Eventos
Junte-se a nós na FabCon Vegas
31 de mar., 23 - 2 de abr., 23
O melhor evento liderado pela comunidade Microsoft Fabric, Power BI, SQL e AI. 31 de março a 2 de abril de 2025.
Registre-se hoje mesmoNão há mais suporte para esse navegador.
Atualize o Microsoft Edge para aproveitar os recursos, o suporte técnico e as atualizações de segurança mais recentes.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Neste tutorial, você criará um Azure Data Factory com um pipeline que carrega dados delta de uma tabela no Banco de Dados SQL do Azure para um Armazenamento de Blobs do Azure.
Neste tutorial, você realizará os seguintes procedimentos:
A seguir está diagrama da solução de alto nível:

Aqui estão as etapas importantes ao criar essa solução:
Selecione a coluna de marca-d'água. Selecione uma coluna no armazenamento de dados de origem, que pode ser usada para dividir os registros novos ou atualizados para cada execução. Normalmente, os dados nessa coluna selecionada (por exemplo, ID ou last_modify_time) seguem crescendo quando linhas são criadas ou atualizadas. O valor máximo dessa coluna é usado como uma marca-d'água.
Prepare um armazenamento de dados para armazenar o valor de marca-d'água. Neste tutorial, você deve armazenar o valor de marca-d'água em um banco de dados SQL.
Criar um pipeline com o seguinte fluxo de trabalho:
O pipeline nesta solução tem as seguintes atividades:
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Abra o SQL Server Management Studio. No Gerenciador de Servidores, clique com o botão direito do mouse no banco de dados e escolha Nova consulta.
Execute o comando SQL a seguir no banco de dados SQL para criar uma tabela chamada data_source_table como o armazenamento de fonte de dados:
create table data_source_table
(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
INSERT INTO data_source_table
(PersonID, Name, LastModifytime)
VALUES
(1, 'aaaa','9/1/2017 12:56:00 AM'),
(2, 'bbbb','9/2/2017 5:23:00 AM'),
(3, 'cccc','9/3/2017 2:36:00 AM'),
(4, 'dddd','9/4/2017 3:21:00 AM'),
(5, 'eeee','9/5/2017 8:06:00 AM');
Neste tutorial, você usa LastModifytime como a coluna marca-d'água. Os dados no respositório de fonte de dados são mostrados na tabela a seguir:
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
Execute o comando SQL a seguir no banco de dados SQL para criar uma tabela chamada watermarktable para armazenar o valor de marca-d'água:
create table watermarktable
(
TableName varchar(255),
WatermarkValue datetime,
);
Defina o valor padrão de marca d'água alta com o nome da tabela do armazenamento de dados de origem. Neste tutorial, o nome da tabela é data_source_table.
INSERT INTO watermarktable
VALUES ('data_source_table','1/1/2010 12:00:00 AM')
Examine os dados na tabela watermarktable.
Select * from watermarktable
Saída:
TableName | WatermarkValue
---------- | --------------
data_source_table | 2010-01-01 00:00:00.000
Execute o comando a seguir para criar um procedimento armazenado no banco de dados SQL:
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Iniciar o navegador da Web Microsoft Edge ou Google Chrome. Atualmente, a interface do usuário do Data Factory tem suporte apenas nos navegadores da Web Microsoft Edge e Google Chrome.
No menu à esquerda, selecione Criar um recurso>Integração>Data Factory:
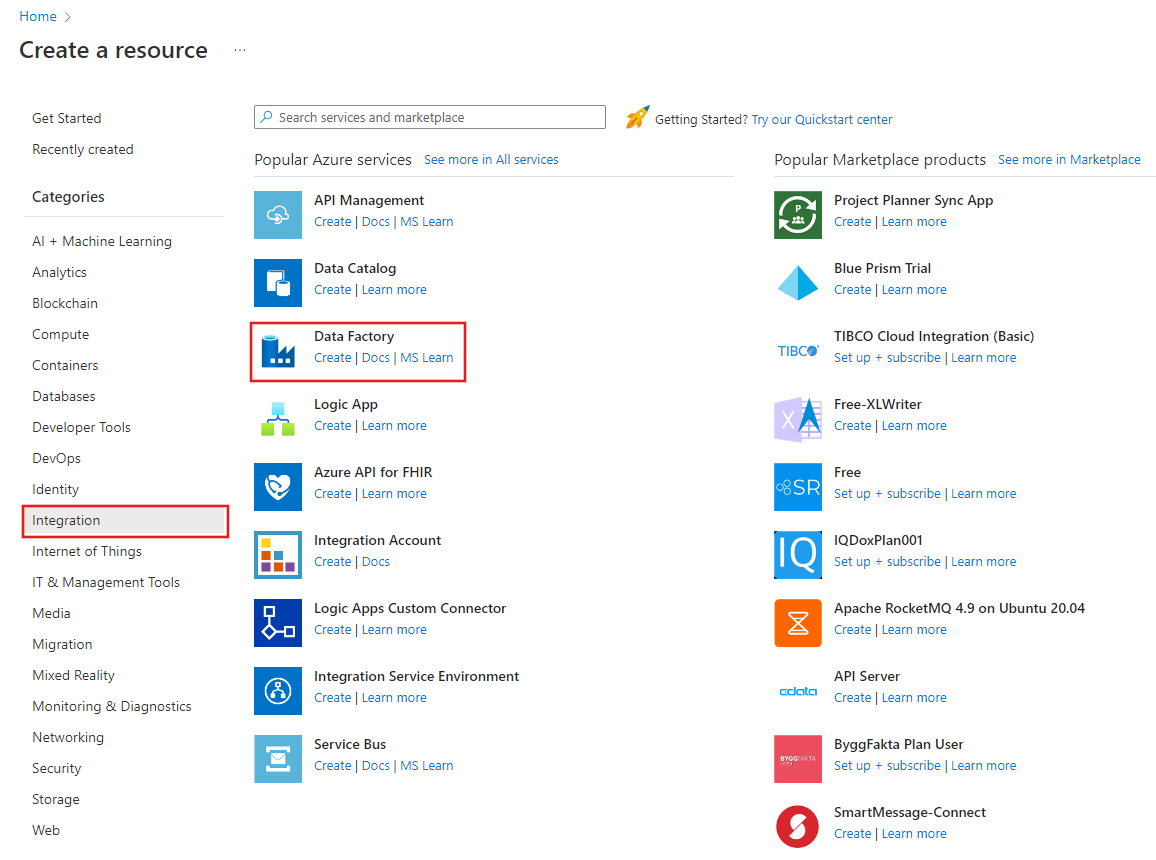
Na página Novo data factory, insira ADFIncCopyTutorialDF como o nome.
O nome do Azure Data Factory precisa ser globalmente exclusivo. Se for exibido um ponto de exclamação vermelho com um erro, altere o nome de data factory (por exemplo, seunomeADFIncCopyTutorialDF) e tente criá-lo novamente. Confira o artigo Data Factory - regras de nomenclatura para ver as regras de nomenclatura para artefatos do Data Factory.
O nome do data factory "ADFIncCopyTutorialDF" não está disponível
Selecione a assinatura do Azure na qual você deseja criar o data factory.
Para o Grupo de Recursos, execute uma das seguintes etapas:
Selecione Usar existentee selecione um grupo de recursos existente na lista suspensa.
Selecione Criar novoe insira o nome de um grupo de recursos.
Para saber mais sobre grupos de recursos, consulte Usando grupos de recursos para gerenciar recursos do Azure.
Selecione V2 para a versão.
Selecione o local do data factory. Apenas os locais com suporte são exibidos na lista suspensa. Os armazenamentos de dados (Armazenamento do Azure, Banco de Dados SQL do Azure, Instância Gerenciada de SQL do Azure etc.) e serviços de computação (HDInsight etc.) usados pelo data factory podem estar em outras regiões.
Clique em Criar.
Após a criação, a página do Data Factory será exibida conforme mostrado na imagem.
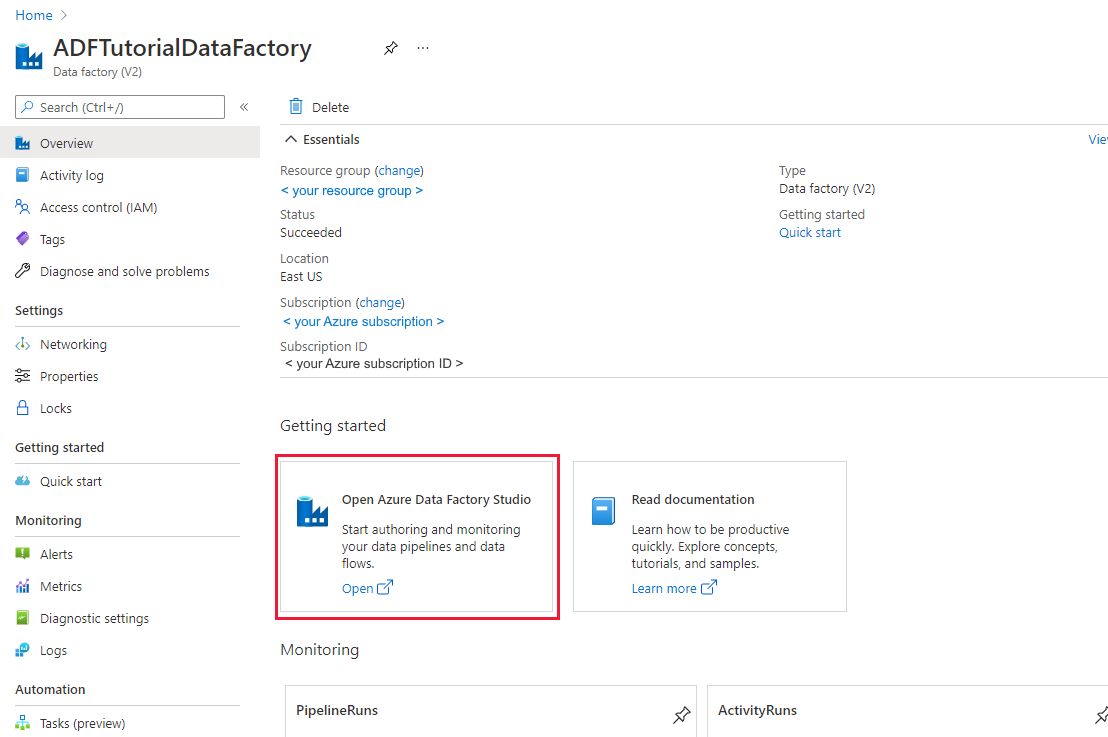
Selecione Abrir no bloco Open Azure Data Factory Studio para iniciar a interface do usuário (IU) do Azure Data Factory em uma guia separada.
Neste tutorial, você cria um pipeline com duas atividades de Pesquisa, uma atividade de Cópia e uma atividade de Procedimento armazenado encadeadas em um pipeline.
Na página inicial da IU do Data Factory, clique no bloco Orquestrar.
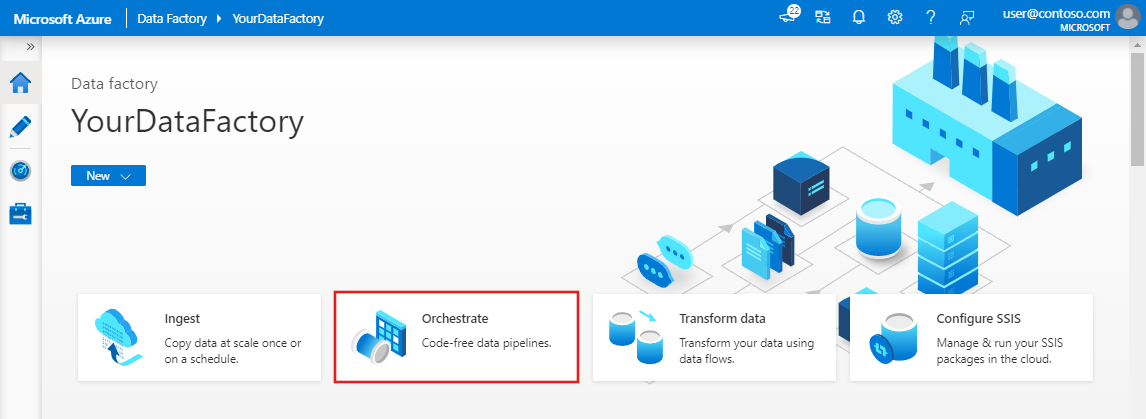
No painel geral, em Propriedades, especifique IncrementalCopyPipeline para Nome. Em seguida, recolha o painel clicando no ícone Propriedades no canto superior direito.
