Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Azure Databricks ma wiele narzędzi i interfejsów API do interakcji z plikami w następujących lokalizacjach:
- Katalogi Unity Catalog
- Pliki obszaru roboczego
- Magazyn obiektów w chmurze
- Instalacja systemu PLIKÓW DBFS i katalog główny systemu plików DBFS
- Magazyn efemeryczny dołączony do węzła sterownika klastra
Ten artykuł zawiera przykłady interakcji z plikami w tych lokalizacjach dla następujących narzędzi:
- Apache Spark
- Spark SQL i Databricks SQL
- Narzędzia systemu plików Databricks (
dbutils.fslub%fs) - Interfejs wiersza polecenia usługi Databricks
- Databricks REST API
- Polecenia powłoki Bash (
%sh) - Instalowanie bibliotek z zakresem notatnika przy użyciu
%pip - Pandy
- Narzędzia do zarządzania i przetwarzania plików open source w Pythonie
Ważny
Niektóre operacje w usłudze Databricks, zwłaszcza te korzystające z bibliotek Java lub Scala, są uruchamiane jako procesy JVM, na przykład:
- Określanie zależności pliku JAR przy użyciu
--jarsw konfiguracjach platformy Spark - Wywoływanie
catlubjava.io.Filew notatnikach języka Scala - Niestandardowe źródła danych, takie jak
spark.read.format("com.mycompany.datasource") - Biblioteki ładujące pliki przy użyciu języka Java
FileInputStreamlubPaths.get()
Te operacje nie obsługują odczytu ani zapisu do woluminów katalogu Unity Catalog lub plików obszaru roboczego przy użyciu standardowych ścieżek plików, takich jak /Volumes/my-catalog/my-schema/my-volume/my-file.csv. Jeśli musisz uzyskać dostęp do plików woluminów lub plików obszaru roboczego z zależności JAR lub bibliotek opartych na JVM, najpierw skopiuj pliki do lokalnej pamięci przy użyciu języka Python lub poleceń %sh, takich jak %sh mv.. Nie należy używać %fs ani dbutils.fs, które wykorzystują maszynę JVM. Aby uzyskać dostęp do plików już skopiowanych lokalnie, użyj poleceń specyficznych dla języka, takich jak Python shutil lub użyj %sh poleceń. Jeśli plik musi być obecny podczas uruchamiania klastra, użyj skryptu inicjowania, aby najpierw przenieść plik. Zobacz Czym są skrypty init?.
Czy muszę podać schemat identyfikatora URI, aby uzyskać dostęp do danych?
Ścieżki dostępu do danych w usłudze Azure Databricks są zgodne z jednym z następujących standardów:
ścieżki w stylu URI obejmują schemat URI. W przypadku rozwiązań dostępu do danych natywnych dla usługi Databricks schematy identyfikatorów URI są opcjonalne w większości przypadków użycia. W przypadku bezpośredniego uzyskiwania dostępu do danych w magazynie obiektów w chmurze należy podać prawidłowy schemat identyfikatora URI dla typu magazynu.
diagram ścieżek identyfikatora URI
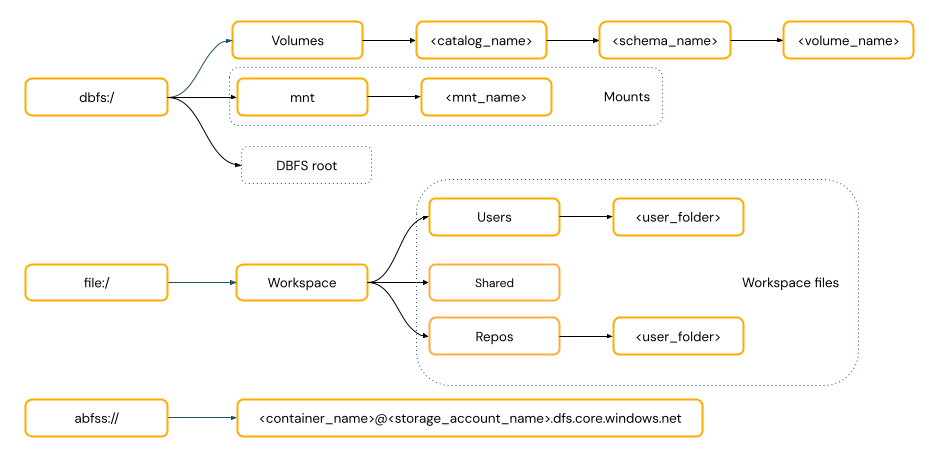
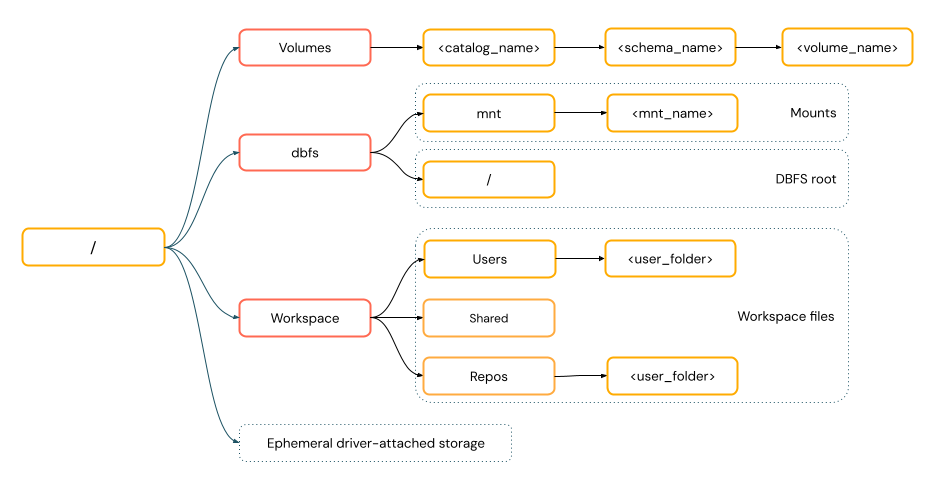
ścieżki w stylu POSIX zapewniają dostęp do danych względem katalogu głównego dysku sterownika (
/). Ścieżki stylu POSIX nigdy nie wymagają schematu. Za pomocą woluminów Unity Catalog lub zamocowań DBFS można zapewnić dostęp zgodny z POSIX do danych w chmurowej pamięci obiektowej. Wiele frameworków uczenia maszynowego i innych modułów open-source Pythona wymaga FUSE i mogą używać tylko ścieżek w stylu POSIX.diagram ścieżek
Notatka
Operacje na plikach wymagające dostępu do danych FUSE nie mogą uzyskiwać bezpośredniego dostępu do chmurowego magazynu obiektów przy użyciu URI. Usługa Databricks zaleca używanie woluminów Unity Catalogu do konfiguracji dostępu do tych lokalizacji dla FUSE.
