Implementowanie architektury medallion lakehouse w usłudze Microsoft Fabric
W tym artykule przedstawiono architekturę jeziora medallion i opisano sposób implementowania magazynu lakehouse w usłudze Microsoft Fabric. Jest ona przeznaczona dla wielu odbiorców:
- Inżynierowie danych: personel techniczny, który projektuje, kompiluje i utrzymuje infrastrukturę i systemy, które umożliwiają organizacji zbieranie, przechowywanie, przetwarzanie i analizowanie dużych ilości danych.
- Centrum doskonałości, IT i zespół ds. analizy biznesowej: zespoły odpowiedzialne za nadzorowanie analiz w całej organizacji.
- Administratorzy sieci szkieletowej: administratorzy, którzy są odpowiedzialni za nadzorowanie usługi Fabric w organizacji.
Architektura typu medallion lakehouse, powszechnie znana jako architektura medalionu, jest wzorcem projektowym używanym przez organizacje do logicznego organizowania danych w lakehouse. Jest to zalecane podejście projektowe dla sieci szkieletowej.
Architektura medalionu składa się z trzech odrębnych warstw — lub stref. Każda warstwa wskazuje jakość danych przechowywanych w lakehouse, a wyższe poziomy reprezentują wyższą jakość. To wielowarstwowe podejście pomaga w tworzeniu pojedynczego źródła prawdy dla produktów danych przedsiębiorstwa.
Co ważne, architektura medalionu gwarantuje niepodzielność, spójność, izolację i trwałość (ACID) właściwości w miarę postępu danych przez warstwy. Począwszy od danych pierwotnych, seria weryfikacji i przekształceń przygotowuje dane zoptymalizowane pod kątem wydajnej analizy. Istnieją trzy etapy medalonu: brązowy (surowy), srebrny (zweryfikowany) i złoty (wzbogacony).
Aby uzyskać więcej informacji, zobacz Co to jest architektura medalonu lakehouse?.
OneLake i lakehouse w sieci szkieletowej
Podstawą nowoczesnego magazynu danych jest usługa Data Lake. Microsoft OneLake, który jest jednym, ujednoliconym, logicznym magazynem danych w całej organizacji. Jest ona automatycznie aprowizowana z każdą dzierżawą usługi Fabric i została zaprojektowana tak, aby była jedną lokalizacją dla wszystkich danych analitycznych.
Możesz użyć usługi OneLake do:
- Usuń silosy i zmniejsz nakład pracy w zakresie zarządzania. Wszystkie dane organizacyjne są przechowywane, zarządzane i zabezpieczone w ramach jednego zasobu usługi Data Lake. Ponieważ usługa OneLake jest aprowizowana w dzierżawie usługi Fabric, nie ma więcej zasobów do aprowizowania ani zarządzania nimi.
- Zmniejszanie przenoszenia i duplikowania danych. Celem usługi OneLake jest przechowywanie tylko jednej kopii danych. Mniejsza liczba kopii danych powoduje zmniejszenie liczby procesów przenoszenia danych, co prowadzi do wzrostu wydajności i zmniejszenia złożoności. W razie potrzeby możesz utworzyć skrót do odwołań do danych przechowywanych w innych lokalizacjach, zamiast kopiować je do usługi OneLake.
- Używanie z wieloma aparatami analitycznymi. Dane w usłudze OneLake są przechowywane w otwartym formacie. Dzięki temu dane mogą być odpytywane przez różne aparaty analityczne, w tym usługi Analysis Services (używane przez usługę Power BI), T-SQL i Apache Spark. Inne aplikacje inne niż sieć szkieletowa mogą używać interfejsów API i zestawów SDK do uzyskiwania dostępu do usługi OneLake .
Aby uzyskać więcej informacji, zobacz OneLake, onedrive dla danych.