Vamos adicionar a primeira atividade de pesquisa para recuperar o último valor de marca-d'água. Na caixa de ferramentas Atividades, expanda Geral e arraste e solte a atividade de Pesquisa para a superfície do designer de pipeline. Alterar o nome da atividade para LookupOldWaterMarkActivity.
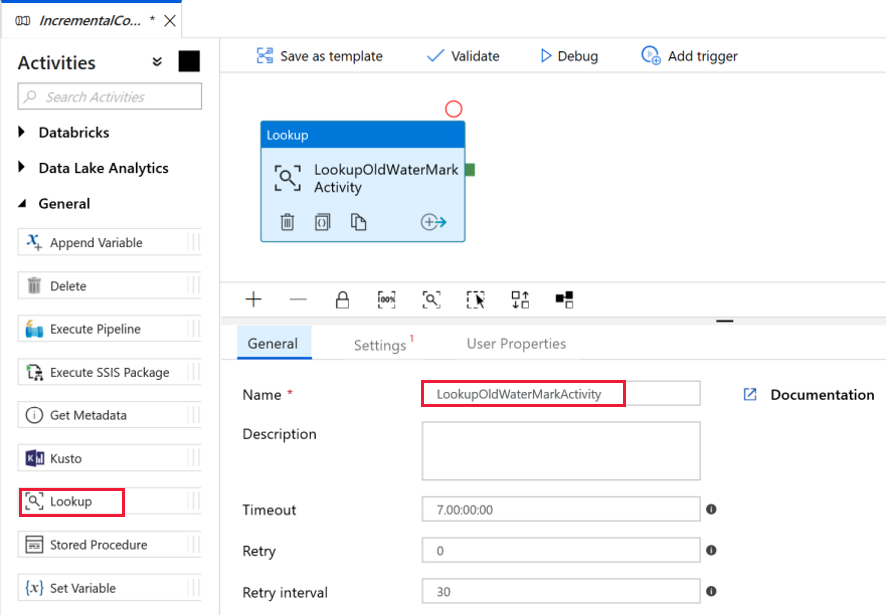
Alterne para a guia Configurações e, em seguida, clique em + Novo para o Conjunto de dados de origem. Nesta etapa, você cria um conjuntos de dados para representar os dados na watermarktable. Esta tabela contém a marca d'água antiga que foi usada na operação de cópia anterior.
Na janela Novo Conjunto de dados, selecione Banco de Dados SQL do Azure e clique em Continuar. Você verá uma nova janela aberta para o conjunto de dados.
Na janela Definir propriedades para o conjunto de dados, insira WatermarkDataset para o Nome.
Para Serviço Vinculado, selecione Novo e, em seguida, execute as seguintes etapas:
Insira AzureSqlDatabaseLinkedService para o Nome.
Selecione o seu servidor para o Nome do servidor.
Selecione o Nome do banco de dados na lista suspensa.
Insira seu Nome de usuário e Senha.
Para testar a conexão ao Banco de Dados SQL, clique em Testar conectividade.
Clique em Concluir.
Confirme se AzureSqlDatabaseLinkedService está selecionado como Serviço vinculado.
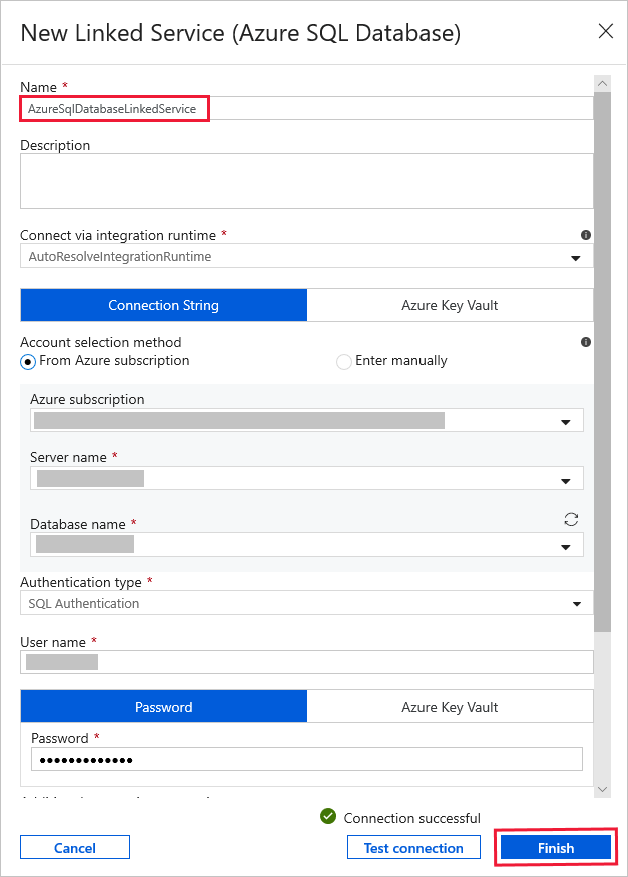
Selecione Concluir.
Na guia Conexão, selecione [dbo].[watermarktable] para Tabela. Se você quiser visualizar os dados na tabela, clique em Visualizar dados.
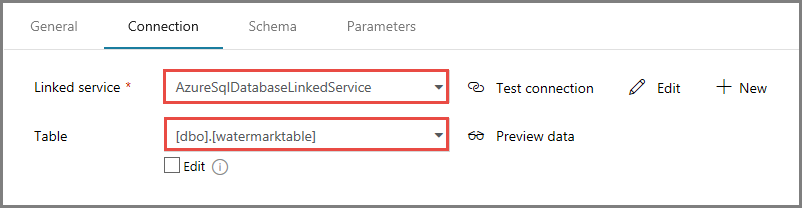
Alterne para o editor de pipeline clicando na guia pipeline na parte superior ou clicando no nome do pipeline n modo de exibição de árvore à esquerda. Na janela Propriedades para a atividade de Pesquisa, confirme se WatermarkDataset está selecionado para o campo Conjunto de Dados de Origem.
Na caixa de ferramentas Atividades, expanda Geral e arraste e solte outra atividade de Pesquisa para a superfície do designer de pipeline e defina o nome como LookupNewWaterMarkActivity na guia Geral da janela Propriedades. Esta atividade de Pesquisa obtém o novo valor de marca d'água da tabela com os dados de origem a serem copiados para o destino.
Na janela Propriedades da segunda atividade de Pesquisa, alterne para a guia Configurações e clique em Novo. Você cria um conjunto de dados para apontar para a tabela de origem que contém o novo valor de marca d'água (valor máximo de LastModifyTime).
Na janela Novo Conjunto de dados, selecione Banco de Dados SQL do Azure e clique em Continuar.
Na janela Definir propriedades, insira SourceDataset como Nome. Selecione AzureSqlDatabaseLinkedService para Serviço vinculado.
Selecione [dbo].[data_source_table] para Tabela. Você especificará uma consulta nesse conjunto de dados posteriormente com o tutorial. A consulta tem precedência sobre a tabela que você especificar nesta etapa.
Selecione Concluir.
Alterne para o editor de pipeline clicando na guia pipeline na parte superior ou clicando no nome do pipeline n modo de exibição de árvore à esquerda. Na janela Propriedades para a atividade de Pesquisa, confirme se SourceDataset está selecionado para o campo Conjunto de dados de origem.
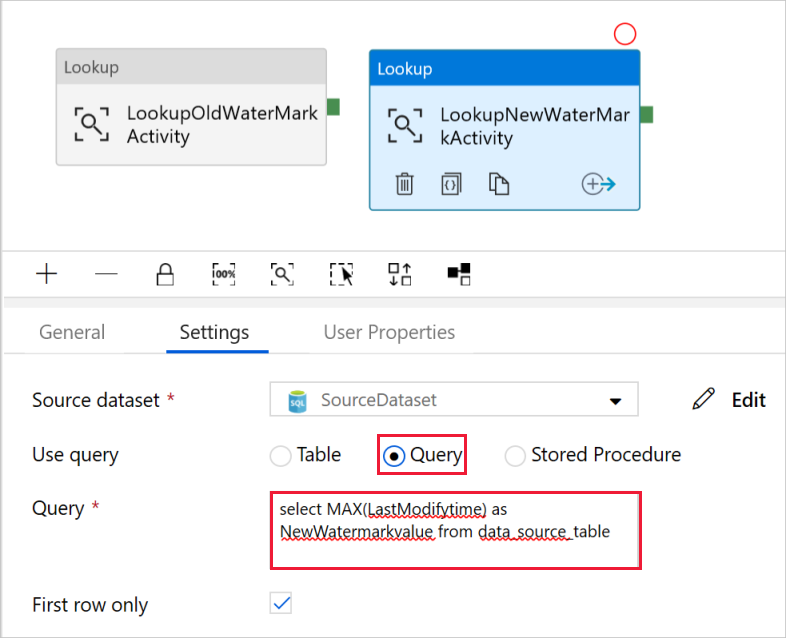
Selecione Consulta para o campo Usar consulta campo e digite a seguinte consulta: você está selecionando apenas o valor máximo de LastModifytime do data_ source_table. Verifique se você também marcou Somente a primeira linha.
select MAX(LastModifytime) as NewWatermarkvalue from data_source_table
Na caixa de ferramentas Atividades, expanda Mover e Transformar e arraste e solte a atividade de Cópia da caixa de ferramentas Atividades e defina o nome para IncrementalCopyActivity.
Conecte ambas as atividades de Pesquisa à atividade de Cópia arrastando o botão verde anexado às atividades de Pesquisa para a atividade de Cópia. Solte o botão do mouse quando visualizar a cor da borda da atividade de Cópia ficar azul.
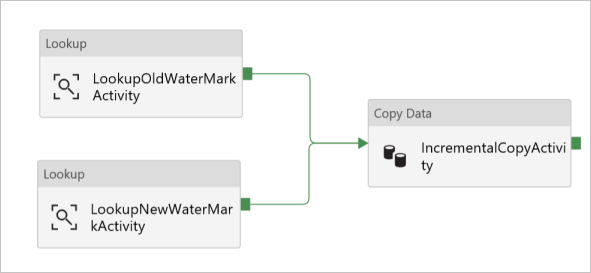
Selecione a atividade de Cópia e confirme se você vê as propriedades da atividade na janela Propriedades.
Alterne para a guia Fonte na janela Propriedades e execute as seguintes etapas:
Selecione SourceDataset para o campo Conjunto de dados de origem.
Selecione a Consulta para o campo Usar consulta.
Insira a seguinte consulta SQL no campo Consulta.
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'
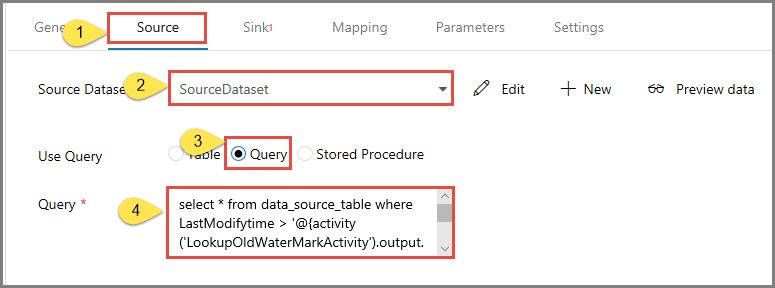
Alterne para a guia Coletor e clique em + Novo para o campo Conjunto de dados do coletor.
Neste tutorial o armazenamento de dados do coletor é do tipo Armazenamento de Blobs do Azure. Portanto, selecione Armazenamento de Blobs do Azure e clique em Continuar na janela Novo Conjunto de dados.
Na página Selecionar Formato, selecione o tipo de formato de seus dados e clique em Continuar.
Na janela Definir Propriedades, insira SinkDataset para o Nome. Para Serviço Vinculado, selecione + Novo. Nesta etapa, você cria uma conexão (serviço vinculado) ao Armazenamento de Blobs do Azure.
Na janela Novo serviço vinculado (Armazenamento de Blobs do Azure) , execute as etapas a seguir:
Na janela Definir Propriedades, confirme se AzureStorageLinkedService está selecionado como Serviço vinculado. Em seguida, selecione Concluir.
Vá para a guia Conexão de SinkDataset e siga estas etapas:
@CONCAT('Incremental-', pipeline().RunId, '.txt') na janela aberta. Em seguida, selecione Concluir. Neste tutorial, o nome do arquivo é gerado dinamicamente pelo uso da expressão. Cada execução de pipeline possui uma ID exclusiva. A atividade de Cópia usa a ID de execução para gerar o nome do arquivo.Alterne para o editor de pipeline clicando na guia Pipeline na parte superior ou clicando no nome do pipeline no modo de exibição de árvore à esquerda.
Na caixa de ferramentas Atividades, expanda Geral e arraste e solte a atividade de Procedimento armazenado da caixa de ferramentas Atividades para a superfície de designer do pipeline. Conecte a saída verde (Bem-sucedida) da atividade de Cópia à atividade de Procedimento armazenado.
Selecione Atividade de Procedimento Armazenado no designer de pipeline, altere seu nome para StoredProceduretoWriteWatermarkActivity.
Alterne para a guia Conta SQL e selecione AzureSqlDatabaseLinkedService para o Serviço Vinculado.
Alterne para a guia Procedimento armazenado e execute as etapas a seguir:
Para Nome do procedimento armazenado, selecione usp_write_watermark.
Para especificar valores para os parâmetros de procedimento armazenado, clique em Importar parâmetros e insira os seguintes valores para os parâmetros:
| Nome | Tipo | Valor |
|---|---|---|
| LastModifiedtime | Datetime | @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} |
| TableName | String | @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName} |
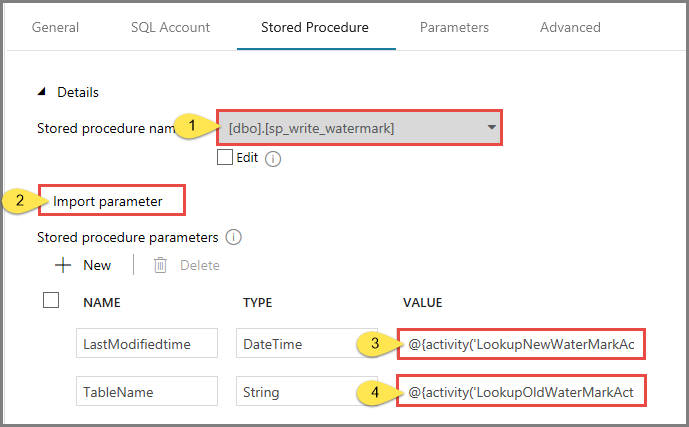
Para validar as configurações de pipeline, clique em Validar na barra de ferramentas. Confirme se não houver nenhum erro de validação. Para fechar a janela Relatório de validação do pipeline clique em >>.
Publique as entidades (serviços vinculados, conjuntos de dados e pipelines) para o serviço de Azure Data Factory selecionando o botão Publicar tudo. Aguarde até que você veja a mensagem informando que a publicação foi bem-sucedida.
Clique em Adicionar Gatilho na barra de ferramentas e, depois, em Gatilho agora.
Na janela Execução de Pipeline, selecione Concluir.
Alterne para a guia Monitorar à esquerda. Você vê o status da execução do pipeline disparado por um gatilho manual. Você pode usar os links na coluna PIPELINE NAME para ver detalhes de execução e executar o pipeline novamente.
Para ver as execuções de atividade associadas à execução do pipeline, selecione o link na coluna PIPELINE NAME. Para obter detalhes sobre as execuções de atividade, selecione o link Detalhes (ícone de óculos) na coluna ACTIVITY NAME. Selecione Todas as execuções de pipeline na parte superior para voltar à exibição Execuções de Pipeline. Para atualizar a exibição, selecione Atualizar.
Conecte-se à sua Conta de Armazenamento do Azure usando ferramentas como o Gerenciador de Armazenamento do Azure. Verifique se um arquivo de saída foi criado na pasta incrementalcopy no contêiner adftutorial.
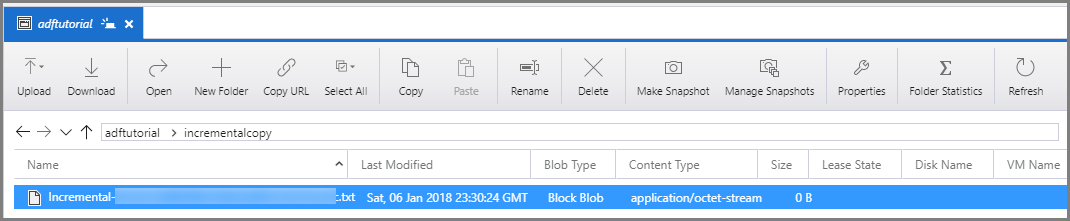
Abra o arquivo de saída e observe que todos os dados são copiado do data_source_table para o arquivo de blobs.
1,aaaa,2017-09-01 00:56:00.0000000
2,bbbb,2017-09-02 05:23:00.0000000
3,cccc,2017-09-03 02:36:00.0000000
4,dddd,2017-09-04 03:21:00.0000000
5,eeee,2017-09-05 08:06:00.0000000
Verifique o valor mais recente de watermarktable. Você verá que o valor da marca d'água foi atualizado.
Select * from watermarktable
Esta é a saída:
| TableName | WatermarkValue |
| --------- | -------------- |
| data_source_table | 2017-09-05 8:06:00.000 |
Insira novos dados no banco de dados (repositório de fonte de dados).
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
Os dados atualizados no banco de dados são:
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
7 | newdata | 2017-09-07 09:01:00.000
Alterne para a guia Editar. Clique no pipeline no modo de exibição de árvore caso ele não esteja aberto no designer.
Clique em Adicionar Gatilho na barra de ferramentas e, depois, em Gatilho agora.
Alterne para a guia Monitorar à esquerda. Você vê o status da execução do pipeline disparado por um gatilho manual. Você pode usar os links na coluna PIPELINE NAME para ver detalhes da atividade e executar o pipeline novamente.
Para ver as execuções de atividade associadas à execução do pipeline, selecione o link na coluna PIPELINE NAME. Para obter detalhes sobre as execuções de atividade, selecione o link Detalhes (ícone de óculos) na coluna ACTIVITY NAME. Selecione Todas as execuções de pipeline na parte superior para voltar à exibição Execuções de Pipeline. Para atualizar a exibição, selecione Atualizar.
No Armazenamento de Blobs você verá que o outro arquivo foi criado. Neste tutorial, o nome do novo arquivo é Incremental-<GUID>.txt. Abra esse arquivo, você verá registros de duas linhas nele.
6,newdata,2017-09-06 02:23:00.0000000
7,newdata,2017-09-07 09:01:00.0000000
Verifique o valor mais recente de watermarktable. Você verá que o valor da marca d'água foi atualizado novamente.
Select * from watermarktable
Saída de exemplo:
| TableName | WatermarkValue |
| --------- | -------------- |
| data_source_table | 2017-09-07 09:01:00.000 |
Neste tutorial, você realizará os seguintes procedimentos:
Neste tutorial, o pipeline copiou dados de uma única tabela em um Banco de Dados SQL para um Armazenamento de Blobs. Avance para o tutorial a seguir para saber mais sobre como copiar dados de várias tabelas em um banco de dados do SQL Server para um Banco de Dados SQL.
Eventos
Junte-se a nós na FabCon Vegas
31 de mar., 23 - 2 de abr., 23
O melhor evento liderado pela comunidade Microsoft Fabric, Power BI, SQL e AI. 31 de março a 2 de abril de 2025.
Registre-se hoje mesmoTreinamento
Módulo
Usar pipelines do Data Factory no Microsoft Fabric - Training
Usar pipelines do Data Factory no Microsoft Fabric
Certificação
Microsoft Certified: Azure Data Engineer Associate - Certifications
Demonstre a compreensão das tarefas comuns de engenharia de dados para implementar e gerenciar cargas de trabalho de engenharia de dados no Microsoft Azure, usando vários serviços do Azure.