Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Autoskalowanie bazy danych Lakebase to najnowsza wersja bazy danych Lakebase, która umożliwia skalowanie automatyczne, skalowanie do zera, rozgałęzianie i natychmiastowe przywracanie. Aby uzyskać informacje o obsługiwanych regionach, zobacz Dostępność regionów. Jeśli jesteś użytkownikiem usługi Lakebase Provisioned, zobacz Lakebase Provisioned.
Autoskalowanie Postgres w usłudze Lakebase to w pełni zarządzana baza danych Postgres zaprojektowana dla każdej aplikacji, która wymaga przetwarzania transakcji online (OLTP) i dostarczania danych z niskim opóźnieniem. Jest zintegrowana z platformą Databricks, umożliwiając tworzenie aplikacji transakcyjnych w czasie rzeczywistym wraz z obciążeniami analitycznymi.
Skalowanie automatyczne bazy danych Lakebase Postgres łączy niezawodność i znajomość bazy danych Postgres z nowoczesnymi funkcjami bazy danych, takimi jak skalowanie automatyczne, skalowanie do zera, rozgałęzianie i natychmiastowe przywracanie. Te funkcje umożliwiają elastyczne przepływy pracy programowania, ekonomiczne operacje i szybką iterację.
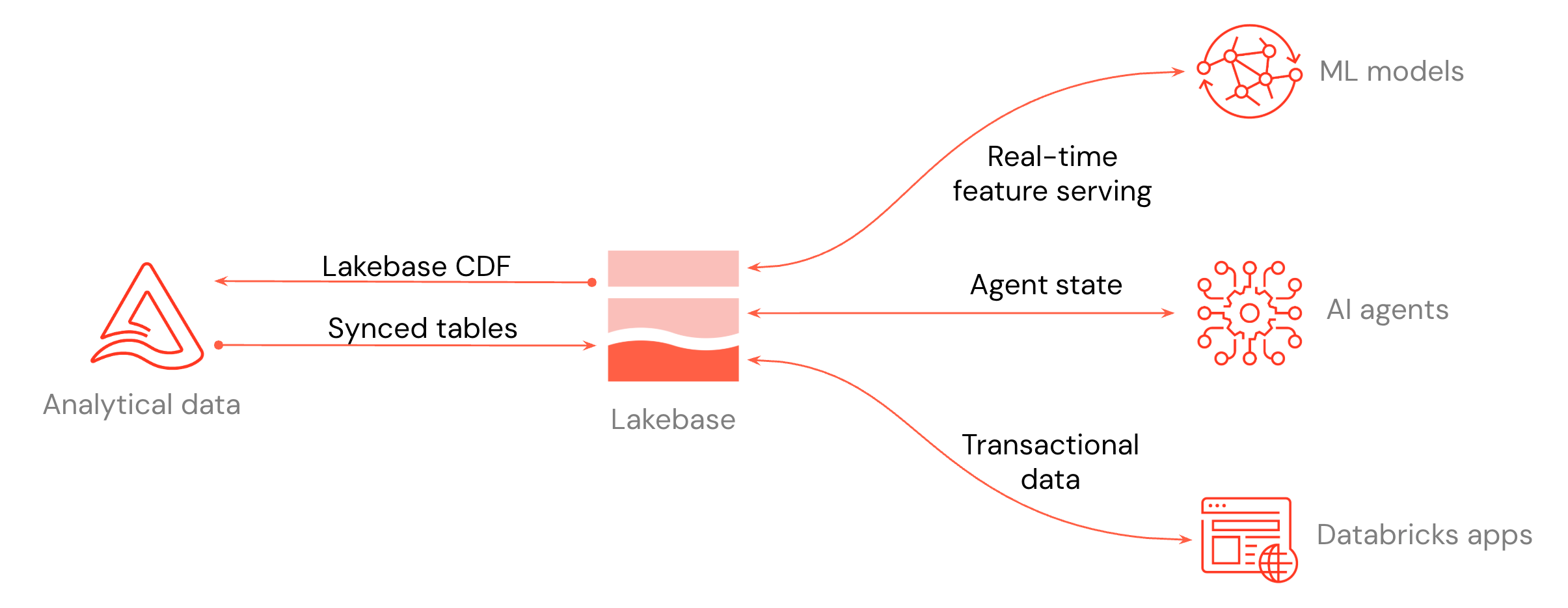
Na diagramie pokazano, jak usługa Lakebase integruje się z resztą platformy: funkcja w czasie rzeczywistym obsługująca modele uczenia maszynowego i magazyn funkcji, stan agenta dla agentów sztucznej inteligencji i dane transakcyjne dla usługi Databricks Apps lub dowolnej aplikacji, z którą się łączysz.
