Copiar dados de ou para o MongoDB usando o Azure Data Factory ou o Synapse Analytics
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a Atividade de Cópia nos pipelines do Azure Data Factory Synapse Analytics para copiar dados de e para um banco de dados MongoDB. Ele se baseia no artigo de visão geral da atividade de cópia que apresenta uma visão geral da atividade de cópia.
Importante
O novo conector MongoDB oferece suporte nativo aprimorado ao MongoDB. Se você estiver usando o conector MongoDB herdado em sua solução, suportado como está apenas para compatibilidade com versões anteriores, consulte o artigo Conector MongoDB (legado).
Capacidades suportadas
Este conector MongoDB é suportado para os seguintes recursos:
| Capacidades suportadas | IR |
|---|---|
| Atividade de cópia (origem/coletor) | (1) (2) |
(1) Tempo de execução de integração do Azure (2) Tempo de execução de integração auto-hospedado
Para obter uma lista de armazenamentos de dados suportados como fontes/coletores, consulte a tabela Armazenamentos de dados suportados.
Especificamente, este conector MongoDB suporta versões até 4.2. Se o seu trabalho requer versões mais recentes do que a 4.2, considere usar o MongoDB Atlas com o conector MongoDB Atlas, que fornece suporte e recursos mais abrangentes.
Pré-requisitos
Se seu armazenamento de dados estiver localizado dentro de uma rede local, uma rede virtual do Azure ou a Amazon Virtual Private Cloud, você precisará configurar um tempo de execução de integração auto-hospedado para se conectar a ele.
Se o seu armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Tempo de Execução de Integração do Azure. Se o acesso for restrito a IPs aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
Você também pode usar o recurso de tempo de execução de integração de rede virtual gerenciada no Azure Data Factory para acessar a rede local sem instalar e configurar um tempo de execução de integração auto-hospedado.
Para obter mais informações sobre os mecanismos de segurança de rede e as opções suportadas pelo Data Factory, consulte Estratégias de acesso a dados.
Introdução
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao MongoDB usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao MongoDB na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e clique em Novo:
Procure MongoDB e selecione o conector MongoDB.
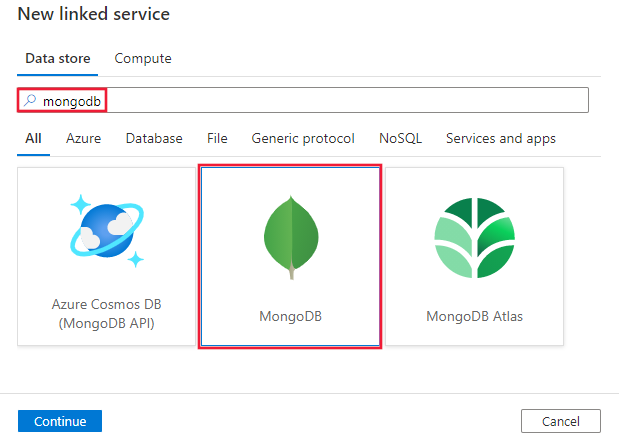
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
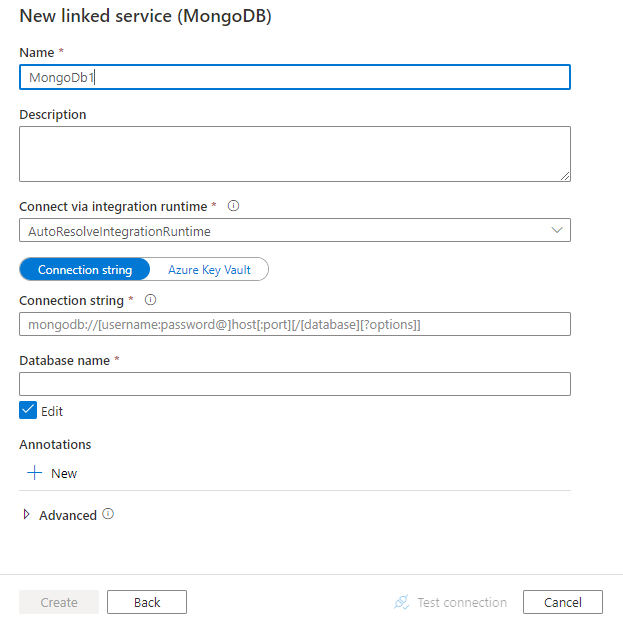
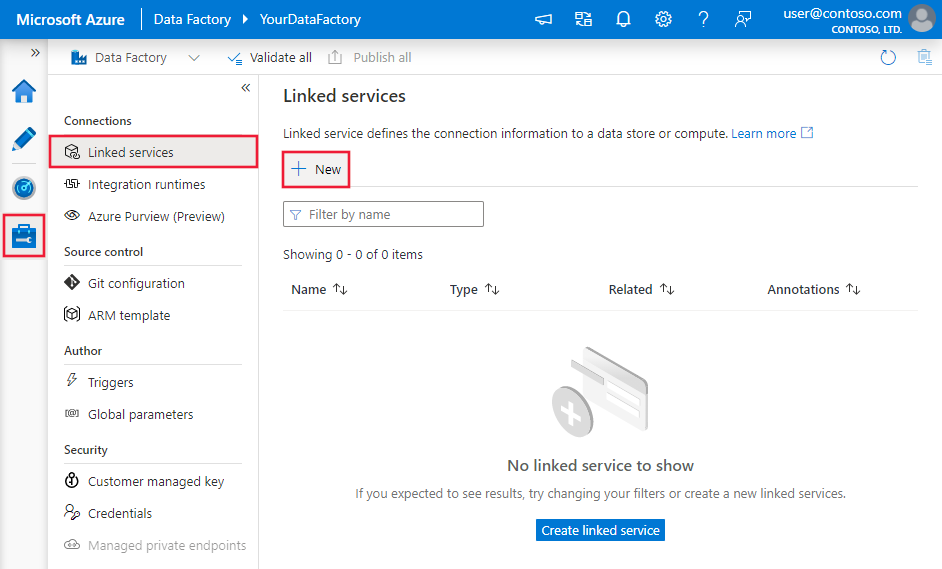
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas para o conector MongoDB.
Propriedades do serviço vinculado
As seguintes propriedades são suportadas para o serviço vinculado MongoDB:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como: MongoDbV2 | Sim |
| connectionString | Especifique a cadeia de conexão MongoDB, por exemplo. mongodb://[username:password@]host[:port][/[database][?options]] Consulte o manual do MongoDB sobre cadeia de conexão para obter mais detalhes. Você também pode colocar uma cadeia de conexão no Cofre da Chave do Azure. Consulte Armazenar credenciais no Azure Key Vault com mais detalhes. |
Sim |
| base de dados | Nome do banco de dados que você deseja acessar. | Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos . Se não for especificado, ele usará o Tempo de Execução de Integração do Azure padrão. | Não |
Exemplo:
{
"name": "MongoDBLinkedService",
"properties": {
"type": "MongoDbV2",
"typeProperties": {
"connectionString": "mongodb://[username:password@]host[:port][/[database][?options]]",
"database": "myDatabase"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte Conjuntos de dados e serviços vinculados. As seguintes propriedades são suportadas para o conjunto de dados MongoDB:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como: MongoDbV2Collection | Sim |
| collectionName | Nome da coleção no banco de dados MongoDB. | Sim |
Exemplo:
{
"name": "MongoDbDataset",
"properties": {
"type": "MongoDbV2Collection",
"typeProperties": {
"collectionName": "<Collection name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<MongoDB linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades suportadas pela fonte e pelo coletor do MongoDB.
MongoDB como fonte
As seguintes propriedades são suportadas na seção de origem da atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como: MongoDbV2Source | Sim |
| filtrar | Especifica o filtro de seleção usando operadores de consulta. Para retornar todos os documentos de uma coleção, omita esse parâmetro ou passe um documento vazio ({}). | Não |
| cursorMethods.project | Especifica os campos a serem retornados nos documentos para projeção. Para retornar todos os campos nos documentos correspondentes, omita esse parâmetro. | Não |
| cursorMethods.sort | Especifica a ordem na qual a consulta retorna documentos correspondentes. Consulte cursor.sort(). | Não |
| cursorMethods.limit | Especifica o número máximo de documentos retornados pelo servidor. Consulte cursor.limit(). | Não |
| cursorMethods.skip | Especifica o número de documentos a serem ignorados e de onde o MongoDB começa a retornar resultados. Consulte cursor.skip(). | Não |
| batchSize | Especifica o número de documentos a serem retornados em cada lote da resposta da instância do MongoDB. Na maioria dos casos, modificar o tamanho do lote não afetará o usuário ou o aplicativo. Os limites do Azure Cosmos DB para cada lote não podem exceder 40 MB de tamanho, que é a soma do número batchSize do tamanho dos documentos, portanto, diminua esse valor se o tamanho do documento for grande. | Não (o padrão é 100) |
Gorjeta
O serviço suporta o consumo de documento BSON no modo estrito. Verifique se a consulta de filtro está no modo Estrito em vez do modo Shell. Mais descrição pode ser encontrada no manual do MongoDB.
Exemplo:
"activities":[
{
"name": "CopyFromMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<MongoDB input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "MongoDbV2Source",
"filter": "{datetimeData: {$gte: ISODate(\"2018-12-11T00:00:00.000Z\"),$lt: ISODate(\"2018-12-12T00:00:00.000Z\")}, _id: ObjectId(\"5acd7c3d0000000000000000\") }",
"cursorMethods": {
"project": "{ _id : 1, name : 1, age: 1, datetimeData: 1 }",
"sort": "{ age : 1 }",
"skip": 3,
"limit": 3
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
MongoDB como pia
As seguintes propriedades são suportadas na seção Copiar coletor de atividade:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do coletor Copy Activity deve ser definida como MongoDbV2Sink. | Sim |
| writeBehavior | Descreve como gravar dados no MongoDB. Valores permitidos: inserir e upsert. O comportamento do upsert é substituir o documento se já existir um documento com o mesmo _id , caso contrário, insira o documento.Nota: O serviço gera automaticamente um _id para um documento se um _id não for especificado no documento original ou por mapeamento de coluna. Isso significa que você deve garantir que, para que o upsert funcione conforme o esperado, seu documento tenha um ID. |
Não (o padrão é inserir) |
| writeBatchSize | A propriedade writeBatchSize controla o tamanho dos documentos a serem gravados em cada lote. Você pode tentar aumentar o valor de writeBatchSize para melhorar o desempenho e diminuir o valor se o tamanho do documento for grande. | Não (o padrão é 10.000) |
| writeBatchTimeout | O tempo de espera para que a operação de inserção de lote termine antes que ela atinja o tempo limite. O valor permitido é timepan. | Não (o padrão é 00:30:00 - 30 minutos) |
Gorjeta
Para importar documentos JSON no estado em que se encontram, consulte a seção Importar ou exportar documentos JSON; para copiar de dados em forma de tabela, consulte Mapeamento de esquema.
Exemplo
"activities":[
{
"name": "CopyToMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Document DB output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "MongoDbV2Sink",
"writeBehavior": "upsert"
}
}
}
]
Importar e exportar documentos JSON
Você pode usar este conector MongoDB para facilmente:
- Copie documentos entre duas coleções do MongoDB no estado em que se encontram.
- Importe documentos JSON de várias fontes para o MongoDB, incluindo do Azure Cosmos DB, do armazenamento de Blobs do Azure, do Azure Data Lake Store e de outros armazenamentos baseados em arquivos com suporte.
- Exporte documentos JSON de uma coleção MongoDB para vários repositórios baseados em arquivos.
Para obter essa cópia agnóstica de esquema, ignore a seção "estrutura" (também chamada de esquema) no conjunto de dados e o mapeamento de esquema na atividade de cópia.
Mapeamento de esquema
Para copiar dados do MongoDB para o coletor tabular ou invertido, consulte o mapeamento de esquema.
Atualizar o serviço vinculado do MongoDB
Aqui estão as etapas que ajudam você a atualizar seu serviço vinculado e consultas relacionadas:
Crie um novo serviço vinculado do MongoDB e configure-o consultando as propriedades do serviço vinculado.
Se você usar consultas SQL em seus pipelines que se referem ao antigo serviço vinculado do MongoDB, substitua-as pelas consultas equivalentes do MongoDB. Consulte a tabela a seguir para obter os exemplos de substituição:
Consulta SQL Consulta equivalente do MongoDB SELECT * FROM usersdb.users.find({})SELECT username, age FROM usersdb.users.find({}, {username: 1, age: 1})SELECT username AS User, age AS Age, statusNumber AS Status, CASE WHEN Status = 0 THEN "Pending" CASE WHEN Status = 1 THEN "Finished" ELSE "Unknown" END AS statusEnum LastUpdatedTime + interval '2' hour AS NewLastUpdatedTime FROM usersdb.users.aggregate([{ $project: { _id: 0, User: "$username", Age: "$age", Status: "$statusNumber", statusEnum: { $switch: { branches: [ { case: { $eq: ["$Status", 0] }, then: "Pending" }, { case: { $eq: ["$Status", 1] }, then: "Finished" } ], default: "Unknown" } }, NewLastUpdatedTime: { $add: ["$LastUpdatedTime", 2 * 60 * 60 * 1000] } } }])SELECT employees.name, departments.name AS department_name FROM employees LEFT JOIN departments ON employees.department_id = departments.id;db.employees.aggregate([ { $lookup: { from: "departments", localField: "department_id", foreignField: "_id", as: "department" } }, { $unwind: "$department" }, { $project: { _id: 0, name: 1, department_name: "$department.name" } } ])
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados suportados como fontes e coletores pela atividade de cópia, consulte Armazenamentos de dados suportados.