Monitorar o Azure Service Fabric
Este artigo descreve:
- Os tipos de dados de monitoramento que você pode coletar para esse serviço.
- Maneiras de analisar esses dados.
Observação
Se já estiver familiarizado com esse serviço e/ou com o Azure Monitor e apenas quiser saber como analisar os dados de monitoramento, confira a seção Analisar ao final deste artigo.
Quando seus aplicativos e processos de negócios críticos dependem de recursos do Azure, você precisa monitorar e receber alertas para o seu sistema. O serviço do Azure Monitor coleta e agrega métricas e logs de cada componente do seu sistema. O Azure Monitor lhe fornece uma exibição da disponibilidade, desempenho e resiliência e notifica você em caso de problemas. Você pode usar o portal do Azure, o PowerShell, a CLI do Azure, a API REST ou as bibliotecas de cliente para configurar e exibir dados de monitoramento.
- Para obter mais informações sobre o Azure Monitor, confira a Visão geral do Azure Monitor.
- Para obter mais informações sobre como monitorar os recursos do Azure de modo geral, confira Monitorar os recursos do Azure com o Azure Monitor.
Monitoramento do Azure Service Fabric
O Azure Service Fabric tem as seguintes camadas que você pode monitorar:
- Monitoramento de aplicativos: Os aplicativos que são executados nos nós. Você pode monitorar aplicativos com a chave do Application Insights ou registro em log do ASP.NET Core, SDK ou EventStore.
- Monitoramento de plataforma (cluster): Métricas de cliente, logs e eventos para os nós da plataforma ou do cluster, incluindo métricas de contêiner. As métricas e os logs são diferentes para nós do Linux ou do Windows.
- Monitoramento de infraestrutura (desempenho): Contadores de integridade e desempenho do serviço para a infraestrutura do serviço.
Você pode monitorar como seus aplicativos são usados, as ações realizadas pela plataforma do Service Fabric, a utilização de recursos com contadores de desempenho e a integridade geral do cluster. Logs do Azure Monitor e Application Insights oferecem integração interna com o Service Fabric.
- Para saber mais sobre as práticas recomendadas, consulte Práticas recomendadas de monitoramento e diagnóstico para o Azure Service Fabric.
- Para obter um tutorial que mostra como exibir eventos e relatórios de integridade do Service Fabric, consultar as APIs EventStore e monitorar contadores de desempenho, consulte Tutorial: Monitorar um cluster do Service Fabric no Azure.
- Para saber como configurar registos do Azure Monitor para monitorizar os seus contentores do Windows orquestrados no Service Fabric, veja Tutorial: Monitorizar contêineres do Windows no Service Fabric utilizando registos do Azure Monitor.
Service Fabric Explorer
Service Fabric Explorer, um aplicativo de área de trabalho para Windows, macOS e Linux, é uma ferramenta de código aberto para inspecionar e gerenciar cluster do Azure Service Fabric. Para habilitar a automação, todas as ações que podem ser executadas por meio do Service Fabric Explorer também podem ser executadas por meio do PowerShell ou de uma API REST.
Monitoramento de aplicativo
O monitoramento de aplicativo controla como os recursos e componentes de um aplicativo estão sendo usados. Você deseja monitorar seus aplicativos para garantir que os problemas que impactam os usuários são capturados. A responsabilidade do monitoramento de aplicativos é dos usuários que desenvolvem um aplicativo e seus serviços, pois depende exclusivamente da lógica de negócios do aplicativo. Monitorar os seus aplicativos pode ser útil nos seguintes cenários:
- A quantidade de tráfego está enfrentando com o meu aplicativo? - Você precisa dimensionar seus serviços para atender às demandas dos usuários ou resolver um possível gargalo em seu aplicativo?
- Minhas chamadas de serviço a serviço são bem-sucedidas e monitoradas?
- Quais ações são executadas pelos usuários do meu aplicativo? -Coleta de telemetria pode guiar o desenvolvimento futuro de recursos e melhorar diagnósticos para erros de aplicativo
- Meu aplicativo está lançando exceções não tratadas?
- O que está acontecendo dentro dos serviços em execução dentro de Meus contêineres?
A grande novidade sobre monitoramento de aplicativos é que os desenvolvedores podem usar qualquer estrutura que gostariam de uma vez que ele reside dentro do contexto de seu aplicativo e as ferramentas! Você pode aprender mais sobre a solução do Azure para o monitoramento de aplicativos com o Azure Monitor Application Insights em Análise de eventos com o Application Insights.
Também temos um tutorial com a maneira configurar isso para aplicativos .NET. Este tutorial aborda como instalar as ferramentas corretas, um exemplo para gravar a telemetria personalizada em seu aplicativo e visualizar o diagnóstico e a telemetria do aplicativo no portal do Azure.
Registro em log do aplicativo
Instrumentar seu código não é apenas uma maneira de obter insights sobre seus usuários, mas também a única maneira de saber se algo está errado em seu aplicativo e diagnosticar o que precisa ser corrigido. Embora tecnicamente é possível conectar um depurador a um serviço de produção, ele não é uma prática comum. Portanto, é importante ter dados de instrumentação detalhados.
Alguns produtos instrumentam automaticamente seu código. Embora essas soluções possam funcionar bem, a instrumentação manual é quase sempre necessária para ser específica à sua lógica de negócios. No fim das contas, você deve ter informações suficientes para depurar legalmente o aplicativo. Aplicativos de Service Fabric podem ser instrumentados com qualquer estrutura de log. Essa seção descreve algumas abordagens diferentes para instrumentar seu código e quando escolher uma abordagem em vez de outra.
SDK do Application Insights: o Application Insights tem uma integração avançada com o Service Fabric pronta para uso. Os usuários podem adicionar os pacotes NuGet do Service Fabric do IA e receber dados e logs criados e coletados visíveis no Portal do Azure. Além disso, os usuários são incentivados a adicionar sua própria telemetria para diagnosticar e depurar os aplicativos e rastrear quais serviços e partes do aplicativo são mais utilizados. A classe TelemetryClient na SDK fornece muitas maneiras de rastrear a telemetria nos aplicativos. Para obter mais informações, consulte Visualização e análise de eventos com o Application Insights.
Confira um exemplo de como instrumentar e adicionar insights de aplicação à sua aplicação em nosso tutorial para monitorar e diagnosticar uma aplicação .NET.
EventSource: quando você cria uma solução Service Fabric a partir de um modelo no Visual Studio, uma classe derivada de EventSource (ServiceEventSource ou ActorEventSource) é gerada. Um modelo é criado, no qual você pode adicionar eventos para seu aplicativo ou serviço. O nome EventSourcedeve ser exclusivo e deve ser renomeado na cadeia de caracteres do modelo padrão MyCompany-<solution>-<project>. Ter várias definições de EventSource que usam o mesmo nome causa um problema no tempo de execução. Cada evento definido deve ter um identificador exclusivo. Se um identificador não for exclusivo, ocorrerá uma falha de runtime. Algumas organizações atribuem antecipadamente intervalos de valores para evitar conflitos entre equipes de desenvolvimento separadas. Para saber mais, veja blog do Vance ou a documentação do MSDN.
Registro em log do ASP.NET Core: é importante planejar cuidadosamente como você instrumentará seu código. O plano de instrumentação certa pode ajudar a evitar potencialmente desestabilizar sua base de código e, em seguida, precisar reinstrument o código. Para reduzir o risco, você pode escolher uma biblioteca de instrumentação como Microsoft.Extensions.Logging, que faz parte do Microsoft ASP.NET Core. Núcleo do ASP.NET tem um ILogger interface que você pode usar com o provedor de sua escolha, minimizando o efeito no código existente. Você pode usar o código ASP.NET Core no Windows e Linux e no .NET Framework completo, então o código de instrumentação é padronizado.
Para exemplos de como usar essas sugestões, consulte Adicionar registro em log ao aplicativo do Service Fabric.
