Omówienie typów modeli w Microsoft Syntex
Dotyczy: √ Wszystkie modele niestandardowe | √ Wszystkie wstępnie utworzone modele
Zrozumienie zawartości w Microsoft Syntex rozpoczyna się od modeli przetwarzania dokumentów. Modele przetwarzania dokumentów umożliwiają identyfikowanie i klasyfikowanie dokumentów przekazanych do bibliotek dokumentów programu SharePoint, a następnie wyodrębnianie potrzebnych informacji z każdego pliku.
Po zastosowaniu do biblioteki dokumentów programu SharePoint model jest skojarzony z typem zawartości i zawiera kolumny do przechowywania wyodrębnianych informacji. Utworzony typ zawartości jest przechowywany w galerii typów zawartości programu SharePoint. Możesz również użyć istniejących typów zawartości do używania ich schematu.
Funkcja Syntex używa modeli niestandardowych i wstępnie utworzonych modeli.
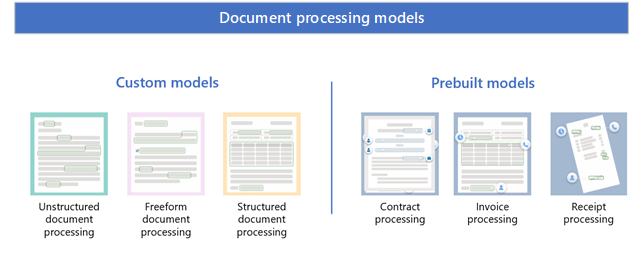
Modele mogą być modelami przedsiębiorstwa utworzonymi w centrum zawartości lub modelami lokalnymi tworzonymi w lokalnej witrynie programu SharePoint.
Modele niestandardowe
Typ wybranego modelu niestandardowego będzie zależeć od używanych typów plików, formatu i struktury plików oraz miejsca, w których chcesz zastosować model.
Modele niestandardowe obejmują:
- Przetwarzanie dokumentów bez struktury
- Dowolne przetwarzanie dokumentów
- Przetwarzanie dokumentów strukturalnych
Aby wyświetlić różnice równoległe w modelach niestandardowych, zobacz Porównanie modeli niestandardowych.
Podczas tworzenia modelu niestandardowego wybierzesz metodę trenowania skojarzoną z typem modelu. Jeśli na przykład chcesz utworzyć model przetwarzania dokumentów bez struktury, na stronie Opcje tworzenia modelu , na której utworzysz model, wybierz opcję Metoda nauczania . W poniższej tabeli przedstawiono metodę trenowania skojarzoną z każdym typem modelu niestandardowego.
| Niestrukturalnych przetwarzanie dokumentów |
Dowolny kształt przetwarzanie dokumentów |
Strukturalnych przetwarzanie dokumentów |
|---|---|---|
 |
 |
 |
Uwaga
Aby udostępnić użytkownikom metodę wyboru Dowolny kształt i opcje metody Układ, najpierw należy je skonfigurować w Centrum administracyjne platformy Microsoft 365.
Przetwarzanie dokumentów bez struktury
Użyj modelu przetwarzania dokumentów bez struktury, aby automatycznie klasyfikować dokumenty i wyodrębniać z nich informacje. Najlepiej sprawdza się w przypadku dokumentów bez struktury, takich jak listy lub umowy. Dokumenty te muszą zawierać tekst, który można zidentyfikować na podstawie fraz lub wzorców. Zidentyfikowany tekst określa zarówno typ pliku, który jest (jego klasyfikacja), jak i to, co chcesz wyodrębnić (jego wyodrębniacze).
Na przykład dokument bez struktury może być listem odnawiającym umowę, który można napisać na różne sposoby. Jednak informacje istnieją spójnie w treści każdego dokumentu odnawiania umowy, na przykład ciąg tekstowy "Data rozpoczęcia usługi", po którym następuje rzeczywista data.
Ten typ modelu obsługuje najszerszy zakres typów plików i obsługuje ponad 40 języków.
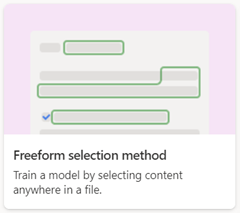
Podczas tworzenia modelu przetwarzania dokumentów bez struktury użyj opcji Metoda nauczania .
Aby uzyskać więcej informacji, zobacz Omówienie przetwarzania dokumentów bez struktury.
Dowolne przetwarzanie dokumentów
Użyj modelu przetwarzania dokumentów o dowolnej postaci, aby automatycznie wyodrębniać informacje z dokumentów bez struktury i dowolnych kształtów, takich jak listy i kontrakty, w których informacje mogą być wyświetlane w dowolnym miejscu dokumentu.
Dowolne modele przetwarzania dokumentów używają narzędzia Microsoft Power Apps AI Builder do tworzenia i trenowania modeli w programie Syntex.
Uwaga
Model przetwarzania dokumentów o dowolnej forformie nie jest jeszcze dostępny w niektórych regionach. Aby uzyskać więcej informacji, zobacz Dostępność funkcji według regionów.
Ponieważ organizacja odbiera listy i dokumenty w dużych ilościach z różnych źródeł, takich jak poczta, faks i poczta e-mail, przetwarzanie tych dokumentów i ręczne wprowadzanie ich do bazy danych może zająć dużo czasu. Dzięki użyciu sztucznej inteligencji do wyodrębniania tekstu i innych informacji z tych dokumentów ten model automatyzuje ten proces.
Ten typ modelu jest najlepszą opcją dla dokumentów w plikach PDF lub plikach obrazów, gdy nie wymagasz automatycznej klasyfikacji typu dokumentu i obsługuje on ponad 40 języków.
Podczas tworzenia modelu przetwarzania dokumentów o dowolnej forformie użyj opcji Wybór dowolnej formy .
Aby uzyskać więcej informacji, zobacz Omówienie przetwarzania dokumentów ze strukturą i dowolną formą.
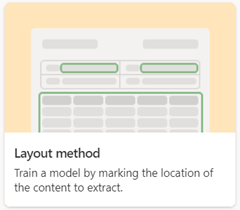
Przetwarzanie dokumentów strukturalnych
Użyj modelu przetwarzania dokumentów strukturalnych, aby automatycznie identyfikować wartości pól i tabel. Najlepiej sprawdza się w przypadku dokumentów ustrukturyzowanych lub częściowo ustrukturyzowanych, takich jak formularze i faktury.
Modele przetwarzania dokumentów strukturalnych używają przetwarzania dokumentów programu Microsoft Power Apps AI Builder (wcześniej znanego jako przetwarzanie formularzy) do tworzenia i trenowania modeli w programie Syntex.
Ten typ modelu obsługuje najszerszy zakres języków i jest wytrenowany w celu zrozumienia układu formularza z przykładowych dokumentów, a następnie uczy się szukać danych potrzebnych do wyodrębnienia z podobnych lokalizacji. Formularze zwykle mają bardziej ustrukturyzowany układ, w którym jednostki znajdują się w tej samej lokalizacji (na przykład numer ubezpieczenia społecznego w formularzu podatkowym).
Podczas tworzenia modelu przetwarzania dokumentów strukturalnych użyj opcji Metoda układu .
Aby uzyskać więcej informacji, zobacz Omówienie przetwarzania dokumentów ze strukturą i dowolną formą.
Wstępnie utworzone modele
Jeśli nie musisz tworzyć modelu niestandardowego, możesz użyć wstępnie utworzonego modelu przetwarzania dokumentów , który został już wytrenowany dla określonych dokumentów strukturalnych.
Wstępnie utworzone modele obejmują:
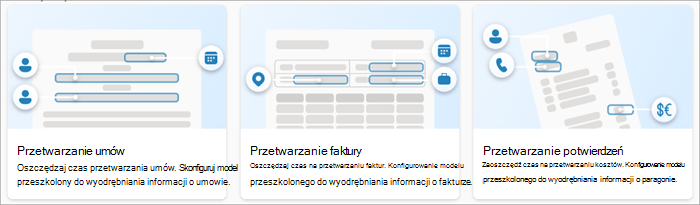
Wstępnie utworzone modele są wstępnie wytrenowane do rozpoznawania dokumentów i informacji strukturalnych w dokumentach. Zamiast tworzyć nowy model niestandardowy od podstaw, można iterować na istniejącym wstępnie wytrenowanym modelu w celu dodania konkretnych pól odpowiadających potrzebom organizacji.
Przetwarzanie kontraktu
Model przetwarzania kontraktów analizuje i wyodrębnia kluczowe informacje z dokumentów kontraktowych. Interfejs API analizuje kontrakty w różnych formatach i wyodrębnia kluczowe informacje o umowie, takie jak nazwa klienta lub strony, adres rozliczeniowy, jurysdykcja i data wygaśnięcia.
Aby uzyskać więcej informacji na temat wstępnie utworzonych modeli przetwarzania kontraktów, zobacz Używanie wstępnie utworzonego modelu do wyodrębniania informacji z kontraktów.
Przetwarzanie faktur
Model przetwarzania faktur analizuje i wyodrębnia kluczowe informacje z faktur sprzedaży. Interfejs API analizuje faktury w różnych formatach i wyodrębnia kluczowe informacje o fakturze, takie jak nazwa klienta, adres rozliczeniowy, data ukończenia i należna kwota.
Aby uzyskać więcej informacji na temat wstępnie utworzonych modeli przetwarzania faktur, zobacz Używanie wstępnie utworzonego modelu do wyodrębniania informacji z faktur.
Przetwarzanie paragonu
Wstępnie utworzony model przetwarzania paragonów analizuje i wyodrębnia kluczowe informacje z paragonów sprzedaży. Interfejs API analizuje drukowane i odręczne potwierdzenia oraz wyodrębnia informacje dotyczące paragonu klucza, takie jak nazwa sprzedawcy, numer telefonu sprzedawcy, data transakcji, podatek i suma transakcji.
Aby uzyskać więcej informacji na temat wstępnie utworzonych modeli przetwarzania paragonów, zobacz Używanie wstępnie utworzonego modelu do wyodrębniania informacji z paragonów.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla