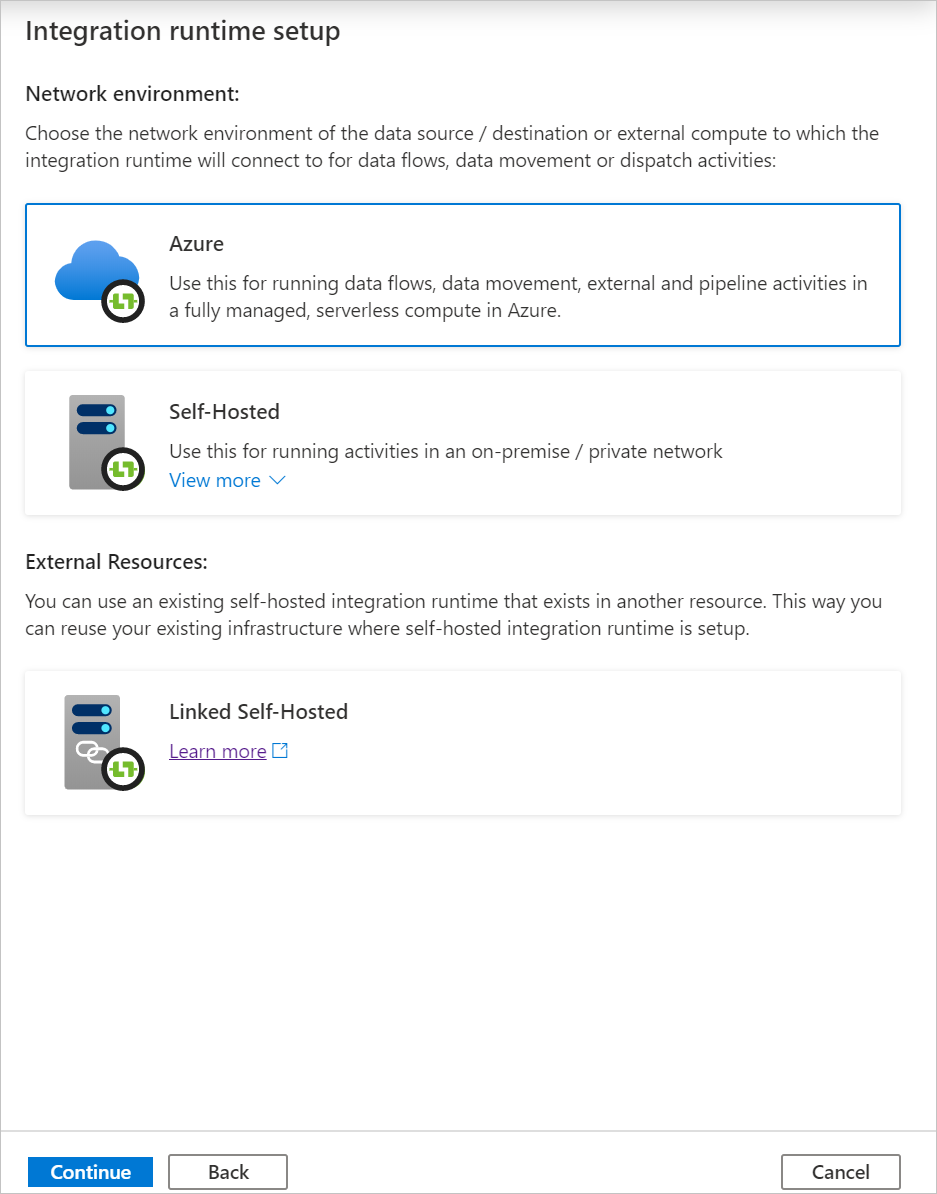
W obszarze Konfiguracja sieci wirtualnej (wersja zapoznawcza) wybierz pozycję Włącz.
