Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dowiedz się, jak utworzyć nowy potok przy użyciu Deklaratywnych Potoków Spark Lakeflow (SDP) do orkiestracji danych i Automatycznego Ładowacza. Ten samouczek rozszerza przykładowy potok danych poprzez oczyszczanie danych i tworzenie zapytania w celu znalezienia 100 najlepszych użytkowników.
Z tego samouczka dowiesz się, jak używać edytora Lakeflow Pipelines do:
- Utwórz nowy potok z domyślną strukturą folderów i zacznij od zestawu przykładowych plików.
- Definiowanie ograniczeń dotyczących jakości danych przy użyciu oczekiwań.
- Użyj funkcji edytora, aby rozszerzyć potok przy użyciu nowej transformacji w celu przeprowadzenia analizy danych.
Requirements
Przed rozpoczęciem tego samouczka należy wykonać następujące czynności:
- Zaloguj się do obszaru roboczego Azure Databricks.
- Upewnij się, że Katalog Unity jest włączony dla Twojego obszaru roboczego.
- Mieć uprawnienia do tworzenia zasobu obliczeniowego lub dostępu do zasobu obliczeniowego.
- Musisz mieć uprawnienia do tworzenia nowego schematu w katalogu. Wymagane uprawnienia to
ALL PRIVILEGESlubUSE CATALOGiCREATE SCHEMA.
Krok 1: Utwórz potok
W tym kroku utworzysz pipeline przy użyciu domyślnej struktury folderów i przykładowego kodu. Przykłady kodu odwołują się do users tabeli w przykładowym wanderbricks źródle danych.
W obszarze roboczym Azure Databricks kliknij
 Nowy, następnie
Nowy, następnie  ETL pipeline. Spowoduje to otwarcie edytora potoku z domyślną nazwą potoku, taką jak
ETL pipeline. Spowoduje to otwarcie edytora potoku z domyślną nazwą potoku, taką jak New Pipeline <date> <time>.(Opcjonalnie) Wybierz nazwę i wprowadź opisową nazwę potoku.
(Opcjonalnie) Po prawej stronie nazwy kliknij katalog i schemat, aby ustawić różne wartości domyślne.
(Opcjonalnie) W utworzonym pliku źródłowym
my_transformationwybierz Python lub SQL z listy rozwijanej języka, aby ustawić język pliku.Kliknij
 Użyj przykładowego kodu.
Użyj przykładowego kodu.Przykładowy kod w wybranym języku jest wyświetlany w pliku źródłowym
my_transformationw folderzetransformations. Wyjściowe zestawy danych nie zostały jeszcze utworzone, a wykres potoku po prawej stronie ekranu jest pusty.Aby uruchomić kod potoku (kod w folderze
transformations), kliknij Uruchom potok w prawym górnym rogu ekranu.Po zakończeniu uruchomienia w dolnej części obszaru roboczego są wyświetlane dwie nowo utworzone tabele:
sample_users_<date_time>isample_aggregation_<date_time>. Wykres potoku po prawej stronie obszaru roboczego pokazuje teraz dwie tabele, w tym to, żesample_usersjest źródłem dlasample_aggregation. Zanotuj pełnąsample_users_<date_time>nazwę tabeli — odwołujesz się do niej w następnym kroku.
Krok 2. Stosowanie kontroli jakości danych
W tym kroku dodajesz kontrolę jakości danych do tabeli sample_users. Aby ograniczyć dane, należy użyć oczekiwań dla potoku. W takim przypadku usuniesz wszystkie rekordy użytkownika, które nie mają prawidłowego adresu e-mail, i wyświetlisz wyczyszczonej tabeli jako users_cleaned.
W przeglądarce zasobów potoku po lewej stronie kliknij
i wybierz pozycję Przekształcenie.W oknie dialogowym Tworzenie nowego pliku transformacji wybierz następujące opcje:
- Wybierz Python lub SQL dla Language. To nie musi być zgodne z poprzednim wyborem.
- Nadaj plikowi nazwę. W tym przypadku wybierz pozycję
users_cleaned. - W polu Ścieżka docelowa pozostaw wartość domyślną.
- W polu Typ zestawu danych pozostaw wartość Brak wybranego lub wybierz pozycję Zmaterializowany widok. W przypadku wybrania widoku zmaterializowanego zostanie wygenerowany przykładowy kod.
Kliknij przycisk Utwórz , aby utworzyć plik kodu przekształcenia.
W nowym pliku kodu zmodyfikuj kod, aby był zgodny z poniższym kodem (użyj języka SQL lub Python na podstawie wybranego na poprzednim ekranie). Zastąp
sample_users_<date_time>pełną nazwą tabelisample_usersz poprzedniej sekcji.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )Kliknij Uruchom potok, aby zaktualizować potok. Powinna ona teraz zawierać trzy tabele.
Krok 3. Analizowanie najważniejszych użytkowników
Następnie uzyskaj 100 pierwszych użytkowników według liczby utworzonych rezerwacji. Dołącz tabelę wanderbricks.bookings do zmaterializowanego users_cleaned widoku.
W przeglądarce zasobów potoku danych po lewej stronie kliknij
, a następnie wybierz Przekształcenie.W oknie dialogowym Tworzenie nowego pliku transformacji wybierz następujące opcje:
- Wybierz Python lub SQL dla Language. To nie musi być zgodne z poprzednim wyborem.
- Nadaj plikowi nazwę. W tym przypadku wybierz pozycję
users_and_bookings. - W polu Ścieżka docelowa pozostaw wartość domyślną.
- Dla Typ zestawu danych pozostaw to jako Nie wybrano.
Kliknij przycisk Utwórz , aby utworzyć plik kodu przekształcenia.
W nowym pliku kodu zmodyfikuj kod, aby był zgodny z poniższym kodem (użyj języka SQL lub Python na podstawie wybranego na poprzednim ekranie).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Kliknij pozycję Uruchom potok , aby zaktualizować zestawy danych. Po zakończeniu przebiegu można zobaczyć w grafie przepływu, że istnieją cztery tabele, w tym nowa tabela
users_and_bookings.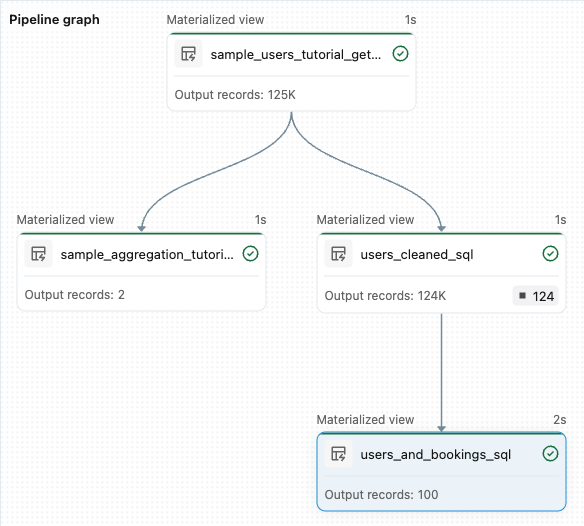
Dalsze kroki
Teraz, gdy wiesz już, jak używać niektórych funkcji edytora potoków Lakeflow i utworzyłeś potok, oto kilka innych funkcji, które warto poznać:
Narzędzia do pracy z przekształceniami i debugowania podczas tworzenia potoków:
- Selektywne wykonywanie
- Podglądy danych
- Interaktywny graf potoku (graf zbiorów danych w Twoim potoku)
Wbudowana integracja Deklaratywnych Pakietów Automatyzacji w celu wydajnej współpracy, kontroli wersji i integracji CI/CD bezpośrednio w edytorze: