Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym samouczku dowiesz się, jak utworzyć aplikację uczenia maszynowego platformy Apache Spark dla usługi Azure HDInsight za pomocą środowiska Jupyter Notebook.
Biblioteka MLlib to elastyczna biblioteka uczenia maszynowego platformy Spark składająca się z typowych algorytmów uczenia i narzędzi. (Klasyfikacja, regresja, klastrowanie, filtrowanie oparte na współpracy i redukcja wymiarowości. Ponadto, podstawowe mechanizmy optymalizacji).
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Tworzenie aplikacji uczenia maszynowego platformy Apache Spark
Wymagania wstępne
Klaster Apache Spark w usłudze HDInsight. Zobacz Tworzenie klastra Apache Spark.
Znajomość zagadnień dotyczących używania notesów Jupyter za pomocą platformy Spark w usłudze HDInsight. Aby uzyskać więcej informacji, zobacz Ładowanie danych i uruchamianie zapytań za pomocą platformy Apache Spark w usłudze HDInsight.
Opis zestawu danych
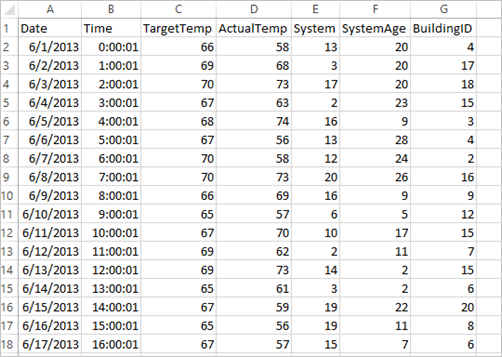
Aplikacja domyślnie używa przykładowych HVAC.csv danych, które są dostępne we wszystkich klastrach. Plik znajduje się w lokalizacji \HdiSamples\HdiSamples\SensorSampleData\hvac. Dane dotyczą temperatury docelowej i temperatury rzeczywistej niektórych budynków, wyposażonych w instalacje grzewczo-wentylacyjne (HVAC). Kolumna System zawiera identyfikatory systemów, a kolumna SystemAge — liczbę lat użytkowania instalacji grzewczo-wentylacyjnej w danym budynku. Można przewidzieć, czy budynek będzie cieplejszy, czy chłodniejszy na podstawie temperatury docelowej, podanego identyfikatora systemu i wieku systemu.
Tworzenie aplikacji uczenia maszynowego platformy Spark przy użyciu biblioteki MLLib platformy Spark
Ta aplikacja używa potoku Spark ML do klasyfikacji dokumentów. Pipeline'y ML zapewniają jednolity zestaw interfejsów API wysokiego poziomu opartych na DataFrame'ach. Ramki danych ułatwiają użytkownikom tworzenie i dostrajanie praktycznych potoków uczenia maszynowego. W procesie dokument jest dzielony na wyrazy, które są przekształcane w wektor cech liczbowych, a na końcu tworzony jest model predykcyjny przy użyciu wektorów cech i etykiet. Wykonaj następujące kroki, aby utworzyć aplikację.
Utwórz notatnik Jupyter przy użyciu jądra PySpark. Aby uzyskać instrukcje, zobacz Utwórz plik notebooka Jupyter.
Zaimportuj typy wymagane w tym scenariuszu. Wklej następujący fragment kodu do pustej komórki, a następnie naciśnij klawisze SHIFT + ENTER.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayZaładuj dane (hvac.csv) i je przeanalizuj, a następnie je wykorzystaj do nauczenia modelu.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()Fragment kodu zawiera definicję funkcji, która porównuje temperaturę rzeczywistą z temperaturą docelową. Jeśli temperatura rzeczywista jest większa, przyjmuje się, że w budynku jest ciepło, co odpowiada wartości 1.0. W przeciwnym razie w budynku jest zimno, co odpowiada wartości 0.0.
Skonfiguruj potok uczenia maszynowego platformy Spark, który składa się z trzech etapów:
tokenizer,hashingTFilr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])Aby uzyskać więcej informacji o potoku (pipeline) i jego działaniu, zajrzyj do Apache Spark machine learning pipeline (Potok uczenia maszynowego platformy Apache Spark).
Dostosuj pipeline do dokumentu szkoleniowego.
model = pipeline.fit(training)Zweryfikuj dokument szkoleniowy w celu sprawdzenia postępu w opracowywaniu aplikacji.
training.show()Dane wyjściowe są podobne do następujących:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+Porównaj dane wyjściowe z nieprzetworzonymi danymi w pliku CSV. Na przykład pierwszy wiersz pliku CSV zawiera te dane:

Zwróć uwagę, że temperatura rzeczywista jest mniejsza niż temperatura docelowa, co świadczy o tym, że w budynku jest zimno. Wartość etykiety w pierwszym wierszu wynosi 0,0, co oznacza, że budynek nie jest gorący.
Przygotuj zestaw danych do uruchomienia trenowanego modelu. W tym celu należy przekazać identyfikator systemu i wiek systemu (oznaczony jako SystemInfo w wynikach trenowania). Model przewiduje, czy budynek o tym identyfikatorze systemu i wieku systemu będzie cieplejszy (oznaczony przez 1,0) lub chłodniejszy (oznaczony przez 0,0).
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Na koniec wygenerujemy prognozy na podstawie danych testowych.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)Dane wyjściowe są podobne do następujących:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Obserwuj pierwszy wiersz w prognozie. W przypadku systemu HVAC o identyfikatorze 20 i wieku systemu wynoszącym 25 lat, w budynku panuje wysoka temperatura (prediction=1.0). Pierwsza wartość elementu DenseVector (0.49999) odpowiada prognozie 0.0, a druga wartość (0.5001) odpowiada prognozie 1.0. Chociaż w danych wyjściowych druga wartość jest tylko nieznacznie większa, model generuje wynik prediction=1.0.
Wyłącz laptop, aby zwolnić zasoby. W tym celu w menu File (Plik) w notesie wybierz pozycję Close and Halt (Zamknij i zatrzymaj). Ta akcja powoduje wyłączenie i zamknięcie notatnika.
Uczenie maszynowe platformy Spark z użyciem biblioteki Anaconda scikit-learn
Klastry Apache Spark w usłudze HDInsight obejmują biblioteki Anaconda. Zawierają także bibliotekę scikit-learn do uczenia maszynowego. Biblioteka zawiera również różne zestawy danych, których można użyć do tworzenia przykładowych aplikacji bezpośrednio z poziomu notesu Jupyter Notebook. Przykłady użycia biblioteki scikit-learn można znaleźć na stroniehttps://scikit-learn.org/stable/auto_examples/index.html.
Czyszczenie zasobów
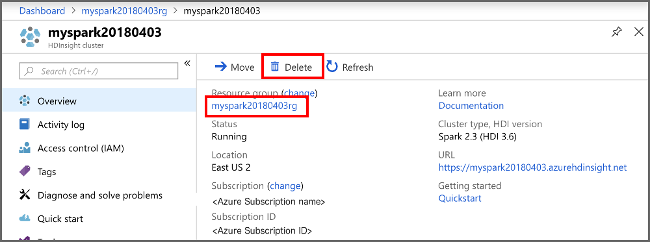
Jeśli nie zamierzasz nadal korzystać z tej aplikacji, usuń utworzony klaster, wykonując następujące czynności:
Zaloguj się w witrynie Azure Portal.
W polu Wyszukaj w górnej części wpisz HDInsight.
Wybierz Klastry HDInsight w sekcji Usługi.
Na wyświetlonej liście klastrów usługi HDInsight wybierz pozycję ... obok klastra utworzonego na potrzeby tego samouczka.
Wybierz Usuń. Wybierz opcję Tak.
Następne kroki
W tym samouczku nauczono się, jak używać notesu Jupyter Notebook do budowania aplikacji uczenia maszynowego Apache Spark w usłudze Azure HDInsight. Przejdź do następnego samouczka, aby dowiedzieć się, jak używać środowiska IntelliJ IDEA na potrzeby zadań Spark.