Usar o Kit de Ferramentas do Azure para IntelliJ para depurar aplicativos Apache Spark remotamente no HDInsight por meio de VPN
Recomendamos depurar aplicativos Apache Spark remotamente por meio de SSH. Para obter instruções, consulte Depurar remotamente aplicativos Apache Spark em um cluster HDInsight com o Kit de Ferramentas do Azure para IntelliJ por meio de SSH.
Este artigo fornece orientação passo a passo sobre como usar as Ferramentas HDInsight no Kit de Ferramentas do Azure para IntelliJ para enviar um trabalho do Spark em um cluster do HDInsight Spark e, em seguida, depurá-lo remotamente do seu computador desktop. Para concluir essas tarefas, você deve executar as seguintes etapas de alto nível:
- Crie uma rede virtual do Azure site a site ou ponto a site. As etapas neste documento pressupõem que você use uma rede site a site.
- Crie um cluster do Spark no HDInsight que faça parte da rede virtual site a site.
- Verifique a conectividade entre o nó principal do cluster e a área de trabalho.
- Crie um aplicativo Scala no IntelliJ IDEA e configure-o para depuração remota.
- Execute e depure o aplicativo.
Pré-requisitos
- Uma subscrição do Azure. Para obter mais informações, consulte Obter uma avaliação gratuita do Azure.
- Um cluster Apache Spark no HDInsight. Para obter instruções, veja Criar clusters do Apache Spark no Azure HDInsight.
- Kit de desenvolvimento Oracle Java. Você pode instalá-lo a partir do site da Oracle.
- IntelliJ IDEA. Este artigo usa a versão 2017.1. Você pode instalá-lo a partir do site da JetBrains.
- Ferramentas do HDInsight no Kit de Ferramentas do Azure para IntelliJ. As ferramentas do HDInsight para IntelliJ estão disponíveis como parte do Kit de Ferramentas do Azure para IntelliJ. Para obter instruções sobre como instalar o Kit de Ferramentas do Azure, consulte Instalar o Kit de Ferramentas do Azure para IntelliJ.
- Inicie sessão na sua Subscrição do Azure a partir do IntelliJ IDEA. Siga as instruções em Usar o Kit de Ferramentas do Azure para IntelliJ para criar aplicativos Apache Spark para um cluster HDInsight.
- Solução alternativa de exceção. Ao executar o aplicativo Spark Scala para depuração remota em um computador Windows, você pode obter uma exceção. Essa exceção é explicada no SPARK-2356 e ocorre devido a um arquivo de WinUtils.exe ausente no Windows. Para contornar esse erro, você deve baixar Winutils.exe para um local como C:\WinUtils\bin. Adicione uma variável de ambiente HADOOP_HOME e, em seguida, defina o valor da variável como C:\WinUtils.
Etapa 1: Criar uma rede virtual do Azure
Siga as instruções dos links a seguir para criar uma rede virtual do Azure e verifique a conectividade entre seu computador desktop e a rede virtual:
- Criar uma rede virtual com uma conexão VPN site a site usando o portal do Azure
- Criar uma rede virtual com uma conexão VPN site a site usando o PowerShell
- Configurar uma conexão ponto a site com uma rede virtual usando o PowerShell
Etapa 2: Criar um cluster HDInsight Spark
Recomendamos que você também crie um cluster Apache Spark no Azure HDInsight que faça parte da rede virtual do Azure que você criou. Use as informações disponíveis em Criar clusters baseados em Linux no HDInsight. Como parte da configuração opcional, selecione a rede virtual do Azure que você criou na etapa anterior.
Etapa 3: Verificar a conectividade entre o nó principal do cluster e sua área de trabalho
Obtenha o endereço IP do nó principal. Abra a interface do usuário do Ambari para o cluster. Na folha do cluster, selecione Painel.
Na interface do usuário do Ambari, selecione Hosts.

Você vê uma lista de nós principais, nós de trabalho e nós de zookeeper. Os nós principais têm um prefixo hn*. Selecione o primeiro nó principal.
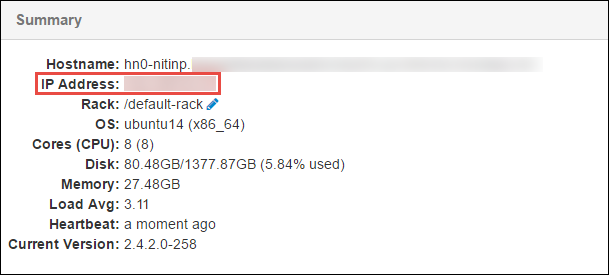
No painel Resumo na parte inferior da página que é aberta, copie o Endereço IP do nó principal e o Nome do host.
Adicione o endereço IP e o nome do host do nó principal ao arquivo hosts no computador onde você deseja executar e depurar remotamente o trabalho do Spark. Isso permite que você se comunique com o nó principal usando o endereço IP, bem como o nome do host.
a. Abra um arquivo do Bloco de Notas com permissões elevadas. No menu Arquivo, selecione Abrir e localize o local do arquivo hosts. Em um computador Windows, o local é C:\Windows\System32\Drivers\etc\hosts.
b. Adicione as seguintes informações ao arquivo hosts :
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netNo computador que você conectou à rede virtual do Azure usada pelo cluster HDInsight, verifique se você pode executar ping nos nós principais usando o endereço IP, bem como o nome do host.
Use SSH para se conectar ao nó principal do cluster seguindo as instruções em Conectar a um cluster HDInsight usando SSH. No nó principal do cluster, execute ping no endereço IP do computador desktop. Teste a conectividade com ambos os endereços IP atribuídos ao computador:
- Um para a conexão de rede
- Um para a rede virtual do Azure
Repita as etapas para o outro nó principal.
Etapa 4: Criar um aplicativo Apache Spark Scala usando as Ferramentas HDInsight no Kit de Ferramentas do Azure para IntelliJ e configurá-lo para depuração remota
Abra o IntelliJ IDEA e crie um novo projeto. Na caixa de diálogo Novo Projeto, faça o seguinte:
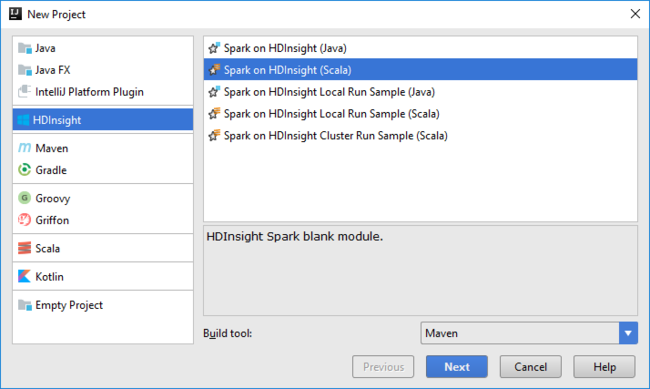
a. Selecione HDInsight>Spark no HDInsight (Scala).
b. Selecione Seguinte.
Na próxima caixa de diálogo Novo Projeto , faça o seguinte e selecione Concluir:
Introduza um nome do projeto e localização.
Na lista pendente SDK do Projeto, selecione Java 1.8 para o cluster do Spark 2.x ou selecione Java 1.7 para o cluster do Spark 1.x.
Na lista suspensa Versão do Spark , o assistente de criação de projeto do Scala integra a versão adequada para o SDK do Spark e o SDK do Scala. Se a versão do cluster do Spark for anterior à 2.0, selecione Spark 1.x. Caso contrário, selecione Spark2.x. Este exemplo utiliza o Spark 2.0.2 (Scala 2.11.8).
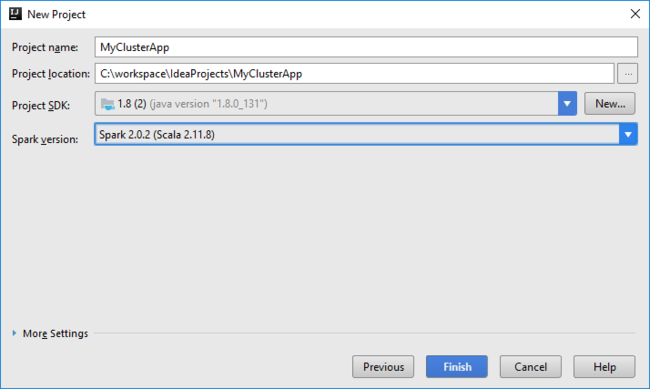
O projeto Spark cria automaticamente um artefato para você. Para exibir o artefato, faça o seguinte:
a. No menu File (Ficheiro), selecione Project Structure (Estrutura do Projeto).
b. Na caixa de diálogo Estrutura do Projeto , selecione Artefatos para exibir o artefato padrão criado. Você também pode criar seu próprio artefato selecionando o sinal de adição (+).
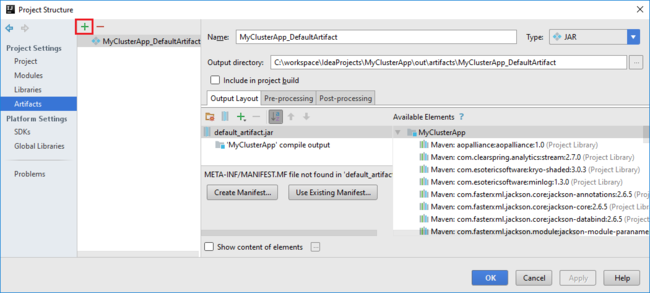
Adicione bibliotecas ao seu projeto. Para adicionar uma biblioteca, faça o seguinte:
a. Clique com o botão direito do mouse no nome do projeto na árvore do projeto e selecione Abrir configurações do módulo.
b. Na caixa de diálogo Estrutura do projeto, selecione Bibliotecas, selecione o símbolo (+) e, em seguida, selecione Do Maven.
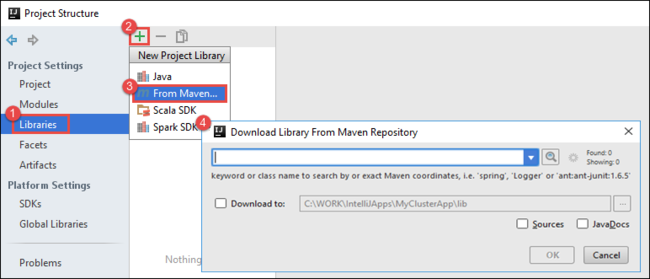
c. Na caixa de diálogo Baixar biblioteca do repositório Maven, procure e adicione as seguintes bibliotecas:
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
Copie
yarn-site.xmlecore-site.xmldo nó principal do cluster e adicione-os ao projeto. Use os seguintes comandos para copiar os arquivos. Você pode usar Cygwin para executar os seguintesscpcomandos para copiar os arquivos dos nós principais do cluster:scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .Como já adicionamos o endereço IP do nó principal do cluster e os nomes de host para o arquivo hosts na área de trabalho, podemos usar os
scpcomandos da seguinte maneira:scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .Para adicionar esses arquivos ao seu projeto, copie-os na pasta /src na árvore do projeto, por exemplo
<your project directory>\src.Atualize o
core-site.xmlarquivo para fazer as seguintes alterações:a. Substitua a chave encriptada. O
core-site.xmlficheiro inclui a chave encriptada para a conta de armazenamento associada ao cluster.core-site.xmlNo arquivo que você adicionou ao projeto, substitua a chave criptografada pela chave de armazenamento real associada à conta de armazenamento padrão. Para obter mais informações, consulte Gerenciar chaves de acesso da conta de armazenamento.<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b. Remova as seguintes entradas de
core-site.xml:<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>c. Guarde o ficheiro.
Adicione a classe principal para seu aplicativo. No Explorador de Projetos, clique com o botão direito do mouse em src, aponte para Novo e selecione Classe Scala.
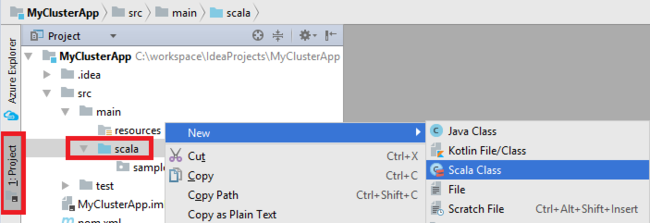
Na caixa de diálogo Criar Nova Classe Scala, forneça um nome, selecione Objeto na caixa Tipo e selecione OK.
MyClusterAppMain.scalaNo arquivo, cole o código a seguir. Esse código cria o contexto do Spark e abre umexecuteJobmétodo doSparkSampleobjeto.import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Repita as etapas 8 e 9 para adicionar um novo objeto Scala chamado
*SparkSample. Adicione o seguinte código a esta classe. Esse código lê os dados do HVAC.csv (disponível em todos os clusters HDInsight Spark). Ele recupera as linhas que têm apenas um dígito na sétima coluna no arquivo CSV e, em seguida, grava a saída em /HVACOut no contêiner de armazenamento padrão para o cluster.import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }Repita as etapas 8 e 9 para adicionar uma nova classe chamada
RemoteClusterDebugging. Essa classe implementa a estrutura de teste do Spark que é usada para depurar os aplicativos. Adicione o seguinte código àRemoteClusterDebuggingclasse:import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Há algumas coisas importantes a observar:
- Para
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar"), verifique se o JAR do assembly do Spark está disponível no armazenamento de cluster no caminho especificado. - Para
setJars, especifique o local onde o artefato JAR é criado. Normalmente, é<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jar.
- Para
Na classe, clique com o
*RemoteClusterDebuggingbotão direito do mouse natestpalavra-chave e selecione Create RemoteClusterDebugging Configuration.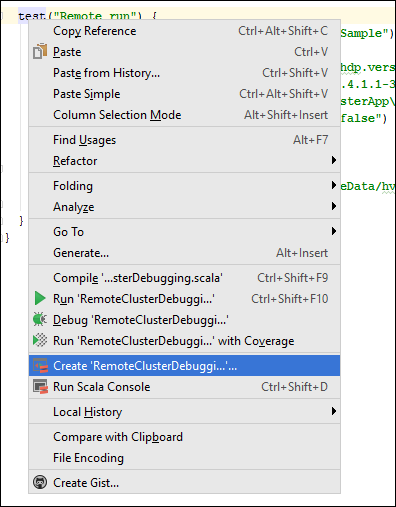
Na caixa de diálogo Criar Configuração de Depuração RemoteCluster, forneça um nome para a configuração e selecione Tipo de teste como o Nome do teste. Deixe todos os outros valores como as configurações padrão. Selecione Aplicar e, em seguida, selecione OK.
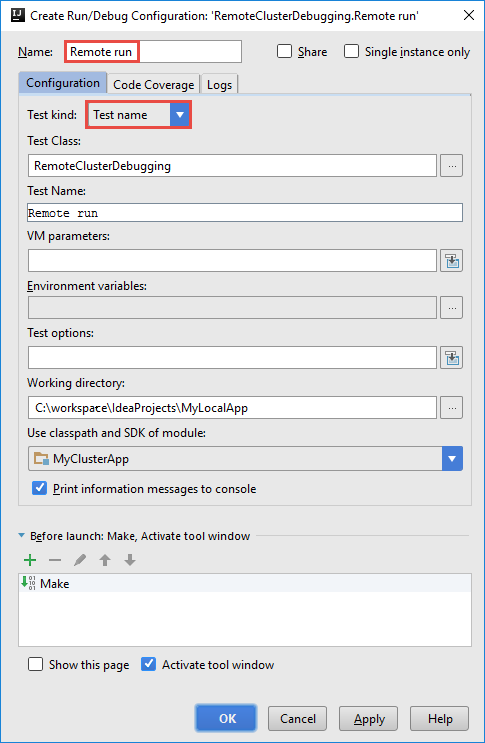
Agora você verá uma lista suspensa Configuração de execução remota na barra de menus.