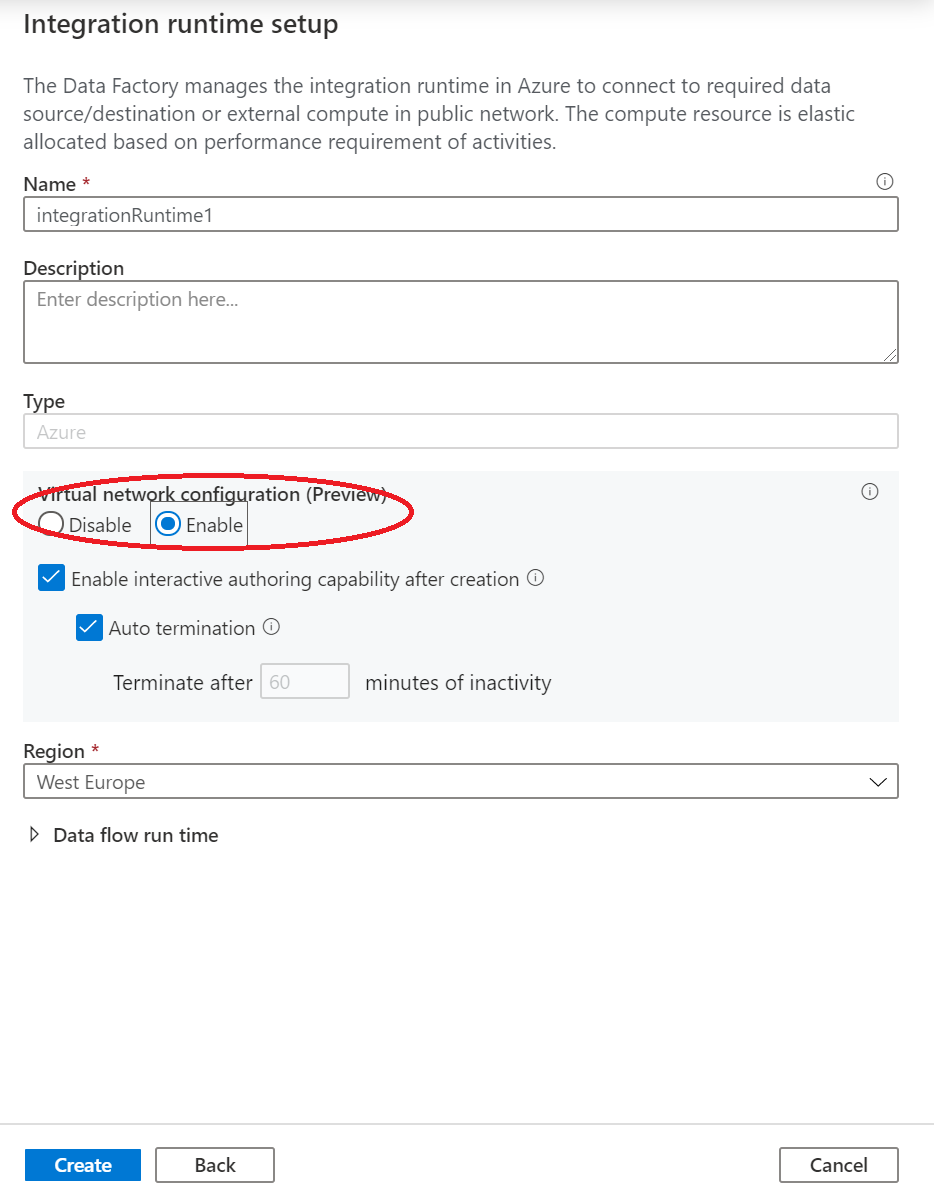
Wybierz pozycję Utwórz.
Tworzenie potoku
W tym kroku utworzysz potok z działaniem kopiowania w fabryce danych. Działanie kopiowania kopiuje dane z magazynu obiektów blob do usługi SQL Database. W samouczku szybkiego startu utworzono potok, wykonując następujące czynności:
- Utworzenie połączonej usługi.
- Utworzenie wejściowych i wyjściowych zestawów danych.
