Zbieranie danych produkcyjnych z modeli wdrożonych na potrzeby wnioskowania w czasie rzeczywistym
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Z tego artykułu dowiesz się, jak za pomocą modułu zbierającego dane usługi Azure Machine Learning zbierać dane wnioskowania produkcyjnego z modelu wdrożonego w zarządzanym punkcie końcowym online usługi Azure Machine Learning lub punkcie końcowym online rozwiązania Kubernetes.
Zbieranie danych dla nowych lub istniejących wdrożeń punktów końcowych online można włączyć. Dane wnioskowania modułu zbierającego dane modułu zbierającego dane modułu zbierającego dane usługi Azure Machine Learning w usłudze Azure Blob Storage. Dane zbierane za pomocą zestawu SDK języka Python są automatycznie rejestrowane jako zasób danych w obszarze roboczym usługi Azure Machine Learning. Ten zasób danych może służyć do monitorowania modelu.
Jeśli interesuje Cię zbieranie danych wnioskowania produkcyjnego dla modelu MLflow wdrożonego w punkcie końcowym w czasie rzeczywistym, zobacz Zbieranie danych dla modeli MLflow.
Wymagania wstępne
Przed wykonaniem kroków opisanych w tym artykule upewnij się, że masz następujące wymagania wstępne:
Interfejs wiersza polecenia platformy
mlAzure i rozszerzenie interfejsu wiersza polecenia platformy Azure. Aby uzyskać więcej informacji, zobacz Instalowanie, konfigurowanie i używanie interfejsu wiersza polecenia (wersja 2).Ważne
W przykładach interfejsu wiersza polecenia w tym artykule założono, że używasz powłoki Bash (lub zgodnej). Na przykład z systemu Linux lub Podsystem Windows dla systemu Linux.
Obszar roboczy usługi Azure Machine Learning. Jeśli go nie masz, wykonaj kroki opisane w temacie Instalowanie, konfigurowanie i używanie interfejsu wiersza polecenia (wersja 2), aby go utworzyć.
- Kontrola dostępu na podstawie ról platformy Azure (Azure RBAC): jest używana do udzielania dostępu do operacji w usłudze Azure Machine Learning. Aby wykonać kroki opisane w tym artykule, konto użytkownika musi mieć przypisaną rolę właściciela lub współautora dla obszaru roboczego usługi Azure Machine Learning lub rolę niestandardową zezwalającą na
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*korzystanie z usługi . Aby uzyskać więcej informacji, zobacz Zarządzanie dostępem do obszaru roboczego usługi Azure Machine Learning.
Masz zarejestrowany model, którego można użyć do wdrożenia. Jeśli nie masz zarejestrowanego modelu, zobacz Rejestrowanie modelu jako zasobu w usłudze Machine Learning.
Tworzenie punktu końcowego online usługi Azure Machine Learning. Jeśli nie masz istniejącego punktu końcowego online, zobacz Wdrażanie i ocenianie modelu uczenia maszynowego przy użyciu punktu końcowego online.
Wykonywanie rejestrowania niestandardowego na potrzeby monitorowania modelu
Zbieranie danych za pomocą rejestrowania niestandardowego umożliwia rejestrowanie ramek danych pandas bezpośrednio ze skryptu oceniania przed, podczas i po wszelkich przekształceniach danych. W przypadku rejestrowania niestandardowego dane tabelaryczne są rejestrowane w czasie rzeczywistym w usłudze Blob Storage obszaru roboczego lub niestandardowym kontenerze magazynu obiektów blob. Monitory modelu mogą wykorzystywać dane z magazynu.
Aktualizowanie skryptu oceniania przy użyciu niestandardowego kodu rejestrowania
Aby rozpocząć, dodaj niestandardowy kod rejestrowania do skryptu oceniania (score.py). W przypadku rejestrowania niestandardowego azureml-ai-monitoring potrzebny jest pakiet. Aby uzyskać więcej informacji na temat tego pakietu, zobacz kompleksową stronę PyPI dla zestawu SDK modułu zbierającego dane.
Zaimportuj
azureml-ai-monitoringpakiet, dodając następujący wiersz na początku skryptu oceniania:from azureml.ai.monitoring import CollectorZadeklaruj zmienne zbierania danych (maksymalnie pięć z nich) w funkcji
init():Uwaga
Jeśli używasz nazw
model_inputsimodel_outputsobiektówCollector, system monitorowania modelu automatycznie rozpoznaje automatycznie zarejestrowane zasoby danych w celu zapewnienia bardziej bezproblemowego środowiska monitorowania modelu.global inputs_collector, outputs_collector inputs_collector = Collector(name='model_inputs') outputs_collector = Collector(name='model_outputs')Domyślnie usługa Azure Machine Learning zgłasza wyjątek, jeśli podczas zbierania danych wystąpi błąd. Opcjonalnie możesz użyć parametru
on_error, aby określić funkcję do uruchomienia, jeśli wystąpi błąd rejestrowania. Na przykład przy użyciu parametruon_errorw poniższym kodzie usługa Azure Machine Learning rejestruje błąd zamiast zgłaszać wyjątek:inputs_collector = Collector(name='model_inputs', on_error=lambda e: logging.info("ex:{}".format(e)))run()W funkcji użyjcollect()funkcji , aby rejestrować ramki danych przed i po ocenianiu. Elementcontextjest zwracany z pierwszego wywołania docollect()elementu i zawiera informacje, aby skorelować dane wejściowe modelu i dane wyjściowe modelu później.context = inputs_collector.collect(data) result = model.predict(data) outputs_collector.collect(result, context)Uwaga
Obecnie interfejs
collect()API rejestruje tylko ramki danych biblioteki pandas. Jeśli dane nie są w ramce danych przekazywanej docollect()usługi , nie zostaną zarejestrowane w magazynie i zostanie zgłoszony błąd.
Poniższy kod jest przykładem pełnego skryptu oceniania (score.py), który używa niestandardowego zestawu SDK języka Python do rejestrowania.
import pandas as pd
import json
from azureml.ai.monitoring import Collector
def init():
global inputs_collector, outputs_collector, inputs_outputs_collector
# instantiate collectors with appropriate names, make sure align with deployment spec
inputs_collector = Collector(name='model_inputs')
outputs_collector = Collector(name='model_outputs')
def run(data):
# json data: { "data" : { "col1": [1,2,3], "col2": [2,3,4] } }
pdf_data = preprocess(json.loads(data))
# tabular data: { "col1": [1,2,3], "col2": [2,3,4] }
input_df = pd.DataFrame(pdf_data)
# collect inputs data, store correlation_context
context = inputs_collector.collect(input_df)
# perform scoring with pandas Dataframe, return value is also pandas Dataframe
output_df = predict(input_df)
# collect outputs data, pass in correlation_context so inputs and outputs data can be correlated later
outputs_collector.collect(output_df, context)
return output_df.to_dict()
def preprocess(json_data):
# preprocess the payload to ensure it can be converted to pandas DataFrame
return json_data["data"]
def predict(input_df):
# process input and return with outputs
...
return output_df
Aktualizowanie skryptu oceniania w celu rejestrowania niestandardowych unikatowych identyfikatorów
Oprócz rejestrowania ramek danych biblioteki pandas bezpośrednio w skryfcie oceniania można rejestrować dane przy użyciu unikatowych identyfikatorów. Te identyfikatory mogą pochodzić z aplikacji, systemu zewnętrznego lub można je wygenerować. Jeśli nie podasz identyfikatora niestandardowego, zgodnie z opisem w tej sekcji, moduł zbierający dane automatycznie wygeneruje unikatowy identyfikator correlationid , aby ułatwić korelowanie danych wejściowych i wyjściowych modelu później. Jeśli podasz identyfikator niestandardowy, correlationid pole w zarejestrowanych danych będzie zawierać wartość podanego identyfikatora niestandardowego.
