Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten samouczek przeprowadza cię przez tworzenie agenta sztucznej inteligencji, który korzysta jednocześnie z mechanizmów wyszukiwania i narzędzi.
Jest to samouczek na poziomie pośrednim, który zakłada, że znasz podstawy tworzenia agenta w usłudze Databricks. Jeśli dopiero zaczynasz kompilować agentów, zobacz Wprowadzenie do agentów sztucznej inteligencji.
Przykładowy notes zawiera cały kod używany w samouczku.
W tym samouczku omówiono niektóre podstawowe wyzwania związane z tworzeniem aplikacji generacyjnych sztucznej inteligencji:
- Usprawnianie środowiska programistycznego dla typowych zadań, takich jak tworzenie narzędzi i debugowanie wykonywania agenta.
- Wyzwania operacyjne, takie jak:
- Konfiguracja agenta śledzenia
- Definiowanie danych wejściowych i wyjściowych w przewidywalny sposób
- Zarządzanie wersjami zależności
- Kontrola wersji i wdrażanie
- Mierzenie i poprawianie jakości i niezawodności agenta.
Dla ułatwienia, w tym samouczku zastosowane jest podejście bazujące na użyciu pamięci operacyjnej, które umożliwia wyszukiwanie słów kluczowych w zestawie danych zawierającym fragmentowaną dokumentację Databricks.
Przykładowy notatnik
Ten samodzielny notebook został zaprojektowany, aby szybko umożliwić Ci pracę z agentami Mosaic AI przy użyciu przykładowego zbioru dokumentów. Jest gotowy do uruchomienia bez wymaganej konfiguracji ani danych.
Demo agenta Mosaic AI
Tworzenie agenta i narzędzi
Framework Mosaic AI Agent obsługuje wiele różnych struktur autorskich. W tym przykładzie użyto języka LangGraph do zilustrowania pojęć, ale nie jest to samouczek langgraph.
Aby zapoznać się z przykładami innych obsługiwanych platform, zobacz Tworzenie agenta sztucznej inteligencji i wdrażanie go w aplikacjach usługi Databricks.
Pierwszym krokiem jest utworzenie agenta. Należy określić klienta LLM i listę narzędzi. Pakiet Python databricks-langchain obejmuje klientów kompatybilnych z LangChain i LangGraph zarówno dla LLM-ów Databricks, jak i narzędzi zarejestrowanych w katalogu Unity.
Punkt końcowy musi być funkcją wywołującą API modelu Foundation lub model zewnętrzny z użyciem AI Gateway. Zobacz Obsługiwane modele.
from databricks_langchain import ChatDatabricks
llm = ChatDatabricks(endpoint="databricks-meta-llama-3-3-70b-instruct")
Poniższy kod definiuje funkcję, która tworzy agenta na podstawie modelu i niektórych narzędzi, omawiając wewnętrzne elementy tego kodu agenta, wykracza poza zakres tej strony. Aby uzyskać więcej informacji na temat tworzenia agenta LangGraph, zobacz dokumentację LangGraph.
from typing import Optional, Sequence, Union
from langchain_core.language_models import LanguageModelLike
from langchain_core.runnables import RunnableConfig, RunnableLambda
from langchain_core.tools import BaseTool
from langgraph.graph import END, StateGraph
from langgraph.graph.graph import CompiledGraph
from langgraph.prebuilt.tool_executor import ToolExecutor
from mlflow.langchain.chat_agent_langgraph import ChatAgentState, ChatAgentToolNode
def create_tool_calling_agent(
model: LanguageModelLike,
tools: Union[ToolExecutor, Sequence[BaseTool]],
agent_prompt: Optional[str] = None,
) -> CompiledGraph:
model = model.bind_tools(tools)
def routing_logic(state: ChatAgentState):
last_message = state["messages"][-1]
if last_message.get("tool_calls"):
return "continue"
else:
return "end"
if agent_prompt:
system_message = {"role": "system", "content": agent_prompt}
preprocessor = RunnableLambda(
lambda state: [system_message] + state["messages"]
)
else:
preprocessor = RunnableLambda(lambda state: state["messages"])
model_runnable = preprocessor | model
def call_model(
state: ChatAgentState,
config: RunnableConfig,
):
response = model_runnable.invoke(state, config)
return {"messages": [response]}
workflow = StateGraph(ChatAgentState)
workflow.add_node("agent", RunnableLambda(call_model))
workflow.add_node("tools", ChatAgentToolNode(tools))
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
routing_logic,
{
"continue": "tools",
"end": END,
},
)
workflow.add_edge("tools", "agent")
return workflow.compile()
Definiowanie narzędzi agenta
Narzędzia to podstawowa koncepcja tworzenia agentów. Zapewniają one możliwość integracji modułów LLM z kodem zdefiniowanym przez człowieka. Po otrzymaniu monitu i listy narzędzi, LLM generuje argumenty do wywołania narzędzia. Aby uzyskać więcej informacji na temat narzędzi i ich używania z agentami Mosaic AI, zobacz narzędzia agentów AI.
Pierwszym krokiem jest utworzenie narzędzia wyodrębniania słów kluczowych na podstawie serwera TF-IDF. W tym przykładzie użyto biblioteki scikit-learn i narzędzia Unity Catalog.
Pakiet databricks-langchain zapewnia wygodny sposób pracy z narzędziami Unity Catalog. Poniższy kod ilustruje sposób implementowania i rejestrowania narzędzia wyodrębniania słów kluczowych.
Uwaga
Obszar roboczy usługi Databricks ma wbudowane narzędzie system.ai.python_exec, którego można użyć do rozszerzania agentów, umożliwiających uruchamianie skryptów języka Python w odizolowanym środowisku. Inne przydatne wbudowane narzędzia obejmują połączenia zewnętrzne i funkcje sztucznej inteligencji .
from databricks_langchain.uc_ai import (
DatabricksFunctionClient,
UCFunctionToolkit,
set_uc_function_client,
)
uc_client = DatabricksFunctionClient()
set_uc_function_client(uc_client)
# Change this to your catalog and schema
CATALOG = "main"
SCHEMA = "my_schema"
def tfidf_keywords(text: str) -> list[str]:
"""
Extracts keywords from the provided text using TF-IDF.
Args:
text (string): Input text.
Returns:
list[str]: List of extracted keywords in ascending order of importance.
"""
from sklearn.feature_extraction.text import TfidfVectorizer
def keywords(text, top_n=5):
vec = TfidfVectorizer(stop_words="english")
tfidf = vec.fit_transform([text]) # Convert text to TF-IDF matrix
indices = tfidf.toarray().argsort()[0, -top_n:] # Get indices of top N words
return [vec.get_feature_names_out()[i] for i in indices]
return keywords(text)
# Create the function in the Unity Catalog catalog and schema specified
# When you use `.create_python_function`, the provided function's metadata
# (docstring, parameters, return type) are used to create a tool in the specified catalog and schema.
function_info = uc_client.create_python_function(
func=tfidf_keywords,
catalog=CATALOG,
schema=SCHEMA,
replace=True, # Set to True to overwrite if the function already exists
)
print(function_info)
Oto wyjaśnienie powyższego kodu:
- Tworzy klienta korzystającego z usługi Unity Catalog w obszarze roboczym usługi Databricks jako "rejestru" do tworzenia i odnajdywania narzędzi.
- Definiuje funkcję języka Python, która wykonuje wyodrębnianie słów kluczowych TF-IDF.
- Rejestruje funkcję języka Python jako funkcję Unity Catalog.
Ten przepływ pracy rozwiązuje kilka typowych problemów. Masz teraz centralny rejestr narzędzi, które, podobnie jak inne obiekty w Unity Catalog, mogą być zarządzane. Jeśli na przykład firma ma standardowy sposób obliczania wewnętrznej stopy zwrotu, możesz zdefiniować ją jako funkcję w Unity Catalog oraz przyznać dostęp wszystkim użytkownikom lub agentom z rolą FinancialAnalyst.
Aby umożliwić korzystanie z tego narzędzia przez agenta LangChain, użyj zestawu UCFunctionToolkit, który tworzy kolekcję narzędzi, aby udostępnić je LLM do wyboru.
# Use ".*" here to specify all the tools in the schema, or
# explicitly list functions by name
# uc_tool_names = [f"{CATALOG}.{SCHEMA}.*"]
uc_tool_names = [f"{CATALOG}.{SCHEMA}.tfidf_keywords"]
uc_toolkit = UCFunctionToolkit(function_names=uc_tool_names)
Poniższy kod pokazuje, jak przetestować narzędzie:
uc_toolkit.tools[0].invoke({ "text": "The quick brown fox jumped over the lazy brown dog." })
Poniższy kod tworzy agenta, który używa narzędzia wyodrębniania słów kluczowych.
import mlflow
mlflow.langchain.autolog()
agent = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools])
agent.invoke({"messages": [{"role": "user", "content":"What are the keywords for the sentence: 'the quick brown fox jumped over the lazy brown dog'?"}]})
W wynikowym śladzie widać, że LLM wybrało narzędzie.
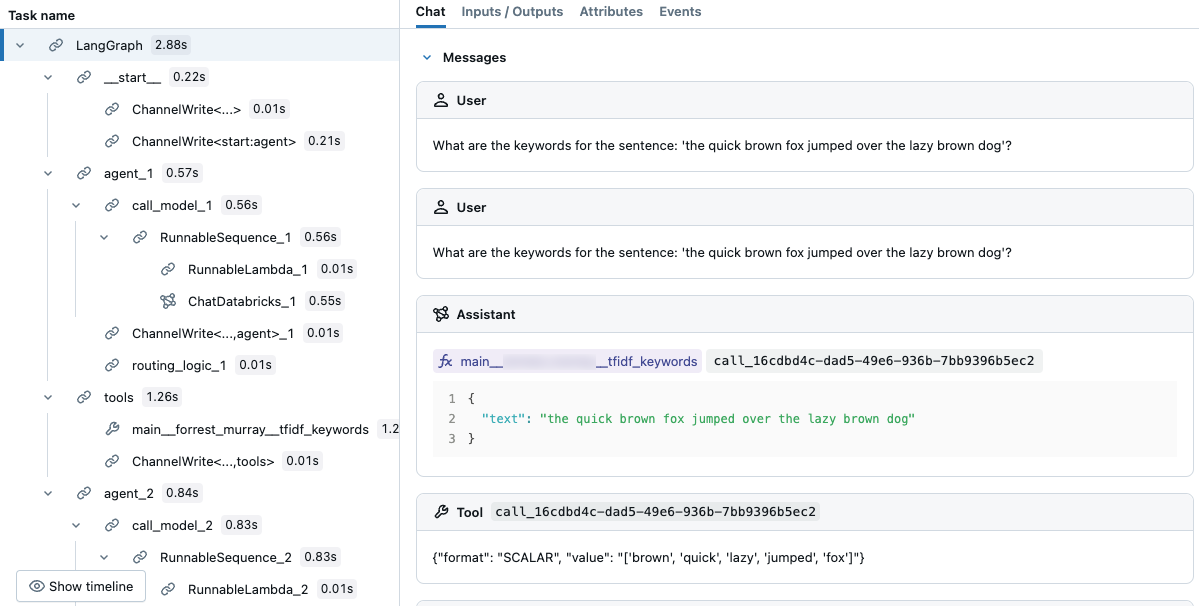
Debugowanie agentów przy użyciu śladów
Śledzenie MLflow to zaawansowane narzędzie do debugowania i obserwowania generatywnych aplikacji sztucznej inteligencji, w tym również agentów. Przechwytuje szczegółowe informacje o operacjach za pośrednictwem zakresów, które hermetyzują określone segmenty kodu i rejestrują dane wejściowe, wyjściowe i dane o chronometrażu.
W przypadku popularnych bibliotek, takich jak LangChain, włącz automatyczne śledzenie za pomocą mlflow.langchain.autolog(). Możesz również użyć mlflow.start_span(), aby dostosować ślad. Na przykład można dodać niestandardowe pola wartości danych lub etykiety w celu zapewnienia obserwowalności. Kod uruchamiany w kontekście tego zakresu jest skojarzony z zdefiniowanymi polami. W tym przykładzie TF-IDF działającym w pamięci, podaj nazwę i ustal typ zakresu.
Aby dowiedzieć się więcej na temat śledzenia, zobacz Śledzenie MLflow - obserwowalność GenAI.
Poniższy przykład tworzy narzędzie wyszukiwania przy użyciu prostego indeksu TF-IDF przechowywanego w pamięci. Demonstruje ona zarówno automatyczne rejestrowanie wykonywania narzędzi, jak i niestandardowe śledzenie rozpiętości dla zwiększenia obserwowalności.
from sklearn.feature_extraction.text import TfidfVectorizer
import mlflow
from langchain_core.tools import tool
documents = parsed_docs_df
doc_vectorizer = TfidfVectorizer(stop_words="english")
tfidf_matrix = doc_vectorizer.fit_transform(documents["content"])
@tool
def find_relevant_documents(query, top_n=5):
"""gets relevant documents for the query"""
with mlflow.start_span(name="LittleIndex", span_type="RETRIEVER") as retriever_span:
retriever_span.set_inputs({"query": query})
retriever_span.set_attributes({"top_n": top_n})
query_tfidf = doc_vectorizer.transform([query])
similarities = (tfidf_matrix @ query_tfidf.T).toarray().flatten()
ranked_docs = sorted(enumerate(similarities), key=lambda x: x[1], reverse=True)
result = []
for idx, score in ranked_docs[:top_n]:
row = documents.iloc[idx]
content = row["content"]
doc_entry = {
"page_content": content,
"metadata": {
"doc_uri": row["doc_uri"],
"score": score,
},
}
result.append(doc_entry)
retriever_span.set_outputs(result)
return result
Ten kod, używa specjalnego typu zakresu, RETRIEVER, który jest zarezerwowany dla narzędzi wyszukiwania. Inne funkcje agenta Mosaic AI (takie jak AI Playground, przegląd interfejsu użytkownika i ocena) używają typu zakresu RETRIEVER do wyświetlania wyników wyszukiwania.
Narzędzia pobierania wymagają określenia ich schematu w celu zapewnienia zgodności z funkcjami podrzędnych usługi Databricks. Aby uzyskać więcej informacji na temat mlflow.models.set_retriever_schema, zobacz Niestandardowe schematy modułu pobierania.
import mlflow
from mlflow.models import set_retriever_schema
uc_toolkit = UCFunctionToolkit(function_names=[f"{CATALOG}.{SCHEMA}.*"])
graph = create_tool_calling_agent(llm, tools=[*uc_toolkit.tools, find_relevant_documents])
mlflow.langchain.autolog()
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
graph.invoke(input = {"messages": [("user", "How do the docs say I use llm judges on databricks?")]})
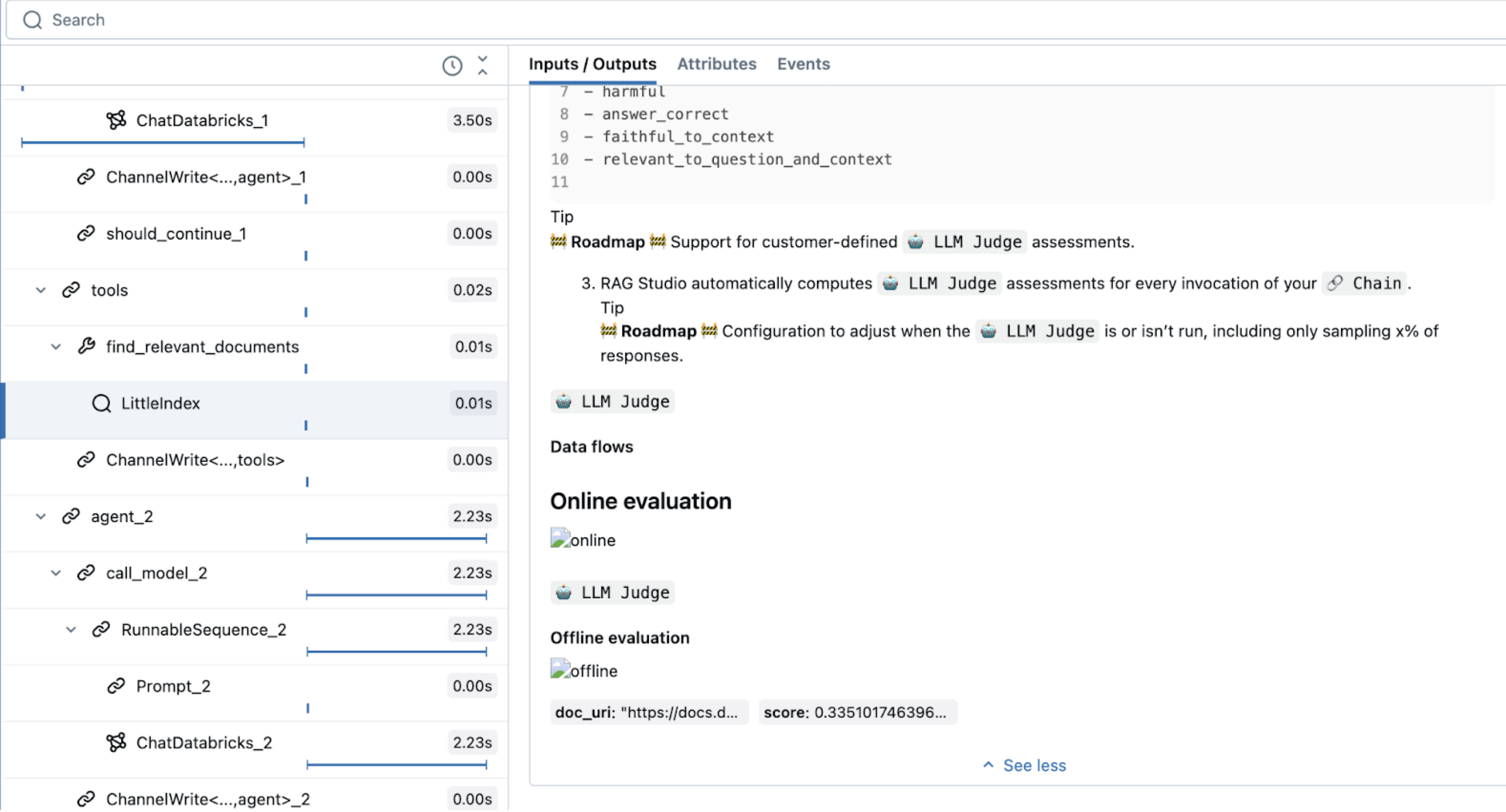
Definiowanie agenta
Następnym krokiem jest ocena agenta i przygotowanie go do wdrożenia. Na wysokim poziomie obejmuje to następujące kwestie:
- Zdefiniuj przewidywalny interfejs API dla agenta przy użyciu podpisu.
- Dodaj konfigurację modelu, co ułatwia konfigurowanie parametrów.
- Zarejestruj model z zależnościami, które zapewniają mu powtarzalne środowisko i umożliwia skonfigurowanie uwierzytelniania do innych usług.
Interfejs ChatAgent MLflow upraszcza definiowanie danych wejściowych i wyjściowych agenta. Aby go użyć, zdefiniuj agenta jako podklasę ChatAgent, implementując wnioskowanie bez przesyłania strumieniowego za pomocą funkcji predict i wnioskowanie w trybie przesyłania strumieniowego za pomocą funkcji predict_stream.
ChatAgent jest niezależny od wybranej struktury tworzenia agentów, co pozwala łatwo testować i używać różnych struktur i implementacji agentów — jedynym wymaganiem jest zaimplementowanie interfejsów predict i predict_stream.
Tworzenie agenta z użyciem ChatAgent zapewnia szereg korzyści, między innymi:
- obsługa strumieniowania danych wyjściowych
- Kompleksowa historia komunikatów wywołujących narzędzia: Zwracanie wielu wiadomości, w tym pośrednich komunikatów wywołujących narzędzia, dla lepszej jakości obsługi i zarządzania przebiegiem rozmów.
- obsługa systemu multi-agentowego
- integracja funkcji usługi Databricks: gotowa do użycia zgodność z AI Playground, ocena i monitorowanie agentów.
- Interfejsy tworzenia z typami: Pisz kod agenta przy użyciu typowanych klas języka Python, korzystając z automatycznego uzupełniania w IDE i notesie.
Aby uzyskać więcej informacji na temat tworzenia ChatAgent, zobacz Legacy schemat agenta wejściowego i wyjściowego (obsługa modelu).
from mlflow.pyfunc import ChatAgent
from mlflow.types.agent import (
ChatAgentChunk,
ChatAgentMessage,
ChatAgentResponse,
ChatContext,
)
from typing import Any, Optional
class DocsAgent(ChatAgent):
def __init__(self, agent):
self.agent = agent
set_retriever_schema(
primary_key="chunk_id",
text_column="chunk_text",
doc_uri="doc_uri",
other_columns=["title"],
)
def predict(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> ChatAgentResponse:
# ChatAgent has a built-in helper method to help convert framework-specific messages, like langchain BaseMessage to a python dictionary
request = {"messages": self._convert_messages_to_dict(messages)}
output = agent.invoke(request)
# Here 'output' is already a ChatAgentResponse, but to make the ChatAgent signature explicit for this demonstration, the code returns a new instance
return ChatAgentResponse(**output)
Poniższy kod pokazuje, jak używać ChatAgent.
AGENT = DocsAgent(agent=agent)
AGENT.predict(
{
"messages": [
{"role": "user", "content": "What are Pipelines in Databricks?"},
]
}
)
Konfigurowanie agentów przy użyciu parametrów
Struktura agentów umożliwia kontrolowanie wykonywania agenta za pomocą parametrów. Oznacza to, że można szybko przetestować różne konfiguracje agenta, takie jak przełączanie punktów końcowych LLM lub wypróbowanie różnych narzędzi bez zmiany kodu źródłowego.
Poniższy kod tworzy słownik konfiguracji, który ustawia parametry agenta podczas inicjowania modelu.
Aby uzyskać więcej informacji na temat parametryzacji agentów, zobacz Parametrize code for deployment across environments (Parametryzowanie kodu na potrzeby wdrażania w różnych środowiskach).
)
from mlflow.models import ModelConfig
baseline_config = {
"endpoint_name": "databricks-meta-llama-3-3-70b-instruct",
"temperature": 0.01,
"max_tokens": 1000,
"system_prompt": """You are a helpful assistant that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
You answer questions using a set of tools. If needed, you ask the user follow-up questions to clarify their request.
""",
"tool_list": ["catalog.schema.*"],
}
class DocsAgent(ChatAgent):
def __init__(self):
self.config = ModelConfig(development_config=baseline_config)
self.agent = self._build_agent_from_config()
def _build_agent_from_config(self):
temperature = config.get("temperature", 0.01)
max_tokens = config.get("max_tokens", 1000)
system_prompt = config.get("system_prompt", """You are a helpful assistant.
You answer questions using a set of tools. If needed you ask the user follow-up questions to clarify their request.""")
llm_endpoint_name = config.get("endpoint_name", "databricks-meta-llama-3-3-70b-instruct")
tool_list = config.get("tool_list", [])
llm = ChatDatabricks(endpoint=llm_endpoint_name, temperature=temperature, max_tokens=max_tokens)
toolkit = UCFunctionToolkit(function_names=tool_list)
agent = create_tool_calling_agent(llm, tools=[*toolkit.tools, find_relevant_documents], prompt=system_prompt)
return agent
Zaloguj agenta
Po zdefiniowaniu agenta jest on teraz gotowy do zarejestrowania. W rozwiązaniu MLflow rejestrowanie agenta oznacza zapisanie konfiguracji agenta (w tym zależności), aby można było go użyć do oceny i wdrożenia.
Uwaga
Podczas opracowywania agentów w notesie platforma MLflow wnioskuje zależności agenta ze środowiska notesu.