- Tworzenie potoku.
W tym samouczku zaczniesz od utworzenia potoku. Następnie utworzysz usługi połączone i zestawy danych, gdy będą potrzebne do skonfigurowania potoku.
Na stronie głównej wybierz pozycję Orkiestruj.
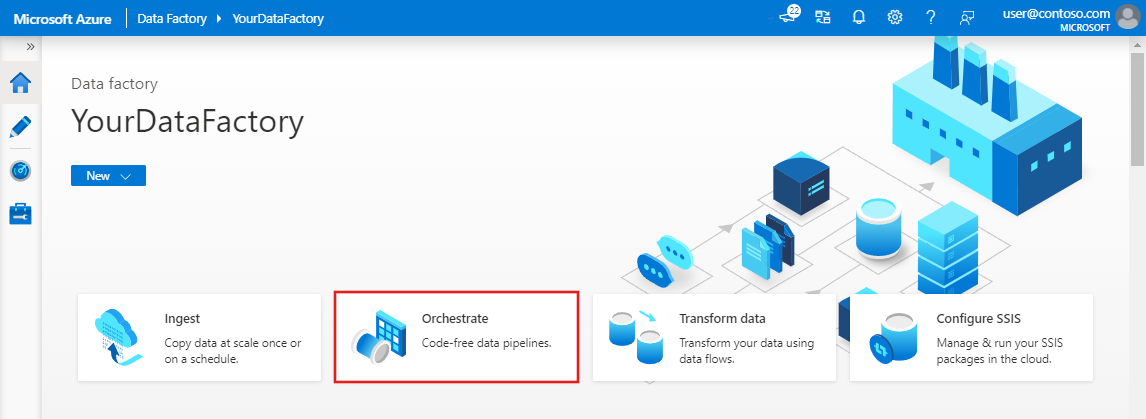
W okienku właściwości potoku wprowadź wartość CopyPipeline jako nazwę potoku.
W oknie narzędzia Działania rozwiń kategorię Przenieś i Przekształć, a następnie przeciągnij działanie Kopiuj dane z pola narzędzia do powierzchni projektanta potoku. Wprowadź wartość CopyFromBlobToSql jako nazwę.
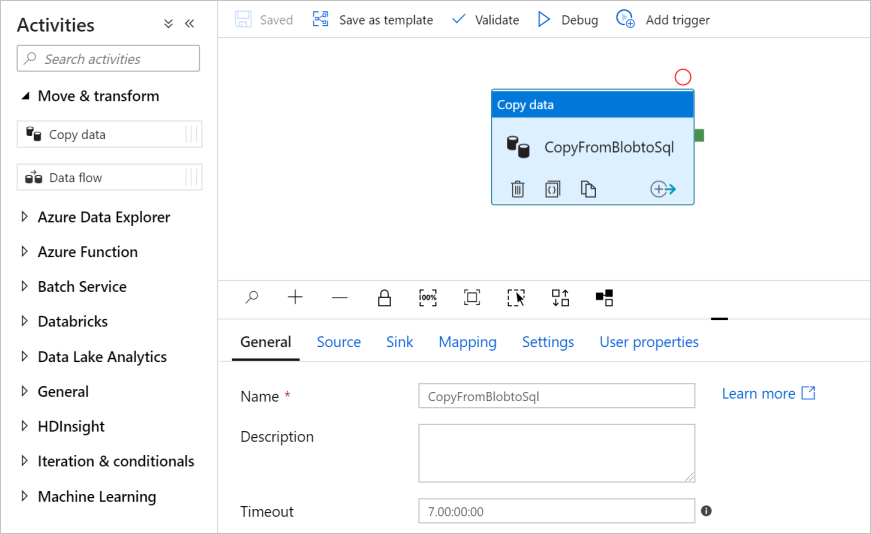
Konfigurowanie źródła
Napiwek
W tym samouczku użyjesz klucza konta jako typu uwierzytelniania dla źródłowego magazynu danych. W razie potrzeby możesz również wybrać inne obsługiwane metody uwierzytelniania, takie jak identyfikator URI sygnatury dostępu współdzielonego, jednostka usługi i tożsamość zarządzana. Aby uzyskać więcej informacji, zobacz odpowiednie sekcje w temacie Kopiowanie i przekształcanie danych w usłudze Azure Blob Storage przy użyciu usługi Azure Data Factory.
Aby bezpiecznie przechowywać wpisy tajne dla magazynów danych, zalecamy również używanie usługi Azure Key Vault. Aby uzyskać więcej informacji i ilustracji, zobacz Przechowywanie poświadczeń w usłudze Azure Key Vault.
Tworzenie źródłowego zestawu danych i połączonej usługi
Przejdź do karty Źródło . Wybierz pozycję + Nowy , aby utworzyć źródłowy zestaw danych.
W oknie dialogowym Nowy zestaw danych wybierz pozycję Azure Blob Storage, a następnie wybierz pozycję Kontynuuj. Dane źródłowe znajdują się w magazynie obiektów blob, musisz więc wybrać usługę Azure Blob Storage dla źródłowego zestawu danych.
W oknie dialogowym Wybieranie formatu wybierz typ formatu danych, a następnie wybierz pozycję Kontynuuj.
W oknie dialogowym Ustawianie właściwości wprowadź wartość SourceBlobDataset w polu Nazwa. Zaznacz pole wyboru Dla pierwszego wiersza jako nagłówka. W polu tekstowym Połączona usługa wybierz pozycję + Nowy.
W oknie dialogowym Nowa połączona usługa (Azure Blob Storage) wprowadź wartość AzureStorageLinkedService jako nazwę, a następnie wybierz konto magazynu z listy Nazwa konta magazynu.
Upewnij się, że włączono tworzenie interakcyjne. Włączenie tej opcji może potrwać około jednej minuty.
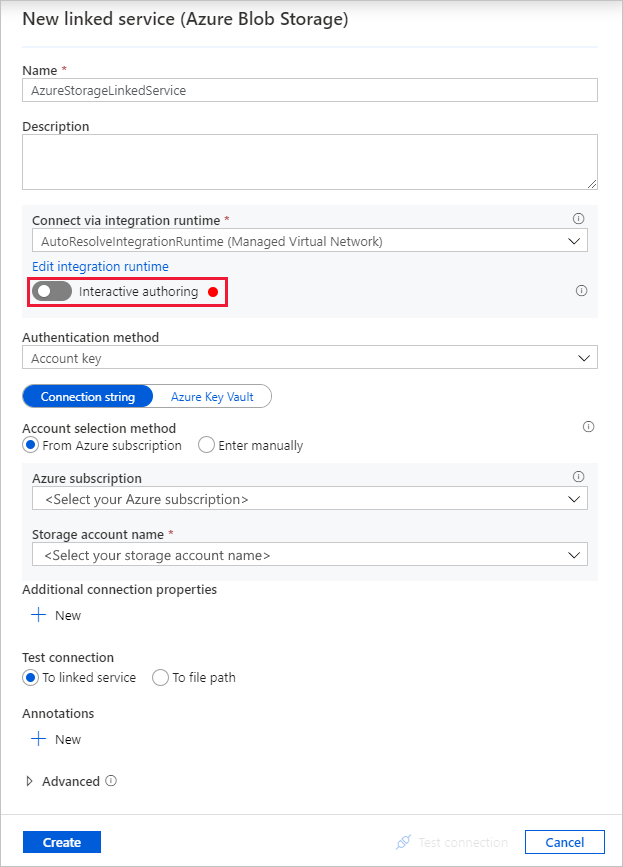
Wybierz pozycję Testuj połączenie. Powinno się to nie powieść, gdy konto magazynu zezwala na dostęp tylko z wybranych sieci i wymaga, aby usługa Data Factory utworzyła dla niego prywatny punkt końcowy, który powinien zostać zatwierdzony przed jego użyciem. W komunikacie o błędzie powinien zostać wyświetlony link umożliwiający utworzenie prywatnego punktu końcowego, który można wykonać, aby utworzyć zarządzany prywatny punkt końcowy. Alternatywą jest przejście bezpośrednio do karty Zarządzanie i wykonanie instrukcji w następnej sekcji , aby utworzyć zarządzany prywatny punkt końcowy.
Uwaga
Karta Zarządzanie może nie być dostępna dla wszystkich wystąpień fabryki danych. Jeśli nie widzisz tego punktu końcowego, możesz uzyskać dostęp do prywatnych punktów końcowych, wybierając pozycję Utwórz>połączenia>prywatne punktu końcowego.
Pozostaw otwarte okno dialogowe, a następnie przejdź do konta magazynu.
Postępuj zgodnie z instrukcjami w tej sekcji , aby zatwierdzić link prywatny.
Wróć do okna dialogowego. Wybierz ponownie pozycję Testuj połączenie i wybierz pozycję Utwórz , aby wdrożyć połączoną usługę.
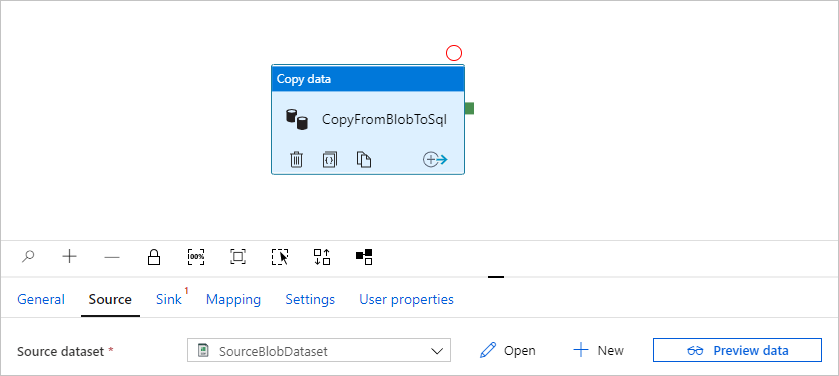
Po utworzeniu połączonej usługi wróć do strony Ustawianie właściwości . Wybierz przycisk Przeglądaj obok pozycji Ścieżka pliku.
Przejdź do folderu adftutorial/input , wybierz plik emp.txt , a następnie wybierz przycisk OK.
Wybierz przycisk OK. Automatycznie przechodzi do strony potoku. Na karcie Źródło upewnij się, że wybrano pozycję SourceBlobDataset. Aby wyświetlić podgląd danych na tej stronie, wybierz pozycję Podgląd danych.
Tworzenie zarządzanego prywatnego punktu końcowego
Jeśli nie wybrano hiperlinku podczas testowania połączenia, postępuj zgodnie ze ścieżką. Teraz musisz utworzyć zarządzany prywatny punkt końcowy, który połączysz się z utworzoną usługą połączoną.
Przejdź do karty Zarządzanie .
Uwaga
Karta Zarządzanie może nie być dostępna dla wszystkich wystąpień usługi Data Factory. Jeśli nie widzisz tego punktu końcowego, możesz uzyskać dostęp do prywatnych punktów końcowych, wybierając pozycję Utwórz>połączenia>prywatne punktu końcowego.
Przejdź do sekcji Zarządzane prywatne punkty końcowe .
Wybierz pozycję + Nowy w obszarze Zarządzane prywatne punkty końcowe.
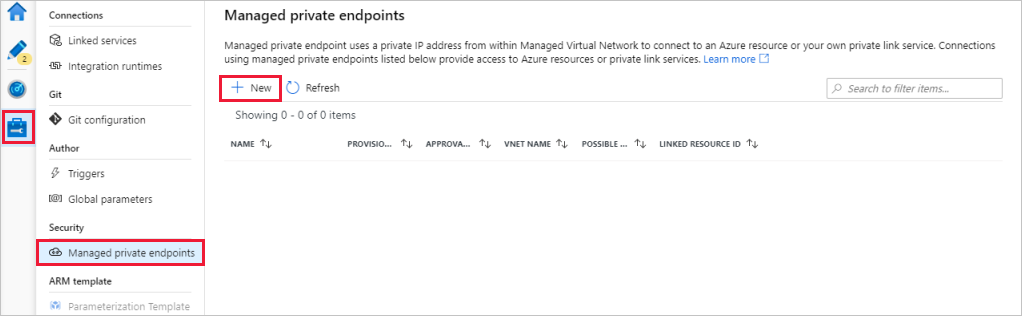
Wybierz kafelek Azure Blob Storage z listy, a następnie wybierz pozycję Kontynuuj.
Wprowadź nazwę utworzonego konta magazynu.
Wybierz pozycję Utwórz.
Po kilku sekundach powinno zostać wyświetlone, że utworzony link prywatny wymaga zatwierdzenia.
Wybierz utworzony prywatny punkt końcowy. Możesz zobaczyć hiperlink, który spowoduje zatwierdzenie prywatnego punktu końcowego na poziomie konta magazynu.
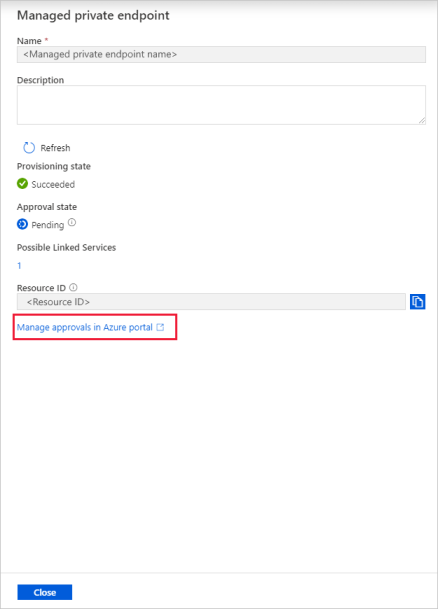
Zatwierdzanie łącza prywatnego na koncie magazynu
Na koncie magazynu przejdź do pozycji Połączenia prywatnego punktu końcowego w sekcji Ustawienia .
Zaznacz pole wyboru dla utworzonego prywatnego punktu końcowego, a następnie wybierz pozycję Zatwierdź.
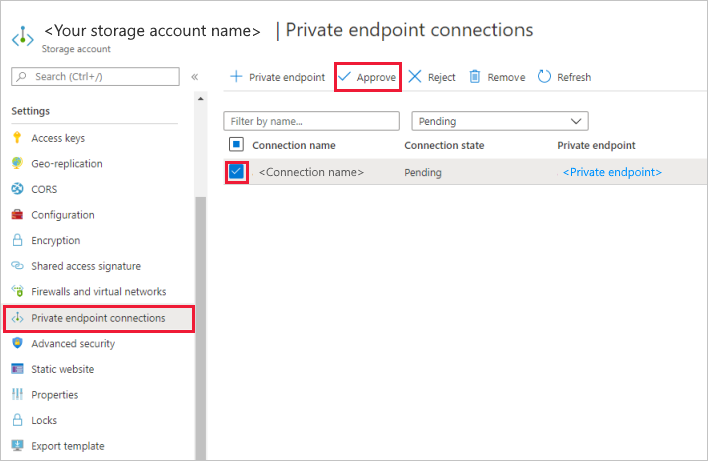
Dodaj opis i wybierz pozycję Tak.
Wróć do sekcji Zarządzane prywatne punkty końcowe na karcie Zarządzanie w usłudze Data Factory.
Po około jednej lub dwóch minutach w interfejsie użytkownika usługi Data Factory powinno zostać wyświetlone zatwierdzenie prywatnego punktu końcowego.