Najpierw wykonaj kroki opisane w poprzedniej sekcji, a następnie zaimportuj
azureml.ai.monitoring.contextpakiet, dodając następujący wiersz do skryptu oceniania:from azureml.ai.monitoring.context import BasicCorrelationContextW skryfcie oceniania utwórz wystąpienie
BasicCorrelationContextobiektu i przekażidobiekt, który chcesz zarejestrować dla tego wiersza. Zalecamy, aby był toidunikatowy identyfikator systemu, dzięki czemu można jednoznacznie zidentyfikować każdy zarejestrowany wiersz z usługi Blob Storage. Przekaż ten obiekt docollect()wywołania interfejsu API jako parametru:# create a context with a custom unique id artificial_context = BasicCorrelationContext(id='test') # collect inputs data, store correlation_context context = inputs_collector.collect(input_df, artificial_context)Upewnij się, że kontekst jest przekazywany do
outputs_collectorpliku , aby dane wejściowe i wyjściowe modelu miały ten sam unikatowy identyfikator zarejestrowany za ich pomocą i można je łatwo skorelować później:# collect outputs data, pass in context so inputs and outputs data can be correlated later outputs_collector.collect(output_df, context)
Poniższy kod to przykład pełnego skryptu oceniania (score.py), który rejestruje niestandardowe unikatowe identyfikatory.
import pandas as pd
import json
from azureml.ai.monitoring import Collector
from azureml.ai.monitoring.context import BasicCorrelationContext
def init():
global inputs_collector, outputs_collector, inputs_outputs_collector
# instantiate collectors with appropriate names, make sure align with deployment spec
inputs_collector = Collector(name='model_inputs')
outputs_collector = Collector(name='model_outputs')
def run(data):
# json data: { "data" : { "col1": [1,2,3], "col2": [2,3,4] } }
pdf_data = preprocess(json.loads(data))
# tabular data: { "col1": [1,2,3], "col2": [2,3,4] }
input_df = pd.DataFrame(pdf_data)
# create a context with a custom unique id
artificial_context = BasicCorrelationContext(id='test')
# collect inputs data, store correlation_context
context = inputs_collector.collect(input_df, artificial_context)
# perform scoring with pandas Dataframe, return value is also pandas Dataframe
output_df = predict(input_df)
# collect outputs data, pass in context so inputs and outputs data can be correlated later
outputs_collector.collect(output_df, context)
return output_df.to_dict()
def preprocess(json_data):
# preprocess the payload to ensure it can be converted to pandas DataFrame
return json_data["data"]
def predict(input_df):
# process input and return with outputs
...
return output_df
Zbieranie danych na potrzeby monitorowania wydajności modelu
Jeśli chcesz użyć zebranych danych na potrzeby monitorowania wydajności modelu, ważne jest, aby każdy zarejestrowany wiersz miał unikatowy identyfikator correlationid , który może służyć do korelowania danych z danymi prawdy podstawowej, gdy takie dane staną się dostępne. Moduł zbierający dane automatycznie wygeneruje unikatowy dla correlationid każdego zarejestrowanego wiersza i uwzględni ten automatycznie wygenerowany identyfikator w correlationid polu w obiekcie JSON. Aby uzyskać więcej informacji na temat schematu JSON, zobacz przechowywanie zebranych danych w magazynie obiektów blob.
Jeśli chcesz użyć własnego unikatowego identyfikatora do rejestrowania danych produkcyjnych, zalecamy zarejestrowanie tego identyfikatora jako oddzielnej kolumny w ramce danych pandas, ponieważ moduł zbierający dane wsaduje żądania znajdujące się blisko siebie. Rejestrując correlationid jako oddzielną kolumnę, będzie ona łatwo dostępna pod kątem integracji z danymi podstawy prawdy.
Aktualizowanie zależności
Przed utworzeniem wdrożenia za pomocą zaktualizowanego skryptu oceniania należy utworzyć środowisko przy użyciu obrazu mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04 podstawowego i odpowiednich zależności conda. Następnie możesz skompilować środowisko przy użyciu specyfikacji w następującym języku YAML.
channels:
- conda-forge
dependencies:
- python=3.8
- pip=22.3.1
- pip:
- azureml-defaults==1.38.0
- azureml-ai-monitoring~=0.1.0b1
name: model-env
Aktualizowanie wdrożenia YAML
Następnie utworzysz wdrożenie YAML. Aby utworzyć wdrożenie YAML, dołącz data_collector atrybut i włącz zbieranie danych dla Collector obiektów model_inputs oraz model_outputs, które utworzono wcześniej za pomocą niestandardowego zestawu SDK języka Python rejestrowania:
data_collector:
collections:
model_inputs:
enabled: 'True'
model_outputs:
enabled: 'True'
Poniższy kod jest przykładem kompleksowego wdrożenia YAML dla zarządzanego wdrożenia punktu końcowego online. Wdrożenie YAML należy zaktualizować zgodnie ze swoim scenariuszem. Aby uzyskać więcej przykładów na temat formatowania wdrożenia YAML na potrzeby rejestrowania danych wnioskowania, zobacz Przykłady modułów zbierających dane modelu platformy Azure.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my_endpoint
model: azureml:iris_mlflow_model@latest
environment:
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: model/conda.yaml
code_configuration:
code: scripts
scoring_script: score.py
instance_type: Standard_F2s_v2
instance_count: 1
data_collector:
collections:
model_inputs:
enabled: 'True'
model_outputs:
enabled: 'True'
Opcjonalnie możesz dostosować następujące dodatkowe parametry dla elementu data_collector:
data_collector.rolling_rate: szybkość partycjonowania danych w magazynie. Wybierz wartości:Minute, ,HourDay,MonthlubYear.data_collector.sampling_rate: Wartość procentowa, reprezentowana jako liczba dziesiętna, danych do zebrania. Na przykład wartość1.0reprezentuje zbieranie 100% danych.data_collector.collections.<collection_name>.data.name: nazwa zasobu danych do zarejestrowania przy użyciu zebranych danych.data_collector.collections.<collection_name>.data.path: pełna ścieżka magazynu danych usługi Azure Machine Learning, w której zebrane dane powinny być zarejestrowane jako zasób danych.data_collector.collections.<collection_name>.data.version: wersja zasobu danych do zarejestrowania przy użyciu zebranych danych w magazynie obiektów blob.
Zbieranie danych do niestandardowego kontenera magazynu obiektów blob
Moduł zbierający dane służy do zbierania danych wnioskowania produkcyjnego do niestandardowego kontenera magazynu obiektów blob, wykonując następujące kroki:
Połącz kontener magazynu z magazynem danych usługi Azure Machine Learning. Aby uzyskać więcej informacji na temat łączenia kontenera magazynu z magazynem danych usługi Azure Machine Learning, zobacz tworzenie magazynów danych.
Sprawdź, czy punkt końcowy usługi Azure Machine Learning ma niezbędne uprawnienia do zapisu w miejscu docelowym magazynu danych.
Moduł zbierający dane obsługuje tożsamości zarządzane przypisane przez system (SAMI) i tożsamości zarządzane przypisane przez użytkownika (UAMI). Dodaj tożsamość do punktu końcowego.
Storage Blob Data ContributorPrzypisz rolę do tej tożsamości za pomocą kontenera usługi Blob Storage, który ma być używany jako miejsce docelowe danych. Aby dowiedzieć się, jak używać tożsamości zarządzanych na platformie Azure, zobacz Przypisywanie ról platformy Azure do tożsamości zarządzanej.Zaktualizuj wdrożenie YAML, aby uwzględnić
datawłaściwość w każdej kolekcji.- Wymagany parametr
data.nameokreśla nazwę zasobu danych, który ma zostać zarejestrowany przy użyciu zebranych danych. - Wymagany parametr
data.pathokreśla w pełni sformułowaną ścieżkę magazynu danych usługi Azure Machine Learning, która jest połączona z kontenerem usługi Azure Blob Storage. - Opcjonalny parametr
data.version, określa wersję zasobu danych (wartość domyślna to 1).
Poniższa konfiguracja YAML przedstawia przykład dołączania
datawłaściwości do każdej kolekcji.data_collector: collections: model_inputs: enabled: 'True' data: name: my_model_inputs_data_asset path: azureml://datastores/workspaceblobstore/paths/modelDataCollector/my_endpoint/blue/model_inputs version: 1 model_outputs: enabled: 'True' data: name: my_model_outputs_data_asset path: azureml://datastores/workspaceblobstore/paths/modelDataCollector/my_endpoint/blue/model_outputs version: 1Uwaga
Możesz również użyć parametru
data.path, aby wskazać magazyny danych w różnych subskrypcjach platformy Azure, podając ścieżkę zgodną z formatem:azureml://subscriptions/<sub_id>/resourcegroups/<rg_name>/workspaces/<ws_name>/datastores/<datastore_name>/paths/<path>- Wymagany parametr
Tworzenie wdrożenia przy użyciu zbierania danych
Wdróż model z włączonym rejestrowaniem niestandardowym:
$ az ml online-deployment create -f deployment.YAML
Aby uzyskać więcej informacji na temat formatowania wdrożenia YAML na potrzeby zbierania danych przy użyciu punktów końcowych online platformy Kubernetes, zobacz schemat YAML z obsługą interfejsu wiersza polecenia (wersja 2) platformy Kubernetes z obsługą usługi Kubernetes.
Aby uzyskać więcej informacji na temat formatowania wdrożenia YAML na potrzeby zbierania danych za pomocą zarządzanych punktów końcowych online, zobacz Schemat YAML zarządzanego wdrożenia online interfejsu wiersza polecenia (wersja 2).
Rejestrowanie ładunku
Oprócz rejestrowania niestandardowego przy użyciu dostarczonego zestawu SDK języka Python można zbierać dane ładunku HTTP żądań i odpowiedzi bezpośrednio bez konieczności rozszerzania skryptu oceniania (score.py).
Aby włączyć rejestrowanie ładunków, w wdrożeniu YAML użyj nazw
requestiresponse:$schema: http://azureml/sdk-2-0/OnlineDeployment.json endpoint_name: my_endpoint name: blue model: azureml:my-model-m1:1 environment: azureml:env-m1:1 data_collector: collections: request: enabled: 'True' response: enabled: 'True'Wdróż model z włączonym rejestrowaniem ładunku:
$ az ml online-deployment create -f deployment.YAML
W przypadku rejestrowania ładunków zebrane dane nie są gwarantowane w formacie tabelarycznym. W związku z tym, jeśli chcesz użyć zebranych danych ładunku z monitorowaniem modelu, musisz podać składnik przetwarzania wstępnego w celu utworzenia tabelarycznego danych. Jeśli interesuje Cię bezproblemowe środowisko monitorowania modelu, zalecamy użycie niestandardowego zestawu SDK języka Python do rejestrowania.
W miarę użycia wdrożenia zebrane dane przepływa do magazynu obiektów blob obszaru roboczego. Poniższy kod JSON jest przykładem zebranego żądania HTTP:
{"specversion":"1.0",
"id":"19790b87-a63c-4295-9a67-febb2d8fbce0",
"source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/mire2etesting/providers/Microsoft.MachineLearningServices/workspaces/mirmasterenvws/onlineEndpoints/localdev-endpoint/deployments/localdev",
"type":"azureml.inference.request",
"datacontenttype":"application/json",
"time":"2022-05-25T08:59:48Z",
"data":{"data": [ [1,2,3,4,5,6,7,8,9,10], [10,9,8,7,6,5,4,3,2,1]]},
"path":"/score",
"method":"POST",
"contentrange":"bytes 0-59/*",
"correlationid":"aaaa0000-bb11-2222-33cc-444444dddddd","xrequestid":"aaaa0000-bb11-2222-33cc-444444dddddd"}
Poniższy kod JSON to kolejny przykład zebranej odpowiedzi HTTP:
{"specversion":"1.0",
"id":"bbd80e51-8855-455f-a719-970023f41e7d",
"source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/mire2etesting/providers/Microsoft.MachineLearningServices/workspaces/mirmasterenvws/onlineEndpoints/localdev-endpoint/deployments/localdev",
"type":"azureml.inference.response",
"datacontenttype":"application/json",
"time":"2022-05-25T08:59:48Z",
"data":[11055.977245525679, 4503.079536107787],
"contentrange":"bytes 0-38/39",
"correlationid":"aaaa0000-bb11-2222-33cc-444444dddddd","xrequestid":"aaaa0000-bb11-2222-33cc-444444dddddd"}
Przechowywanie zebranych danych w magazynie obiektów blob
Zbieranie danych umożliwia rejestrowanie danych wnioskowania produkcyjnego do wybranego miejsca docelowego usługi Blob Storage. Ustawienia miejsca docelowego danych można konfigurować na collection_name poziomie.
Dane wyjściowe/format usługi Blob Storage:
Domyślnie zebrane dane są przechowywane w następującej ścieżce w usłudze Blob Storage obszaru roboczego:
azureml://datastores/workspaceblobstore/paths/modelDataCollector.Ostateczna ścieżka w obiekcie blob zostanie dołączona za pomocą
{endpoint_name}/{deployment_name}/{collection_name}/{yyyy}/{MM}/{dd}/{HH}/{instance_id}.jsonlpolecenia .Każdy wiersz w pliku jest obiektem JSON reprezentującym zarejestrowane jedno żądanie/odpowiedź wnioskowania.