Dane można przesuwać w obu kierunkach między Lakehouse a Lakebase. Zsynchronizowane tabele przenoszą dane z usługi Lakehouse do usługi Lakebase, dzięki czemu aplikacje mogą je zapytania z niskim opóźnieniem.
Przykładowe przypadki użycia i typy obciążeń
Poniżej przedstawiono kilka przykładów wielu sposobów korzystania z bazy danych OLTP Postgres, takiej jak Lakebase w różnych branżach: spersonalizowane rekomendacje i oferty przeznaczone dla handlu elektronicznego i handlu detalicznego, dane badań klinicznych i systemy rekomendacji w opiece zdrowotnej, zautomatyzowane analizy handlu i przesyłania strumieniowego w usługach finansowych oraz przepływy pracy telemetrii i konserwacji maszyn w produkcji.
Typowe typy obciążeń dla baz danych OLTP mogą obejmować następujące elementy:
- Serwowanie danych: Serwowanie wniosków ze złotych tabel do aplikacji z małym opóźnieniem i wysokim wskaźnikiem QPS.
- Przechowaj stan aplikacji: Zarządzaj przepływem pracy i stanem agenta w transakcyjnym repozytorium danych.
- Serwowanie cech: Serwowanie danych cechowanych z niskim opóźnieniem dla modeli uczenia maszynowego.
Integracja z usługą Databricks
Na powyższym diagramie przedstawiono trzy kluczowe przypadki użycia integracji:
- Obsługa funkcji w czasie rzeczywistym: Używaj projektów Lakebase jako sklepu online dla modeli uczenia maszynowego i magazynu funkcji, dzięki czemu można udostępniać dane cechowane przy małych opóźnieniach. Zobacz Sklep Funkcji Online (Lakebase) i Serwowanie Funkcji.
- Stan agenta dla agentów sztucznej inteligencji: Przechowywanie stanu agentów sztucznej inteligencji i zarządzanie nim w transakcyjnej bazie danych, dzięki czemu konwersacje i kontekst przepływu pracy są utrwalane między żądaniami.
- Dane transakcyjne dla aplikacji: Zachowaj dane dla aplikacji Databricks Apps lub dowolnej aplikacji połączonej z Lakebase. W przypadku usługi Databricks Apps dodaj projekt Lakebase jako zasób aplikacji. Zobacz Dodaj zasób Lakebase do aplikacji Databricks.
Aprowizowana usługa Lakebase
Usługa Lakebase Provisioned to oryginalna oferta usługi Lakebase, która korzysta z aprowizowanych zasobów obliczeniowych, które skalujesz ręcznie. Istniejące wystąpienia aprowizowania nadal są obsługiwane. Opracowywanie aplikacji New Lakebase koncentruje się na skalowaniu automatycznym. Jeśli masz aprovisionowane instancje lub oceniasz obie opcje, zobacz Co to jest Lakebase Provisioned? i domyślnie automatyczne skalowanie.
Co to jest projekt?
Zasoby skalowania automatycznego w usłudze Lakebase są zorganizowane w strukturę projektu . Projekt jest kontenerem najwyższego poziomu dla zasobów bazy danych. Podczas tworzenia bazy danych autoskalowania usługi Lakebase tworzysz projekt. Projekt obejmuje wasze gałęzie (środowiska baz danych), zasoby obliczeniowe, role oraz bazy danych. Projekt można traktować jako jednostkę organizacji dla jednej aplikacji lub obciążenia. Możesz mieć wiele projektów w obszarze roboczym, z których każda ma własne gałęzie i dane.
Sposób organizowania projektów
Zrozumienie hierarchii obiektów w projekcie ułatwia organizowanie zasobów i zarządzanie nimi:
Databricks Workspace
└── Project(s)
└── Branch(es)
├── Compute (primary R/W)
├── Read replica(s) (optional)
├── Role(s)
└── Database(s)
└── Schema(s)
Każdy poziom w hierarchii służy do określonego celu:
| Object | Description |
|---|---|
| Project | Kontener najwyższego poziomu dla zasobów bazy danych. Projekt zawiera gałęzie, bazy danych, role i zasoby obliczeniowe. Zobacz Zarządzanie projektami. |
| Gałąź | Izolowane środowisko bazy danych, które dzieli pamięć masową z nadrzędną gałęzią. Każdy projekt może zawierać wiele gałęzi. Zobacz Zarządzanie gałęziami. |
| Środowisko obliczeniowe | Serwer Postgres, który obsługuje gałąź. Każda gałąź ma własne obliczenia, które zapewniają moc obliczeniową i pamięć na potrzeby operacji bazy danych. Zobacz Zarządzanie obliczeniami. |
| Baza danych | Standardowa baza danych Postgres w instancji. Każda gałąź może zawierać wiele baz danych z własnymi tabelami, schematami i danymi. Zobacz Zarządzanie bazami danych. |
Informacje o gałęziach
Jedną z najbardziej zaawansowanych funkcji bazy danych Lakebase Postgres jest rozgałęzianie. Podobnie jak gałęzie usługi Git dla kodu, gałęzie umożliwiają tworzenie izolowanych środowisk baz danych na potrzeby programowania i testowania — bez wpływu na środowisko produkcyjne.
Dlaczego ma to znaczenie: Tradycyjne przepływy pracy bazy danych wymagają oddzielnych serwerów deweloperskich i przejściowych, ręcznych odświeżeń danych i starannej koordynacji. Za pomocą gałęzi można wykonywać następujące czynności:
- Natychmiastowe tworzenie środowiska projektowego z danymi produkcyjnymi
- Bezpieczne testowanie zmian schematu przed ich zastosowaniem do środowiska produkcyjnego
- Odzyskiwanie po błędach przez tworzenie gałęzi z dowolnego punktu w czasie
- Płacisz tylko za zmienione dane, a nie pełne zduplikowane bazy danych
| Temat | Description |
|---|---|
| Oddziały | Dowiedz się, jak gałęzie działają, typowe przepływy pracy i najlepsze rozwiązania dla zespołu. |
| Zarządzanie oddziałami | Tworzenie, resetowanie i usuwanie gałęzi na potrzeby programowania i testowania. |
| Chronione gałęzie | Chroń gałęzie produkcyjne przed przypadkowymi zmianami i usunięciami. |
Podstawowe pojęcia
Usługa Lakebase opiera się na kilku kluczowych innowacjach, które odróżniają ją od tradycyjnych systemów baz danych:
- Oddzielone zasoby obliczeniowe i magazyn: Skalowanie zasobów obliczeniowych niezależnie od magazynu w celu zwiększenia wydajności i elastyczności.
- Skalowanie automatyczne: Obliczenia są automatycznie dostosowywane na podstawie zapotrzebowania na obciążenie, z obsługą skalowania do zera w okresach bezczynności.
- Magazyn kopii na zapis: Umożliwia natychmiastowe rozgałęzianie, w którym płacisz tylko za zmiany danych, a nie pełne duplikaty.
- Natychmiastowe operacje punktowe w czasie: Tworzenie gałęzi lub przywracanie do dowolnego momentu w skonfigurowanym oknie przywracania (2–30 dni)
Te koncepcje współpracują ze sobą, aby umożliwić elastyczne procesy rozwoju, oszczędne operacje i szybkie odzyskiwanie po błędach.
Aby uzyskać szczegółowe wyjaśnienie poszczególnych podstawowych pojęć, zobacz Podstawowe pojęcia.