Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Notesy Databricks obsługują formatowanie kodu, autouzupełnianie, wiele języków oraz polecenia magiczne do programowania w Pythonie, SQL, Scali i R.
Aby uzyskać więcej informacji na temat zaawansowanych funkcji dostępnych w edytorze, takich jak autouzupełnianie, wybór zmiennych, obsługa wielu kursorów i porównania obok siebie, zobacz Nawigacja po notatniku i edytorze plików Databricks.
Gdy używasz notesu lub edytora plików, kod Genie jest dostępny, aby ułatwić generowanie, objaśnienie i debugowanie kodu. Aby uzyskać więcej informacji, zobacz Use Genie Code (Używanie kodu Genie ).
Notatniki usługi Databricks obejmują również wbudowany interaktywny debuger dla notatników Pythona. Zobacz Debugowanie notesów Databricks.
Ważne
Notebook musi być dołączony do aktywnej sesji compute, aby uzyskać dostęp do funkcji wspomagania kodu, takich jak autouzupełnianie, formatowanie kodu Python i debuger.
Modularyzacja kodu
W środowisku Databricks Runtime 11.3 LTS i nowszym można tworzyć pliki kodu źródłowego i zarządzać nimi w obszarze roboczym Azure Databricks, a następnie importować te pliki do notesów zgodnie z potrzebami.
Aby uzyskać więcej informacji na temat pracy z plikami kodu źródłowego, zobacz Udostępnianie kodu między notatnikami Databricks oraz Praca z modułami Python i R.
Formatowanie komórek kodu
Azure Databricks udostępnia narzędzia, które umożliwiają formatowanie kodu Python i SQL w komórkach notesu. Te narzędzia zmniejszają wysiłek potrzebny do utrzymania formatowania kodu oraz pomagają w narzucaniu jednolitych standardów kodowania w notesach.
Python biblioteka formaterów
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
Azure Databricks obsługuje formatowanie kodu Python przy użyciu black w notesie. Notatnik musi być podłączony do klastra z zainstalowanymi pakietami Python black i tokenize-rt.
W Databricks Runtime 11.3 LTS i nowszym środowisku Azure Databricks preinstaluje black i tokenize-rt. Możesz użyć formattera bezpośrednio, bez konieczności instalowania tych bibliotek.
W środowisku Databricks Runtime 10.4 LTS i niższym należy zainstalować black==22.3.0 i tokenize-rt==4.2.1 z PyPI w notesie lub klastrze, aby korzystać z formatera Pythona. W notesie można uruchomić następujące polecenie:
%pip install black==22.3.0 tokenize-rt==4.2.1
lub zainstaluj bibliotekę w klastrze.
Aby uzyskać więcej informacji na temat instalowania bibliotek, zobacz Python zarządzanie środowiskami.
W przypadku plików i notesów w folderach Usługi Git usługi Databricks można skonfigurować formater Python na podstawie pliku pyproject.toml. Aby użyć tej funkcji, utwórz plik pyproject.toml w katalogu głównym folderu Git i skonfiguruj go zgodnie z formatem konfiguracji Black. Edytuj sekcję [tool.black] w pliku . Konfiguracja jest stosowana podczas formatowania dowolnego pliku i notesu w tym folderze Git.
Jak sformatować komórki Python i SQL
Aby sformatować kod, musisz mieć uprawnienie CAN EDIT w notesie.
Azure Databricks używa niestandardowego formatera SQL do formatowania kodu SQL i black formatera kodu dla języka Python.
Formater można uruchomić w następujący sposób:
Formatowanie pojedynczej komórki
- Skrót klawiaturowy: naciśnij Cmd+Shift+F.
- Menu kontekstowe polecenia:
- Formatuj komórkę SQL: wybierz Format SQL z menu kontekstowego komórki SQL. Ten element menu jest widoczny tylko w komórkach zeszytu SQL lub w tych, które używają
%sqlmagii językowej. - Sformatuj komórkę Python: wybierz Format Python w rozwijanym menu kontekstu poleceń komórki Python. Ten element menu jest widoczny tylko w komórkach notatnika Python lub tych z
%pythonlanguage magic.
- Formatuj komórkę SQL: wybierz Format SQL z menu kontekstowego komórki SQL. Ten element menu jest widoczny tylko w komórkach zeszytu SQL lub w tych, które używają
- Menu notatnika Edit: wybierz komórkę Python lub SQL, a następnie wybierz Edytuj> Formatuj komórki.
Formatowanie wielu komórek
Zaznacz wiele komórek, a następnie wybierz Formatuj komórkę(i) > Edytuj. W przypadku zaznaczenia komórek więcej niż jednego języka sformatowane są tylko komórki SQL i Python. Obejmuje to te, które używają
%sqli%python.Formatuj wszystkie komórki Python i SQL w notesie
Wybierz Edytuj formatowanie notesu>. Jeśli notes zawiera więcej niż jeden język, zostaną sformatowane tylko komórki SQL i Python. Obejmuje to te, które używają
%sqli%python.
Aby dostosować sposób formatowania zapytań SQL, zobacz Instrukcje JĘZYKA SQL w formacie niestandardowym.
Ograniczenia formatowania kodu
- Black wymusza standardy PEP 8 dla wcięcia na 4 spacje. Wcięcie nie jest konfigurowalne.
- Formatowanie osadzonych ciągów znaków języka Python wewnątrz funkcji SQL, zdefiniowanej przez użytkownika, nie jest obsługiwane. Podobnie formatowanie ciągów SQL wewnątrz funkcji UDF w Pythonie nie jest obsługiwane.
Języki kodu w notesach
Ustaw język domyślny
Domyślny język notesu jest wyświetlany poniżej nazwy notesu.

Aby zmienić język domyślny, kliknij przycisk języka i wybierz nowy język z menu rozwijanego. Aby upewnić się, że istniejące polecenia nadal działają, polecenia poprzedniego języka domyślnego są automatycznie prefiksowane za pomocą polecenia magicznego języka.
Mieszaj języki
Komórki domyślnie używają języka notesu. Język domyślny można zastąpić w komórce, klikając przycisk języka i wybierając język z menu rozwijanego.
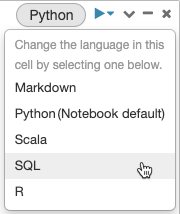
Alternatywnie możesz użyć polecenia magicznego języka %<language> na początku komórki. Obsługiwane polecenia magic to: %python, %r, %scala i %sql.
Uwaga
Po wywołaniu polecenia magicznego języka to polecenie jest wysyłane do środowiska REPL w kontekście wykonywania notatnika. Zmienne zdefiniowane w jednym języku (a tym samym w REPL dla tego języka) nie są dostępne w REPL innego języka. REPL-e mogą współdzielić stan tylko za pośrednictwem zasobów zewnętrznych, takich jak pliki w DBFS lub obiekty w magazynie obiektów.
Notatniki obsługują również kilka dodatkowych poleceń magicznych.
-
%sh: umożliwia uruchamianie kodu powłoki w notatniku. Aby spowodować niepowodzenie komórki, jeśli polecenie powłoki ma stan zakończenia inny niż zero, dodaj opcję-e. To polecenie jest uruchamiane tylko w sterowniku platformy Apache Spark, a nie na pracownikach. Aby uruchomić polecenie powłoki na wszystkich węzłach, użyj skryptu init. -
%fs: umożliwia korzystanie zdbutilspoleceń systemu plików. Aby na przykład uruchomić poleceniedbutils.fs.ls, aby wyświetlić listę plików, możesz określić%fs lszamiast tego. Aby uzyskać więcej informacji, zobaczWork with files on Azure Databricks (Praca z plikami w witrynie Azure Databricks -
%md: umożliwia dołączenie różnych typów dokumentacji, w tym tekstu, obrazów i formuł matematycznych oraz równań. Zobacz następną sekcję.
Wyróżnianie składni SQL i autouzupełnianie w poleceniach Python
Wyróżnianie składni i SQL autocomplete są dostępne w przypadku używania języka SQL wewnątrz polecenia Pythona, takiego jak spark.sql.
