Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
O Azure Cosmos DB para PostgreSQL não tem mais suporte para novos projetos. Não use este serviço para novos projetos. Em vez disso, use um destes dois serviços:
Use o Azure Cosmos DB para NoSQL para obter uma solução de banco de dados distribuído projetada para cenários de alta escala com um SLA (contrato de nível de serviço) de disponibilidade de 99.999%, dimensionamento automático instantâneo e failover automático em várias regiões.
Use a funcionalidade de Clusters Elásticos do Azure para PostgreSQL para PostgreSQL fragmentado, utilizando a extensão Citus de código aberto.
Escolher a coluna de distribuição de cada tabela é uma das decisões de modelação mais importantes que irá tomar. O Azure Cosmos DB para PostgreSQL armazena linhas em fragmentos com base no valor da coluna de distribuição das linhas.
A escolha correta agrupa dados relacionados nos mesmos nós físicos, o que torna as consultas rápidas e adiciona suporte para todos os recursos SQL. Uma escolha incorreta faz com que o sistema funcione lentamente.
Sugestões gerais
Aqui estão quatro critérios para escolher a coluna de distribuição ideal para suas tabelas distribuídas.
Escolha uma coluna que seja uma peça central na carga de trabalho do aplicativo.
Você pode pensar nesta coluna como o "coração", "peça central" ou "dimensão natural" para particionar dados.
Exemplos:
-
device_idem uma carga de trabalho de IoT -
security_idpara um aplicativo financeiro que rastreia valores mobiliários -
user_idem análise de usuários -
tenant_idpara um aplicativo SaaS multilocatário
-
Escolha uma coluna com cardinalidade decente e uma distribuição estatística uniforme.
A coluna deve ter muitos valores e distribuir completa e uniformemente entre todos os fragmentos.
Exemplos:
- Cardinalidade acima de 1000
- Não escolha uma coluna que tenha o mesmo valor em uma grande porcentagem de linhas (distorção de dados)
- Em uma carga de trabalho SaaS, ter um locatário muito maior do que o resto pode causar distorção de dados. Para esta situação, pode usar isolamento de inquilinos para criar uma partição dedicada a lidar com o inquilino.
Escolha uma coluna que beneficie suas consultas existentes.
Para uma carga de trabalho transacional ou operacional (onde a maioria das consultas leva apenas alguns milissegundos), escolha uma coluna que apareça como um filtro em
WHEREcláusulas para pelo menos 80% das consultas. Por exemplo, adevice_idcoluna emSELECT * FROM events WHERE device_id=1.Para uma carga de trabalho analítica (em que a maioria das consultas leva de 1 a 2 segundos), escolha uma coluna que permita que as consultas sejam paralelizadas entre nós de trabalho. Por exemplo, uma coluna que ocorre frequentemente em cláusulas GROUP BY ou consultada sobre vários valores ao mesmo tempo.
Escolha uma coluna que esteja presente na maioria das tabelas grandes.
Tabelas com mais de 50 GB devem ser distribuídas. Escolher a mesma coluna de distribuição para todos permite-lhe localizar os dados dessa coluna nos nós de trabalho. A co-localização torna mais eficiente a execução de JOINs e rollups, bem como a imposição de chaves estrangeiras.
As outras tabelas (menores) podem ser tabelas locais ou de referência. Se a tabela menor precisar UNIR com tabelas distribuídas, torne-a uma tabela de referência.
Exemplos de casos de uso
Vimos critérios gerais para escolher a coluna de distribuição. Agora vamos ver como eles se aplicam a casos de uso comuns.
Aplicações multi-inquilino
A arquitetura multilocatária usa uma forma de modelagem de banco de dados hierárquico para distribuir consultas entre nós no cluster. A parte superior da hierarquia de dados é conhecida como ID do locatário e precisa ser armazenada em uma coluna em cada tabela.
O Azure Cosmos DB para PostgreSQL inspeciona consultas para ver qual ID de locatário elas envolvem e localiza o fragmento de tabela correspondente. Ele roteia a consulta para um único nó de trabalho que contém o fragmento. A execução de uma consulta com todos os dados relevantes colocados no mesmo nó é chamada de colocation.
O diagrama a seguir ilustra a colocalização no modelo de dados multilocatário. Contém duas tabelas, Contas e Campanhas, cada uma distribuída pela account_id. As caixas sombreadas representam fragmentos. Os fragmentos verdes são armazenados juntos em um nó de trabalho e os fragmentos azuis são armazenados em outro nó de trabalho. Observe como uma consulta de associação entre Contas e Campanhas tem todos os dados necessários juntos em um nó quando ambas as tabelas estão restritas ao mesmo account_id.
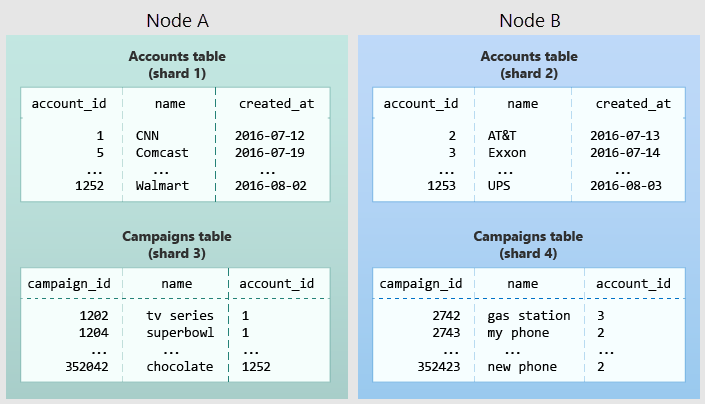
Para aplicar esse design em seu próprio esquema, identifique o que constitui um locatário em seu aplicativo. As instâncias comuns incluem empresa, conta, organização ou cliente. O nome da coluna será algo como company_id ou customer_id. Examine cada uma de suas consultas e pergunte-se: funcionaria se tivesse mais cláusulas WHERE para restringir todas as tabelas envolvidas a linhas com o mesmo ID de locatário? As consultas no modelo multilocatário têm escopo para um locatário. Por exemplo, consultas sobre vendas ou estoque têm escopo dentro de uma determinada loja.
Melhores práticas
- Distribuir tabelas por uma coluna tenant_id comum. Por exemplo, em um aplicativo SaaS onde os locatários são empresas, o tenant_id provavelmente será o company_id.
- Converta pequenas tabelas entre locatários em tabelas de referência. Quando vários locatários compartilham uma pequena tabela de informações, distribua-a como uma tabela de referência.
- Restringir todas as consultas de aplicações usando o tenant_id como filtro. Cada consulta deve solicitar informações para um locatário de cada vez.
Leia o tutorial multilocatário para obter um exemplo de como criar esse tipo de aplicativo.
Aplicações em tempo real
A arquitetura multilocatária introduz uma estrutura hierárquica e usa a colocalização de dados para rotear consultas por locatário. Por outro lado, as arquiteturas em tempo real dependem de propriedades de distribuição específicas de seus dados para obter um processamento altamente paralelo.
Usamos "ID de entidade" como um termo para colunas de distribuição no modelo em tempo real. As entidades típicas são usuários, hosts ou dispositivos.
As consultas em tempo real normalmente pedem agregados numéricos agrupados por data ou categoria. O Azure Cosmos DB para PostgreSQL envia essas consultas para cada fragmento para obter resultados parciais e monta a resposta final no nó coordenador. As consultas são executadas mais rapidamente quando o máximo de nós possível contribui e quando nenhum nó deve realizar uma quantidade desproporcional de trabalho.
Melhores práticas
- Escolha uma coluna com cardinalidade alta como coluna de distribuição. Para comparação, um campo Status em uma tabela de pedidos com valores Novo, Pago e Enviado é uma escolha ruim de coluna de distribuição. Ele assume apenas esses poucos valores, o que limita o número de fragmentos que podem armazenar os dados e o número de nós que podem processá-los. Entre as colunas com alta cardinalidade, também é bom escolher aquelas que são frequentemente usadas em cláusulas de agrupamento ou como chaves de associação.
- Escolha uma coluna com distribuição uniforme. Caso distribua uma tabela numa coluna enviesada para valores comuns específicos, os dados na tabela tendem a acumular-se em determinados fragmentos. Os nós que contêm esses fragmentos acabam fazendo mais trabalho do que outros nós.
- Distribua tabelas de fatos e dimensões em suas colunas comuns. Sua tabela de fatos pode ter apenas uma chave de distribuição. As tabelas que se juntam por outra chave não estarão alocadas junto à tabela de fatos. Escolha uma dimensão para colocalizar com base na frequência com que é unida e no tamanho das linhas de junção.
- Altere algumas tabelas de dimensão em tabelas de referência. Se uma tabela de dimensão não puder ser colocalizada com a tabela de fatos, você poderá melhorar o desempenho da consulta distribuindo cópias da tabela de dimensões para todos os nós na forma de uma tabela de referência.
Leia o tutorial do painel em tempo real para obter um exemplo de como criar esse tipo de aplicação.
Dados de séries cronológicas
Em uma carga de trabalho de série cronológica, os aplicativos consultam informações recentes enquanto arquivam informações antigas.
O erro mais comum na modelagem de informações de séries cronológicas no Azure Cosmos DB para PostgreSQL é usar o próprio carimbo de data/hora como uma coluna de distribuição. Uma distribuição hash baseada no tempo distribui os tempos de maneira aparentemente aleatória por diferentes fragmentos, em vez de manter os intervalos de tempo juntos nos fragmentos. As consultas que envolvem tempo geralmente fazem referência a intervalos de tempo, por exemplo, os dados mais recentes. Este tipo de distribuição hash causa a sobrecarga da rede.
Melhores práticas
- Não escolha um timestamp como coluna de distribuição de dados. Escolha uma coluna de distribuição diferente. Em um aplicativo multilocatário, use a ID do locatário ou, em um aplicativo em tempo real, use a ID da entidade.
- Em vez disso, use o particionamento de tabela PostgreSQL por tempo. Use o particionamento de tabela para dividir uma grande tabela de dados ordenados por tempo em várias tabelas herdadas com cada tabela contendo intervalos de tempo diferentes. A distribuição de uma tabela particionada pelo Postgres cria fragmentos para as tabelas herdadas.
Próximos passos
- Saiba como a colocalização entre dados distribuídos ajuda as consultas a serem executadas rapidamente.
- Descubra a coluna de distribuição de uma tabela distribuída e outras consultas de diagnóstico úteis.