Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo descreve problemas comuns com o desenvolvimento de consultas do Stream Analytics e como solucioná-los.
Este artigo descreve problemas comuns com o desenvolvimento de consultas do Azure Stream Analytics, como solucionar problemas de consulta e como corrigir os problemas. Muitas etapas de solução de problemas exigem que os logs de recursos sejam habilitados para seu trabalho do Stream Analytics. Se você não tiver os logs de recursos habilitados, confira Solucionar problemas do Azure Stream Analytics usando os logs de recursos.
A consulta não está produzindo a saída esperada
Examine os erros testando localmente:
- No portal do Azure, na guia Consulta, selecione Teste. Use os dados de exemplo baixado para testar a consulta. Examine os erros e tente corrigi-los.
- Você também pode testar sua consulta localmente usando as ferramentas do Azure Stream Analytics para Visual Studio ou Visual Studio Code.
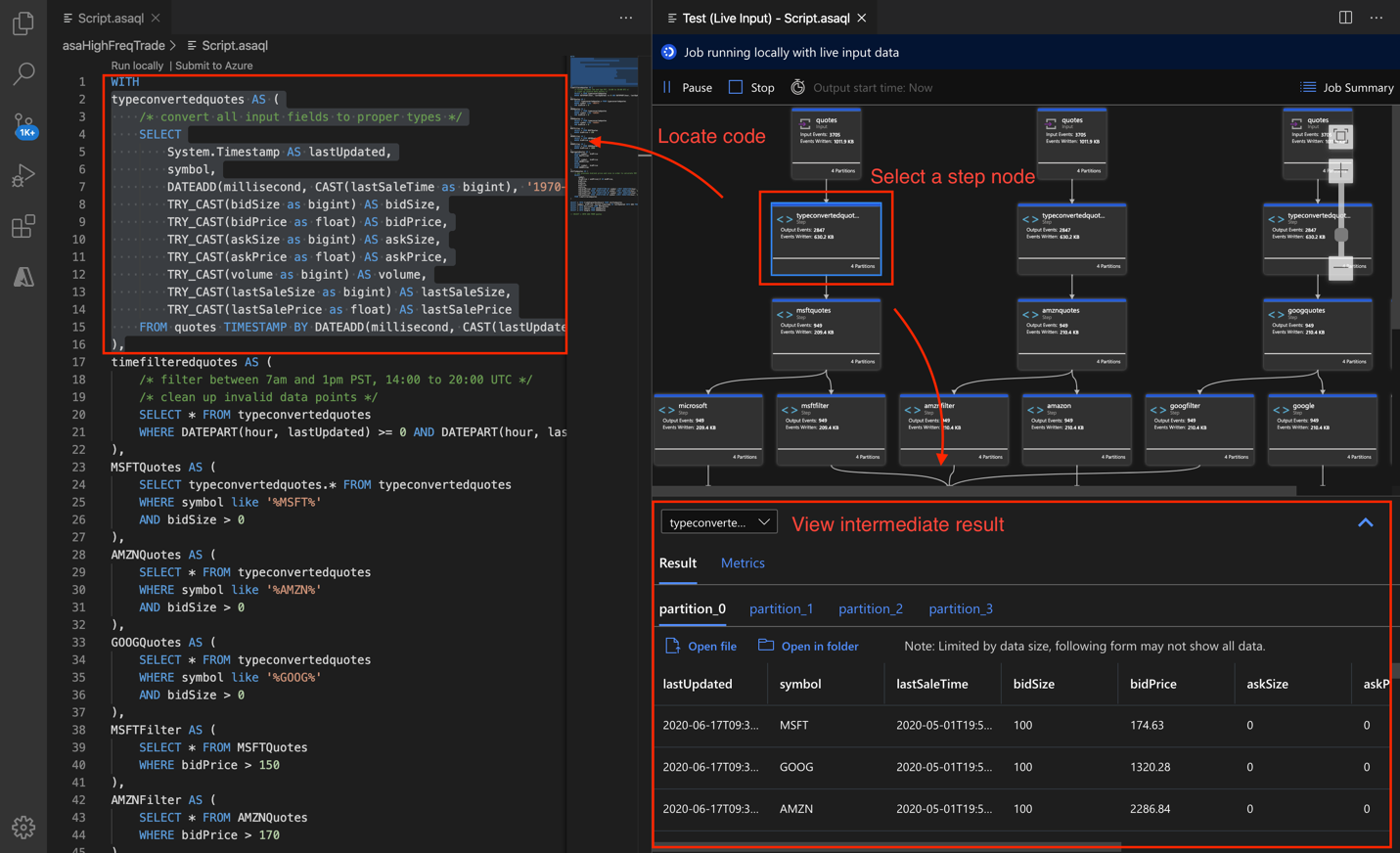
Depurar consultas passo a passo e localmente usando o diagrama de trabalho nas ferramentas do Azure Stream Analytics para Visual Studio Code. O diagrama de trabalho mostra como os dados fluem de fontes de entrada (hub de eventos, Hub IoT, etc.) por meio de várias etapas de consulta e finalmente para coletores de saída. Cada etapa da consulta é mapeada para um conjunto de resultados temporário definido no script usando a instrução WITH. Você pode exibir os dados, além das métricas, em cada conjunto de resultados intermediários para localizar a origem do problema.