Eksplorowanie wyników komórek SQL
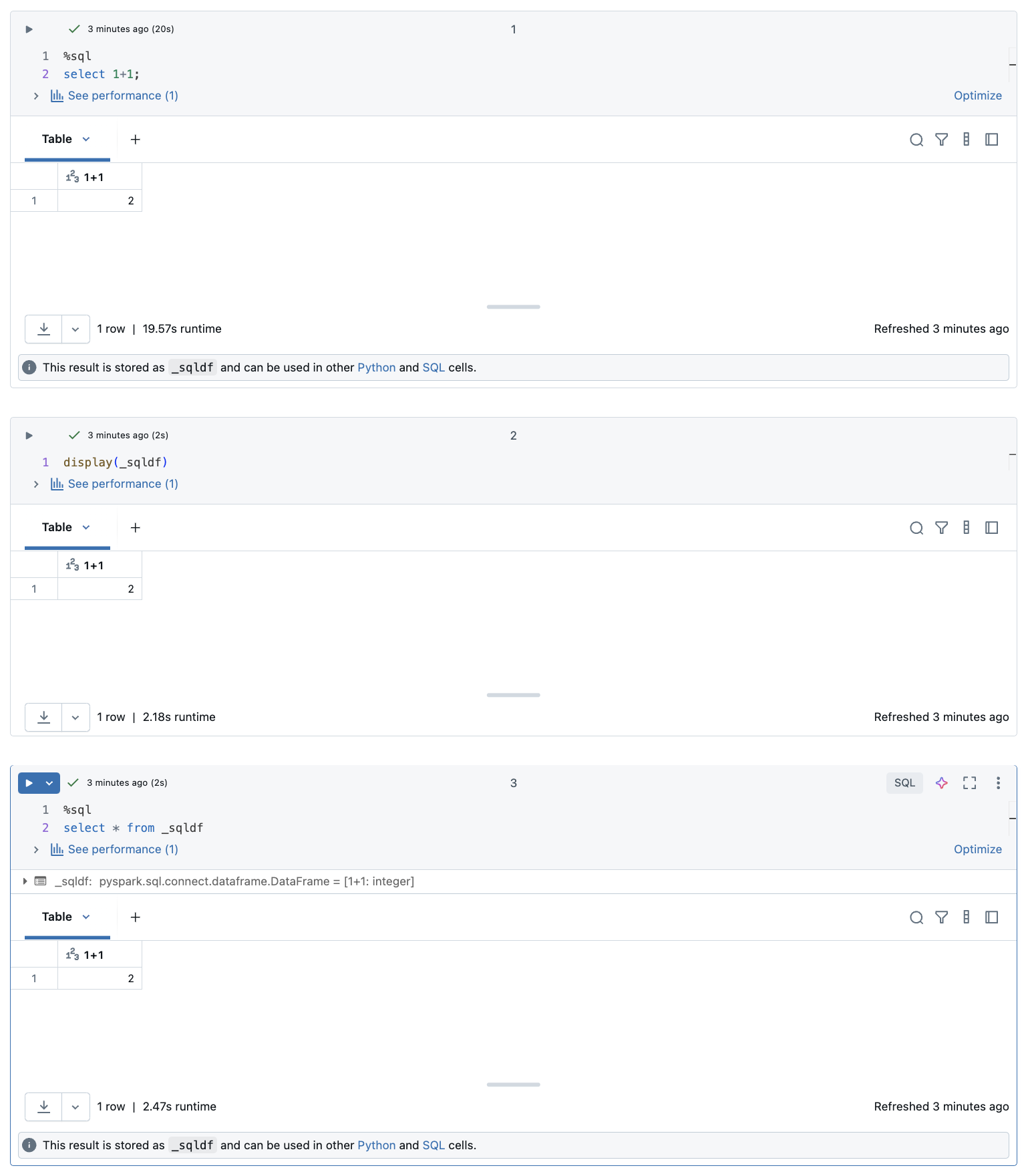
W notesie usługi Databricks wyniki z komórki języka SQL są automatycznie udostępniane jako niejawna ramka danych przypisana do zmiennej _sqldf. Następnie możesz użyć tej zmiennej w dowolnym Python i komórkach SQL uruchamianych później, niezależnie od ich położenia w notesie.
Uwaga
Ta funkcja ma następujące ograniczenia:
- Zmienna
_sqldfnie jest dostępna w notesach korzystających z usługi SQL Warehouse na potrzeby obliczeń. - Używanie
_sqldfw kolejnych komórkach Python jest obsługiwane w środowisku Databricks Runtime 13.3 lub nowszym. - Używanie
_sqldfw kolejnych komórkach SQL jest obsługiwane tylko w środowisku Databricks Runtime 14.3 lub nowszym. - Jeśli zapytanie używa słów kluczowych
CACHE TABLElubUNCACHE TABLE, zmienna jest niedostępna_sqldf.
Poniższy zrzut ekranu przedstawia sposób użycia _sqldf w kolejnych komórkach Python i SQL:
Ważne
Zmienna _sqldf jest ponownie przypisywana za każdym razem, gdy jest uruchamiana komórka SQL. Aby uniknąć utraty odwołania do określonego wyniku ramki danych, przed uruchomieniem następnej komórki SQL przypisz ją do nowej nazwy zmiennej:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
Równoległe uruchamianie komórek SQL
Gdy polecenie jest uruchomione, a notatnik jest dołączony do klastra interaktywnego, możesz uruchomić komórkę SQL jednocześnie z bieżącym poleceniem. Komórka SQL jest wykonywana w nowej sesji równoległej.
Aby uruchomić komórkę równolegle:
Kliknij przycisk Uruchom teraz. Komórka jest natychmiast wykonywana.
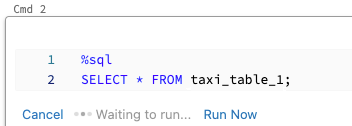
Ponieważ komórka jest uruchamiana w nowej sesji, widoki tymczasowe, funkcje zdefiniowane przez użytkownika i implicit Python DataFrame (_sqldf) nie są obsługiwane dla komórek wykonywanych równocześnie. Ponadto podczas równoległego wykonywania są używane domyślne nazwy wykazu i bazy danych. Jeśli kod odwołuje się do tabeli w innym wykazie lub bazie danych, musisz określić nazwę tabeli przy użyciu przestrzeni nazw na poziomie trzech poziomów (catalog.schema.table).