Uwaga
collection_name odwołuje się do nazwy zbierania danych (np. model_inputs lub model_outputs).
instance_id jest unikatowym identyfikatorem identyfikującym grupowanie danych, które zostały zarejestrowane.
Zebrane dane są zgodne z następującym schematem JSON. Zebrane dane są dostępne z data klucza i udostępniane są dodatkowe metadane.
{"specversion":"1.0",
"id":"725aa8af-0834-415c-aaf5-c76d0c08f694",
"source":"/subscriptions/bbbb1b1b-cc2c-dd3d-ee4e-ffffff5f5f5f/resourceGroups/mire2etesting/providers/Microsoft.MachineLearningServices/workspaces/mirmasterws/onlineEndpoints/localdev-endpoint/deployments/localdev",
"type":"azureml.inference.inputs",
"datacontenttype":"application/json",
"time":"2022-12-01T08:51:30Z",
"data":[{"label":"DRUG","pattern":"aspirin"},{"label":"DRUG","pattern":"trazodone"},{"label":"DRUG","pattern":"citalopram"}],
"correlationid":"bbbb1111-cc22-3333-44dd-555555eeeeee","xrequestid":"bbbb1111-cc22-3333-44dd-555555eeeeee",
"modelversion":"default",
"collectdatatype":"pandas.core.frame.DataFrame",
"agent":"monitoring-sdk/0.1.2",
"contentrange":"bytes 0-116/117"}
Napiwek
Podziały wierszy są wyświetlane tylko dla czytelności. W zebranych plikach jsonl nie będzie żadnych podziałów wierszy.
Przechowywanie dużych ładunków
Jeśli ładunek danych jest większy niż 4 MB, w pliku znajduje się zdarzenie znajdujące się w {instance_id}.jsonl {endpoint_name}/{deployment_name}/request/.../{instance_id}.jsonl ścieżce wskazującej nieprzetworzonej ścieżki pliku, która powinna mieć następującą ścieżkę: blob_url/{blob_container}/{blob_path}/{endpoint_name}/{deployment_name}/{rolled_time}/{instance_id}.jsonl. Zebrane dane będą istnieć na tej ścieżce.
Przechowywanie danych binarnych
W przypadku zebranych danych binarnych bezpośrednio wyświetlamy nieprzetworzony plik z instance_id nazwą pliku. Dane binarne są umieszczane w tym samym folderze co ścieżka grupy źródłowej żądania na rolling_ratepodstawie . Poniższy przykład odzwierciedla ścieżkę w polu danych. Format to json, a podziały wierszy są wyświetlane tylko pod kątem czytelności:
{
"specversion":"1.0",
"id":"ba993308-f630-4fe2-833f-481b2e4d169a",
"source":"/subscriptions//resourceGroups//providers/Microsoft.MachineLearningServices/workspaces/ws/onlineEndpoints/ep/deployments/dp",
"type":"azureml.inference.request",
"datacontenttype":"text/plain",
"time":"2022-02-28T08:41:07Z",
"data":"https://masterws0373607518.blob.core.windows.net/modeldata/mdc/%5Byear%5D%5Bmonth%5D%5Bday%5D-%5Bhour%5D_%5Bminute%5D/ba993308-f630-4fe2-833f-481b2e4d169a",
"path":"/score?size=1",
"method":"POST",
"contentrange":"bytes 0-80770/80771",
"datainblob":"true"
}
Przetwarzanie wsadowe modułu zbierającego dane
Jeśli żądania są wysyłane w krótkim przedziale czasu od siebie, moduł zbierający dane dzieli je razem na ten sam obiekt JSON. Jeśli na przykład uruchomisz skrypt w celu wysłania przykładowych danych do punktu końcowego, a wdrożenie ma włączone zbieranie danych, niektóre żądania mogą być podzielone na partie, w zależności od interwału czasu między nimi. Jeśli używasz zbierania danych z monitorowaniem modelu usługi Azure Machine Learning, usługa monitorowania modelu obsługuje każde żądanie niezależnie. Jeśli jednak oczekujesz, że każdy zarejestrowany wiersz danych będzie miał własny unikatowy identyfikator correlationid, możesz dołączyć correlationid go jako kolumnę do ramki danych biblioteki pandas, która jest rejestrowana za pomocą modułu zbierającego dane. Aby uzyskać więcej informacji na temat sposobu dołączania unikatowego correlationid elementu jako kolumny w ramce danych biblioteki pandas, zobacz Zbieranie danych na potrzeby monitorowania wydajności modelu.
Oto przykład dwóch zarejestrowanych żądań, które są połączone wsadowe:
{"specversion":"1.0",
"id":"720b8867-54a2-4876-80eb-1fd6a8975770",
"source":"/subscriptions/cccc2c2c-dd3d-ee4e-ff5f-aaaaaa6a6a6a/resourceGroups/rg-bozhlinmomoignite/providers/Microsoft.MachineLearningServices/workspaces/momo-demo-ws/onlineEndpoints/credit-default-mdc-testing-4/deployments/main2",
"type":"azureml.inference.model_inputs",
"datacontenttype":"application/json",
"time":"2024-03-05T18:16:25Z",
"data":[{"LIMIT_BAL":502970,"AGE":54,"BILL_AMT1":308068,"BILL_AMT2":381402,"BILL_AMT3":442625,"BILL_AMT4":320399,"BILL_AMT5":322616,"BILL_AMT6":397534,"PAY_AMT1":17987,"PAY_AMT2":78764,"PAY_AMT3":26067,"PAY_AMT4":24102,"PAY_AMT5":-1155,"PAY_AMT6":2154,"SEX":2,"EDUCATION":2,"MARRIAGE":2,"PAY_0":0,"PAY_2":0,"PAY_3":0,"PAY_4":0,"PAY_5":0,"PAY_6":0},{"LIMIT_BAL":293458,"AGE":35,"BILL_AMT1":74131,"BILL_AMT2":-71014,"BILL_AMT3":59284,"BILL_AMT4":98926,"BILL_AMT5":110,"BILL_AMT6":1033,"PAY_AMT1":-3926,"PAY_AMT2":-12729,"PAY_AMT3":17405,"PAY_AMT4":25110,"PAY_AMT5":7051,"PAY_AMT6":1623,"SEX":1,"EDUCATION":3,"MARRIAGE":2,"PAY_0":-2,"PAY_2":-2,"PAY_3":-2,"PAY_4":-2,"PAY_5":-1,"PAY_6":-1}],
"contentrange":"bytes 0-6794/6795",
"correlationid":"test",
"xrequestid":"test",
"modelversion":"default",
"collectdatatype":"pandas.core.frame.DataFrame",
"agent":"azureml-ai-monitoring/0.1.0b4"}
Wyświetlanie danych w interfejsie użytkownika programu Studio
Aby wyświetlić zebrane dane w usłudze Blob Storage z poziomu interfejsu użytkownika programu Studio:
Przejdź do karty Dane w obszarze roboczym usługi Azure Machine Learning:
Przejdź do magazynów danych i wybierz swój obszar roboczyBlobstore (ustawienie domyślne)::
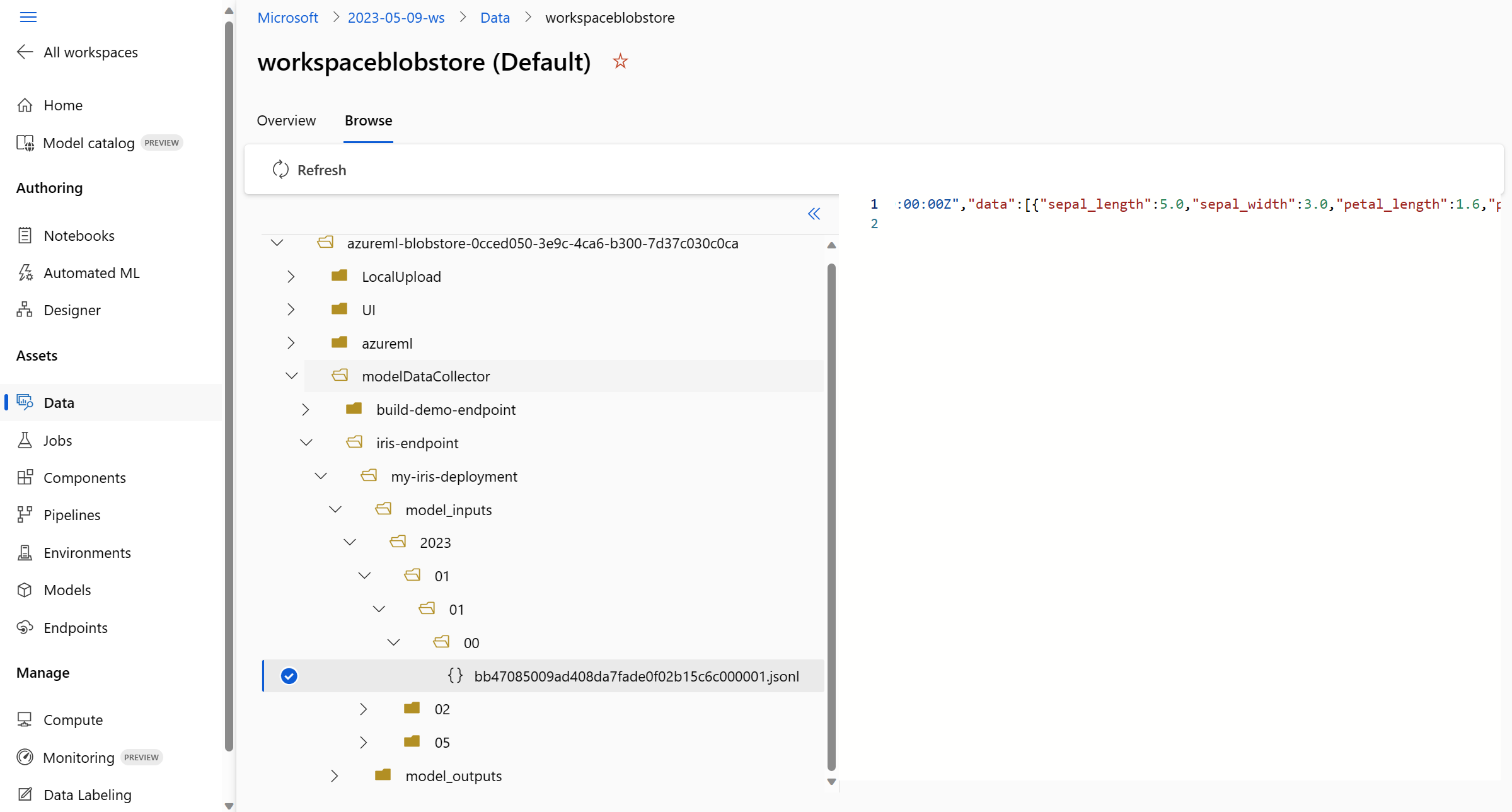
Użyj menu Przeglądaj, aby wyświetlić zebrane dane produkcyjne:



Zbieranie danych dla modeli MLflow
Jeśli wdrażasz model MLflow w punkcie końcowym online usługi Azure Machine Learning, możesz włączyć zbieranie danych wnioskowania produkcyjnego za pomocą pojedynczego przełącznika w interfejsie użytkownika programu Studio. Jeśli zbieranie danych jest włączone, usługa Azure Machine Learning automatycznie instrumentuje skrypt oceniania za pomocą niestandardowego kodu rejestrowania, aby upewnić się, że dane produkcyjne są rejestrowane w usłudze Blob Storage obszaru roboczego. Monitory modelu mogą następnie używać danych do monitorowania wydajności modelu MLflow w środowisku produkcyjnym.
Podczas konfigurowania wdrożenia modelu można włączyć zbieranie danych produkcyjnych. Na karcie Wdrożenie wybierz pozycję Włączone dla zbierania danych.
Po włączeniu zbierania danych dane produkcyjne będą rejestrowane w obszarze roboczym usługi Blob Storage usługi Azure Machine Learning, a dwa zasoby danych zostaną utworzone przy użyciu nazw <endpoint_name>-<deployment_name>-model_inputs i <endpoint_name>-<deployment_name>-model_outputs. Te zasoby danych są aktualizowane w czasie rzeczywistym podczas korzystania z wdrożenia w środowisku produkcyjnym. Monitory modelu mogą następnie używać zasobów danych do monitorowania wydajności modelu w środowisku produkcyjnym.