Etapa 5: Executar o aplicativo no modo de depuração
No seu projeto IntelliJ IDEA, abra
SparkSample.scalae crie um ponto de interrupção ao lado deval rdd1. No menu pop-up Criar ponto de interrupção para, selecione linha na função executeJob.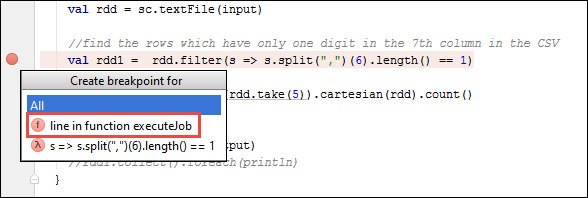
Para executar o aplicativo, selecione o botão Depurar Executar ao lado da lista suspensa Configuração de Execução Remota.

Quando a execução do programa atinge o ponto de interrupção, você vê uma guia Depurador no painel inferior.
Para adicionar um relógio, selecione o ícone (+).
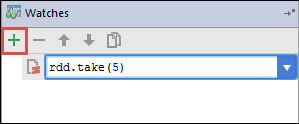
Neste exemplo, o aplicativo quebrou antes que a variável
rdd1fosse criada. Usando este relógio, podemos ver as primeiras cinco linhas na variávelrdd. Selecione Enter.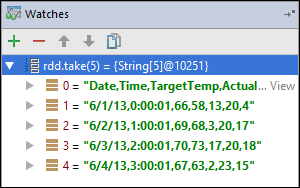
O que você vê na imagem anterior é que, em tempo de execução, você pode consultar terabytes de dados e depurar como seu aplicativo progride. Por exemplo, na saída mostrada na imagem anterior, você pode ver que a primeira linha da saída é um cabeçalho. Com base nessa saída, você pode modificar o código do aplicativo para ignorar a linha de cabeçalho, se necessário.
Agora você pode selecionar o ícone Programa de Retomada para prosseguir com a execução do aplicativo.
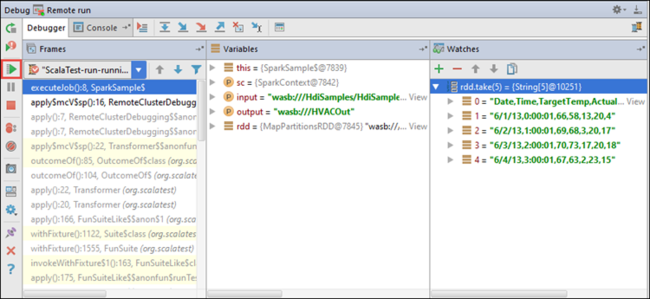
Se o aplicativo for concluído com êxito, você verá a saída como a seguinte:
Próximos passos
Cenários
- Apache Spark com BI: execute análises de dados interativas usando o Spark no HDInsight com ferramentas de BI
- Apache Spark com Machine Learning: use o Spark no HDInsight para analisar a temperatura do edifício usando dados de HVAC
- Apache Spark com Machine Learning: use o Spark no HDInsight para prever resultados de inspeção de alimentos
- Análise de log do site usando o Apache Spark no HDInsight
Criar e executar aplicações
- Criar uma aplicação autónoma com o Scala
- Executar trabalhos remotamente em um cluster Apache Spark usando o Apache Livy
Ferramentas e extensões
- Usar o Kit de Ferramentas do Azure para IntelliJ para criar aplicativos Apache Spark para um cluster HDInsight
- Use o Kit de Ferramentas do Azure para IntelliJ para depurar aplicativos Apache Spark remotamente por meio de SSH
- Usar as Ferramentas do HDInsight no Kit de Ferramentas do Azure para Eclipse para criar aplicativos Apache Spark
- Usar blocos de anotações Apache Zeppelin com um cluster Apache Spark no HDInsight
- Kernels disponíveis para o Jupyter Notebook em um cluster Apache Spark para HDInsight
- Use pacotes externos com o Jupyter Notebooks
- Instalar o Jupyter no computador e ligar a um cluster do Spark do HDInsight
Gerir recursos
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários