Rozwiązywanie problemów dotyczących wolnego działania lub niepowodzenia zadania w klastrze usługi HDInsight
Jeśli dane przetwarzania aplikacji w klastrze usługi HDInsight działają wolno lub kończą się niepowodzeniem z kodem błędu, masz kilka opcji rozwiązywania problemów. Jeśli uruchamianie zadań trwa dłużej niż oczekiwano lub ogólnie występują powolne czasy odpowiedzi, mogą wystąpić błędy nadrzędne z klastra, takie jak usługi, na których działa klaster. Jednak najczęstszą przyczyną tych spowolnień jest niewystarczające skalowanie. Podczas tworzenia nowego klastra usługi HDInsight wybierz odpowiednie rozmiary maszyn wirtualnych.
Aby zdiagnozować powolny lub kończący się niepowodzeniem klaster, zbierz informacje o wszystkich aspektach środowiska, takich jak skojarzone usługi platformy Azure, konfiguracja klastra i informacje o wykonywaniu zadania. Przydatną diagnostyką jest próba odtworzenia stanu błędu w innym klastrze.
- Krok 1. Zbieranie danych dotyczących problemu.
- Krok 2. Weryfikowanie środowiska klastra usługi HDInsight.
- Krok 3. Wyświetlanie kondycji klastra.
- Krok 4. Przeglądanie stosu i wersji środowiska.
- Krok 5. Badanie plików dziennika klastra.
- Krok 6. Sprawdzanie ustawień konfiguracji.
- Krok 7. Odtworzenie błędu w innym klastrze.
Krok 1. Zbieranie danych dotyczących problemu
Usługa HDInsight udostępnia wiele narzędzi, których można użyć do identyfikowania i rozwiązywania problemów z klastrami. Poniższe kroki przeprowadzą Cię przez te narzędzia i zawierają sugestie dotyczące ustalania problemu.
Identyfikowanie problemu
Aby ułatwić zidentyfikowanie problemu, rozważ następujące pytania:
- Czego się spodziewałem? Co się stało zamiast tego?
- Jak długo trwał proces? Jak długo powinien zostać uruchomiony?
- Czy moje zadania zawsze działają wolno w tym klastrze? Czy działały szybciej w innym klastrze?
- Kiedy ten problem wystąpił po raz pierwszy? Jak często to się stało od tego czasu?
- Czy coś się zmieniło w mojej konfiguracji klastra?
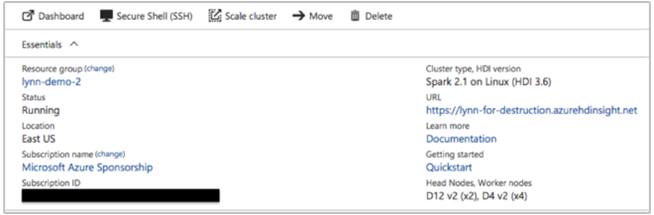
Szczegóły klastra
Ważne informacje o klastrze obejmują:
- Nazwa klastra.
- Region klastra — sprawdź awarie regionów.
- Typ i wersja klastra usługi HDInsight.
- Typ i liczba wystąpień usługi HDInsight określonych dla węzłów głównych i roboczych.
Witryna Azure Portal może podać następujące informacje:
Możesz również użyć interfejsu wiersza polecenia platformy Azure:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Inną opcją jest użycie programu PowerShell. Aby uzyskać więcej informacji, zobacz Zarządzanie klastrami Apache Hadoop w usłudze HDInsight przy użyciu programu Azure PowerShell.
Krok 2. Weryfikowanie środowiska klastra usługi HDInsight
Każdy klaster usługi HDInsight opiera się na różnych usługach platformy Azure i oprogramowaniu typu open source, takim jak Apache HBase i Apache Spark. Klastry usługi HDInsight mogą również wywoływać inne usługi platformy Azure, takie jak Azure Virtual Networks. Awaria klastra może być spowodowana przez dowolne z uruchomionych usług w klastrze lub przez usługę zewnętrzną. Zmiana konfiguracji usługi klastra może również spowodować niepowodzenie klastra.
Szczegóły usługi
- Sprawdź wersje wersji biblioteki open source.
- Sprawdź przerwy w działaniu usługi platformy Azure.
- Sprawdź limity użycia usługi platformy Azure.
- Sprawdź konfigurację podsieci usługi Azure Virtual Network.
Wyświetlanie ustawień konfiguracji klastra za pomocą interfejsu użytkownika systemu Ambari
Apache Ambari zapewnia zarządzanie klastrem usługi HDInsight i monitorowanie go za pomocą internetowego interfejsu użytkownika i interfejsu API REST. System Ambari jest dołączony do klastrów usługi HDInsight opartych na systemie Linux. Wybierz okienko Pulpit nawigacyjny klastra na stronie usługi HDInsight w witrynie Azure Portal. Wybierz okienko pulpitu nawigacyjnego klastra usługi HDInsight, aby otworzyć interfejs użytkownika systemu Ambari, a następnie wprowadź poświadczenia logowania klastra.
Aby otworzyć listę widoków usług, wybierz pozycję Widoki systemu Ambari na stronie witryny Azure Portal. Ta lista zależy od tego, które biblioteki są zainstalowane. Na przykład mogą zostać wyświetlone pozycje Menedżer kolejek usługi YARN, Widok Hive i Tez View. Wybierz link usługi, aby wyświetlić informacje o konfiguracji i usłudze.
Sprawdzanie, czy wystąpiły awarie usługi platformy Azure
Usługa HDInsight korzysta z kilku usług platformy Azure. Uruchamia ona serwery wirtualne w usłudze Azure HDInsight, przechowuje dane i skrypty w usłudze Azure Blob Storage lub Azure Data Lake Storage oraz indeksuje pliki dziennika w usłudze Azure Table Storage. Zakłócenia w tych usługach, choć rzadkie, mogą powodować problemy w usłudze HDInsight. Jeśli w klastrze wystąpią nieoczekiwane spowolnienie lub awarie, sprawdź pulpit nawigacyjny stanu platformy Azure. Stan każdej usługi jest wyświetlany według regionu. Sprawdź region klastra, a także regiony dla dowolnych powiązanych usług.
Sprawdzanie limitów użycia usługi platformy Azure
Jeśli uruchamiasz duży klaster lub uruchamiasz wiele klastrów jednocześnie, klaster może zakończyć się niepowodzeniem, jeśli przekroczono limit usługi platformy Azure. Limity usług różnią się w zależności od subskrypcji platformy Azure. Aby uzyskać więcej informacji, zobacz Limity, przydziały i ograniczenia usług i subskrypcji platformy Azure. Możesz poprosić firmę Microsoft o zwiększenie liczby dostępnych zasobów usługi HDInsight (takich jak rdzenie maszyn wirtualnych i wystąpienia maszyn wirtualnych) przy użyciu żądania zwiększenia limitu przydziału rdzeni usługi Resource Manager.
Sprawdzanie wersji
Porównaj wersję klastra z najnowszą wersją usługi HDInsight. Każda wersja usługi HDInsight zawiera ulepszenia, takie jak nowe aplikacje, funkcje, poprawki i poprawki błędów. Problem, który ma wpływ na klaster, mógł zostać rozwiązany w najnowszej wersji. Jeśli to możliwe, uruchom ponownie klaster przy użyciu najnowszej wersji usługi HDInsight i skojarzonych bibliotek, takich jak Apache HBase, Apache Spark i inne.
Ponowne uruchamianie usług klastra
Jeśli w klastrze występują spowolnienia, rozważ ponowne uruchomienie usług za pomocą interfejsu użytkownika systemu Ambari lub klasycznego interfejsu wiersza polecenia platformy Azure. W klastrze mogą występować błędy przejściowe, a ponowne uruchomienie jest najszybszym sposobem stabilizacji środowiska i prawdopodobnie zwiększenia wydajności.
Krok 3. Wyświetlanie kondycji klastra
Klastry usługi HDInsight składają się z różnych typów węzłów uruchomionych w wystąpieniach maszyn wirtualnych. Każdy węzeł można monitorować pod kątem głodu zasobów, problemów z łącznością sieciową i innych problemów, które mogą spowalniać klaster. Każdy klaster zawiera dwa węzły główne, a większość typów klastrów zawiera kombinację węzłów procesów roboczych i węzłów brzegowych.
Opis różnych węzłów używanych przez poszczególne typy klastrów znajduje się w temacie Konfigurowanie klastrów w usłudze HDInsight przy użyciu usług Apache Hadoop, Apache Spark, Apache Kafka i nie tylko.
W poniższych sekcjach opisano sposób sprawdzania kondycji każdego węzła i ogólnego klastra.
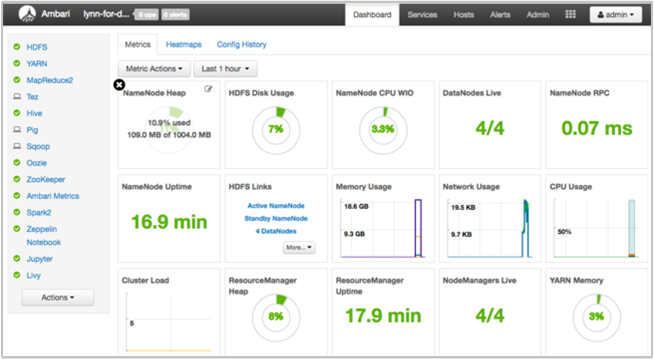
Uzyskiwanie migawki kondycji klastra przy użyciu pulpitu nawigacyjnego interfejsu użytkownika systemu Ambari
Pulpit nawigacyjny interfejsu użytkownika systemu Ambari (https://<clustername>.azurehdinsight.net) zawiera omówienie kondycji klastra, takie jak czas pracy, pamięć, użycie sieci i procesora CPU, użycie dysku hdFS itd. Użyj sekcji Hosty systemu Ambari, aby wyświetlić zasoby na poziomie hosta. Możesz również zatrzymać i ponownie uruchomić usługi.
Sprawdzanie usługi WebHCat
Jednym z typowych scenariuszy niepowodzenia zadań Apache Hive, Apache Pig lub Apache Sqoop jest niepowodzenie usługi WebHCat (lub Templeton). WebHCat to interfejs REST do zdalnego wykonywania zadań, takich jak Hive, Pig, Scoop i MapReduce. Usługa WebHCat tłumaczy żądania przesyłania zadań na aplikacje apache Hadoop YARN i zwraca stan pochodzący ze stanu aplikacji YARN. W poniższych sekcjach opisano typowe kody stanu HTTP webHCat.
BadGateway (kod stanu 502)
Ten kod jest ogólnym komunikatem z węzłów bramy i jest najbardziej typowymi kodami stanu awarii. Jedną z możliwych przyczyn jest wyłączenie usługi WebHCat w aktywnym węźle głównym. Aby sprawdzić tę możliwość, użyj następującego polecenia CURL:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Narzędzie Ambari wyświetla alert pokazujący hosty, na których działa usługa WebHCat. Możesz spróbować przywrócić kopię zapasową usługi WebHCat, uruchamiając ponownie usługę na hoście.
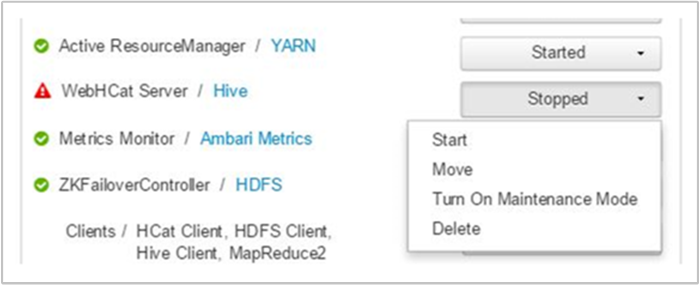
Jeśli serwer WebHCat nadal nie pojawi się, sprawdź dziennik operacji pod kątem komunikatów o błędach. Aby uzyskać bardziej szczegółowe informacje, sprawdź stderr pliki i stdout , do których się odwołujesz w węźle.
Limit czasu serwera WebHCat
Upłynął limit czasu odpowiedzi bramy usługi HDInsight, które trwa dłużej niż dwie minuty, zwracając wartość 502 BadGateway. Usługa WebHCat wysyła zapytania do usług YARN pod kątem stanów zadań, a jeśli YARN odpowiada dłużej niż dwie minuty, to żądanie może upłynął limit czasu.
W takim przypadku przejrzyj następujące dzienniki w /var/log/webhcat katalogu:
- webhcat.log jest dziennik Log4j, do którego serwer zapisuje dzienniki
- webhcat-console.log jest stdout serwera po uruchomieniu
- webhcat-console-error.log jest stderr procesu serwera
Uwaga
Każda z nich webhcat.log jest przerzucana codziennie, generując pliki o nazwie webhcat.log.YYYY-MM-DD. Wybierz odpowiedni plik dla badanego zakresu czasu.
W poniższych sekcjach opisano niektóre możliwe przyczyny przekroczenia limitu czasu serwera WebHCat.
Limit czasu na poziomie serwera WebHCat
Gdy serwer WebHCat jest pod obciążeniem, z ponad 10 otwartych gniazd, ustanowienie nowych połączeń gniazd może spowodować przekroczenie limitu czasu. Aby wyświetlić listę połączeń sieciowych z serwerem WebHCat, użyj netstat polecenia w bieżącym aktywnym węźle głównym:
netstat | grep 30111
30111 to port WebHCat nasłuchuje. Liczba otwartych gniazd powinna być mniejsza niż 10.
Jeśli nie ma otwartych gniazd, poprzednie polecenie nie generuje wyniku. Aby sprawdzić, czy Templeton jest włączony i nasłuchuje na porcie 30111, użyj:
netstat -l | grep 30111
Limit czasu poziomu usługi YARN
Templeton wywołuje YARN do uruchamiania zadań, a komunikacja między Templeton i YARN może spowodować przekroczenie limitu czasu.
Na poziomie usługi YARN istnieją dwa typy limitów czasu:
Przesyłanie zadania usługi YARN może trwać wystarczająco długo, aby spowodować przekroczenie limitu czasu.
Jeśli otworzysz
/var/log/webhcat/webhcat.logplik dziennika i wyszukasz "zadanie w kolejce", może zostać wyświetlonych wiele wpisów, w których czas wykonywania jest zbyt długi (>2000 ms), a wpisy wyświetlają rosnące czasy oczekiwania.Czas dla zadań w kolejce nadal rośnie, ponieważ szybkość przesłania nowych zadań jest wyższa niż wskaźnik ukończenia starych zadań. Gdy pamięć usługi YARN jest używana w 100%,
joblauncher queuepojemność domyślna nie może już być pożyczona z kolejki domyślnej. W związku z tym nie można zaakceptować więcej nowych zadań w kolejce uruchamiania zadań. To zachowanie może spowodować, że czas oczekiwania będzie dłuższy i dłuższy, powodując błąd przekroczenia limitu czasu, po którym zwykle występuje wiele innych.Na poniższej ilustracji przedstawiono kolejkę uruchamiania zadań na poziomie 714,4% nadmiernego użycia. Jest to akceptowalne tak długo, jak nadal istnieje bezpłatna pojemność w domyślnej kolejce do zaciągania pożyczek. Jednak gdy klaster jest w pełni wykorzystywany, a pamięć usługi YARN jest w 100% pojemności, nowe zadania muszą czekać, co ostatecznie powoduje przekroczenie limitu czasu.

Istnieją dwa sposoby rozwiązania tego problemu: zmniejszenie szybkości przesłania nowych zadań lub zwiększenie szybkości zużycia starych zadań przez skalowanie klastra w górę.
Przetwarzanie usługi YARN może zająć dużo czasu, co może spowodować przekroczenie limitu czasu.
Wyświetl listę wszystkich zadań: jest to czasochłonne wywołanie. To wywołanie wylicza aplikacje z usługi Resource Manager usługi YARN, a dla każdej ukończonej aplikacji pobiera stan z serwera JobHistoryServer usługi YARN. W przypadku większej liczby zadań to wywołanie może upłynął limit czasu.
Wyświetlanie listy zadań starszych niż siedem dni: zadanie usługi HDInsight YARN JobHistoryServer jest skonfigurowane do przechowywania informacji o ukończonym zadaniu przez siedem dni (
mapreduce.jobhistory.max-age-mswartość). Próba wyliczenia przeczyszczonych zadań powoduje przekroczenie limitu czasu.
Aby zdiagnozować te problemy:
- Określanie zakresu czasu UTC do rozwiązania problemu
- Wybierz odpowiednie
webhcat.logpliki - Poszukaj komunikatów WARN i ERROR w tym czasie
Inne błędy serwera WebHCat
Kod stanu HTTP 500
W większości przypadków, gdy usługa WebHCat zwraca wartość 500, komunikat o błędzie zawiera szczegóły dotyczące błędu. W przeciwnym razie poszukaj
webhcat.logkomunikatów WARN i ERROR.Niepowodzenia zadań
Mogą wystąpić przypadki, w których interakcje z serwerem WebHCat kończą się powodzeniem, ale zadania kończą się niepowodzeniem.
Templeton zbiera dane wyjściowe konsoli zadań, jak
stderrwstatusdirpliku , co jest często przydatne do rozwiązywania problemów.stderrzawiera identyfikator aplikacji YARN rzeczywistego zapytania.
Krok 4. Przegląd stosu i wersji środowiska
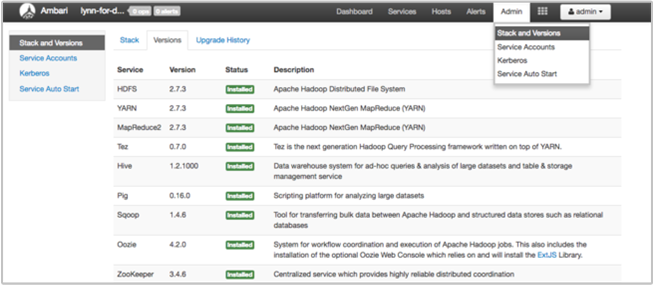
Strona Stos i wersja interfejsu użytkownika systemu Ambari zawiera informacje o konfiguracji usług klastra i historii wersji usługi. Nieprawidłowa wersja biblioteki usługi Hadoop może być przyczyną awarii klastra. W interfejsie użytkownika systemu Ambari wybierz menu Administratora , a następnie pozycję Stosy i wersje. Wybierz kartę Wersje na stronie, aby wyświetlić informacje o wersji usługi:
Krok 5. Badanie plików dziennika
Istnieje wiele typów dzienników generowanych na podstawie wielu usług i składników składających się na klaster usługi HDInsight. Pliki dziennika WebHCat zostały opisane wcześniej. Istnieje kilka innych przydatnych plików dziennika, które można zbadać, aby zawęzić problemy z klastrem, zgodnie z opisem w poniższych sekcjach.
Klastry usługi HDInsight składają się z kilku węzłów, z których większość jest zadaniem uruchamiania przesłanych zadań. Zadania są uruchamiane współbieżnie, ale pliki dziennika mogą wyświetlać wyniki tylko liniowo. Usługa HDInsight wykonuje nowe zadania, kończąc inne, które nie mogą zostać wykonane jako pierwsze. Wszystkie te działania są rejestrowane w plikach
stderri .syslogPliki dziennika akcji skryptu pokazują błędy lub nieoczekiwane zmiany konfiguracji podczas procesu tworzenia klastra.
Dzienniki kroków usługi Hadoop identyfikują uruchomione zadania usługi Hadoop w ramach kroku zawierającego błędy.
Sprawdzanie dzienników akcji skryptu
Akcje skryptu usługi HDInsight uruchamiają skrypty w klastrze ręcznie lub po określeniu. Na przykład akcje skryptu mogą służyć do instalowania dodatkowego oprogramowania w klastrze lub zmiany ustawień konfiguracji z wartości domyślnych. Sprawdzanie dzienników akcji skryptu może zapewnić wgląd w błędy, które wystąpiły podczas konfiguracji i konfiguracji klastra. Stan akcji skryptu można wyświetlić, wybierając przycisk ops w interfejsie użytkownika systemu Ambari lub korzystając z dzienników z domyślnego konta magazynu.
Dzienniki akcji skryptu \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE znajdują się w katalogu.
Wyświetlanie dzienników usługi HDInsight przy użyciu szybkich linków systemu Ambari
Interfejs użytkownika systemu Ambari usługi HDInsight zawiera wiele sekcji Szybkich linków . Aby uzyskać dostęp do linków dziennika dla określonej usługi w klastrze usługi HDInsight, otwórz interfejs użytkownika systemu Ambari dla klastra, a następnie wybierz link usługi z listy po lewej stronie. Wybierz listę rozwijaną Szybkie linki, a następnie węzeł usługi HDInsight, a następnie wybierz link dla skojarzonego dziennika.
Na przykład w przypadku dzienników systemu plików HDFS:
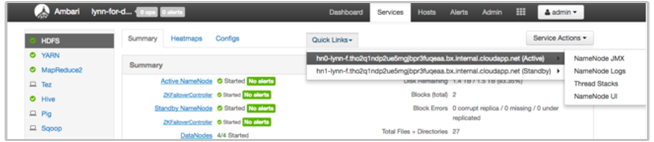
Wyświetlanie plików dziennika generowanych przez usługę Hadoop
Klaster usługi HDInsight generuje dzienniki zapisywane w tabelach platformy Azure i usłudze Azure Blob Storage. Usługa YARN tworzy własne dzienniki wykonywania. Aby uzyskać więcej informacji, zobacz Zarządzanie dziennikami klastra usługi HDInsight.
Przeglądanie zrzutów sterty
Zrzuty sterty zawierają migawkę pamięci aplikacji, w tym wartości zmiennych w tym czasie, które są przydatne do diagnozowania problemów występujących w czasie wykonywania. Aby uzyskać więcej informacji, zobacz Włączanie zrzutów sterty dla usług Apache Hadoop w usłudze HDInsight opartej na systemie Linux.
Krok 6. Sprawdzanie ustawień konfiguracji
Klastry usługi HDInsight są wstępnie skonfigurowane z ustawieniami domyślnymi dla powiązanych usług, takich jak Hadoop, Hive, HBase itd. W zależności od typu klastra, konfiguracji sprzętu, liczby węzłów, typów uruchomionych zadań oraz danych, z którymi pracujesz (i sposobu przetwarzania tych danych), może być konieczne zoptymalizowanie konfiguracji.
Aby uzyskać szczegółowe instrukcje dotyczące optymalizowania konfiguracji wydajności dla większości scenariuszy, zobacz Optymalizowanie konfiguracji klastra przy użyciu narzędzia Apache Ambari. W przypadku korzystania z platformy Spark zobacz Optymalizowanie zadań platformy Apache Spark pod kątem wydajności.
Krok 7. Odtworzenie błędu w innym klastrze
Aby ułatwić diagnozowanie źródła błędu klastra, uruchom nowy klaster z tą samą konfiguracją, a następnie ponownie prześlij kroki zadania, które zakończyły się niepowodzeniem. Przed przetworzeniem następnego sprawdź wyniki każdego kroku. Ta metoda umożliwia poprawienie i ponowne uruchomienie jednego kroku, który zakończył się niepowodzeniem. Ta metoda ma również zaletę ładowania tylko danych wejściowych raz.
- Utwórz nowy klaster testowy z taką samą konfiguracją jak klaster, który zakończył się niepowodzeniem.
- Prześlij pierwszy krok zadania do klastra testowego.
- Po zakończeniu przetwarzania krok sprawdź błędy w plikach dziennika kroku. Połącz się z węzłem głównym klastra testowego i wyświetl tam pliki dziennika. Pliki dziennika kroków są wyświetlane tylko po uruchomieniu kroku przez jakiś czas, kończy się lub kończy się niepowodzeniem.
- Jeśli pierwszy krok zakończył się pomyślnie, uruchom następny krok. Jeśli wystąpiły błędy, zbadaj błąd w plikach dziennika. Jeśli wystąpił błąd w kodzie, wprowadź poprawkę i ponownie uruchom krok.
- Kontynuuj, aż wszystkie kroki będą uruchamiane bez błędu.
- Po zakończeniu debugowania klastra testowego usuń go.
Następne kroki
- Zarządzanie klastrami HDInsight przy użyciu internetowego interfejsu użytkownika systemu Apache Ambari
- Analizowanie dzienników usługi HDInsight
- Uzyskiwanie dostępu do logowania aplikacji Apache Hadoop YARN w usłudze HDInsight opartej na systemie Linux
- Włączanie zrzutów sterty dla usług Apache Hadoop w usłudze HDInsight opartej na systemie Linux
- Znane problemy z klastrem Apache Spark w usłudze HDInsight