Monitoramento de plataforma (cluster)
Um usuário está no controle sobre qual telemetria é proveniente de seus aplicativos, pois um usuário escreve o código em si, mas o que sobre o diagnóstico da plataforma do Service Fabric? Uma das metas do Service Fabric é manter os aplicativos resilientes a falhas de hardware. Esse objetivo é conseguido por meio da capacidade de serviços de sistema da plataforma para detectar problemas de infraestrutura e rápidas failover de cargas de trabalho para outros nós no cluster. Mas, neste caso específico, e se os próprios serviços do sistema tiverem problemas? Ou se, ao tentar implantar ou mover uma carga de trabalho, as regras para a veiculação de serviços forem violadas? O Service Fabric fornece diagnósticos para esses e mais para garantir que você seja informado sobre a atividade que ocorre em seu cluster. Alguns cenários de amostra para monitoramento de cluster incluem:
Para obter mais informações sobre monitoramento de plataforma (cluster), veja Monitorando o cluster.
Eventos do Service Fabric
O Service Fabric fornece um conjunto abrangente de eventos de diagnóstico prontos para uso, que você pode acessar por meio do EventStore ou do canal de evento operacional exposto pela plataforma. Esses eventos do Service Fabric ilustram as ações realizadas pela plataforma em entidades diferentes, como nós, aplicativos, serviços e partições. Os mesmos eventos estão disponíveis nos clusters Windows e Linux.
Canais de eventos do Service Fabric: no Windows, os eventos do Service Fabric estão disponíveis em um único provedor de ETW com um conjunto de
logLevelKeywordFiltersrelevantes usados para escolher entre canais operacionais e de dados e mensagens. Essa é a forma como separamos os eventos de saída do Service Fabric para serem filtrados conforme necessário. No Linux, todos os eventos do Service Fabric são fornecidos por meio de LTTng e são colocados em uma tabela de Armazenamento, de onde eles podem ser filtrados conforme necessário. Esses canais contém eventos curados e estruturados que podem ser usados para entender melhor o estado do cluster. O Diagnóstico é habilitado por padrão no momento da criação do cluster, que cria uma tabela de Armazenamento do Azure onde os eventos desses canais são enviados para a consulta no futuro.EventStore é um recurso que mostra eventos de plataforma do Service Fabric no Service Fabric Explorer e programaticamente por meio da API REST da Biblioteca de Clientes do Service Fabric. Você pode ver uma exibição de instantâneo do que está acontecendo em seu cluster para cada nó, serviço, aplicativo e consulta com base na hora do evento. As APIs do EventStore estão disponíveis apenas para clusters do Windows em execução no Azure. Nos computadores Windows, esses eventos são inseridos no EventLog para que você possa ver eventos do Service Fabric no Visualizador de Eventos.
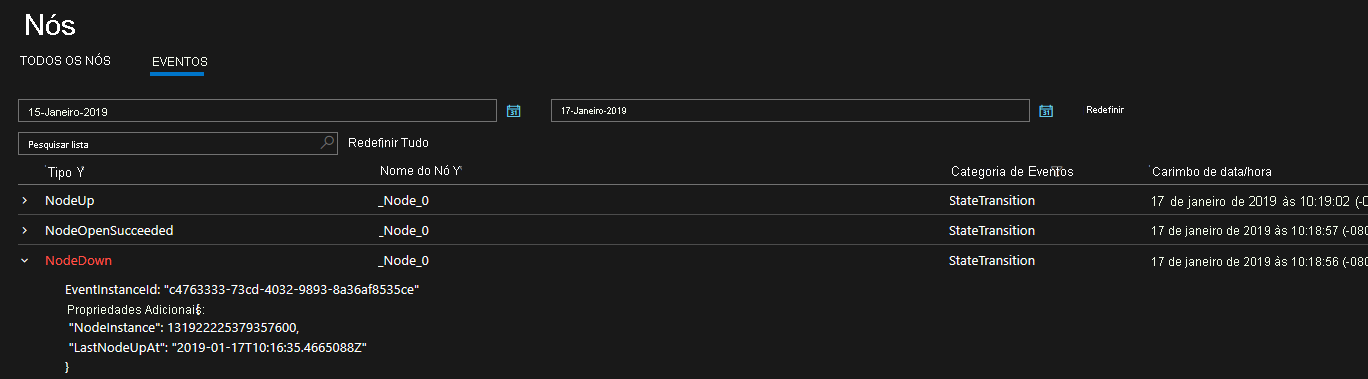
Os diagnósticos fornecidos estão na forma de um conjunto abrangente de eventos prontos para uso. Esses eventos do Service Fabric ilustram ações executadas pela plataforma em entidades diferentes, como Nós, Aplicativos, Serviços, Partições, etc. No último cenário acima, se um nó fosse desativado, a plataforma emitiria um NodeDown evento e você poderia ser notificado imediatamente pela ferramenta de monitoramento de sua escolha. Outros exemplos comuns incluem ApplicationUpgradeRollbackStarted ou PartitionReconfigured durante um failover. Os mesmos eventos estão disponíveis nos clusters Windows e Linux.
Os eventos são enviados através de canais padrão no Windows e no Linux e podem ser lidos por qualquer ferramenta de monitoramento que os suporte. A solução do Azure Monitor é logs do Azure Monitor. Sinta-se à vontade para ler mais sobre nossa integração dos logs do Azure Monitor, que inclui um painel operacional personalizado para seu cluster e algumas consultas de amostra a partir das quais você pode criar alertas. Mais conceitos de monitoramento de cluster estão disponíveis em evento de nível de plataforma e geração de log.
Monitoramento da integridade
A plataforma do Service Fabric inclui um modelo de integridade, que fornece o relatório de integridade extensível para o status de entidades em um cluster. Cada nó, aplicativo, serviço, partição, réplicas ou instância, tem um status de integridade continuamente atualizável. O status de integridade pode ser "OK", "Aviso" ou "Erro". Pense em eventos do Service Fabric como verbos feitos pelo cluster para várias entidades e health como um adjetivo para cada entidade. Cada vez que a integridade de uma determinada entidade transita, um evento também será emitido. Dessa forma, você pode configurar consultas e alertas para eventos de integridade em sua ferramenta de monitoramento escolhida, assim como qualquer outro evento.
Além disso, até permitimos que os usuários substituam a integridade de entidades. Se seu aplicativo estiver passando por uma atualização e os testes de validação falharem, você poderá gravar no Service Fabric Health usando a API Health para indicar que seu aplicativo não está mais íntegro e o Service Fabric reverterá automaticamente a atualização! Para obter mais informações sobre o modelo de integridade, confira a introdução ao monitoramento de integridade do Service Fabric

Watchdogs
Em geral, um watchdog é um serviço separado que inspeciona a integridade e a carga entre serviços, executa ping em pontos de extremidade e relata eventos de integridade inesperados no cluster. Isso pode ajudar a evitar erros que podem não ser detectados com base apenas no desempenho de um único serviço. Os watchdogs também são um bom local para hospedar o código que executa ações corretivas que não exigem a interação do usuário, como limpeza de arquivos de log no armazenamento em determinados intervalos de tempo. Se você quiser um serviço de watchdog SF de software livre totalmente implementado que inclua um modelo de extensibilidade de watchdog fácil de usar e que seja executado em clusters Windows e Linux, consulte o projeto FabricObserver. O FabricObserver é um software pronto para produção. Incentivamos você a implantar o FabricObserver nos clusters de teste e produção e estendê-lo para atender às suas necessidades, por meio de seu modelo de plug-in ou com a bifurcação e a criação de seus próprios observadores internos. O primeiro (plug-ins) é a abordagem recomendada.
Monitoramento de infraestrutura (desempenho)
Agora que abordamos os diagnósticos em seu aplicativo e na plataforma, como sabemos se o hardware está funcionando conforme o esperado? Monitoramento de sua infraestrutura subjacente é uma parte importante para compreender o estado do seu cluster e a utilização de recursos. O desempenho do sistema de medição depende de muitos fatores que podem ser subjetivos, dependendo de suas cargas de trabalho. Esses fatores geralmente são medidos por meio de contadores de desempenho. Esses contadores de desempenho podem vir de uma variedade de fontes, incluindo o sistema operacional, o .NET framework ou a própria plataforma do Service Fabric. Alguns cenários em que eles seriam úteis são
- Eu estou utilizando o meu hardware com eficiência? Você quer usar seu hardware com 90% da CPU ou 10% da CPU. Isso é útil ao dimensionar seu cluster ou otimizar os processos do seu aplicativo.
- Posso prever problemas de infraestrutura proativamente? - muitos problemas são precedidos por alterações bruscas no desempenho, para que você possa usar contadores de desempenho, como I / O de rede e utilização da CPU, para prever e diagnosticar os problemas de maneira proativa.
Uma lista de contadores de desempenho que devem ser coletados no nível de infraestrutura pode ser encontrada em Métricas de desempenho.
Os logs do Azure Monitor são recomendados para o monitoramento de eventos no nível do cluster. Depois de configurar o agente do Log Analytics com seu workspace, você poderá coletar:
- Métricas de desempenho, como utilização da CPU.
- Contadores de desempenho do .NET, como utilização da CPU no nível do processo.
- Contadores de desempenho do Service Fabric, como o número de exceções de um serviço confiável.
- Métricas de contêiner, como utilização de CPU.
Tipos de recurso
O Azure usa o conceito de tipos de recursos e IDs para identificar tudo em uma assinatura. O Azure Monitor organiza os principais dados de monitoramento de maneira similar em métricas e logs com base em tipos de recursos, também chamados de namespaces. Métricas e logs diferentes estão disponíveis para diferentes tipos de recursos. Seu serviço pode estar associado a mais de um tipo de recurso.
Os tipos de recurso também fazem parte das IDs de recursos para cada recurso em execução no Azure. Por exemplo, um tipo de recurso para uma máquina virtual é Microsoft.Compute/virtualMachines. Para obter uma lista de serviços e os tipos de recursos associados a eles, confira Provedores de recursos.
Para obter mais informações sobre os tipos de recursos do Azure Service Fabric, consulte Referência de dados de monitoramento do Service Fabric.
Armazenamento de dados
Para o Azure Monitor:
- Os dados de métricas são armazenados no banco de dados de métricas do Azure Monitor.
- Os dados de log são armazenados no repositório de logs do Azure Monitor. O Log Analytics é uma ferramenta no portal do Azure que pode consultar esse repositório.
- O log de atividades do Azure é um repositório separado com uma interface própria no portal do Azure.
Opcionalmente, você pode rotear dados de log de métricas e atividades para o armazenamento de logs do Azure Monitor. Em seguida, você pode usar o Log Analytics para consultar os dados e correlacioná-los com outros dados de log.
Muitos serviços podem usar configurações de diagnóstico para enviar dados de métricas e logs para outros locais de armazenamento fora do Azure Monitor. Os exemplos incluem o Armazenamento do Azure, sistemas de parceiros hospedados e sistemas de parceiros não Azure, usando Hubs de Eventos.
Para obter informações detalhadas sobre como o Azure Monitor armazena dados, confira Plataforma de dados do Azure Monitor.
Métricas de plataforma do Azure Monitor
O Azure Monitor fornece métricas de plataforma para muitos serviços. Para obter uma lista de todas as métricas que é possível coletar para todos os recursos no Azure Monitor, confira Métricas com suporte no Azure Monitor.
Esse serviço não coleta métricas de plataforma.
Métricas não baseadas no Azure Monitor
Esse serviço fornece outras métricas que não estão incluídas no banco de dados de métricas do Azure Monitor.
Métricas do SO convidado
As métricas para o sistema operacional convidado (SO) executado em nós de cluster do Service Fabric devem ser coletadas por meio de um ou mais agentes executados no SO convidado. As métricas do SO convidado incluem contadores de desempenho que acompanham o percentual de CPU ou o uso da memória do convidado, que são frequentemente usados para dimensionamento automático ou alerta.
A melhor prática é usar e configurar o agente do Azure Monitor para enviar métricas de desempenho do SO convidado por meio da API de métricas personalizadas para o banco de dados de métricas do Azure Monitor. Você pode enviar as métricas do SO convidado para os logs do Azure Monitor usando o mesmo agente. Em seguida, você pode consultar essas métricas e logs usando o Log Analytics.
Observação
O agente do Azure Monitor substitui a extensão do Diagnóstico do Azure e o agente do Log Analytics para o roteamento do SO convidado. Para saber mais, confira Visão geral dos agentes do Azure Monitor.
Logs de recursos do Azure Monitor
Os logs de recursos fornecem insights sobre as operações que foram executadas por um recurso do Azure. Os logs são gerados automaticamente, mas você deve roteá-los para os logs do Azure Monitor para salvá-los ou consultá-los. Os logs são organizados em categorias. Um determinado namespace pode ter várias categorias de log de recursos que você pode coletar.
Esse serviço não coleta logs de recursos, mas você pode encontrar informações sobre eles em Monitoramento de dados de recursos do Azure.
Logs e eventos do Service Fabric
O Service Fabric pode coletar os seguintes logs:
- Para clusters do Windows, você pode configurar o monitoramento de cluster com o Agente de Diagnóstico e os logs do Azure Monitor.
- Para clusters do Linux, os logs do Azure Monitor também são a ferramenta recomendada para o monitoramento da infraestrutura e da plataforma Azure. O diagnóstico de plataforma Linux exige uma configuração diferente. Para obter mais informações, consulte Eventos de cluster do Linux do Service Fabric no Syslog.
- Você pode configurar o agente do Azure Monitor para enviar logs do SO convidado para os logs do Azure Monitor, onde você pode consultá-los usando o Log Analytics.
- Você pode gravar logs de contêiner do Service Fabric no stdout ou stderr para que eles estejam disponíveis nos logs do Azure Monitor.
- Você pode configurar a solução de monitoramento de contêiner para logs do Azure Monitor para exibir eventos de contêiner.
Outras soluções de registro em log
Embora as duas soluções que recomendamos, registros do Azure Monitor e Application Insights, tenham integração integrada com o Service Fabric, muitos eventos são gravados por meio de provedores de ETW e são extensíveis com outras soluções de log. Você também deve examinar o Elastic Stack (especialmente se estiver considerando a execução de um cluster em um ambiente offline), Dynatrace, ou qualquer outra plataforma de sua preferência. Para obter uma lista de parceiros integrados, consulte Parceiros de monitoramento do Azure Service Fabric.
Os pontos-chave para qualquer plataforma que você escolher devem incluir o quanto você está confortável com a interface do usuário, os recursos de consulta, as visualizações e painéis personalizados disponíveis e as ferramentas adicionais que eles fornecem para aprimorar sua experiência de monitoramento.
Log de atividades do Azure
O log de atividades contém eventos de nível de assinatura que acompanham as operações de cada recurso do Azure, conforme visto fora desse recurso, por exemplo, criar um recurso ou iniciar uma máquina virtual.
Coleta: Os eventos do log de Atividades são gerados e coletados automaticamente em um repositório separado para serem vistos no portal do Azure.
Roteamento: você pode enviar dados de log de atividades para os logs do Azure Monitor para analisá-los junto com outros dados de log. Também estão disponíveis outros locais, como o Armazenamento do Microsoft Azure, os Hubs de Eventos do Azure e determinados parceiros de monitoramento da Microsoft. Para obter mais informações sobre como encaminhar o log de atividades, confira Visão geral do log de atividades do Azure.
Analisar dados de monitoramento
Existem várias ferramentas para analisar os dados de monitoramento.
Ferramentas do Azure Monitor
O Azure Monitor dá suporte às seguintes ferramentas básicas:
Explorador de Métricas, uma ferramenta no portal do Azure que permite que você veja e analise as métricas de recursos do Azure. Para obter mais informações sobre essa ferramenta, consulte Analisar métricas com o explorador de métricas do Azure Monitor.
Log Analytics, uma ferramenta no portal do Azure que permite consultar e analisar dados de log usando o KQL (Linguagem de Consulta Kusto). Para obter mais informações, consulte Introdução às consultas de log no Azure Monitor.
O log de atividades, que tem uma interface do usuário no portal do Azure para exibição e pesquisas básicas. Para fazer uma análise mais detalhada, você precisa encaminhar os dados para os logs do Azure Monitor e executar consultas mais complexas no Log Analytics.
As ferramentas que permitem uma visualização mais complexa incluem:
- Painéis, que permitem que você combine diferentes tipos de dados em um único painel no portal do Azure.
- Pastas de Trabalho, relatórios personalizáveis que você pode criar no portal do Azure. As pastas de trabalho podem incluir texto, métricas e consultas de log.
- Grafana, uma ferramenta de plataforma aberta que oferece excelência em termos de painéis operacionais. Você pode usar o Grafana para criar painéis que incluem dados de várias fontes além do Azure Monitor.
- Power BI, um serviço de análises corporativas que fornece visualizações interativas nas diversas fontes de dados. Você pode configurar o Power BI para importar dados de log automaticamente do Azure Monitor a fim de aproveitar essas visualizações.
Para obter uma visão geral de cenários comuns de análise de monitoramento do Service Fabric, consulte Diagnosticar cenários comuns com o Service Fabric.
Ferramentas de exportação do Azure Monitor
Você pode obter dados do Azure Monitor em outras ferramentas usando os seguintes métodos:
Métricas: Use a API REST para métricas para extrair dados de métricas do banco de dados de métricas do Azure Monitor. A API dá suporte a expressões de filtros para refinar os dados recuperados. Para obter mais informações, confira Referência da API REST do Azure Monitor.
Logs: Use a API REST ou as bibliotecas de cliente associadas.
Outra opção é a exportação de dados do workspace.
Para começar a usar a API REST do Azure Monitor, confira o Passo a passo da API REST de monitoramento do Azure.
Consultas do Kusto
Analise os dados de monitoramento nos logs do Azure Monitor/no repositório do Log Analytics usando o KQL (Linguagem de Consulta Kusto).
Importante
Quando você seleciona Logs no menu do serviço no portal, o Log Analytics é aberto com o escopo da consulta definido para o serviço atual. Esse escopo significa que as consultas de log incluirão apenas dados desse tipo de recurso. Se você quiser executar uma consulta que inclua dados de outros serviços do Azure, selecione Logs no menu do Azure Monitor. Confira Escopo da consulta de log e intervalo de tempo no Log Analytics do Azure Monitor para obter detalhes.
Para obter uma lista de consultas comuns para qualquer serviço, confira a Interface de consultas do Log Analytics.
Consultas de exemplo
As consultas a seguir retornam eventos do Service Fabric, incluindo ações em nós. Para ver outras consultas úteis, consulte Eventos do Service Fabric.
Eventos operacionais retornados registrados na última hora:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Retornar relatórios de integridade com HealthState == 3 (Erro) e extrair mais propriedades do campo EventMessage:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Obter eventos operacionais do Service Fabric agregados ao serviço e nó específico:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Alertas
Os alertas do Azure Monitor o notificam proativamente quando condições específicas são encontradas em seus dados de monitoramento. Os alertas permitem que você identifique e resolva problemas no seu sistema antes que os clientes os percebam. Para saber mais, confira Alertas do Azure Monitor.
Existem muitas fontes de alertas comuns para os recursos do Azure. Para obter exemplos de alertas comuns para recursos do Azure, confira Amostra de consultas de alerta de logs. O site Alertas de Linha de Base do Azure Monitor (AMBA) fornece um método semiautomatizado de implementação de alertas, painéis e diretrizes importantes de métrica de plataforma. O site se aplica a um subconjunto de serviços do Azure em contínua expansão, incluindo todos os serviços que fazem parte da Zona de Destino do Azure (ALZ).
O esquema de alerta comum padroniza a consumo do Azure Monitor para notificações de alerta no Azure. Para obter mais informações, confira Esquema de alertas comuns.
Tipos de alertas
Você pode receber alertas sobre qualquer fonte de dados de log ou métrica na plataforma de dados do Azure Monitor. Existem muitos tipos diferentes de alertas dependendo dos serviços que você está monitorando e dos dados de monitoramento que você está coletando. Diferentes tipos de alertas têm diversos benefícios e desvantagens. Para obter mais informações, confira Escolha o tipo de alerta de monitoramento correto para você.
A lista a seguir descreve os tipos de alertas do Azure Monitor que você pode criar:
- Os Alertas de métricas avaliam as métricas de recursos a intervalos regulares. As métricas podem ser métricas de plataforma, métricas personalizadas, logs do Azure Monitor convertidos em métricas ou métricas do Application Insights. Os alertas de métrica também podem aplicar várias condições e limites dinâmicos.
- Os Alertas de logs permitem que os usuários usem uma consulta do Log Analytics para avaliar os logs de recursos com uma frequência predefinida.
- Os Alertas do log de atividades são disparados quando ocorre um novo evento de log de atividades que corresponda às condições definidas. Os alertas do Resource Health e da Integridade do Serviço são alertas do log de atividades que relatam a integridade do serviço e do recurso.
Alguns serviços do Azure também dão suporte a alertas de detecção inteligentes, alertas do Prometheus ou regras de alerta recomendadas.
No caso de alguns serviços, você pode monitorar em larga escala aplicando a mesma regra de alerta de métricas a vários recursos do mesmo tipo que existem na mesma região do Azure. Notificações individuais são enviadas para cada recurso monitorado. Para ver os serviços e as nuvens do Azure com suporte, confira Monitorar vários recursos com uma regra de alerta.
Regras de alerta do Service Fabric
A tabela a seguir lista algumas regras de alerta para o Service Fabric. Esses alertas são apenas exemplos. Você pode definir alertas para qualquer métrica, entrada de log ou entrada de log de atividades listada na Referência de dados de monitoramento do Service Fabric ou na Lista de eventos do Service Fabric.
| Tipo de alerta | Condição | Descrição |
|---|---|---|
| Evento de nó | Nó fica inoperante | ServiceFabricOperationalEvent em que EventID >= 25622 e EventID <= 25626. Essas IDs de evento são encontradas na Referência de eventos de nó. |
| Evento de aplicativo | Reversão da atualização do aplicativo | ServiceFabricOperationalEvent em que EventID == 29623 e EventID == 29624. Essas IDs de evento são encontradas na Referência de evento de aplicativo. |
| Integridade de recursos | Serviço de atualização inacessível/indisponível | O cluster vai para o estado UpgradeServiceUnreachable. |
Recomendações do Assistente
Para alguns serviços, se ocorrerem condições críticas ou alterações iminentes durante operações de recurso, um alerta será exibido na página de Visão geral do serviço no portal. Você pode encontrar mais informações e correções recomendadas para o alerta nas Recomendações do assistente em Monitoramento no menu à esquerda. Durante as operações normais, nenhuma recomendação do assistente será exibida.
Para obter mais informações sobre o Assistente do Azure, confira Visão geral do Assistente do Azure.
Configuração recomendada
Agora que passamos sobre cada área de cenários de monitoramento e exemplo, aqui está um resumo do Azure, ferramentas de monitoramento e configurar necessários para monitorar todas as áreas acima.
- Monitoramento de aplicativos com Application Insights
- Monitoramento de cluster com agente de diagnóstico e logs do Azure Monitor
- Monitoramento de infraestrutura com logs do Azure Monitor
Você também pode usar e modificar o modelo ARM de amostra para automatizar a implantação de todos os recursos e agentes necessários.
Conteúdo relacionado
- Consulte Referência de dados de monitoramento do Service Fabric para obter uma referência das métricas, logs e outros valores importantes criados para o Service Fabric.
- Confira Como monitorar recursos do Azure com o Azure Monitor para obter detalhes gerais sobre o monitoramento de recursos do Azure.
- Consulte a Lista de eventos do Service Fabric.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de