Uruchamianie komórek SQL w usłudze SQL Warehouse
Polecenia SQL można uruchamiać w notesie Databricks na magazynie SQL, rodzaju obliczeniowego zoptymalizowanego pod kątem analizy SQL. Zobacz Używanie notesu w środowisku SQL Warehouse.
Użyj poleceń magicznych
Notesy usługi Databricks obsługują różne polecenia magiczne, które rozszerzają funkcjonalność poza standardową składnię, aby uprościć typowe zadania. Magie linii są poprzedzone prefiksem % i stosowane do pojedynczego wiersza. Magia komórek jest poprzedzona prefiksem %% i stosowana do całej treści komórki.
| Polecenie Magiczne | Przykład | Opis |
|---|---|---|
%python |
%pythonprint("Hello") |
Przełącz język komórek na Python. Wykonuje kod Python w komórce. |
%r |
%rprint("Hello") |
Przełącz język komórek na język R. Wykonuje kod języka R w komórce. |
%scala |
%scalaprintln("Hello") |
Przełącz język komórek na Scala. Wykonuje kod Scala w komórce. |
%sql |
%sqlSELECT * FROM table |
Przełącz język komórek na język SQL. Wyniki są dostępne jako _sqldf w komórkach Python/SQL. |
%md |
%md# TitleContent here |
Przełącz język komórek na język Markdown. Renderuje zawartość języka Markdown w komórce. Obsługuje tekst, obrazy, formuły i LaTeX. |
%pip |
%pip install pandas |
Zainstaluj pakiety Python (w zakresie notesu). Zobacz biblioteki Pythona w zakresie notebooka. |
%run |
%run /path/to/notebook |
Wykonaj inny notatnik, importując jego funkcje i zmienne. Zobacz Przepływy pracy notesu. |
%fs |
%fs ls /path |
Wykonaj polecenia systemu plików dbutils. Skrócona notacja dla poleceń dbutils.fs. Zobacz Praca z plikami. |
%sh |
%sh ls -la |
Wykonaj polecenia powłoki. Działa tylko w węźle sterownika. Użyj -e, aby zgłosić błąd w przypadku błędu. |
%tensorboard |
%tensorboard --logdir /logs |
Wyświetl interfejs użytkownika TensorBoard jako wbudowany. Dostępne tylko w usłudze Databricks Runtime ML. Zobacz TensorBoard. |
%set_cell_max_output_size_in_mb |
%set_cell_max_output_size_in_mb 10 |
Ustaw maksymalny rozmiar danych wyjściowych komórki. Zakres: 1–20 MB. Dotyczy wszystkich kolejnych komórek w notesie. |
%skip |
%skipprint("This won't run") |
Pomiń wykonanie komórek kodu. Uniemożliwia uruchomienie komórki podczas wykonywania notesu. |
%%profile |
%%profilemy_function() |
Profilowanie wykonywania kodu w Pythonie. Wyświetla hierarchiczne drzewo wywołań z informacjami o czasie. Wymaga środowiska Databricks Runtime 17.2 lub nowszego. |
%%oprofile |
%%oprofilemy_function() |
Profilowanie tworzenia obiektów w trakcie wykonywania komórki. Wyświetla tabelę utworzonych nowych obiektów sieci pogrupowanych według typu. Wymaga środowiska Databricks Runtime 17.2 lub nowszego. |
%uv pip |
%uv pip install simplejson |
Instaluj pakiety języka Python (w zakresie notesu) i zarządzaj nimi za pomocą uv oraz standardowych podpoleceń pip (install, uninstall, list, show, freeze, check, tree). Zobacz Szybsze instalowanie za pomocą polecenia %uv pip. |
Uwaga
IPython Automagic: Notatniki Databricks mają domyślnie włączoną funkcję automagii IPython, co umożliwia działanie niektórych poleceń, takich jak pip, bez prefiksu %. Na przykład pip install pandas działa tak samo jak %pip install pandas.
Ważne
- Zmienne i stan są izolowane między różnymi repozytoriami języka. Na przykład zmienne Python nie są dostępne w komórkach Scala.
- Komórka notesu może mieć tylko jedno polecenie magiczne i musi znajdować się w pierwszym wierszu komórki.
-
%runmusi znajdować się samodzielnie w komórce, ponieważ uruchamia cały notebook w trybie inline. - W przypadku korzystania z
%pipw środowisku Databricks Runtime 12.2 LTS i poniżej umieść wszystkie polecenia instalacji pakietu na początku notesu, ponieważ stan Python jest resetowany po instalacji.