Planowanie wydajności klastrów usługi HDInsight
Przed wdrożeniem klastra usługi HDInsight zaplanuj docelową pojemność klastra, określając wymaganą wydajność i skalę. To planowanie pomaga zoptymalizować zarówno użyteczność, jak i koszty. Niektórych decyzji dotyczących pojemności klastra nie można zmienić po wdrożeniu. Jeśli parametry wydajności zmienią się, klaster można zdemontować i ponownie utworzyć bez utraty przechowywanych danych.
Kluczowe pytania dotyczące planowania pojemności to:
- W którym regionie geograficznym należy wdrożyć klaster?
- Ile miejsca do magazynowania potrzebujesz?
- Jakiego typu klastra należy wdrożyć?
- Jakiego rozmiaru i typu maszyny wirtualnej powinny używać węzły klastra?
- Ile węzłów procesu roboczego powinno mieć klaster?
Wybieranie regionu świadczenia usługi Azure
Region świadczenia usługi Azure określa, gdzie klaster jest fizycznie aprowizowany. Aby zminimalizować opóźnienie operacji odczytu i zapisu, klaster powinien znajdować się w pobliżu danych.
Usługa HDInsight jest dostępna w wielu regionach świadczenia usługi Azure. Aby znaleźć najbliższy region, zobacz Dostępność produktów według regionów.
Wybieranie lokalizacji i rozmiaru magazynu
Lokalizacja domyślnego magazynu
Domyślny magazyn , konto usługi Azure Storage lub usługa Azure Data Lake Storage, musi znajdować się w tej samej lokalizacji co klaster. Usługa Azure Storage jest dostępna we wszystkich lokalizacjach. Usługa Data Lake Storage jest dostępna w niektórych regionach — zobacz bieżącą dostępność usługi Data Lake Storage.
Lokalizacja istniejących danych
Jeśli chcesz użyć istniejącego konta magazynu lub usługi Data Lake Storage jako domyślnego magazynu klastra, musisz wdrożyć klaster w tej samej lokalizacji.
Rozmiar magazynu
W wdrożonym klastrze można dołączyć inne konta usługi Azure Storage lub uzyskać dostęp do innych usługi Data Lake Storage. Wszystkie konta magazynu muszą znajdować się w tej samej lokalizacji co klaster. Usługa Data Lake Storage może znajdować się w innej lokalizacji, ale duże odległości mogą powodować pewne opóźnienia.
Usługa Azure Storage ma pewne limity pojemności, a usługa Data Lake Storage jest prawie nieograniczona. Klaster może uzyskiwać dostęp do kombinacji różnych kont magazynu. Typowe przykłady:
- Gdy ilość danych prawdopodobnie przekroczy pojemność magazynu pojedynczego kontenera obiektów blob.
- Gdy szybkość dostępu do kontenera obiektów blob może przekroczyć próg, w którym występuje ograniczanie przepustowości.
- Gdy chcesz udostępnić dane, przekazano już do kontenera obiektów blob dostępnego dla klastra.
- Jeśli chcesz odizolować różne części magazynu ze względów bezpieczeństwa lub uprościć administrację.
Aby uzyskać lepszą wydajność, użyj tylko jednego kontenera na konto magazynu.
Wybieranie typu klastra
Typ klastra określa obciążenie skonfigurowane do uruchomienia klastra usługi HDInsight. Typy to Apache Hadoop, Apache Kafka lub Apache Spark. Aby uzyskać szczegółowy opis dostępnych typów klastrów, zobacz Wprowadzenie do usługi Azure HDInsight. Każdy typ klastra ma określoną topologię wdrożenia, która zawiera wymagania dotyczące rozmiaru i liczby węzłów.
Wybieranie rozmiaru i typu maszyny wirtualnej
Każdy typ klastra ma zestaw typów węzłów, a każdy typ węzła ma określone opcje dotyczące rozmiaru i typu maszyny wirtualnej.
Aby określić optymalny rozmiar klastra dla aplikacji, możesz przeprowadzić test porównawczy pojemności klastra i zwiększyć rozmiar zgodnie ze wskazaniem. Można na przykład użyć symulowanego obciążenia lub zapytania kanarowego. Uruchamianie symulowanych obciążeń w różnych klastrach o różnych rozmiarach. Stopniowo zwiększaj rozmiar do momentu osiągnięcia zamierzonej wydajności. Zapytanie kanarne można okresowo wstawiać między innymi zapytaniami produkcyjnymi, aby pokazać, czy klaster ma wystarczającą ilość zasobów.
Aby uzyskać więcej informacji na temat wybierania odpowiedniej rodziny maszyn wirtualnych dla obciążenia, zobacz Wybieranie odpowiedniego rozmiaru maszyny wirtualnej dla klastra.
Wybieranie skali klastra
Skala klastra zależy od ilości węzłów maszyny wirtualnej. W przypadku wszystkich typów klastrów istnieją typy węzłów, które mają określoną skalę, oraz typy węzłów, które obsługują skalowanie w poziomie. Na przykład klaster może wymagać dokładnie trzech węzłów usługi Apache ZooKeeper lub dwóch węzłów głównych. Węzły robocze, które przetwarzają dane w sposób rozproszony, korzystają z innych węzłów procesu roboczego.
W zależności od typu klastra zwiększenie liczby węzłów roboczych zwiększa pojemność obliczeniową (np. więcej rdzeni). Więcej węzłów zwiększy łączną ilość pamięci wymaganej dla całego klastra w celu obsługi magazynu w pamięci przetwarzanych danych. Podobnie jak w przypadku wyboru rozmiaru i typu maszyny wirtualnej, wybór odpowiedniej skali klastra jest zwykle osiągany empirycznie. Używanie symulowanych obciążeń lub zapytań kanarowych.
Klaster można skalować w poziomie, aby sprostać szczytowemu zapotrzebowaniu na obciążenie. Następnie przeprowadź skalowanie w dół, gdy te dodatkowe węzły nie są już potrzebne. Funkcja autoskalowania umożliwia automatyczne skalowanie klastra na podstawie wstępnie określonych metryk i chronometrażu. Aby uzyskać więcej informacji na temat ręcznego skalowania klastrów, zobacz Skalowanie klastrów usługi HDInsight.
Cykl życia klastra
Opłaty są naliczane za okres istnienia klastra. Jeśli klaster wymaga tylko określonych godzin, utwórz klastry na żądanie przy użyciu usługi Azure Data Factory. Możesz również utworzyć skrypty programu PowerShell, które aprowizować i usuwać klaster, a następnie planować te skrypty przy użyciu usługi Azure Automation.
Uwaga
Po usunięciu klastra jego domyślny magazyn metadanych Hive również zostanie usunięty. Aby zachować magazyn metadanych na potrzeby następnego ponownego tworzenia klastra, użyj zewnętrznego magazynu metadanych, takiego jak Azure Database lub Apache Oozie.
Izolowanie błędów zadań klastra
Czasami mogą wystąpić błędy z powodu równoległego wykonywania wielu składników map i redukcji w klastrze z wieloma węzłami. Aby pomóc wyizolować problem, wypróbuj testowanie rozproszone. Uruchamianie współbieżnych wielu zadań w klastrze jednego węzła roboczego. Następnie rozwiń to podejście, aby jednocześnie uruchamiać wiele zadań w klastrach zawierających więcej niż jeden węzeł. Aby utworzyć klaster usługi HDInsight z jednym węzłem na platformie Azure, użyj opcji i użyj Custom(size, settings, apps) wartości 1 w sekcji Liczba węzłów procesu roboczego w sekcji Rozmiar klastra podczas aprowizowania nowego klastra w portalu.
Wyświetlanie zarządzania limitami przydziału dla usługi HDInsight
Wyświetlanie szczegółowego poziomu i kategoryzacji limitu przydziału na poziomie rodziny maszyn wirtualnych. Wyświetl bieżący limit przydziału i liczbę pozostałych przydziałów dla regionu na poziomie rodziny maszyn wirtualnych.
Uwaga
Ta funkcja jest obecnie dostępna w usługach HDInsight 4.x i 5.x dla regionu Wschodnie stany USA EUAP. Inne regiony, które mają być następnie obserwowane.
Wyświetl bieżący limit przydziału:
Zobacz bieżący limit przydziału i liczbę pozostałych przydziałów dla regionu na poziomie rodziny maszyn wirtualnych.
W witrynie Azure Portal na górnym pasku wyszukiwania wyszukaj i wybierz pozycję Limity przydziału.
Na stronie Limit przydziału wybierz pozycję Azure HDInsight
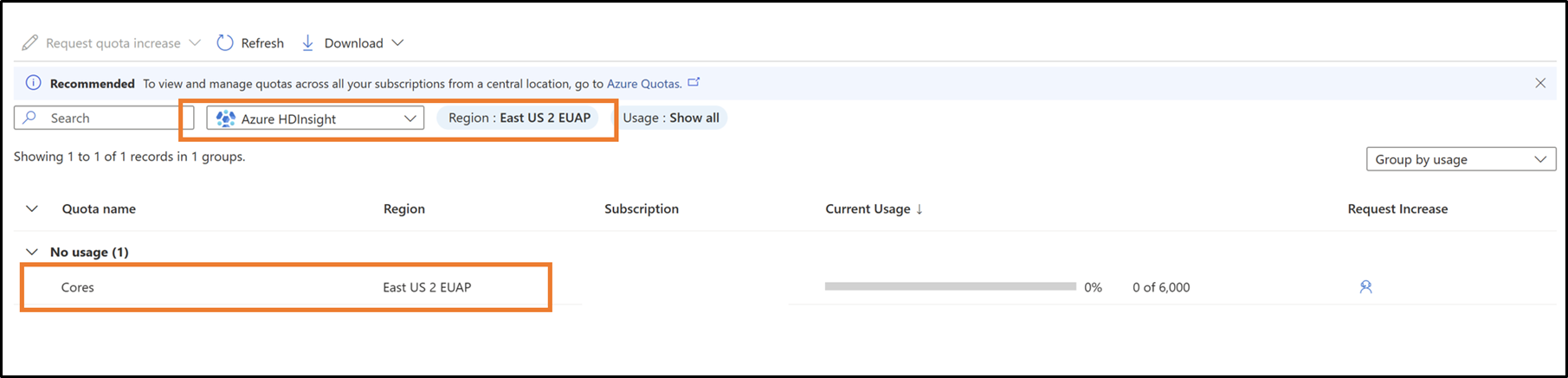
Z listy rozwijanej wybierz swoją subskrypcję i region
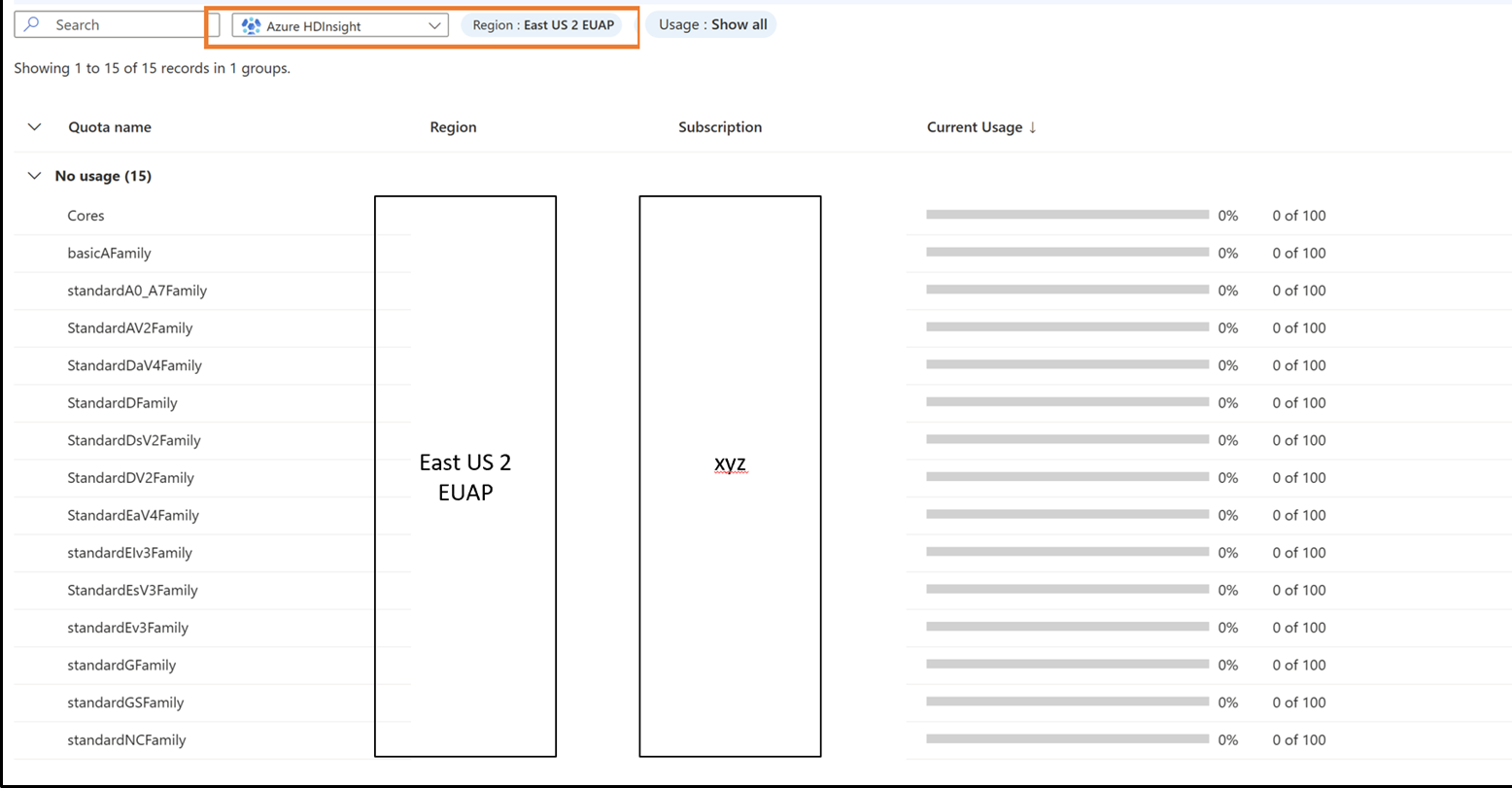
Żądanie nowych przydziałów dla rodziny maszyn wirtualnych i regionu
- Kliknij wiersz, dla którego chcesz wyświetlić szczegóły limitu przydziału.
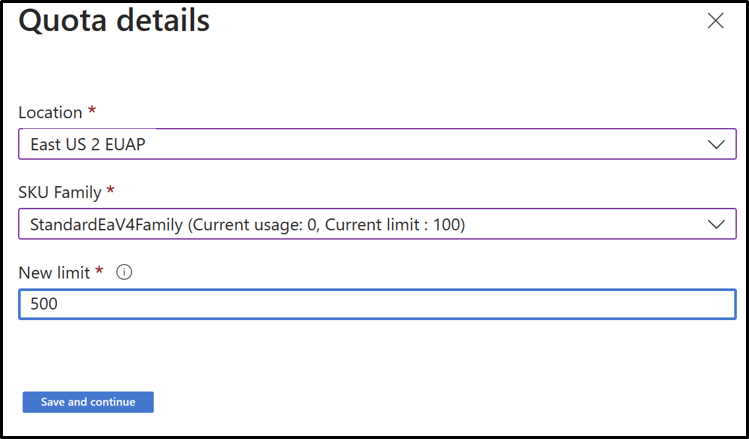




Normy sprzedaży
Aby uzyskać więcej informacji na temat zarządzania limitami przydziałów subskrypcji, zobacz Żądanie zwiększenia limitu przydziału.
Następne kroki
- Konfigurowanie klastrów w usłudze HDInsight przy użyciu platform Apache Hadoop, Spark, Kafka i nie tylko: Dowiedz się, jak konfigurować i konfigurować klastry w usłudze HDInsight.
- Monitorowanie wydajności klastra: dowiedz się więcej o kluczowych scenariuszach monitorowania klastra usługi HDInsight, które mogą mieć wpływ na pojemność klastra.