Aby zarejestrować agenta z notesu, możesz napisać cały kod definiujący model w jednej komórce, a następnie użyć polecenia magic %%writefile, aby zapisać definicję agenta w pliku:
%%writefile agent.py
...
<Code that defines the agent>
Jeśli agent wymaga dostępu do zasobów zewnętrznych, takich jak Unity Catalog w celu wykonania narzędzia wyodrębniania słów kluczowych, należy skonfigurować uwierzytelnianie agenta, aby mógł uzyskiwać dostęp do zasobów po ich wdrożeniu.
Aby uprościć uwierzytelnianie zasobów usługi Databricks, włącz przepustowość automatycznego uwierzytelniania:
from mlflow.models.resources import DatabricksFunction, DatabricksServingEndpoint
resources = [
DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME),
DatabricksFunction(function_name=tool.uc_function_name),
]
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
artifact_path="agent",
python_model="agent.py",
pip_requirements=[
"mlflow",
"langchain",
"langgraph",
"databricks-langchain",
"unitycatalog-langchain[databricks]",
"pydantic",
],
resources=resources,
)
Aby dowiedzieć się więcej na temat agentów rejestrowania, zobacz rejestrowanie bazujące na kodzie.
Oceń agenta
Następnym krokiem jest ocena agenta w celu sprawdzenia, jak działa. Ocena agenta jest trudna i wywołuje wiele pytań, takich jak:
- Jakie są właściwe metryki do oceny jakości? Jak ufać danych wyjściowych tych metryk?
- Muszę ocenić wiele pomysłów - jak mogę...
- Czy mogę szybko uruchomić ocenę, aby większość mojego czasu nie była poświęcana na czekanie?
- Czy mogę szybko porównać te różne wersje mojego agenta pod względem jakości, kosztów i opóźnień?
- Jak szybko zidentyfikować główną przyczynę problemów z jakością?
Jako analityk danych lub programista możesz nie być rzeczywistym ekspertem w tej dziedzinie. Pozostała część tej sekcji opisuje narzędzia oceny działania agenta, które mogą pomóc w uzyskaniu dobrych wyników.
Tworzenie zestawu oceny
Aby zdefiniować, co znaczy jakość dla agenta, należy użyć metryk do mierzenia wydajności agenta w zestawie ewaluacyjnym. Zobacz Definiowanie "jakości": zestawy ewaluacyjne.
Przy użyciu ewaluacji agenta można tworzyć syntetyczne zestawy oceniające i mierzyć jakość, przeprowadzając oceny. Chodzi o to, aby zacząć od faktów, takich jak zestaw dokumentów, i "pracować wstecz", używając tych faktów do generowania zestawu pytań. Pytania, które są generowane, można określić, podając pewne wskazówki:
from databricks.agents.evals import generate_evals_df
import pandas as pd
databricks_docs_url = "https://raw.githubusercontent.com/databricks/genai-cookbook/refs/heads/main/quick_start_demo/chunked_databricks_docs_filtered.jsonl"
parsed_docs_df = pd.read_json(databricks_docs_url, lines=True)
agent_description = f"""
The agent is a RAG chatbot that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
"""
question_guidelines = f"""
# User personas
- A developer who is new to the Databricks platform
- An experienced, highly technical Data Scientist or Data Engineer
# Example questions
- what API lets me parallelize operations over rows of a delta table?
- Which cluster settings will give me the best performance when using Spark?
# Additional Guidelines
- Questions should be succinct, and human-like
"""
num_evals = 25
evals = generate_evals_df(
docs=parsed_docs_df[
:500
], # Pass your docs. They should be in a Pandas or Spark DataFrame with columns `content STRING` and `doc_uri STRING`.
num_evals=num_evals, # How many synthetic evaluations to generate
agent_description=agent_description,
question_guidelines=question_guidelines,
)
Wygenerowane oceny obejmują następujące elementy:
Pole żądania, które wygląda podobnie do wymienionego wcześniej
ChatAgentRequest:{"messages":[{"content":"What command must be run at the start of your workload to explicitly target the Workspace Model Registry if your workspace default catalog is in Unity Catalog and you use Databricks Runtime 13.3 LTS or above?","role":"user"}]}Lista "oczekiwana zawartość do pobrania". Schemat pobierania został zdefiniowany z polami
contentidoc_uri.[{"content":"If your workspace's [default catalog](https://docs.databricks.com/data-governance/unity-catalog/create-catalogs.html#view-the-current-default-catalog) is in Unity Catalog (rather than `hive_metastore`) and you are running a cluster using Databricks Runtime 13.3 LTS or above, models are automatically created in and loaded from the workspace default catalog, with no configuration required. To use the Workspace Model Registry in this case, you must explicitly target it by running `import mlflow; mlflow.set_registry_uri(\"databricks\")` at the start of your workload.","doc_uri":"https://docs.databricks.com/machine-learning/manage-model-lifecycle/workspace-model-registry.html"}]Lista oczekiwanych faktów. Podczas porównywania dwóch odpowiedzi trudno jest znaleźć małe różnice między nimi. Oczekiwane fakty wyjaśniają, co odróżnia prawidłową odpowiedź od odpowiedzi częściowo poprawnej i od niepoprawnej, i poprawiają jakość sędziów sztucznej inteligencji oraz doświadczenie osób pracujących nad agentem.
["The command must import the MLflow module.","The command must set the registry URI to \"databricks\"."]Pole source_id, tutaj oznaczone jako
SYNTHETIC_FROM_DOC. Podczas tworzenia bardziej kompletnych zestawów oceny próbki będą pochodzić z różnych źródeł, więc to pole je rozróżnia.
Aby dowiedzieć się więcej na temat tworzenia zestawów oceny, zobacz Syntetyzowanie zestawów oceny.
Ocena agenta przy użyciu sędziów LLM
Ręczne ocenianie wydajności agenta na tak wielu wygenerowanych przykładach nie jest dobrze skalowalne. Na dużej skali użycie LLM-ów jako sędziów jest o wiele bardziej rozsądnym rozwiązaniem. Aby użyć wbudowanych sędziów dostępnych podczas korzystania z funkcji Ocena Agenta, użyj następującego kodu:
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation
)
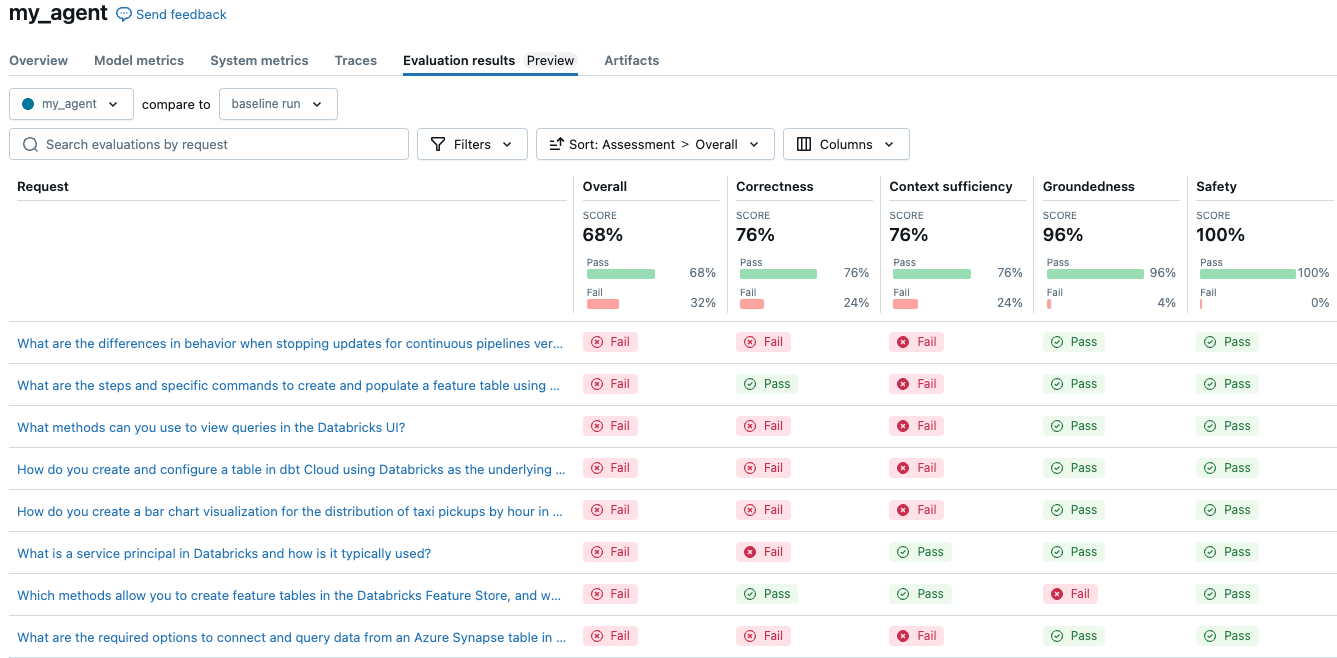
Prosty agent zdobył ogólny wynik 68%. Wyniki mogą się różnić w zależności od używanej konfiguracji. Uruchomienie eksperymentu w celu porównania trzech różnych maszyn LLM pod kątem kosztów i jakości jest tak proste, jak zmiana konfiguracji i ponownej oceny.
Rozważ zmianę konfiguracji modelu tak, aby korzystała z innego ustawienia LLM, monitu systemowego lub temperatury.
Tych sędziów można dostosować, aby postępować zgodnie z tymi samymi wytycznymi, których używają ludzie, aby ocenić odpowiedź. Aby uzyskać więcej informacji na temat sędziów LLM, zobacz Wbudowani sędziowie AI (MLflow 2).
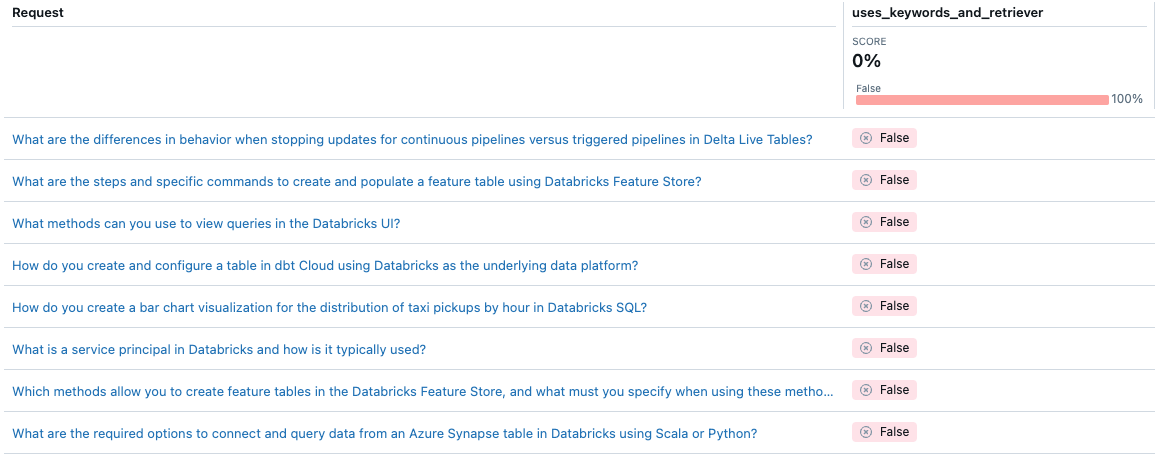
Przy użyciu oceny agenta można dostosować sposób mierzenia jakości określonego agenta przy użyciu metryk niestandardowych. Ocenę można traktować jak test integracji i poszczególne metryki jako testy jednostkowe. W poniższym przykładzie użyto metryki logicznej (Boolowskiej), aby sprawdzić, czy agent użył zarówno wyodrębniania słów kluczowych, jak i mechanizmu retriever dla danego żądania.
from databricks.agents.evals import metric
@metric
def uses_keywords_and_retriever(request, trace):
retriever_spans = trace.search_spans(span_type="RETRIEVER")
keyword_tool_spans = trace.search_spans(name=f"{CATALOG}__{SCHEMA}__tfidf_keywords")
return len(keyword_tool_spans) > 0 and len(retriever_spans) > 0
# same evaluate as above, with the addition of 'extra_metrics'
with mlflow.start_run(run_name="my_agent"):
eval_results = mlflow.evaluate(
data=evals, # Your evaluation set
model=model_info.model_uri, # Logged agent from above
model_type="databricks-agent", # activate Mosaic AI Agent Evaluation,
extra_metrics=[uses_keywords_and_retriever],
)
Należy pamiętać, że agent nigdy nie używa wyodrębniania słów kluczowych. Jak można rozwiązać ten problem?
Wdrażanie i monitorowanie agenta
Gdy wszystko będzie gotowe do rozpoczęcia testowania agenta z rzeczywistymi użytkownikami, platforma Agent Framework oferuje rozwiązanie gotowe do użycia w środowisku produkcyjnym do obsługi agenta w Mosaic AI Model Serving.
Wdrażanie agentów w usłudze modelowej zapewnia następujące korzyści:
- Obsługa modelu zarządza skalowaniem automatycznym, rejestrowaniem, kontrolą wersji i kontrolą dostępu, co pozwala skupić się na tworzeniu agentów jakości.
- Eksperci z danej dziedziny mogą korzystać z aplikacji Przegląd, aby korzystać z agenta i przekazywać opinie, które można włączyć do monitorowania i ocen.
- Można monitorować agenta, uruchamiając oceny ruchu na żywo. Mimo że ruch użytkowników nie zawiera podstawowej prawdy, sędziowie LLM (i utworzona metryka niestandardowa) wykonują ocenę nienadzorowaną.
Poniższy kod wdraża agentów w serwerowym punkcie końcowym. Aby uzyskać więcej informacji, zobacz Deploy an agent for generative AI applications (Model Serving) (Wdrażanie agenta na potrzeby generowania aplikacji sztucznej inteligencji (obsługa modelu).
from databricks import agents
import mlflow
# Connect to the Unity Catalog model registry
mlflow.set_registry_uri("databricks-uc")
# Configure UC model location
UC_MODEL_NAME = f"{CATALOG}.{SCHEMA}.getting_started_agent"
# REPLACE WITH UC CATALOG/SCHEMA THAT YOU HAVE `CREATE MODEL` permissions in
# Register to Unity Catalog
uc_registered_model_info = mlflow.register_model(
model_uri=model_info.model_uri, name=UC_MODEL_NAME
)
# Deploy to enable the review app and create an API endpoint
deployment_info = agents.deploy(
model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version
)