Aby przechowywać dane w usłudze OneLake, należy utworzyć magazyn lakehouse w usłudze Fabric. Lakehouse to platforma architektury danych do przechowywania danych, zarządzania nimi i analizowania danych ze strukturą i bez struktury w jednej lokalizacji. Można ją łatwo skalować do dużych ilości danych wszystkich typów i rozmiarów plików, a ponieważ jest ona przechowywana w jednej lokalizacji, jest łatwo współużytkowana i ponownie wykorzystywana w całej organizacji.
Każdy magazyn typu lakehouse ma wbudowany punkt końcowy analizy SQL, który umożliwia odblokowanie możliwości magazynu danych bez konieczności przenoszenia danych. Oznacza to, że możesz wykonywać zapytania dotyczące danych w usłudze Lakehouse przy użyciu zapytań SQL i bez żadnej specjalnej konfiguracji.
Aby uzyskać więcej informacji, zobacz Co to jest lakehouse w usłudze Microsoft Fabric?.
Tabele i pliki
Podczas tworzenia magazynu lakehouse w usłudze Fabric dwie fizyczne lokalizacje magazynu są aprowizowane automatycznie dla tabel i plików.
- Tabele to obszar zarządzany do hostowania tabel wszystkich formatów na platformie Apache Spark (CSV, Parquet lub Delta). Wszystkie tabele, niezależnie od tego, czy są tworzone automatycznie, czy jawnie, są rozpoznawane jako tabele w lakehouse. Ponadto wszystkie tabele delty, które są plikami danych Parquet z dziennikiem transakcji opartym na plikach, również są rozpoznawane jako tabele.
- Pliki to obszar niezarządzany do przechowywania danych w dowolnym formacie pliku. Wszystkie pliki różnicowe przechowywane w tym obszarze nie są automatycznie rozpoznawane jako tabele. Jeśli chcesz utworzyć tabelę w folderze usługi Delta Lake w niezarządzanym obszarze, musisz jawnie utworzyć skrót lub tabelę zewnętrzną z lokalizacją wskazującą folder niezarządzany zawierający pliki usługi Delta Lake na platformie Apache Spark.
Główną różnicą między obszarem zarządzanym (tabelami) a obszarem niezarządzanych (plikami) jest automatyczne odnajdywanie tabel i proces rejestracji. Ten proces jest uruchamiany w dowolnym folderze utworzonym tylko w obszarze zarządzanym, ale nie w obszarze niezarządzanych.
W usłudze Microsoft Fabric eksplorator lakehouse udostępnia ujednoliconą graficzną reprezentację całej usługi Lakehouse, aby użytkownicy mogli nawigować po danych, uzyskiwać do niej dostęp i aktualizować je.
Aby uzyskać więcej informacji na temat automatycznego odnajdywania tabel, zobacz Automatyczne odnajdywanie i rejestrowanie tabel.
Magazyn usługi Delta Lake
Usługa Delta Lake to zoptymalizowana warstwa magazynu, która stanowi podstawę do przechowywania danych i tabel. Obsługuje ona transakcje ACID dla obciążeń danych big data i z tego powodu jest to domyślny format magazynu w usłudze Fabric Lakehouse.
Co ważne, usługa Delta Lake zapewnia niezawodność, bezpieczeństwo i wydajność w usłudze Lakehouse na potrzeby operacji przesyłania strumieniowego i wsadowego. Wewnętrznie przechowuje dane w formacie pliku Parquet, jednak obsługuje również dzienniki transakcji i statystyki, które zapewniają funkcje i poprawę wydajności w standardowym formacie Parquet.
Format usługi Delta Lake w formatach plików ogólnych zapewnia następujące główne korzyści.
- Obsługa właściwości ACID, a zwłaszcza trwałości, aby zapobiec uszkodzeniu danych.
- Szybsze odczytywanie zapytań.
- Zwiększona świeżość danych.
- Obsługa obciążeń wsadowych i przesyłanych strumieniowo.
- Obsługa wycofywania danych przy użyciu podróży w czasie usługi Delta Lake.
- Ulepszono zgodność z przepisami i inspekcję przy użyciu historii tabel usługi Delta Lake.
Sieć szkieletowa standandaryzuje format pliku magazynu za pomocą usługi Delta Lake, a domyślnie każdy aparat obciążenia w sieci szkieletowej tworzy tabele delty podczas zapisywania danych w nowej tabeli. Aby uzyskać więcej informacji, zobacz Tabele lakehouse i Delta Lake.
Architektura medalionu w sieci szkieletowej
Celem architektury medalionu jest przyrostowe i stopniowe ulepszanie struktury i jakości danych podczas przechodzenia przez poszczególne etapy.
Architektura medalionu składa się z trzech odrębnych warstw (lub stref).
- Brązowy: znany również jako strefa nieprzetworzona, ta pierwsza warstwa przechowuje dane źródłowe w oryginalnym formacie. Dane w tej warstwie są zwykle dołączane i niezmienne.
- Silver: znana również jako wzbogacona strefa, ta warstwa przechowuje dane pochodzące z warstwy z brązu. Nieprzetworzone i ustandaryzowane dane są teraz ustrukturyzowane jako tabele (wiersze i kolumny). Może być również zintegrowana z innymi danymi w celu zapewnienia widoku przedsiębiorstwa wszystkich jednostek biznesowych, takich jak klient, produkt i inne.
- Złoto: Znana również jako wyselekcjonowana strefa, ta końcowa warstwa przechowuje dane pochodzące z warstwy srebrnej. Dane są uściślizowane w celu spełnienia określonych wymagań biznesowych i analitycznych podrzędnych. Tabele zwykle są zgodne z projektem schematu gwiazdy, który obsługuje opracowywanie modeli danych zoptymalizowanych pod kątem wydajności i użyteczności.
Ważne
Ponieważ lakehouse fabric reprezentuje jedną strefę, należy utworzyć jedną strefę typu lakehouse dla każdej z trzech stref.
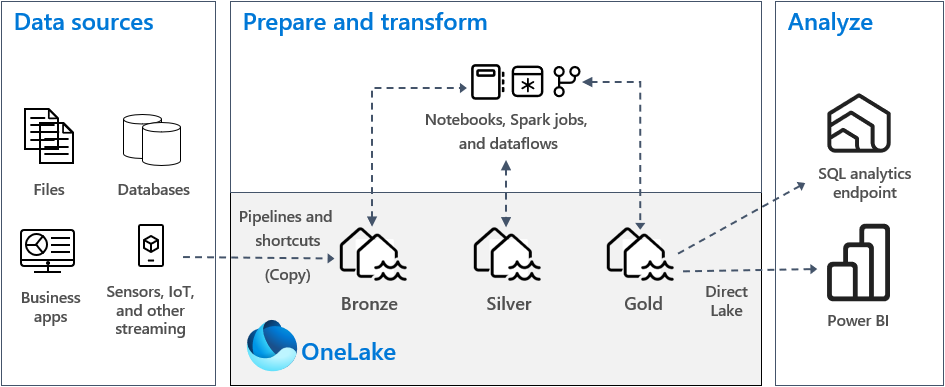
W typowej implementacji architektury medallionu w usłudze Fabric strefa z brązu przechowuje dane w tym samym formacie co źródło danych. Gdy źródło danych jest relacyjną bazą danych, tabele delty są dobrym wyborem. Strefy srebra i złota zawierają tabele delta.
Napiwek
Aby dowiedzieć się, jak utworzyć jezioro, zapoznaj się z samouczkiem dotyczącym kompleksowego scenariusza usługi Lakehouse.
Wskazówki dotyczące usługi Lakehouse w usłudze Fabric
Ta sekcja zawiera wskazówki dotyczące implementowania usługi Fabric lakehouse przy użyciu architektury medalonu.
Model wdrażania
Aby zaimplementować architekturę medalionu w usłudze Fabric, można użyć magazynów typu lakehouse (po jednym dla każdej strefy), magazynu danych lub kombinacji obu tych obiektów. Twoja decyzja powinna być oparta na preferencjach i wiedzy twojego zespołu. Należy pamiętać, że sieć szkieletowa zapewnia elastyczność: możesz użyć różnych aparatów analitycznych, które działają na jednej kopii danych w usłudze OneLake.
Poniżej przedstawiono dwa wzorce, które należy wziąć pod uwagę.
- Wzorzec 1: Utwórz każdą strefę jako jezioro. W takim przypadku użytkownicy biznesowi uzyskują dostęp do danych przy użyciu punktu końcowego analizy SQL.
- Wzorzec 2: Utwórz strefy z brązu i srebra jako magazyny danych oraz strefę złota. W takim przypadku użytkownicy biznesowi uzyskują dostęp do danych przy użyciu punktu końcowego magazynu danych.
Chociaż można tworzyć wszystkie magazyny lakehouse w jednym obszarze roboczym usługi Fabric, zalecamy utworzenie każdego magazynu lakehouse we własnym, oddzielnym obszarze roboczym usługi Fabric. Takie podejście zapewnia większą kontrolę i lepszy nadzór na poziomie strefy.
W przypadku strefy z brązu zalecamy przechowywanie danych w oryginalnym formacie lub używanie parquet lub delta lake. Jeśli to możliwe, zachowaj dane w oryginalnym formacie. Jeśli dane źródłowe pochodzą z usługi OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 lub Google, utwórz skrót w strefie z brązu zamiast kopiować dane.
W przypadku stref srebra i złota zalecamy używanie tabel delty ze względu na dodatkowe możliwości i ulepszenia wydajności, które zapewniają. Sieć szkieletowa standandaryzuje format usługi Delta Lake, a domyślnie każdy aparat w sieci szkieletowej zapisuje dane w tym formacie. Ponadto te aparaty używają optymalizacji czasu zapisu W-Order do formatu pliku Parquet. Ta optymalizacja umożliwia bardzo szybkie odczyty przez aparaty obliczeniowe sieci szkieletowej, takie jak Power BI, SQL, Apache Spark i inne. Aby uzyskać więcej informacji, zobacz Delta Lake table optimization and V-Order (Optymalizacja tabel usługi Delta Lake) i V-Order (Kolejność maszyn wirtualnych).
Na koniec wiele organizacji stoi w obliczu ogromnego wzrostu ilości danych, wraz z coraz większą potrzebą organizowania tych danych i zarządzania nimi w logiczny sposób, ułatwiając bardziej ukierunkowane i wydajne wykorzystanie i nadzór. Może to prowadzić do ustanowienia zdecentralizowanej lub federacyjnej organizacji danych i zarządzania nią za pomocą ładu.
Aby osiągnąć ten cel, rozważ zaimplementowanie architektury siatki danych. Siatka danych to wzorzec architektury, który koncentruje się na tworzeniu domen danych, które oferują dane jako produkt.
Możesz utworzyć architekturę siatki danych dla majątku danych w usłudze Fabric, tworząc domeny danych. Możesz tworzyć domeny mapujące na domeny biznesowe, na przykład marketing, sprzedaż, spis, zasoby ludzkie i inne. Następnie można zaimplementować architekturę medalionu, konfigurując strefy danych w każdej domenie.
Aby uzyskać więcej informacji o domenach, zobacz Domeny.
Omówienie magazynu danych tabel usługi Delta
W tej sekcji opisano inne tematy wskazówek związane z implementacją architektury lakehouse medallion w usłudze Fabric.
Rozmiar pliku
Ogólnie rzecz biorąc, platforma danych big data działa lepiej, gdy ma niewielką liczbę dużych plików, a nie dużą liczbę małych plików. Dzieje się tak, ponieważ spadek wydajności występuje, gdy aparat obliczeniowy musi zarządzać wieloma operacjami metadanych i plików. Aby uzyskać lepszą wydajność zapytań, zalecamy, aby dążyć do plików danych o rozmiarze około 1 GB.
Usługa Delta Lake ma funkcję o nazwie optymalizacja predykcyjna. Optymalizacja predykcyjna eliminuje konieczność ręcznego zarządzania operacjami konserwacji tabel różnicowych. Po włączeniu tej funkcji usługa Delta Lake automatycznie identyfikuje tabele, które będą korzystać z operacji konserwacji, a następnie optymalizuje ich magazyn. Może ona w sposób przezroczysty połączyć wiele mniejszych plików w duże pliki i bez żadnego wpływu na innych czytelników i autorów danych. Chociaż ta funkcja powinna stanowić część doskonałości operacyjnej i pracy nad przygotowywaniem danych, sieć Szkieletowa ma również możliwość optymalizacji tych plików danych podczas zapisywania danych. Aby uzyskać więcej informacji, zobacz Optymalizacja predykcyjna usługi Delta Lake.
Przechowywanie historyczne
Domyślnie usługa Delta Lake przechowuje historię wszystkich wprowadzonych zmian, co oznacza, że rozmiar metadanych historycznych rośnie wraz z upływem czasu. Na podstawie wymagań biznesowych należy dążyć do przechowywania danych historycznych tylko przez określony czas, aby zmniejszyć koszty magazynowania. Rozważ przechowywanie danych historycznych tylko w ostatnim miesiącu lub w innym odpowiednim przedziale czasu.
Starsze dane historyczne z tabeli delty można usunąć przy użyciu polecenia VACUUM. Należy jednak pamiętać, że domyślnie nie można usuwać danych historycznych w ciągu ostatnich siedmiu dni — w celu zachowania spójności danych. Domyślna liczba dni jest kontrolowana przez właściwość delta.deletedFileRetentionDuration = "interval <interval>"tabeli . Określa okres, przez który plik musi zostać usunięty, zanim będzie można go uznać za kandydata do operacji próżniowej.
Partycje tabel
Podczas przechowywania danych w każdej strefie zalecamy użycie struktury folderów partycjonowanych wszędzie tam, gdzie ma to zastosowanie. Ta technika pomaga zwiększyć możliwości zarządzania danymi i wydajność zapytań. Ogólnie rzecz biorąc, partycjonowane dane w strukturze folderów umożliwiają szybsze wyszukiwanie określonych wpisów danych dzięki przycinaniu partycji/eliminacji.
Zazwyczaj dane są dołączane do tabeli docelowej w miarę nadejścia nowych danych. Jednak w niektórych przypadkach możesz scalić dane, ponieważ trzeba zaktualizować istniejące dane w tym samym czasie. W takim przypadku można wykonać operację upsert przy użyciu polecenia MERGE. Podczas partycjonowania tabeli docelowej należy użyć filtru partycji, aby przyspieszyć operację. Dzięki temu aparat może wyeliminować partycje, które nie wymagają aktualizacji.
Dostęp do danych
Na koniec należy zaplanować i kontrolować, kto potrzebuje dostępu do określonych danych w lakehouse. Należy również zrozumieć różne wzorce transakcji, których będą używać podczas uzyskiwania dostępu do tych danych. Następnie można zdefiniować odpowiedni schemat partycjonowania tabel i kolokację danych za pomocą indeksów kolejności usługi Delta Lake Z.
Powiązana zawartość
Aby uzyskać więcej informacji na temat implementowania usługi Fabric Lakehouse, zobacz następujące zasoby.
- Samouczek: kompleksowe scenariusze usługi Lakehouse
- Tabele Lakehouse i Delta Lake
- Przewodnik po decyzjach dotyczących usługi Microsoft Fabric: wybieranie magazynu danych
- Optymalizacja tabel usługi Delta Lake i kolejność V
- Potrzeba optymalizacji zapisu na platformie Apache Spark
- Pytania? Spróbuj poprosić społeczność usługi Fabric.
- Sugestie? Współtworzenie pomysłów na ulepszanie usługi Fabric.