Konfigurowanie ujścia
Napiwek
W tym samouczku użyjesz uwierzytelniania SQL jako typu uwierzytelniania dla magazynu danych ujścia. W razie potrzeby możesz również wybrać inne obsługiwane metody uwierzytelniania, takie jak jednostka usługi i tożsamość zarządzana. Aby uzyskać więcej informacji, zobacz odpowiednie sekcje w temacie Kopiowanie i przekształcanie danych w usłudze Azure SQL Database przy użyciu usługi Azure Data Factory.
Aby bezpiecznie przechowywać wpisy tajne dla magazynów danych, zalecamy również używanie usługi Azure Key Vault. Aby uzyskać więcej informacji i ilustracji, zobacz Przechowywanie poświadczeń w usłudze Azure Key Vault.
Tworzenie zestawu danych ujścia i połączonej usługi
Przejdź do karty Ujście, a następnie wybierz pozycję + Nowy, aby utworzyć zestaw danych będący ujściem.
W oknie dialogowym Nowy zestaw danych wprowadź ciąg SQL w polu wyszukiwania, aby filtrować łączniki. Wybierz pozycję Azure SQL Database, a następnie wybierz pozycję Kontynuuj. W tym samouczku skopiujesz dane do bazy danych SQL.
W oknie dialogowym Ustawianie właściwości wprowadź wartość OutputSqlDataset w polu Nazwa. Z listy rozwijanej Połączona usługa wybierz pozycję + Nowy. Zestaw danych musi być skojarzony z połączoną usługą. Połączona usługa ma parametry połączenia, których usługa Data Factory używa do nawiązywania połączenia z usługą SQL Database w środowisku uruchomieniowym. Zestaw danych określa kontener, folder i plik (opcjonalnie), do którego dane są kopiowane.
W oknie dialogowym Nowa połączona usługa (Azure SQL Database) wykonaj następujące kroki:
- W obszarze Nazwa wprowadź wartość AzureSqlDatabaseLinkedService.
- W polu Nazwa serwera wybierz swoje wystąpienie programu SQL Server.
- Upewnij się, że włączono tworzenie interakcyjne.
- W polu Nazwa bazy danych wybierz swoją usługę SQL Database.
- W polu Nazwa użytkownika wprowadź nazwę użytkownika.
- W polu Hasło wprowadź hasło użytkownika.
- Wybierz pozycję Testuj połączenie. Powinno to zakończyć się niepowodzeniem, ponieważ serwer SQL zezwala na dostęp tylko z wybranych sieci i wymaga, aby usługa Data Factory utworzyła dla niego prywatny punkt końcowy, który powinien zostać zatwierdzony przed jego użyciem. W komunikacie o błędzie powinien zostać wyświetlony link umożliwiający utworzenie prywatnego punktu końcowego, który można wykonać, aby utworzyć zarządzany prywatny punkt końcowy. Alternatywą jest przejście bezpośrednio do karty Zarządzanie i wykonanie instrukcji w następnej sekcji, aby utworzyć zarządzany prywatny punkt końcowy.
- Pozostaw otwarte okno dialogowe, a następnie przejdź do wybranego serwera SQL.
- Postępuj zgodnie z instrukcjami w tej sekcji , aby zatwierdzić link prywatny.
- Wróć do okna dialogowego. Wybierz ponownie pozycję Testuj połączenie i wybierz pozycję Utwórz , aby wdrożyć połączoną usługę.
Automatycznie przechodzi do okna dialogowego Ustawianie właściwości . W obszarze Tabela wybierz pozycję [dbo].[emp]. Następnie wybierz opcję OK.
Przejdź do karty z potokiem i w zestawie danych ujścia upewnij się, że wybrano pozycję OutputSqlDataset .
