Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Interfejs API danych usługi Lakebase to interfejs RESTful zgodny z standardem POSTGREST, który umożliwia bezpośrednią interakcję z bazą danych Postgres w usłudze Lakebase przy użyciu standardowych metod HTTP. Oferuje punkty końcowe interfejsu API pochodzące ze schematu bazy danych, co umożliwia bezpieczne operacje CRUD (tworzenie, odczyt, aktualizacja i usuwanie) na danych bez konieczności tworzenia niestandardowego zaplecza backend.
Przegląd
API danych automatycznie generuje punkty końcowe RESTful bazując na schemacie bazy danych. Każda tabela w bazie danych staje się dostępna za pośrednictwem żądań HTTP, umożliwiając:
- Wykonywanie zapytań dotyczących danych przy użyciu żądań HTTP GET z elastycznym filtrowaniem, sortowaniem i stronicowaniem
- Wstawianie rekordów przy użyciu żądań HTTP POST
- Aktualizowanie rekordów przy użyciu żądań HTTP PATCH lub PUT
- Usuwanie rekordów przy użyciu żądań HTTP DELETE
- Wykonywanie funkcji jako wywołań RPC przy użyciu żądań HTTP POST
Takie podejście eliminuje konieczność pisania i obsługi niestandardowego kodu interfejsu API, co pozwala skupić się na logice aplikacji i schemacie bazy danych.
Zgodność postgREST
Interfejs API danych usługi Lakebase jest zgodny ze specyfikacją PostgREST . Masz następujące możliwości:
- Korzystanie z istniejących bibliotek klienckich i narzędzi PostgREST
- Postępuj zgodnie z konwencjami PostgREST dotyczącymi filtrowania, porządkowania i stronicowania
- Dostosuj dokumentację i przykłady ze społeczności PostgREST
Uwaga / Notatka
Interfejs API danych usługi Lakebase jest implementacją Azure Databricks zaprojektowaną tak, aby był zgodny ze specyfikacją PostgREST. Ponieważ interfejs API danych jest niezależną implementacją, niektóre funkcje PostgREST, które nie mają zastosowania do środowiska Lakebase, nie są uwzględniane. Aby uzyskać szczegółowe informacje na temat zgodności funkcji, zobacz Dokumentacja zgodności funkcji.
Aby uzyskać szczegółowe informacje na temat funkcji interfejsu API, parametrów zapytań i możliwości, zobacz dokumentację interfejsu API PostgREST.
Przypadki użycia
Interfejs API danych usługi Lakebase jest idealny do następujących celów:
- Aplikacje internetowe: twórz frontony, które bezpośrednio wchodzą w interakcję z bazą danych za pośrednictwem żądań HTTP
- Mikrousługi: tworzenie uproszczonych usług, które uzyskują dostęp do zasobów bazy danych za pośrednictwem interfejsów API REST
- Architektury bezserwerowe: integracja z funkcjami bezserwerowymi i platformami przetwarzania brzegowego
- Aplikacje mobilne: udostępnianie aplikacji mobilnych z bezpośrednim dostępem do bazy danych za pośrednictwem interfejsu RESTful
- Integracje innych firm: bezpieczne odczytywanie i zapisywanie danych w systemach zewnętrznych
Konfigurowanie interfejsu API danych
Ta sekcja przeprowadzi Cię przez proces konfigurowania interfejsu API danych od tworzenia wymaganych ról do tworzenia pierwszego żądania interfejsu API.
Warunki wstępne
Interfejs API danych wymaga projektu bazy danych Lakebase Postgres Autoscaling. Jeśli go nie masz, zobacz Wprowadzenie do projektów baz danych.
Wskazówka
Jeśli potrzebujesz przykładowych tabel do testowania interfejsu API danych, utwórz je przed włączeniem interfejsu API danych. Zobacz Przykładowy schemat , aby uzyskać kompletny przykładowy schemat.
Włącz interfejs API danych
Interfejs API danych umożliwia dostęp do bazy danych za pośrednictwem pojedynczej roli Postgres o nazwie authenticator, która wymaga jedynie uprawnienia do logowania. Po włączeniu interfejsu API danych za pośrednictwem aplikacji Lakebase ta rola i niezbędna infrastruktura są tworzone automatycznie.
Aby włączyć interfejs API danych:
- Przejdź do strony API Danych w projekcie.
- Kliknij Włącz interfejs API danych.
Spowoduje to automatyczne wykonanie wszystkich kroków konfiguracji, w tym utworzenie authenticator roli, skonfigurowanie pgrst schematu i ujawnienie public schematu za pośrednictwem interfejsu API.
Uwaga / Notatka
Jeśli musisz udostępnić dodatkowe schematy (poza public), możesz zmodyfikować udostępnione schematy w ustawieniach zaawansowanego interfejsu API danych.
Po włączeniu interfejsu API danych
Po włączeniu interfejsu API danych aplikacja Lakebase wyświetli stronę interfejsu API danych z dwiema kartami: INTERFEJS API i Ustawienia.
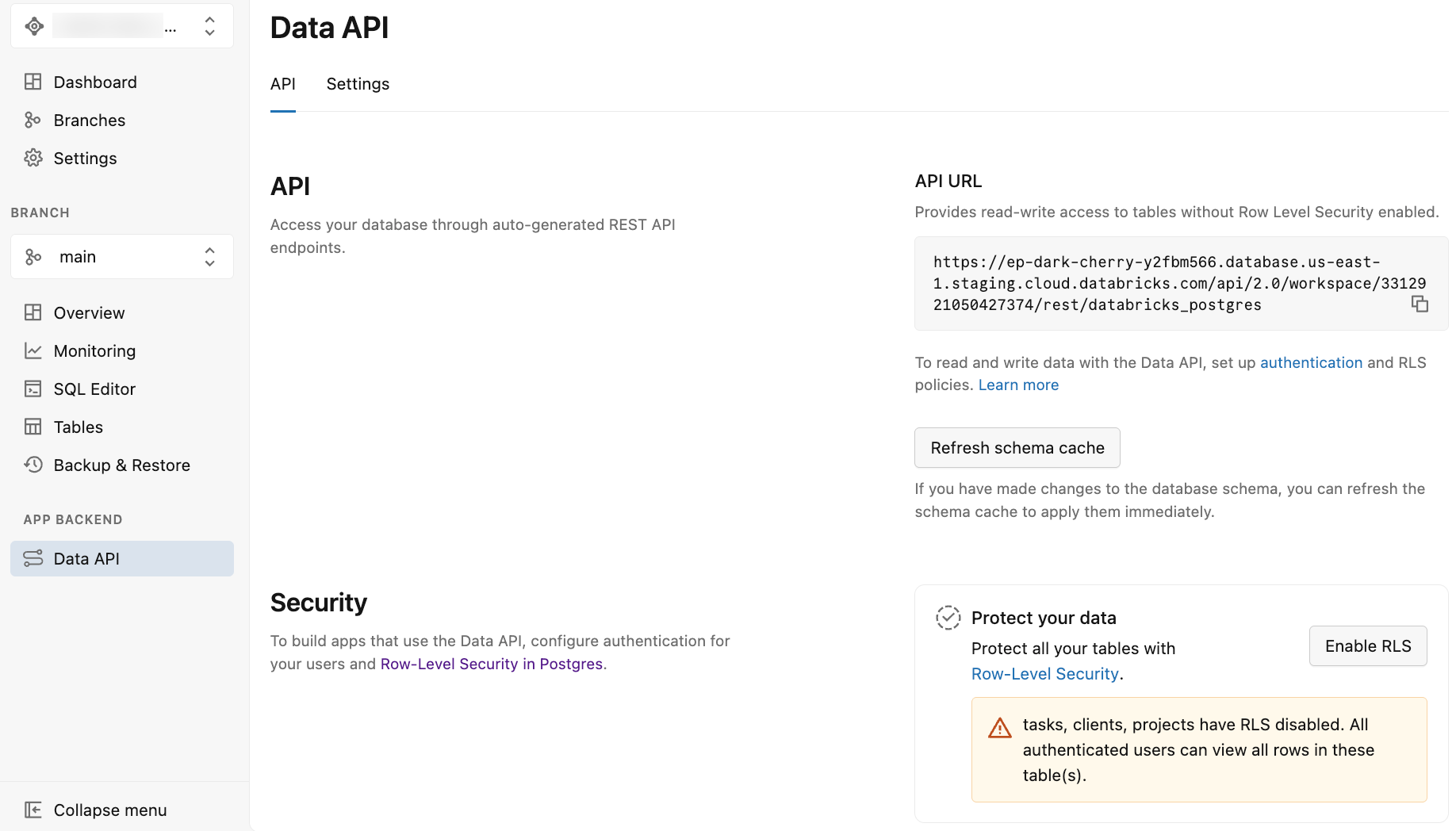
Zakładka API zapewnia:
-
Adres URL interfejsu API: adres URL punktu końcowego REST do użycia w kodzie aplikacji i żądaniach interfejsu API. Wyświetlany adres URL nie zawiera schematu, dlatego podczas tworzenia żądań interfejsu API należy dołączyć nazwę schematu (na przykład
/public) do adresu URL. - Odśwież pamięć podręczną schematu: przycisk umożliwiający odświeżenie pamięci podręcznej schematu interfejsu API po wprowadzeniu zmian w schemacie bazy danych. Zobacz także Odświeżanie pamięci podręcznej schematu.
- Ochrona danych: opcje umożliwiające włączenie zabezpieczeń na poziomie wiersza (RLS) bazy danych Postgres dla tabel. Zobacz Włączanie zabezpieczeń na poziomie wiersza.
Karta Ustawienia zawiera opcje konfigurowania zachowania interfejsu API, takie jak uwidocznione schematy, maksymalne wiersze, ustawienia mechanizmu CORS i inne. Zobacz Zaawansowane ustawienia interfejsu API danych.