W przypadku przetwarzania danych skonfigurowanego z dedykowanym trybem dostępu (dawniej tryb dostępu pojedynczego użytkownika) i środowiskiem Databricks Runtime 14.3 lub nowszym, Scala obsługuje FUSE dla wolumenów w Unity Catalog i plików obszarów roboczych, z wyjątkiem podprocesów pochodzących z języka Scala, takich jak polecenie "cat /Volumes/path/to/file".!!w języku Scala.
Praca z plikami w woluminach Unity Catalog
Databricks zaleca używanie woluminów Unity Catalog do konfigurowania dostępu do plików danych innych niż tabelaryczne przechowywanych w chmurowym magazynie obiektów. Aby uzyskać pełną dokumentację dotyczącą zarządzania plikami w woluminach, w tym szczegółowych instrukcji i najlepszych rozwiązań, zobacz Praca z plikami w woluminach katalogu Unity.
W poniższych przykładach przedstawiono typowe operacje przy użyciu różnych narzędzi i interfejsów:
| Narzędzie | Przykład |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL i Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`;LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Narzędzia do systemu plików Databricks | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/")%fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Interfejs wiersza polecenia usługi Databricks | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create{"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Polecenia powłoki Bash | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| Instalacje bibliotekarne | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandas | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| System operacyjny Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
Aby uzyskać informacje o ograniczeniach woluminów i rozwiązaniach alternatywnych, zobacz Ograniczenia pracy z plikami w woluminach.
Praca z plikami przestrzeni roboczej
Pliki w obszarze roboczym usługi Databricks to pliki przechowywane na koncie magazynu przypisanym do obszaru roboczego . Pliki obszaru roboczego umożliwiają przechowywanie i uzyskiwanie dostępu do plików, takich jak notesy, pliki kodu źródłowego, pliki danych i inne zasoby obszaru roboczego.
Ważny
Ponieważ pliki obszarów roboczych mają ograniczenia rozmiaru, usługa Databricks zaleca przechowywanie tylko małych plików danych w tym miejscu głównie na potrzeby programowania i testowania. Aby uzyskać zalecenia dotyczące miejsca przechowywania innych typów plików, zobacz Typy plików.
| Narzędzie | Przykład |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL i Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Narzędzia do systemu plików Databricks | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/")%fs ls file:/Workspace/Users/<user-folder>/ |
| Interfejs wiersza polecenia usługi Databricks | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete{"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Polecenia powłoki Bash | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| Instalacje bibliotekarne | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandas | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| System operacyjny Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
Notatka
Schemat file:/ jest wymagany podczas pracy z Narzędziami Databricks, Apache Spark lub SQL.