Se você usar Carimbo de Data/Hora Por, verifique se os eventos têm carimbos de data/hora maiores que a hora de início do trabalho.
Elimine armadilhas comuns, como:
- Uma cláusula WHERE na consulta filtrou todos os eventos, impedindo que uma saída seja gerada.
- Uma função CAST falha, causando a falha do trabalho. Nesse caso, para evitar falhas de conversão de tipo, use TRY_CAST.
- Ao usar funções de janela, aguarde a duração de toda a janela para ver uma saída da consulta.
- O carimbo de hora de eventos precede a hora de início do trabalho e os eventos são removidos.
- As condições JOIN não correspondem. Se não houver correspondência, não haverá saída.
Verifique se as políticas de ordenação de eventos estão configuradas conforme o esperado. Acesse Configurações e selecione Ordenação de eventos. A política não é aplicada quando você usa o botão Testar para testar a consulta. Esse resultado é uma das diferenças entre o teste no navegador comparado à execução do trabalho em produção.
Depurar usando logs de atividade e de recursos:
- Use os logs de atividade e filtre para identificar e depurar erros.
- Use logs de recurso de trabalho para identificar e depurar erros.
A utilização de recursos está alta
Este artigo mostra como tirar proveito da paralelização no Azure Stream Analytics. Você pode aprender a dimensionar com paralelização de consultas de trabalhos do Stream Analytics configurando partições de entrada e ajustando a definição da consulta de análise.
Se a utilização de recursos estiver consistentemente acima de 80%, o atraso da marca d'água estiver aumentando e o número de eventos pendentes estiver aumentando, considere aumentar as unidades de streaming. A alta utilização indica que o trabalho está perto de usar o máximo de recursos alocados.
Depurar consultas progressivamente
No processamento de dados em tempo real, saber qual será a aparência dos dados no meio da consulta pode ser útil. Isso pode ser visto no diagrama de trabalho no Visual Studio. Se não tiver o Visual Studio, você poderá executar etapas adicionais para gerar dados intermediários.
Como as entradas ou etapas de um trabalho do Stream Analytics do Azure podem ser lidas várias vezes, você pode escrever instruções SELECT INTO extras. Ao fazer isso, dados intermediários são gerados no armazenamento que permitem a você inspecionar a exatidão dos dados, assim como as variáveis de inspeção fazem quando você depura um programa.
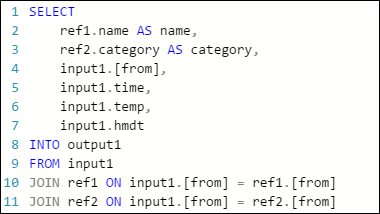
O exemplo de consulta a seguir em um trabalho do Stream Analytics do Azure tem uma entrada de fluxo, duas entradas de dados de referência e uma saída para o Armazenamento de Tabelas do Azure. A consulta une dados do hub de eventos e dois blobs de referência para obter informações de nome e categoria:
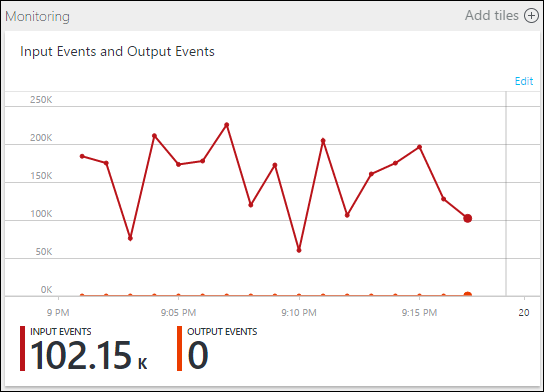
Observe que o trabalho está em execução, mas não há eventos sendo gerados na saída. No bloco Monitoramento, mostrado aqui, você pode ver que a entrada está gerando dados, mas não dá para saber qual etapa de JOIN fez com que todos os eventos fossem removidos.
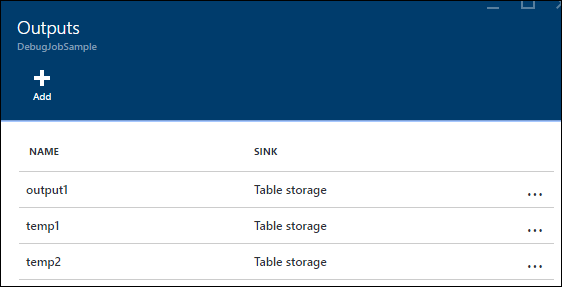
Nesse caso, é possível adicionar algumas instruções extras SELECT INTO para "registrar em log" os resultados intermediários de JOIN e os dados que são lidos da entrada.
Neste exemplo, adicionamos duas novas "saídas temporárias". Elas podem ser qualquer coletor que você quiser. Aqui, usamos o Armazenamento do Azure como um exemplo:
Assim, você pode reescrever a consulta desta forma:
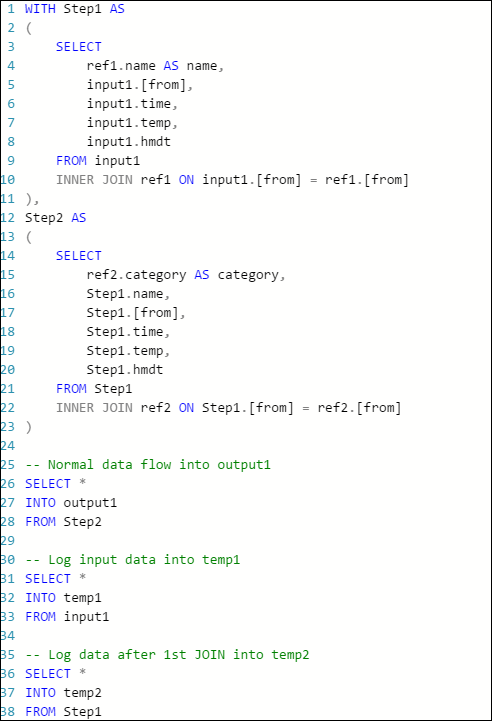
Agora, reinicie o trabalho e deixe ele ser executado por alguns minutos. Em seguida, consulte temp1 e temp2 com o Cloud Explorer do Visual Studio para gerar as seguintes tabelas:
tabela temp1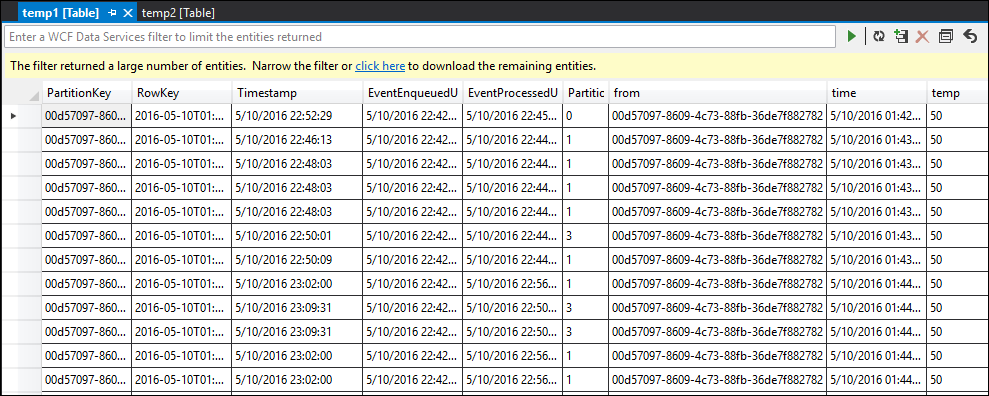
tabela temp2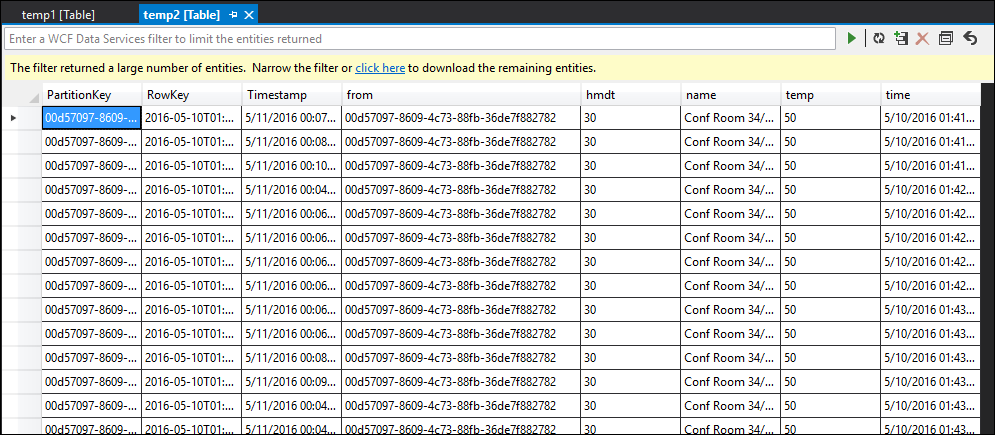
Como você pode ver, temp1 e temp2 têm dados e a coluna de nome é preenchida corretamente em temp2. No entanto, como ainda não há dados na saída, algo está errado:
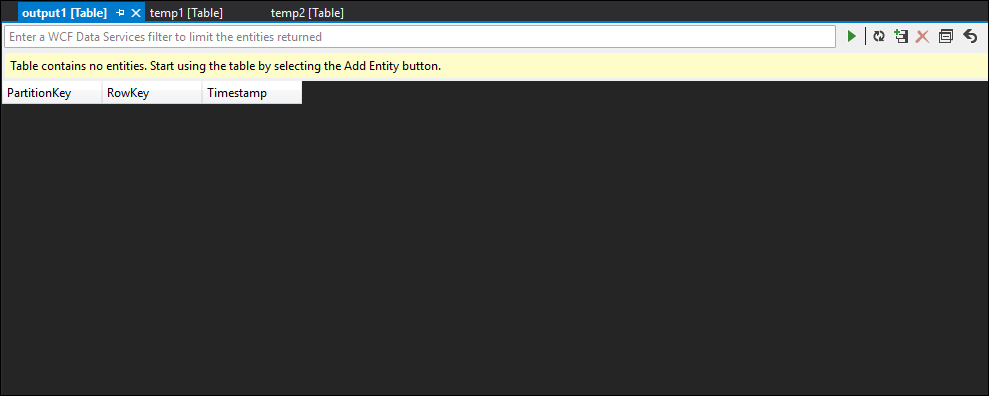
Pela amostragem de dados, você pode ter quase certeza de que o problema é com o segundo JOIN. Você pode baixar os dados de referência do blob e dar uma olhada:
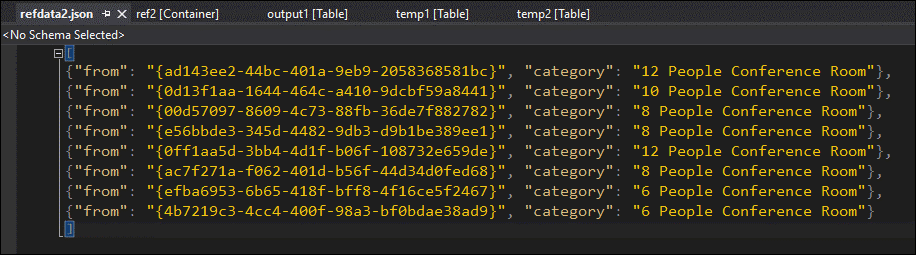
Como você pode ver, o formato do GUID nos dados de referência é diferente do formato da coluna [from] em temp2. Por esse motivo, os dados não chegaram em output1 como esperado.
É possível corrigir o formato dos dados, carregá-los no blob de referência e tentar novamente:
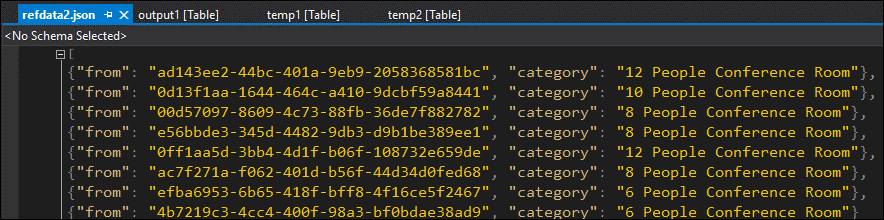
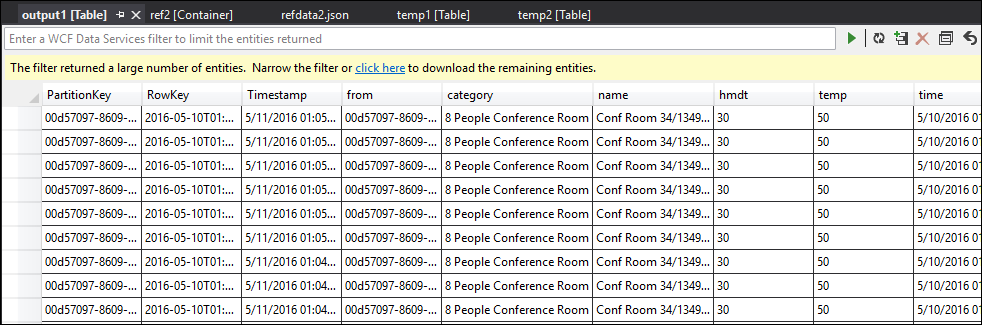
Dessa vez, os dados na saída são formatados e preenchidos conforme esperado.
Obter ajuda
Para obter mais assistência, confira nossa página de Perguntas e respostas do Microsoft do Azure Stream Analytics.