Przykładowy schemat (opcjonalnie)
Przykłady w tej dokumentacji korzystają z następującego schematu. Możesz utworzyć własne tabele lub użyć tego przykładowego schematu do testowania. Uruchom następujące instrukcje SQL przy użyciu edytora SQL Lakebase lub dowolnego klienta SQL:
-- Create clients table
CREATE TABLE clients (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL,
company TEXT,
phone TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Create projects table with foreign key to clients
CREATE TABLE projects (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
description TEXT,
client_id INTEGER NOT NULL REFERENCES clients(id) ON DELETE CASCADE,
status TEXT DEFAULT 'active',
start_date DATE,
end_date DATE,
budget DECIMAL(10,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Create tasks table with foreign key to projects
CREATE TABLE tasks (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
description TEXT,
project_id INTEGER NOT NULL REFERENCES projects(id) ON DELETE CASCADE,
status TEXT DEFAULT 'pending',
priority TEXT DEFAULT 'medium',
assigned_to TEXT,
due_date DATE,
estimated_hours DECIMAL(5,2),
actual_hours DECIMAL(5,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Insert sample data
INSERT INTO clients (name, email, company, phone) VALUES
('Acme Corp', 'contact@acme.com', 'Acme Corporation', '+1-555-0101'),
('TechStart Inc', 'hello@techstart.com', 'TechStart Inc', '+1-555-0102'),
('Global Solutions', 'info@globalsolutions.com', 'Global Solutions Ltd', '+1-555-0103');
INSERT INTO projects (name, description, client_id, status, start_date, end_date, budget) VALUES
('Website Redesign', 'Complete overhaul of company website with modern design', 1, 'active', '2024-01-15', '2024-06-30', 25000.00),
('Mobile App Development', 'iOS and Android app for customer management', 1, 'planning', '2024-07-01', '2024-12-31', 50000.00),
('Database Migration', 'Migrate legacy system to cloud database', 2, 'active', '2024-02-01', '2024-05-31', 15000.00),
('API Integration', 'Integrate third-party services with existing platform', 3, 'completed', '2023-11-01', '2024-01-31', 20000.00);
INSERT INTO tasks (title, description, project_id, status, priority, assigned_to, due_date, estimated_hours, actual_hours) VALUES
('Design Homepage', 'Create wireframes and mockups for homepage', 1, 'in_progress', 'high', 'Sarah Johnson', '2024-03-15', 16.00, 8.00),
('Setup Development Environment', 'Configure local development setup', 1, 'completed', 'medium', 'Mike Chen', '2024-02-01', 4.00, 3.50),
('Database Schema Design', 'Design new database structure', 3, 'completed', 'high', 'Alex Rodriguez', '2024-02-15', 20.00, 18.00),
('API Authentication', 'Implement OAuth2 authentication flow', 4, 'completed', 'high', 'Lisa Wang', '2024-01-15', 12.00, 10.50),
('User Testing', 'Conduct usability testing with target users', 1, 'pending', 'medium', 'Sarah Johnson', '2024-04-01', 8.00, NULL),
('Performance Optimization', 'Optimize database queries and caching', 3, 'in_progress', 'medium', 'Alex Rodriguez', '2024-04-30', 24.00, 12.00);
Konfigurowanie uprawnień użytkownika
Należy uwierzytelnić wszystkie żądania interfejsu API danych, używając tokenów OAuth typu bearer Azure Databricks, które są wysyłane za pośrednictwem nagłówka Authorization. Interfejs API danych ogranicza dostęp do uwierzytelnionych tożsamości użytkowników Azure Databricks, a system Postgres zarządza uprawnieniami bazowymi.
Rola authenticator przyjmuje tożsamość żądającego użytkownika podczas przetwarzania żądań interfejsu API. Aby to działało, każda tożsamość Azure Databricks uzyskująca dostęp do API Danych musi mieć odpowiadającą rolę Postgres w Twojej bazie danych. Jeśli musisz najpierw dodać użytkowników do konta Azure Databricks, zobacz Dodaj użytkowników do konta.
Dodawanie ról Postgres
Ważne
Nie używaj konta właściciela bazy danych (tożsamości Azure Databricks odpowiedzialnej za utworzenie projektu Lakebase) do uzyskania dostępu do interfejsu API danych. Rola authenticator wymaga możliwości przejęcia roli i nie można przyznać uprawnień dla kont z podwyższonym poziomem uprawnień. Zamiast tego użyj nazwy głównej usługi (zalecane) lub innego konta użytkownika Azure Databricks.
Utwórz rolę, wykonując poniższe kroki SQL. Roli dodanej za pomocą elementu interfejsu użytkownika Role i bazy danych > Dodaj rolę nie można przyznać do authenticator, więc następny krok kończy się błędem odmowy uprawnień. Zobacz Rozwiązywanie problemów.
Za pomocą edytora SQL Lakebase utwórz rolę Postgres dla każdej tożsamości Azure Databricks, która wymaga dostępu do interfejsu API danych:
databricks_authUtwórz rozszerzenie. Każda baza danych Postgres musi mieć własne rozszerzenie.CREATE EXTENSION IF NOT EXISTS databricks_auth;Użyj
databricks_create_role, aby dodać rolę Postgres dla tożsamości Azure Databricks:Dla użytkownika:
SELECT databricks_create_role('user@databricks.com', 'USER');W przypadku jednostki usługi użyj identyfikatora aplikacji (UUID) jako nazwy tożsamości. Znajdź to w obszarze roboczym Azure Databricks w sekcji Ustawienia > Tożsamość i dostęp > Podmioty usługi:
SELECT databricks_create_role('8c01cfb1-62c9-4a09-88a8-e195f4b01b08', 'SERVICE_PRINCIPAL');
Udzielanie uprawnień użytkownikom
Po utworzeniu odpowiednich ról Postgres dla tożsamości Azure Databricks, musisz przyznać uprawnienia tym rolom Postgres. Te uprawnienia kontrolują, z którymi obiektami bazy danych (schematami, tabelami, sekwencjami, funkcjami) każdy użytkownik może wchodzić w interakcje za pośrednictwem żądań interfejsu API.
Udzielanie uprawnień przy użyciu standardowych instrukcji SQL GRANT . W tym przykładzie użyto schematu public; jeśli udostępniasz inny schemat, zastąp public nazwą swojego schematu.
-- Allow authenticator to assume the identity of the user
GRANT "user@databricks.com" TO authenticator;
-- Allow user@databricks.com to access everything in public schema
GRANT USAGE ON SCHEMA public TO "user@databricks.com";
GRANT SELECT, UPDATE, INSERT, DELETE ON ALL TABLES IN SCHEMA public TO "user@databricks.com";
GRANT USAGE ON ALL SEQUENCES IN SCHEMA public TO "user@databricks.com";
GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA public TO "user@databricks.com";
Ten przykład zapewnia pełny dostęp do schematu public dla tożsamości user@databricks.com. Zastąp to rzeczywistą tożsamością Azure Databricks i dostosuj uprawnienia zgodnie z wymaganiami. W przypadku jednostek usługi użyj identyfikatora aplikacji (UUID) jako nazwy roli Postgres w GRANT instrukcjach zamiast adresu e-mail.
Ważne
Implementowanie zabezpieczeń na poziomie wiersza: powyższe uprawnienia udzielają dostępu na poziomie tabeli, ale większość przypadków użycia interfejsu API wymaga ograniczeń na poziomie wiersza. Na przykład w aplikacjach wielodostępnych użytkownicy powinni widzieć tylko własne dane lub dane organizacji. Zasady zabezpieczeń na poziomie wiersza (RLS) postgreSQL umożliwiają wymuszanie szczegółowej kontroli dostępu na poziomie bazy danych. Zobacz Implementowanie zabezpieczeń na poziomie wiersza.
Uwierzytelnianie
Aby uzyskać dostęp do interfejsu API danych, musisz podać token OAuth Azure Databricks w nagłówku `Authorization` żądania HTTP. Uwierzytelniona tożsamość Azure Databricks musi mieć odpowiednią rolę Postgres (utworzoną w poprzednich krokach), która definiuje jej uprawnienia do bazy danych.
Uzyskiwanie tokenu OAuth
Połącz się z obszarem roboczym, korzystając z tożsamości Azure Databricks, dla której utworzono rolę Postgres w poprzednich krokach i uzyskaj token OAuth. Aby uzyskać instrukcje, zobacz Uwierzytelnianie .
Wysyłanie żądania
Za pomocą tokenu OAuth i adresu URL interfejsu API (dostępnego na karcie interfejsu API w aplikacji Lakebase) możesz wysyłać żądania interfejsu API przy użyciu narzędzia curl lub dowolnego klienta HTTP. Pamiętaj, aby dołączyć nazwę schematu (na przykład /public) do adresu URL interfejsu API. W poniższych przykładach założono, że zmienne środowiskowe DBX_OAUTH_TOKEN i REST_ENDPOINT zostały wyeksportowane.
Oto przykładowe wywołanie z oczekiwanymi danymi wyjściowymi (przy użyciu przykładowego schematu klientów/projektów/zadań):
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name,projects(id,name)&id=gte.2"
Przykładowa odpowiedź:
[
{ "id": 2, "name": "TechStart Inc", "projects": [{ "id": 3, "name": "Database Migration" }] },
{ "id": 3, "name": "Global Solutions", "projects": [{ "id": 4, "name": "API Integration" }] }
]
Aby uzyskać więcej przykładów i szczegółowych informacji na temat operacji interfejsu API, zobacz sekcję Dokumentacja interfejsu API . Aby uzyskać szczegółowe informacje na temat parametrów zapytań i możliwości interfejsu API, zobacz dokumentację interfejsu API PostgREST. Aby uzyskać informacje o zgodności specyficzne dla usługi Lakebase, zobacz Zgodność z usługą PostgREST.
Przed rozbudowanym użyciem interfejsu API skonfiguruj zabezpieczenia na poziomie wiersza , aby chronić dane.
Zarządzanie interfejsem API danych
Po włączeniu interfejsu API danych można zarządzać zmianami schematu i ustawieniami zabezpieczeń za pośrednictwem aplikacji Lakebase.
Odświeżanie pamięci podręcznej schematu
Po wprowadzeniu zmian w schemacie bazy danych (dodawaniu tabel, kolumn lub innych obiektów schematu) należy odświeżyć pamięć podręczną schematu. Dzięki temu zmiany są natychmiast dostępne za pośrednictwem interfejsu API danych.
Aby odświeżyć pamięć podręczną schematu:
- Przejdź do interfejsu API danych w sekcji Zaplecze aplikacji projektu.
- Kliknij Odśwież pamięć podręczną schematu.
Interfejs API danych odzwierciedla teraz najnowsze zmiany schematu.
Włączanie zabezpieczeń na poziomie wiersza
Aplikacja Lakebase umożliwia szybkie włączanie zabezpieczeń na poziomie wiersza dla tabel w bazie danych. Gdy tabele istnieją w schemacie, na karcie interfejsu API zostanie wyświetlona sekcja Ochrona danych zawierająca następujące informacje:
- Tabele z włączonym RLS
- Tabele z wyłączonym RLS (z ostrzeżeniami)
- Przycisk Włącz RLS do włączenia RLS dla wszystkich tabel
Ważne
Włączenie RLS za pośrednictwem aplikacji Lakebase powoduje zastosowanie zabezpieczeń na poziomie wiersza w tabelach. Po włączeniu RLS wszystkie wiersze stają się domyślnie niedostępne dla użytkowników (z wyjątkiem właścicieli tabel, ról z atrybutem BYPASSRLS, oraz superużytkowników, choć superużytkownicy nie są obsługiwani w usłudze Lakebase). Aby udzielić dostępu do określonych wierszy na podstawie wymagań dotyczących zabezpieczeń, należy utworzyć polityki RLS. Aby uzyskać informacje na temat tworzenia zasad, zobacz Zabezpieczenia na poziomie wiersza .
Aby włączyć ochronę na poziomie wiersza (RLS) dla tabel:
- Przejdź do interfejsu API danych w sekcji Zaplecze aplikacji projektu.
- W sekcji Ochrona danych przejrzyj tabele, które nie mają włączonego zabezpieczenia na poziomie wiersza.
- Kliknij Włącz RLS, aby włączyć zabezpieczenia na poziomie wiersza dla wszystkich tabel.
Zabezpieczenia na poziomie wiersza można również włączyć dla poszczególnych tabel przy użyciu języka SQL. Aby uzyskać szczegółowe informacje, zobacz Zabezpieczenia na poziomie wiersza .
Rozwiązywanie problemów
odmowa uprawnień do udzielenia roli (SQLSTATE 42501)
ERROR: permission denied to grant role "<identity>" (SQLSTATE 42501)
Dzieje się tak podczas uruchamiania GRANT "<identity>" TO authenticator, gdy:
- Rola została dodana za pomocą interfejsu użytkownika Roles & Databases. Zamiast tego utwórz rolę
databricks_create_rolew edytorze SQL. Zobacz Dodawanie ról Postgres. - Celem jest konto właściciela bazy danych. Użyj nazwy głównej usługi lub innego użytkownika usługi Azure Databricks, który nie jest właścicielem.
Interfejs API danych nie jest włączony dla tego punktu końcowego
Jeśli dodasz repliki do odczytu przed włączeniem Data API, endpointy mogą przez krótki czas zwracać ten błąd. Najpierw włącz interfejs API danych, a następnie dodaj repliki do odczytu.
Zaawansowane ustawienia interfejsu API danych
Sekcja Ustawienia zaawansowane na karcie Interfejs API w aplikacji Lakebase steruje zabezpieczeniami, wydajnością i zachowaniem punktu końcowego interfejsu API danych.
Uwidocznione schematy
Domyślny:public
Definiuje, które schematy postgreSQL są udostępniane jako punkty końcowe interfejsu API REST. Domyślnie tylko public schemat jest dostępny. Jeśli używasz innych schematów (na przykład api, v1), wybierz je z listy rozwijanej, aby je dodać.
Uwaga / Notatka
Uprawnienia mają zastosowanie: Dodanie schematu w tym miejscu uwidacznia punkty końcowe, ale rola bazy danych używana przez interfejs API musi nadal mieć USAGE uprawnienia do schematu i SELECT uprawnień w tabelach.
Maksymalna liczba wierszy
Domyślny: Pusty
Wymusza sztywny limit liczby wierszy, które mają być zwracane w pojedynczej odpowiedzi interfejsu API. Zapobiega to przypadkowemu pogorszeniu wydajności dużych zapytań. Klienci powinni używać limitów stronicowania do pobierania danych w ramach tego progu. Zapobiega to również nieoczekiwanym kosztom ruchu wychodzącego z dużych transferów danych.
Dozwolone źródła mechanizmu CORS
Domyślny: Brak ustawień (zezwala na wszystkie źródła)
Określa, które domeny internetowe mogą pobierać dane z interfejsu API przy użyciu przeglądarki.
-
Pusty: Zezwala
*(dowolna domena). Przydatne do programowania. -
Produkcja: Wyświetl listę określonych domen (na przykład
https://myapp.com), aby uniemożliwić nieautoryzowanym witrynom internetowym wysyłanie zapytań do interfejsu API.
Specyfikacja interfejsu OpenAPI
Domyślnie: Wyłączony
Określa, czy schemat OpenAPI 3 generowany automatycznie jest dostępny pod adresem /openapi.json. W tym schemacie opisano tabele, kolumny i punkty końcowe REST. Po włączeniu można go użyć do:
- Generowanie dokumentacji interfejsu API (Swagger UI, Redoc)
- Tworzenie bibliotek klienckich z typami (TypeScript, Python, Go)
- Importowanie interfejsu API do narzędzia Postman
- Integracja z bramami interfejsu API i innymi narzędziami opartymi na interfejsie OpenAPI
Nagłówki czasowe serwera
Domyślnie: Wyłączony
Po włączeniu, API danych zawiera nagłówki Server-Timing w każdej odpowiedzi. Te nagłówki pokazują, jak długo różne części żądania trwały do przetworzenia (na przykład czas wykonywania bazy danych i wewnętrzny czas przetwarzania). Te informacje umożliwiają debugowanie wolnych zapytań, mierzenie wydajności i rozwiązywanie problemów z opóźnieniami w aplikacji.
Uwaga / Notatka
Po wprowadzeniu zmian w ustawieniach zaawansowanych kliknij przycisk Zapisz , aby je zastosować.
Zabezpieczenia na poziomie wiersza
Zasady zabezpieczeń na poziomie wiersza zapewniają szczegółową kontrolę dostępu przez ograniczenie wierszy, do których użytkownicy mogą uzyskać dostęp w tabeli.
Jak RLS współpracuje z interfejsem API danych: Gdy użytkownik wysyła żądanie API, authenticator rola przyjmuje tożsamość tego użytkownika. Wszystkie zasady RLS zdefiniowane dla tej roli użytkownika są automatycznie wymuszane przez PostgreSQL, ograniczając dane dostępne dla użytkownika. Dzieje się tak na poziomie bazy danych, więc nawet jeśli kod aplikacji próbuje wykonać zapytanie dotyczące wszystkich wierszy, baza danych zwraca tylko wiersze, które użytkownik może zobaczyć. Zapewnia to ochronę w głąb systemu zabezpieczeń bez konieczności użycia logiki filtrowania w kodzie aplikacji.
Dlaczego RLS jest kluczowe dla interfejsów API: w przeciwieństwie do bezpośrednich połączeń z bazą danych, w których kontrolujesz kontekst połączenia, interfejsy API HTTP udostępniają bazę danych wielu użytkownikom za pośrednictwem jednego punktu końcowego. Same uprawnienia na poziomie tabeli oznaczają, że jeśli użytkownik może uzyskać dostęp do clients tabeli, może uzyskać dostęp do wszystkich rekordów klientów, chyba że implementujesz filtrowanie. Zasady zabezpieczeń na poziomie wiersza (RLS) zapewniają, że każdy użytkownik automatycznie widzi tylko swoje upoważnione dane.
RLS (Zabezpieczenia na poziomie wiersza) są niezbędne dla:
- Aplikacje wielodostępne: izolowanie danych między różnymi klientami lub organizacjami
- Dane należące do użytkownika: upewnij się, że użytkownicy uzyskują dostęp tylko do własnych rekordów
- Dostęp oparty na zespole: Ograniczanie widoczności członków zespołu lub określonych grup
- Wymagania dotyczące zgodności: Wymuszanie ograniczeń dostępu do danych na poziomie bazy danych
RLS i widoki: zasady RLS są stosowane na poziomie tabeli. Nie można zdefiniować zasady RLS bezpośrednio dla widoku. Domyślnie, gdy użytkownik wykonuje zapytanie na widoku, PostgreSQL ocenia zasady RLS dla właściciela widoku, a nie użytkownika wykonującego zapytanie. Oznacza to, że jeśli właściciel widoku jest właścicielem tabeli lub superużytkownikiem, zabezpieczenia na poziomie wiersza w tabeli bazowej są skutecznie pomijane dla każdego, kto może SELECT w widoku.
Aby wymusić zasady RLS w odniesieniu do użytkownika, który faktycznie wykonuje zapytanie, utwórz widok przy użyciu security_invoker = true:
CREATE VIEW my_view WITH (security_invoker = true) AS
SELECT * FROM clients;
Lub zaktualizuj istniejący widok:
ALTER VIEW my_view SET (security_invoker = true);
Alternatywnie użyj FORCE ROW LEVEL SECURITY na tabeli bazowej, aby RLS miało zastosowanie również do właściciela tabeli:
ALTER TABLE clients FORCE ROW LEVEL SECURITY;
Aby ograniczyć dostęp do samego widoku (określających, kto może go odpytywać), użyj uprawnień ról PostgreSQL (GRANT/REVOKE), a nie zasad RLS.
Włącz RLS (Zabezpieczenia na poziomie wiersza)
Można włączyć RLS (zabezpieczenia na poziomie wiersza) za pomocą aplikacji Lakebase lub używając instrukcji SQL. Aby uzyskać instrukcje dotyczące korzystania z aplikacji Lakebase, zobacz Włączanie zabezpieczeń na poziomie wiersza.
Ostrzeżenie
Jeśli masz tabele bez włączonych zabezpieczeń RLS, karta interfejsu API w aplikacji Lakebase wyświetla ostrzeżenie, że uwierzytelnieni użytkownicy mogą wyświetlać wszystkie wiersze w tych tabelach. Interfejs API danych współdziała bezpośrednio ze schematem Postgres i dlatego, że interfejs API jest dostępny za pośrednictwem Internetu, niezwykle ważne jest wymuszanie zabezpieczeń na poziomie bazy danych przy użyciu zabezpieczeń na poziomie wiersza bazy danych PostgreSQL.
Aby włączyć RLS przy użyciu języka SQL, uruchom następujące polecenie:
ALTER TABLE clients ENABLE ROW LEVEL SECURITY;
Tworzenie zasad zabezpieczeń na poziomie wiersza
Po włączeniu RLS (zabezpieczeń na poziomie wiersza) w tabeli, należy utworzyć zasady polityki definiujące reguły dostępu. Bez zasad użytkownicy nie mogą uzyskać dostępu do żadnych wierszy (wszystkie wiersze są domyślnie ukryte).
Jak działają zasady: po włączeniu RLS na tabeli użytkownicy mogą wyświetlać tylko wiersze zgodne z co najmniej jedną zasadą. Wszystkie inne wiersze są odfiltrowane. Właściciele tabel, role z atrybutem BYPASSRLS i superużytkownicy mogą pominąć system zabezpieczeń wiersza (choć superużytkownicy nie są obsługiwani w usłudze Lakebase).
Uwaga / Notatka
W usłudze Lakebase current_user zwraca uwierzytelniony adres e-mail użytkownika (na przykład user@databricks.com). Użyj tej funkcji w zasadach RLS, aby określić, który użytkownik wysyła żądanie.
Podstawowa składnia zasad:
CREATE POLICY policy_name ON table_name
[TO role_name]
USING (condition);
- policy_name: opisowa nazwa zasad
- table_name: tabela, do której zastosować politykę
- DO role_name: Opcjonalny. Określa rolę dla tych zasad. Pomiń tę klauzulę, aby zastosować zasady do wszystkich ról.
- USING (warunek): warunek określający, które wiersze są widoczne
Samouczek RLS
W poniższym samouczku użyto przykładowego schematu z tej dokumentacji (klientów, projektów, tabel zadań), aby pokazać, jak zaimplementować zabezpieczenia na poziomie wiersza.
Scenariusz: Masz wielu użytkowników, którzy powinni widzieć tylko przypisanych klientów i powiązanych projektów. Ogranicz dostęp w taki sposób, aby:
-
alice@databricks.commoże wyświetlać tylko klientów z identyfikatorami 1 i 2 -
bob@databricks.commoże wyświetlać tylko klientów z identyfikatorami 2 i 3
Krok 1. Włącz RLS w tabeli klientów
ALTER TABLE clients ENABLE ROW LEVEL SECURITY;
Krok 2. Tworzenie zasad dla Alicji
CREATE POLICY alice_clients ON clients
TO "alice@databricks.com"
USING (id IN (1, 2));
Krok 3. Tworzenie zasad dla Boba
CREATE POLICY bob_clients ON clients
TO "bob@databricks.com"
USING (id IN (2, 3));
Krok 4. Testowanie zasad
Gdy Alicja wysyła żądanie interfejsu API:
# Alice's token in the Authorization header
curl -H "Authorization: Bearer $ALICE_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name"
Odpowiedź (Alicja widzi tylko klientów 1 i 2):
[
{ "id": 1, "name": "Acme Corp" },
{ "id": 2, "name": "TechStart Inc" }
]
Gdy Bob wysyła żądanie interfejsu API:
# Bob's token in the Authorization header
curl -H "Authorization: Bearer $BOB_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name"
Odpowiedź (Bob widzi tylko klientów 2 i 3):
[
{ "id": 2, "name": "TechStart Inc" },
{ "id": 3, "name": "Global Solutions" }
]
Typowe wzorce zabezpieczeń RLS
Te wzorce obejmują typowe wymagania dotyczące zabezpieczeń interfejsu API danych:
Własność użytkownika — ogranicza wiersze dla uwierzytelnionego użytkownika:
CREATE POLICY user_owned_data ON tasks
USING (assigned_to = current_user);
Izolacja tenantów — ogranicza wiersze do organizacji użytkownika:
CREATE POLICY tenant_data ON clients
USING (tenant_id = (
SELECT tenant_id
FROM user_tenants
WHERE user_email = current_user
));
Członkostwo w zespole — ogranicza wiersze do zespołów użytkownika:
CREATE POLICY team_projects ON projects
USING (client_id IN (
SELECT client_id
FROM team_clients
WHERE team_id IN (
SELECT team_id
FROM user_teams
WHERE user_email = current_user
)
));
Dostęp oparty na rolach — ogranicza wiersze na podstawie członkostwa w rolach:
CREATE POLICY manager_access ON tasks
USING (
status = 'pending' OR
pg_has_role(current_user, 'managers', 'member')
);
Tylko do odczytu dla określonych ról — różne zasady dla różnych operacji:
-- Allow all users to read their assigned tasks
CREATE POLICY read_assigned_tasks ON tasks
FOR SELECT
USING (assigned_to = current_user);
-- Only managers can update tasks
CREATE POLICY update_tasks ON tasks
FOR UPDATE
TO "managers"
USING (true);
Dodatkowe zasoby
Aby uzyskać kompleksowe informacje na temat implementowania zasad zabezpieczeń wierszy (RLS), w tym typów zasad, najlepszych praktyk w zakresie zabezpieczeń i zaawansowanych wzorców, zobacz dokumentację zasad zabezpieczeń wierszy PostgreSQL.
Aby uzyskać więcej informacji na temat uprawnień, zobacz Zarządzanie uprawnieniami.
Dokumentacja interfejsu API
W tej sekcji założono, że wykonano kroki konfiguracji, skonfigurowano uprawnienia i zaimplementowano zabezpieczenia na poziomie wiersza. Poniższe sekcje zawierają informacje referencyjne dotyczące korzystania z interfejsu API danych, w tym typowe operacje, funkcje zaawansowane, zagadnienia dotyczące zabezpieczeń i szczegóły zgodności.
Podstawowe operacje
Wykonywanie zapytań dotyczących rekordów
Pobieranie rekordów z tabeli przy użyciu protokołu HTTP GET:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients"
Przykładowa odpowiedź:
[
{ "id": 1, "name": "Acme Corp", "email": "contact@acme.com", "company": "Acme Corporation", "phone": "+1-555-0101" },
{
"id": 2,
"name": "TechStart Inc",
"email": "hello@techstart.com",
"company": "TechStart Inc",
"phone": "+1-555-0102"
}
]
Filtruj wyniki
Użyj parametrów zapytania, aby filtrować wyniki. W tym przykładzie pobierani są klienci z id większymi lub równymi 2.
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?id=gte.2"
Przykładowa odpowiedź:
[
{ "id": 2, "name": "TechStart Inc", "email": "hello@techstart.com" },
{ "id": 3, "name": "Global Solutions", "email": "info@globalsolutions.com" }
]
Wybierz określone kolumny i połącz tabele
Użyj parametru select, aby pobrać określone kolumny i łączyć powiązane tabele.
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name,projects(id,name)&id=gte.2"
Przykładowa odpowiedź:
[
{ "id": 2, "name": "TechStart Inc", "projects": [{ "id": 3, "name": "Database Migration" }] },
{ "id": 3, "name": "Global Solutions", "projects": [{ "id": 4, "name": "API Integration" }] }
]
Wstaw rekordy
Utwórz nowe rekordy przy użyciu protokołu HTTP POST:
curl -X POST \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "New Client",
"email": "newclient@example.com",
"company": "New Company Inc",
"phone": "+1-555-0104"
}' \
"$REST_ENDPOINT/public/clients"
Aktualizacja rekordów
Zaktualizuj istniejące rekordy przy użyciu poprawki HTTP:
curl -X PATCH \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{"phone": "+1-555-0199"}' \
"$REST_ENDPOINT/public/clients?id=eq.1"
Usuwanie rekordów
Usuwanie rekordów przy użyciu funkcji HTTP DELETE:
curl -X DELETE \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?id=eq.5"
Funkcje zaawansowane
Paginacja
Kontroluj liczbę rekordów zwracanych za pomocą parametrów limit i offset.
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?limit=10&offset=0"
Sortowanie
Sortuj wyniki przy użyciu parametru order :
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?order=due_date.desc"
Filtrowanie złożone
Łączenie wielu warunków filtrowania:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?status=eq.in_progress&priority=eq.high"
Typowe operatory filtrów:
-
eq- równa się -
gte- większe lub równe -
lte- mniejsze lub równe -
neq- nie równa się -
like- dopasowywanie wzorca -
in— pasuje do dowolnej wartości na liście
Aby uzyskać więcej informacji na temat obsługiwanych parametrów zapytań i funkcji interfejsu API, zobacz dokumentację interfejsu API PostgREST. Aby uzyskać informacje o zgodności specyficzne dla usługi Lakebase, zobacz Zgodność z usługą PostgREST.
Odniesienie dotyczące zgodności funkcji
Interfejs API danych Lakebase jest w pełni zgodny ze specyfikacją PostgREST, obejmując osadzanie zasobów (relacje klucza obcego i obliczane, wskazówki dla połączeń wewnętrznych/lewych), formaty odpowiedzi (JSON, CSV, GeoJSON, niestandardowe typy mediów), filtrowanie, stronicowanie, tryby zliczania (exact, planned, estimated), preferencje żądań (handling, timezone, tx), ekspozycję planu zapytań oraz funkcje RPC.
Następujące funkcje PostgREST nie mają zastosowania lub nie są dostępne w środowisku Lakebase:
Uwierzytelnianie
| Funkcja | Status | Szczegóły |
|---|---|---|
| Konfiguracja JWT | Nie dotyczy | API danych Lakebase używa tokenów OAuth Azure Databricks zamiast autentykacji JWT. Opcje konfiguracji specyficzne dla JWT (niestandardowe sekrety, klucze RS256, walidacja audiencji) nie są dostępne. |
Konfiguracja zaawansowana
| Funkcja | Status | Szczegóły |
|---|---|---|
| Ustawienia aplikacji (GUCs) | Niewspierane | Przekazywanie niestandardowych wartości konfiguracji do funkcji bazy danych za pośrednictwem GUCs PostgreSQL nie jest obsługiwane. |
| Funkcja wstępna żądania | Niewspierane | Konfiguracja umożliwiająca db-pre-request określenie funkcji bazy danych do uruchomienia przed każdym żądaniem nie jest obsługiwana. |
Observability
| Funkcja | Status | Szczegóły |
|---|---|---|
| Propagacja nagłówka śledzenia | Nie dotyczy | Usługa Lakebase implementuje własne funkcje obserwowalności zamiast X-Request-Id i propagacji niestandardowego nagłówka śledzenia w PostgREST. |
Aby uzyskać więcej informacji na temat funkcji PostgREST, zobacz dokumentację postgREST.
Zagadnienia dotyczące zabezpieczeń
Interfejs API danych wymusza model zabezpieczeń bazy danych na wielu poziomach:
- Uwierzytelnianie: wszystkie żądania wymagają prawidłowego uwierzytelniania tokenu OAuth
- Dostęp oparty na rolach: kontrola uprawnień na poziomie bazy danych, do których tabel i operacji użytkownicy mogą uzyskiwać dostęp
- Zabezpieczenia na poziomie wiersza: zasady zabezpieczeń na poziomie wiersza wymuszają szczegółową kontrolę dostępu, ograniczając, które określone wiersze użytkownicy mogą wyświetlać lub modyfikować
- Kontekst użytkownika: interfejs API zakłada tożsamość uwierzytelnioną użytkownika, zapewniając prawidłowe stosowanie uprawnień bazy danych i zasad
Zalecane rozwiązania w zakresie zabezpieczeń
W przypadku wdrożeń produkcyjnych:
- Zaimplementuj zabezpieczenia na poziomie wiersza: Wykorzystaj zasady RLS, aby ograniczyć dostęp do danych. Jest to szczególnie ważne w przypadku aplikacji wielodostępnych i danych należących do użytkownika. Zobacz zabezpieczenia na poziomie wiersza.
-
Udziel minimalnych uprawnień: przyznaj tylko uprawnienia, których potrzebują użytkownicy (
SELECT,INSERT,UPDATE,DELETE) w określonych tabelach, zamiast udzielać szerokiego dostępu. - Używaj oddzielnych ról na aplikację: utwórz dedykowane role dla różnych aplikacji lub usług zamiast współdzielić jedną rolę.
- Regularnie przeprowadzaj inspekcję dostępu: okresowo sprawdzaj przyznane uprawnienia i zasady RLS, aby upewnić się, że spełniają one wymagania dotyczące zabezpieczeń.
Aby uzyskać informacje na temat zarządzania rolami i uprawnieniami, zobacz: