Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a Atividade de Cópia no Azure Data Factory e nos pipelines do Synapse Analytics para copiar dados do Google BigQuery. Ele se baseia no artigo Visão geral da atividade de cópia que apresenta uma visão geral da atividade de cópia.
Importante
O conector do Google BigQuery V2 oferece suporte nativo aprimorado ao Google BigQuery. Se você estiver usando o conector do Google BigQuery V1 em sua solução, atualize seu conector do Google BigQuery, pois o V1 está no estágio de Fim do Suporte. O pipeline deixará de funcionar após 30 de setembro de 2025 se não for atualizado. Consulte esta seção para obter detalhes sobre a diferença entre V2 e V1.
Capacidades suportadas
Este conector do Google BigQuery é compatível com os seguintes recursos:
| Capacidades suportadas | IR |
|---|---|
| Atividade de cópia (fonte/-) | (1) (2) |
| Atividade de Pesquisa | (1) (2) |
(1) Tempo de execução de integração do Azure (2) Tempo de execução de integração auto-hospedado
Para obter uma lista de armazenamentos de dados suportados como fontes ou coletores pela atividade de cópia, consulte a tabela Armazenamentos de dados suportados.
O serviço fornece um driver interno para habilitar a conectividade. Portanto, você não precisa instalar manualmente um driver para usar esse conector.
Nota
Este conector do Google BigQuery é construído sobre as APIs do BigQuery. Lembre-se de que o BigQuery limita a taxa máxima de solicitações recebidas e impõe cotas apropriadas por projeto, consulte Cotas & Limites - solicitações de API. Certifique-se de não acionar muitas solicitações simultâneas para a conta.
Introdução
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao Google BigQuery usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao Google BigQuery na interface do usuário do portal do Azure.
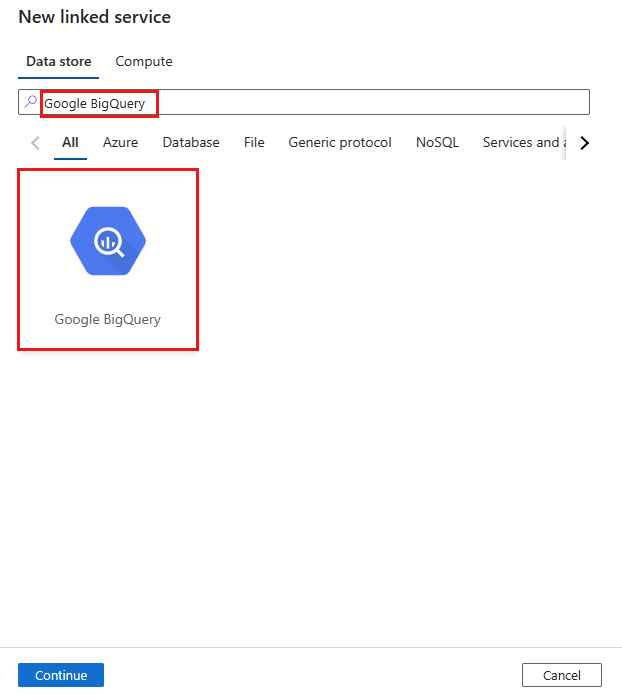
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e clique em Novo:
Pesquise o Google BigQuery e selecione o conector.
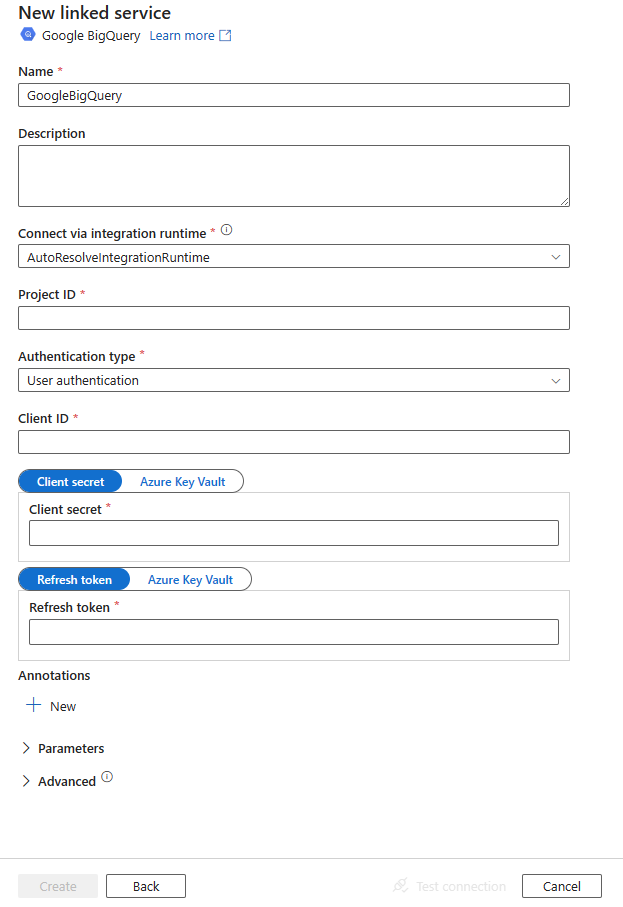
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades específicas para o conector do Google BigQuery.
