Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Wiele razy podczas przetwarzania danych dla zadań ETL należy zmienić nazwy kolumn przed zapisaniem wyników. Czasami jest to konieczne, aby dopasować nazwy kolumn do dobrze znanego schematu docelowego. Innym razem może być konieczne ustawienie nazw kolumn w czasie wykonywania na podstawie zmieniających się schematów. W tym samouczku dowiesz się, jak używać przepływów danych do ustawiania nazw kolumn dla plików docelowych i tabel baz danych dynamicznie przy użyciu zewnętrznych plików konfiguracji i parametrów.
Jeśli jesteś nowym użytkownikiem usługi Azure Data Factory, zobacz Wprowadzenie do usługi Azure Data Factory.
Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto platformy Azure.
- Konto usługi Azure Storage. Magazyn ADLS jest używany jako źródło danych i docelowy magazyn danych. Jeśli nie masz konta magazynu, utwórz je, wykonując czynności przedstawione w artykule Tworzenie konta magazynu platformy Azure.
Tworzenie fabryki danych
W tym kroku utworzysz fabrykę danych i otworzysz interfejs użytkownika usługi Data Factory, aby utworzyć przepływ pracy w fabryce danych.
- Otwórz przeglądarkę Microsoft Edge lub Google Chrome. Obecnie interfejs użytkownika usługi Data Factory jest obsługiwany tylko w przeglądarkach internetowych Przeglądarki Microsoft Edge i Google Chrome.
- W menu po lewej stronie wybierz Utwórz zasób>Integracja>Data Factory
- Na stronie Nowa fabryka danych w obszarze Nazwa wprowadź wartość ADFTutorialDataFactory
- Wybierz subskrypcję platformy Azure, w której chcesz utworzyć fabrykę danych.
- W przypadku grupy zasobów wykonaj jedną z następujących czynności:
- Wybierz pozycję Użyj istniejącej, a następnie wybierz istniejącą grupę zasobów z listy rozwijanej.
- Wybierz pozycję Utwórz nową i wprowadź nazwę grupy zasobów. Aby dowiedzieć się więcej o grupach zasobów, zobacz Zarządzanie zasobami platformy Azure przy użyciu grup zasobów.
- W obszarze Wersja wybierz pozycję V2.
- W obszarze Lokalizacja wybierz lokalizację fabryki danych. Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (na przykład Azure Storage i SQL Database) i obliczenia (na przykład Usługa Azure HDInsight) używane przez fabrykę danych mogą znajdować się w innych regionach.
- Wybierz pozycję Utwórz.
- Po zakończeniu tworzenia zostanie wyświetlone powiadomienie w Centrum powiadomień. Wybierz pozycję Przejdź do zasobu, aby przejść do strony usługi Data Factory.
- Wybierz pozycję Tworzenie i monitorowanie, aby uruchomić interfejs użytkownika usługi Data Factory na osobnej karcie.
Utwórz kanał z czynnością przepływu danych
W tym kroku utworzysz potok zawierający aktywność przepływu danych.
Na stronie głównej usługi ADF wybierz pozycję Utwórz potok.
W zakładce Ogólne dla potoku, wprowadź DeltaLake jako Nazwę potoku.
Na górnym pasku narzędzi fabryki, przesuń suwak debugowanie Przepływu danych włącz. Tryb debugowania umożliwia interaktywne testowanie logiki transformacji względem dynamicznego klastra Spark. Klastry Przepływu Danych potrzebują od 5 do 7 minut na rozgrzanie, a użytkownikom zaleca się najpierw włączyć debugowanie, jeśli planują rozwijać Przepływ Danych. Aby uzyskać więcej informacji, zobacz Tryb debugowania.
W okienku Działania rozwiń akordeon Przenieś i Przekształć . Przeciągnij i upuść działanie Przepływ danych z okienka do kanwy potoku.
W oknie podręcznym Dodawanie Przepływ danych wybierz pozycję Utwórz nową Przepływ danych, a następnie nadaj przepływowi danych nazwę DynaCols. Po zakończeniu wybierz pozycję Zakończ.
Tworzenie dynamicznego mapowania kolumn w przepływach danych
W tym samouczku użyjemy przykładowego pliku ocen filmów i zmienimy nazwy kilku pól w źródle na nowy zestaw kolumn docelowych, które mogą się zmieniać z czasem. Zestawy danych, które utworzysz poniżej, powinny wskazywać na ten plik filmów CSV w twoim koncie usługi Storage Blob lub ADLS Gen2. Pobierz plik filmów tutaj i zapisz go na koncie usługi Azure Storage.
Cele samouczka
Dowiesz się, jak dynamicznie ustawiać nazwy kolumn przy użyciu przepływu danych
- Utwórz zestaw danych źródłowych dla pliku filmów CSV.
- Utwórz zestaw danych do wyszukiwania dla pliku konfiguracji JSON mapowania pól.
- Przekonwertuj kolumny ze źródła na nazwy kolumn docelowych.
Rozpoczynanie od pustej kanwy przepływu danych
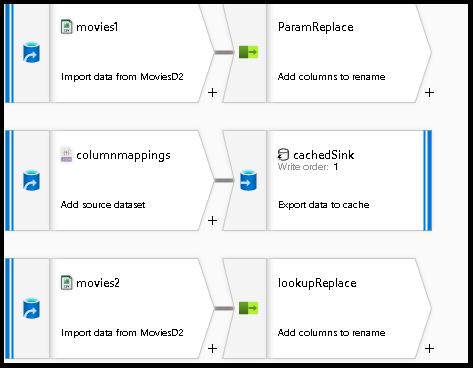
Najpierw skonfigurujmy środowisko przepływu danych dla każdego z mechanizmów opisanych poniżej, aby umieścić dane w usłudze ADLS Gen2.
Wybierz transformację źródłową i wywołaj ją
movies1.Wybierz nowy przycisk obok zestawu danych w dolnym panelu.
Wybierz pozycję Blob lub ADLS Gen2 w zależności od miejsca przechowywania pliku moviesDB.csv powyżej.
Dodaj drugie źródło, którego użyjemy do źródła pliku JSON konfiguracji w celu wyszukania mapowań pól.
Wywołaj to jako
columnmappings.W przypadku zestawu danych wskaż nowy plik JSON, który będzie przechowywać konfigurację mapowania kolumn. Możesz wkleić to do pliku JSON na potrzeby tego przykładowego samouczka:
[ {"prevcolumn":"title","newcolumn":"movietitle"}, {"prevcolumn":"year","newcolumn":"releaseyear"} ]Ustaw to ustawienie źródłowe na
array of documents.Dodaj trzecie źródło i wywołaj je
movies2. Skonfiguruj to dokładnie tak samo jakmovies1.
Mapowanie kolumn sparametryzowanych
W tym pierwszym scenariuszu ustawisz nazwy kolumn wyjściowych w przepływie danych, konfigurując mapowanie kolumn na podstawie dopasowywania przychodzących pól z parametrem, który jest tablicą ciągów określającą kolumny i dopasowując każdy indeks tablicy z porządkowym położeniem kolumn przychodzących. Podczas wykonywania tego przepływu danych z potoku, będzie można ustawić różne nazwy kolumn przy każdym wykonaniu potoku, przekazując tę tablicę ciągów jako parametr do aktywności przepływu danych.
Wróć do projektanta przepływu danych i edytuj przepływ danych utworzony powyżej.
Wybieranie na karcie parametrów
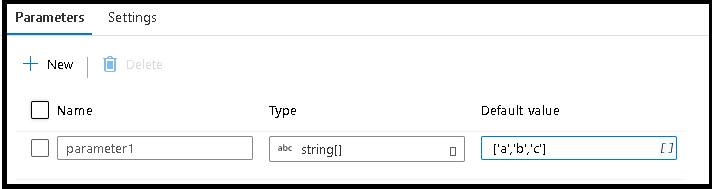
Utwórz nowy parametr i wybierz typ danych tablicy ciągów
W polu wartość domyślna wprowadź wartość
['a','b','c']Użyj górnego
movies1źródła, aby zmodyfikować nazwy kolumn tak, by odpowiadały tym wartościom tablicy.Dodaj przekształcenie typu Wybierz. Przekształcenie Wybierz będzie używane do mapowania kolumn przychodzących do nowych nazw kolumn w danych wyjściowych.
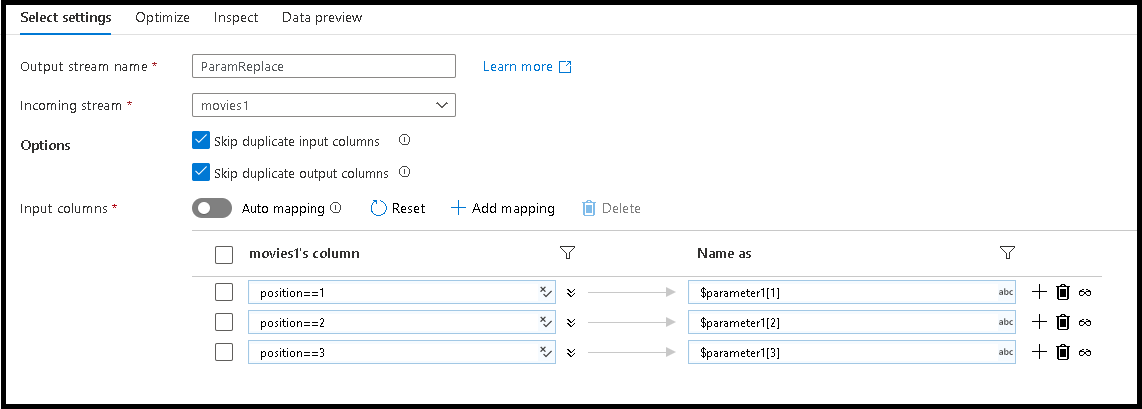
Zmienimy pierwsze trzy nazwy kolumn na nowe nazwy zdefiniowane w parametrze
W tym celu dodaj trzy wpisy mapowania oparte na regułach w dolnym okienku
Dla pierwszej kolumny regułą dopasowania będzie
position==1, a nazwa będzie$parameter1[1]Postępuj zgodnie z tym samym wzorcem dla kolumn 2 i 3
Wybierz zakładki Inspekcja i Podgląd danych w przekształceniu Select, aby wyświetlić nowe wartości nazw kolumn
(a,b,c), zastępując oryginalne nazwy kolumn film, tytuł, gatunek.
Tworzenie buforowanego wyszukiwania mapowań kolumn zewnętrznych
Następnie utworzymy buforowany ujście dla późniejszego wyszukiwania. Pamięć podręczna będzie odczytywać zewnętrzny plik konfiguracyjny JSON, który może być używany do dynamicznego zmieniania nazw kolumn przy każdym wykonaniu przepływu danych.
- Wróć do projektanta przepływu danych i edytuj przepływ danych utworzony powyżej. Dodaj przekształcenie typu 'Sink' do źródła
columnmappings. - Ustaw typ ujścia na
Cache. - W obszarze Ustawienia wybierz
prevcolumnjako kolumnę klucza.
Wyszukiwanie nazw kolumn z buforowanej pamięci zwrotnej
Teraz, gdy zawartość pliku konfiguracji jest przechowywana w pamięci, możesz dynamicznie mapować przychodzące nazwy kolumn na nowe nazwy kolumn wychodzących.
- Wróć do projektanta przepływu danych i edytuj utworzony powyżej przepływ danych. Wybierz transformację źródłową
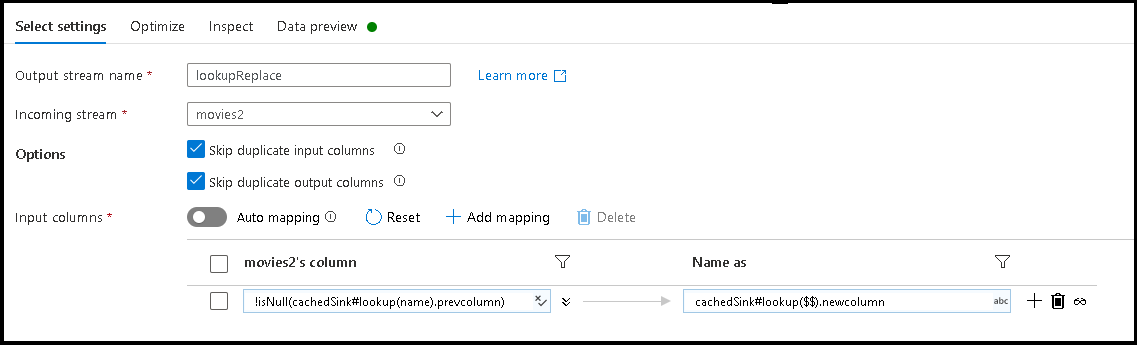
movies2. - Dodaj przekształcenie typu Wybierz. Tym razem użyjemy przekształcenia Wybierz, aby zmienić nazwy kolumn na podstawie nazwy docelowej w pliku konfiguracji JSON przechowywanego w buforowanym ujściu.
- Dodaj mapowanie oparte na regułach. W przypadku warunku dopasowywania użyj następującej formuły:
!isNull(cachedSink#lookup(name).prevcolumn). - Jako nazwę kolumny wyjściowej użyj następującej formuły:
cachedSink#lookup($$).newcolumn. - Znaleźliśmy wszystkie nazwy kolumn, które pasują do właściwości
prevcolumnz zewnętrznego pliku konfiguracyjnego JSON i zmieniliśmy każdą z nich na nową nazwęnewcolumn. - Aby zobaczyć nowe nazwy kolumn z pliku mapowania zewnętrznego, wybierz zakładki Podgląd danych oraz Inspekcja w ramach transformacji Wybierz.