W obszarach roboczych, w których jest wyłączony katalog główny i instalacja systemu plików DBFS, można również użyć dbfs:/Workspace do uzyskiwania dostępu do plików obszaru roboczego za pomocą narzędzi usługi Databricks. Wymaga to środowiska Databricks Runtime 13.3 LTS lub nowszego. Zobacz Wyłączanie dostępu do katalogu głównego systemu plików DBFS i instalacji w istniejącym obszarze roboczym usługi Azure Databricks.
W celu zapoznania się z ograniczeniami dotyczącymi pracy z plikami obszarów roboczych, zobacz Ograniczenia.
Dokąd trafiają usunięte pliki z obszaru roboczego?
Usunięcie pliku z obszaru roboczego powoduje wysłanie go do kosza. Możesz odzyskać lub trwale usunąć pliki z kosza przy użyciu interfejsu użytkownika.
Zobacz Usuwanie obiektu.
Praca z plikami w magazynie obiektów w chmurze
Databricks zaleca używanie woluminów w Unity Catalog do konfigurowania bezpiecznego dostępu do plików w magazynie obiektów w chmurze. Jeśli zdecydujesz się uzyskać dostęp do danych bezpośrednio w magazynie obiektów w chmurze przy użyciu identyfikatorów URI, musisz skonfigurować uprawnienia. Zobacz Zarządzane i zewnętrzne woluminy.
W poniższych przykładach używane są identyfikatory URI do uzyskiwania dostępu do danych w magazynie obiektów w chmurze:
| Narzędzie | Przykład |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL i Databricks SQL |
SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`;
LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path';
|
| Narzędzia do systemu plików Databricks |
dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/")
%fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/
|
| Interfejs wiersza polecenia usługi Databricks | Nieobsługiwane |
| Databricks REST API | Nieobsługiwane |
| Polecenia powłoki Bash | Nieobsługiwane |
| Instalacje bibliotekarne | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Pandas | Nieobsługiwane |
| System operacyjny Python | Nieobsługiwane |
Praca z plikami w instalacjach systemu plików DBFS i katalogu głównym systemu plików DBFS
Ważny
Zarówno instalacja główna systemu plików DBFS, jak i DBFS są przestarzałe i nie są zalecane przez usługę Databricks. Nowe konta są aprowidowane bez dostępu do tych funkcji. Databricks zaleca używanie woluminów konfiguracji Unity, lokalizacji zewnętrznych lub plików obszaru roboczego.
| Narzędzie | Przykład |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL i Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Narzędzia do systemu plików Databricks | dbutils.fs.ls("/mnt/path")%fs ls /mnt/path |
| Interfejs wiersza polecenia usługi Databricks | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Polecenia powłoki Bash | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| Instalacje bibliotekarne | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandas | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| System operacyjny Python | os.listdir('/dbfs/mnt/path/to/directory') |
Notatka
Schemat dbfs:/ jest wymagany podczas pracy z interfejsem wiersza polecenia usługi Databricks.
Praca z plikami w przechowalni efemerycznej dołączonej do węzła sterownika
Tymczasowa pamięć masowa dołączona do węzła sterownika to pamięć blokowa z wbudowanym dostępem do ścieżki opartej na systemie POSIX. Wszystkie dane przechowywane w tej lokalizacji znikają po zakończeniu lub ponownym uruchomieniu klastra.
| Narzędzie | Przykład |
|---|---|
| Apache Spark | Nieobsługiwane |
| Spark SQL i Databricks SQL | Nieobsługiwane |
| Narzędzia do systemu plików Databricks | dbutils.fs.ls("file:/path")%fs ls file:/path |
| Interfejs wiersza polecenia usługi Databricks | Nieobsługiwane |
| Databricks REST API | Nieobsługiwane |
| Polecenia powłoki Bash | %sh curl http://<address>/text.zip > /tmp/text.zip |
| Instalacje bibliotekarne | Nieobsługiwane |
| Pandas | df = pd.read_csv('/path/to/data.csv') |
| System operacyjny Python | os.listdir('/path/to/directory') |
Notatka
Schemat file:/ jest wymagany podczas pracy z narzędziami usługi Databricks.
Przenoszenie danych z magazynu efemerycznego do woluminów
Możesz chcieć uzyskać dostęp do danych pobranych lub zapisanych w magazynie efemerycznym przy użyciu platformy Apache Spark. Nie wszystkie operacje mogą bezpośrednio uzyskiwać tutaj dostępu do danych, ponieważ pamięć efemeryczna jest dołączona do sterownika, a platforma Spark jest silnikiem przetwarzania rozproszonego. Załóżmy, że musisz przenieść dane z systemu plików sterownika do woluminów Unity Catalog. W takim przypadku można kopiować pliki przy użyciu poleceń magicznych lub narzędzi Databricks , jak w następujących przykładach:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>