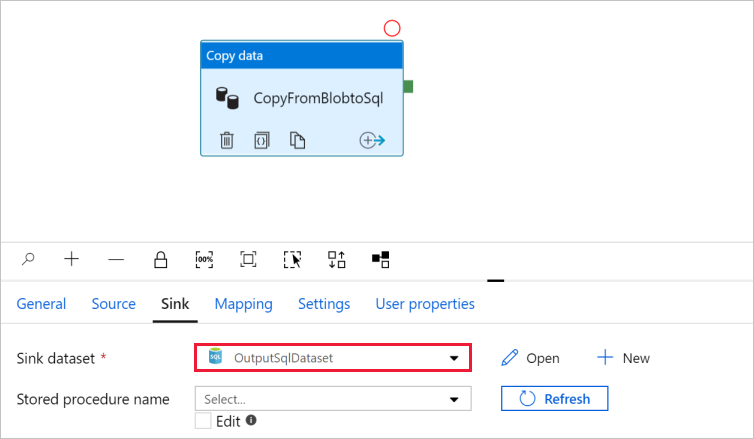
Opcjonalnie można mapować schemat źródła na odpowiedni schemat miejsca docelowego, postępując zgodnie z mapowaniem schematu w działaniu kopiowania.
Tworzenie zarządzanego prywatnego punktu końcowego
Jeśli nie wybrano hiperlinku podczas testowania połączenia, postępuj zgodnie ze ścieżką. Teraz musisz utworzyć zarządzany prywatny punkt końcowy, który połączysz się z utworzoną usługą połączoną.
Przejdź do karty Zarządzanie .
Przejdź do sekcji Zarządzane prywatne punkty końcowe .
Wybierz pozycję + Nowy w obszarze Zarządzane prywatne punkty końcowe.
Wybierz kafelek usługi Azure SQL Database z listy, a następnie wybierz pozycję Kontynuuj.
Wprowadź nazwę wybranego serwera SQL.
Wybierz pozycję Utwórz.
Po kilku sekundach powinno zostać wyświetlone, że utworzony link prywatny wymaga zatwierdzenia.
Wybierz utworzony prywatny punkt końcowy. Możesz zobaczyć hiperlink, który spowoduje zatwierdzenie prywatnego punktu końcowego na poziomie serwera SQL.
Zatwierdzanie łącza prywatnego w programie SQL Server
- W programie SQL Server przejdź do pozycji Połączenia prywatnego punktu końcowego w sekcji Ustawienia .
- Zaznacz pole wyboru dla utworzonego prywatnego punktu końcowego, a następnie wybierz pozycję Zatwierdź.
- Dodaj opis i wybierz pozycję Tak.
- Wróć do sekcji Zarządzane prywatne punkty końcowe na karcie Zarządzanie w usłudze Data Factory.
- Wyświetlenie zatwierdzenia dla prywatnego punktu końcowego powinno potrwać co najmniej jedną minutę.
Debugowanie i publikowanie potoku
Przed opublikowaniem artefaktów (połączone usługi, zestawy danych i potok) w usłudze Data Factory lub własnym repozytorium Git usługi Azure Repos możesz debugować potok.
- Aby debugować potok, wybierz na pasku narzędzi pozycję Debuguj. Na karcie Dane wyjściowe w dolnej części okna wyświetlany jest stan uruchomienia potoku.
- Po pomyślnym uruchomieniu potoku na górnym pasku narzędzi wybierz pozycję Opublikuj wszystko. Ta akcja publikuje jednostki (zestawy danych i potoki) utworzone w usłudze Data Factory.
- Poczekaj na wyświetlenie komunikatu Pomyślnie opublikowano. Aby wyświetlić komunikaty powiadomień, wybierz pozycję Pokaż powiadomienia w prawym górnym rogu (przycisk dzwonka).
Podsumowanie
Potok w tym przykładzie kopiuje dane z usługi Blob Storage do usługi SQL Database przy użyciu prywatnych punktów końcowych w zarządzanej sieci wirtualnej usługi Data Factory. W tym samouczku omówiono:
- Tworzenie fabryki danych.
- Tworzenie potoku z działaniem kopiowania.