Propriedades do serviço vinculado
As propriedades a seguir são compatíveis com o serviço vinculado do Google BigQuery.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como GoogleBigQueryV2. | Sim |
| versão | A versão que especificares. Recomendo atualizar para a versão mais recente para aproveitar os aprimoramentos mais recentes. | Sim para a versão 1.1 |
| projectId | A ID do projeto do BigQuery padrão para consulta. | Sim |
| tipo de autenticação | O mecanismo de autenticação OAuth 2.0 usado para autenticação. Os valores permitidos são UserAuthentication e ServiceAuthentication. Consulte as seções abaixo desta tabela sobre mais propriedades e exemplos JSON para esses tipos de autenticação, respectivamente. |
Sim |
Usando a autenticação do usuário
Defina a propriedade "authenticationType" como UserAuthentication e especifique as seguintes propriedades, juntamente com as propriedades genéricas descritas na seção anterior:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| ID do cliente | ID do aplicativo usado para gerar o token de atualização. | Sim |
| clientSecret (segredo do cliente) | Segredo do aplicativo usado para gerar o token de atualização. Marque este campo como um SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. | Sim |
| refreshToken | O token de atualização obtido do Google foi usado para autorizar o acesso ao BigQuery. Saiba como obter um em Obtendo tokens de acesso OAuth 2.0 e neste blog da comunidade. Marque este campo como um SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. | Sim |
Exemplo:
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQueryV2",
"version": "1.1",
"typeProperties": {
"projectId" : "<project ID>",
"authenticationType" : "UserAuthentication",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value":"<client secret>"
},
"refreshToken": {
"type": "SecureString",
"value": "<refresh token>"
}
}
}
}
Usando a autenticação de serviço
Defina a propriedade "authenticationType" como ServiceAuthentication e especifique as seguintes propriedades, juntamente com as propriedades genéricas descritas na seção anterior.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| conteúdoDoFicheiroChave | O arquivo de chave no formato JSON que é usado para autenticar a conta de serviço. Marque este campo como um SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. | Sim |
Exemplo:
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQueryV2",
"version": "1.1",
"typeProperties": {
"projectId": "<project ID>",
"authenticationType": "ServiceAuthentication",
"keyFileContent": {
"type": "SecureString",
"value": "<key file JSON string>"
}
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte o artigo Conjuntos de dados. Esta seção fornece uma lista de propriedades compatíveis com o conjunto de dados do Google BigQuery.
Para copiar dados do Google BigQuery, defina a propriedade type do conjunto de dados como GoogleBigQueryV2Object. As seguintes propriedades são suportadas:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como: GoogleBigQueryV2Object | Sim |
| conjunto de dados | Nome do conjunto de dados do Google BigQuery. | Não (se "consulta" na fonte da atividade for especificado) |
| tabela | Nome da tabela. | Não (se "consulta" na fonte da atividade for especificado) |
Exemplo
{
"name": "GoogleBigQueryDataset",
"properties": {
"type": "GoogleBigQueryV2Object",
"linkedServiceName": {
"referenceName": "<Google BigQuery linked service name>",
"type": "LinkedServiceReference"
},
"schema": [],
"typeProperties": {
"dataset": "<dataset name>",
"table": "<table name>"
}
}
}
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades compatíveis com o tipo de fonte do Google BigQuery.
GoogleBigQuerySource como um tipo de fonte
Para copiar dados do Google BigQuery, defina o tipo de origem na atividade de cópia como GoogleBigQueryV2Source. As propriedades a seguir são suportadas na seção copiar fonte de atividade.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como GoogleBigQueryV2Source. | Sim |
| consulta | Use a consulta SQL personalizada para ler dados. Um exemplo é "SELECT * FROM MyTable". Para obter mais informações, vá para Sintaxe de consulta. |
Não (se "conjunto de dados" e "tabela" no conjunto de dados forem especificados) |
Exemplo:
"activities":[
{
"name": "CopyFromGoogleBigQuery",
"type": "Copy",
"inputs": [
{
"referenceName": "<Google BigQuery input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "GoogleBigQueryV2Source",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Propriedades da atividade de pesquisa
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Ciclo de vida e atualização do conector do Google BigQuery
A tabela a seguir mostra o estágio de lançamento e os registos de alterações para diferentes versões do conector do Google BigQuery.
| Versão | Fase de lançamento | Registo de alterações |
|---|---|---|
| Google BigQuery V1 | Fim do suporte | / |
| Google BigQuery V2 (versão 1.0) | Versão GA disponível | • A autenticação de serviço é suportada pelo runtime de integração do Azure e pelo runtime de integração autónomo. As propriedades trustedCertPath, useSystemTrustStore, email e keyFilePath não são suportadas, pois estão disponíveis apenas no runtime de integração auto-hospedado. requestGoogleDriveScope• não é suportado. Além disso, você precisa aplicar a permissão no serviço Google BigQuery consultando os escopos da API do Google Drive e os dados do Query Drive. additionalProjects• não é suportado. Como alternativa, consulte um conjunto de dados público com o console do Google Cloud.• NUMBER é lido como Tipo de Dados Decimal. • Timestamp e Datetime são lidos como tipo de dados DateTimeOffset. |
| Google BigQuery V2 (versão 1.1) | Versão GA disponível | • Corrigido um bug: ao executar várias declarações, o query agora retorna os resultados da primeira declaração depois de excluir as declarações de avaliação, em vez de sempre retornar o resultado da primeira declaração. |
Atualizar o conector do Google BigQuery
Para atualizar o conector do Google BigQuery:
De V1 a V2:
Crie um novo serviço vinculado do Google BigQuery e configure-o consultando as propriedades do serviço vinculado.Da versão 1.0 da V2 para a versão 1.1:
Na página Editar serviço vinculado , selecione 1.1 para versão. Para obter mais informações, consulte Propriedades do serviço vinculado.
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados suportados como fontes e coletores pela atividade de cópia, consulte Armazenamentos de dados suportados.