Componente Preparar Modelo
Este artigo descreve um componente no estruturador do Azure Machine Learning.
Utilize este componente para preparar um modelo de classificação ou regressão. A preparação ocorre depois de definir um modelo e definir os respetivos parâmetros e requer dados etiquetados. Também pode utilizar Preparar Modelo para preparar novamente um modelo existente com novos dados.
Como funciona o processo de preparação
No Azure Machine Learning, criar e utilizar um modelo de machine learning é normalmente um processo de três passos.
Pode configurar um modelo ao escolher um determinado tipo de algoritmo e definir os respetivos parâmetros ou hiperparâmetros. Escolha qualquer um dos seguintes tipos de modelo:
- Modelos de classificação , com base em redes neurais, árvores de decisões e florestas de decisões e outros algoritmos.
- Modelos de regressão , que podem incluir a regressão linear padrão ou que utilizam outros algoritmos, incluindo redes neurais e regressão bayesiana.
Forneça um conjunto de dados etiquetado e que tenha dados compatíveis com o algoritmo. Ligue os dados e o modelo ao Modelo de Preparação.
O que a preparação produz é um formato binário específico, o iLearner, que encapsula os padrões estatísticos aprendidos com os dados. Não pode modificar ou ler diretamente este formato; no entanto, outros componentes podem utilizar este modelo preparado.
Também pode ver as propriedades do modelo. Para obter mais informações, consulte a secção Resultados.
Após a conclusão da preparação, utilize o modelo preparado com um dos componentes de classificação para fazer predições em novos dados.
Como utilizar o Modelo de Preparação
Adicione o componente Train Model (Preparar Modelo ) ao pipeline. Pode encontrar este componente na categoria Machine Learning . Expanda Preparar e, em seguida, arraste o componente Preparar Modelo para o pipeline.
Na entrada esquerda, anexe o modo não preparado. Anexe o conjunto de dados de preparação à entrada à direita de Train Model (Preparar Modelo).
O conjunto de dados de preparação tem de conter uma coluna de etiqueta. Todas as linhas sem etiquetas são ignoradas.
Na coluna Etiqueta, clique em Editar coluna no painel direito do componente e escolha uma única coluna que contenha resultados que o modelo possa utilizar para preparação.
Para problemas de classificação, a coluna de etiquetas tem de conter valores categóricos ou valores discretos . Alguns exemplos podem ser uma classificação sim/não, um nome ou código de classificação de doenças ou um grupo de rendimentos. Se escolher uma coluna nãocategoria, o componente devolverá um erro durante a preparação.
Para problemas de regressão, a coluna de etiquetas tem de conter dados numéricos que representem a variável de resposta. Idealmente, os dados numéricos representam uma escala contínua.
Os exemplos podem ser uma classificação de risco de crédito, o tempo previsto para a falha de um disco rígido ou o número previsto de chamadas para um call center num determinado dia ou hora. Se não escolher uma coluna numérica, poderá obter um erro.
- Se não especificar a coluna de etiqueta a utilizar, o Azure Machine Learning tentará inferir qual é a coluna de etiqueta adequada ao utilizar os metadados do conjunto de dados. Se escolher a coluna errada, utilize o seletor de colunas para a corrigir.
Dica
Se tiver problemas ao utilizar o Seletor de Colunas, consulte o artigo Selecionar Colunas no Conjunto de Dados para obter sugestões. Descreve alguns cenários e sugestões comuns para utilizar as opções COM REGRAS e POR NOME .
Submeta o pipeline. Se tiver muitos dados, pode demorar algum tempo.
Importante
Se tiver uma coluna de ID que seja o ID de cada linha ou uma coluna de texto que contenha demasiados valores exclusivos, o Modelo de Preparação poderá obter um erro como "Número de valores exclusivos na coluna: "{column_name}" é maior do que o permitido.
Isto acontece porque a coluna atingiu o limiar de valores exclusivos e pode causar memória insuficiente. Pode utilizar Editar Metadados para marcar essa coluna como funcionalidade Limpar e esta não será utilizada na preparação ou Extrair Funcionalidades N-Gramas do componente Texto para pré-processar a coluna de texto. Veja Designer código de erro para obter mais detalhes sobre o erro.
Capacidade de Interpretação de Modelos
A interpretação de modelos permite compreender o modelo de ML e apresentar a base subjacente à tomada de decisões de uma forma que seja compreensível para os seres humanos.
Atualmente, o componente Train Model suporta a utilização do pacote de interpretação para explicar os modelos de ML. São suportados os seguintes algoritmos incorporados:
- Regressão Linear
- Regressão da Rede Neural
- Regressão da Árvore de Decisão Aumentada
- Regressão da Floresta de Decisão
- Regressão de Poisson
- Regressão Logística de Duas Classes
- Máquina de Vetores de Suporte de Duas Classes
- árvore de decisão Two-Class aumentada
- Floresta de Decisão de Duas Classes
- Floresta de Decisões multiclasse
- Regressão Logística multiclasse
- Rede Neural multiclasse
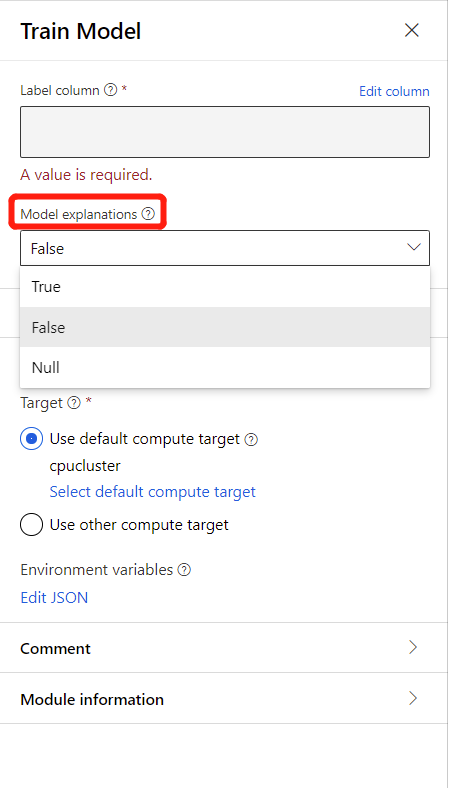
Para gerar explicações de modelos, pode selecionar Verdadeiro na lista pendente de Explicação do Modelo no componente Preparar Modelo. Por predefinição, está definido como Falso no componente Preparar Modelo . Tenha em atenção que gerar explicação requer custos de computação adicionais.
Após a conclusão da execução do pipeline, pode visitar o separador Explicações no painel direito do componente Preparar Modelo e explorar o desempenho do modelo, o conjunto de dados e a importância da funcionalidade.
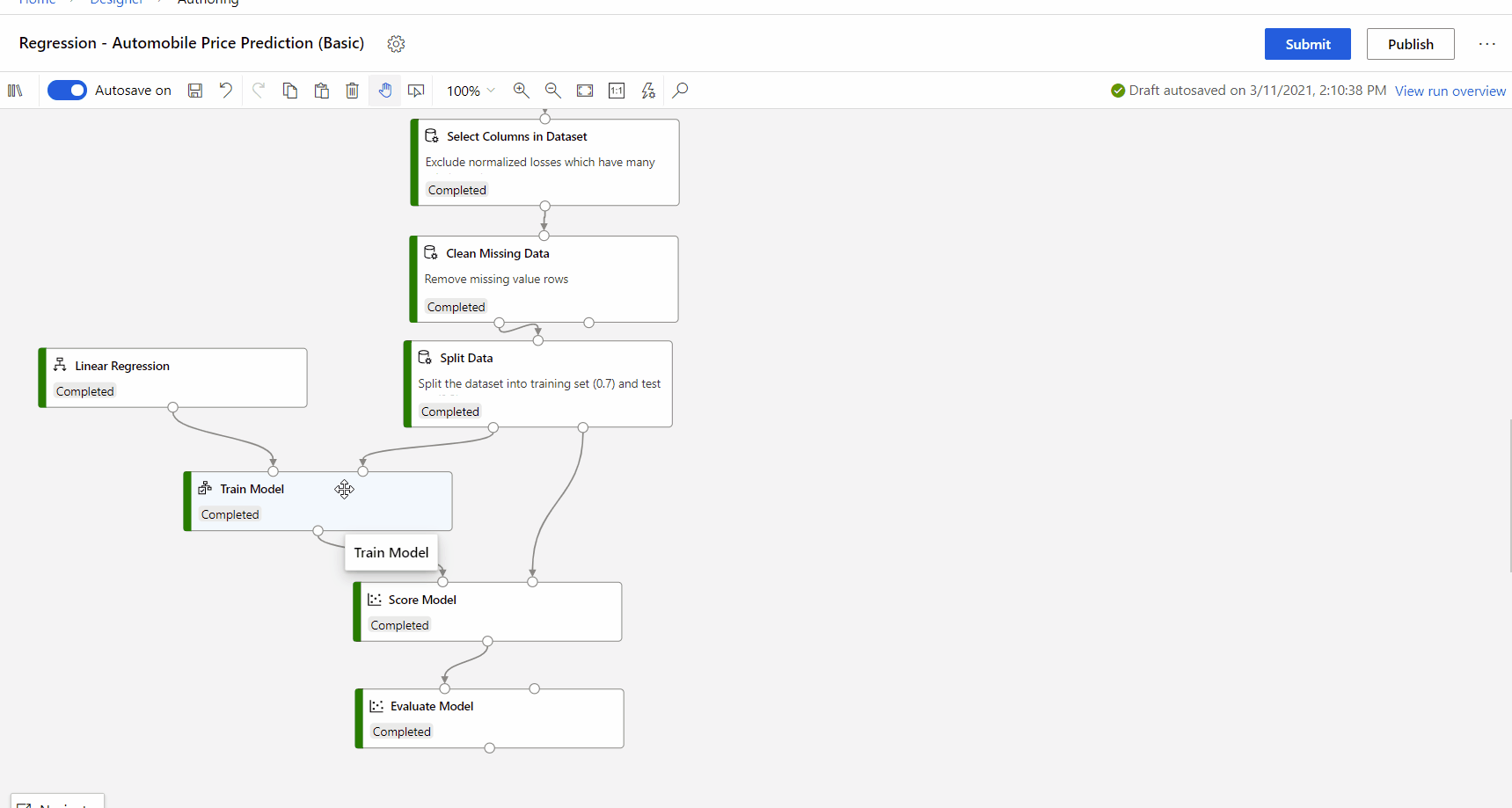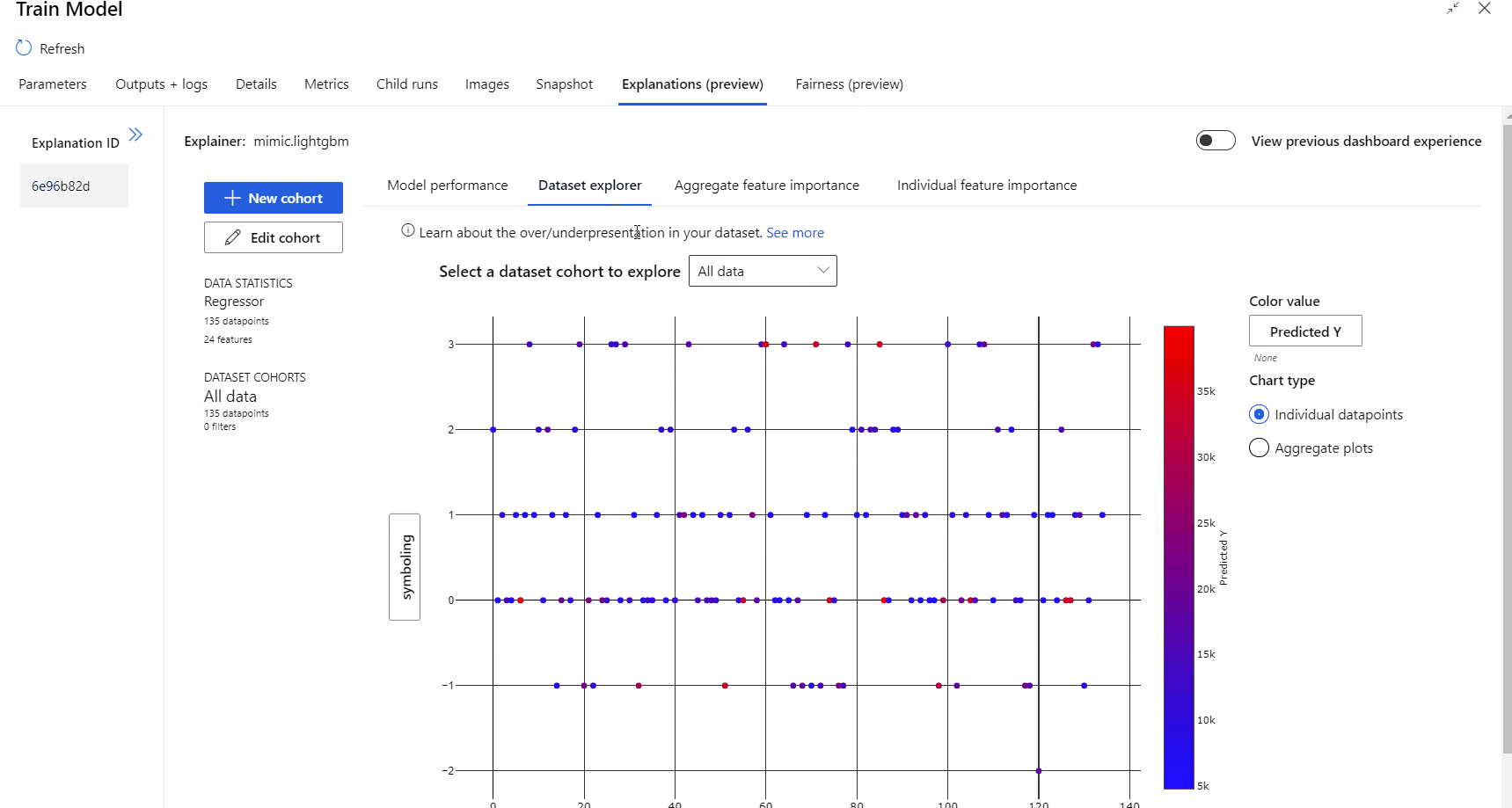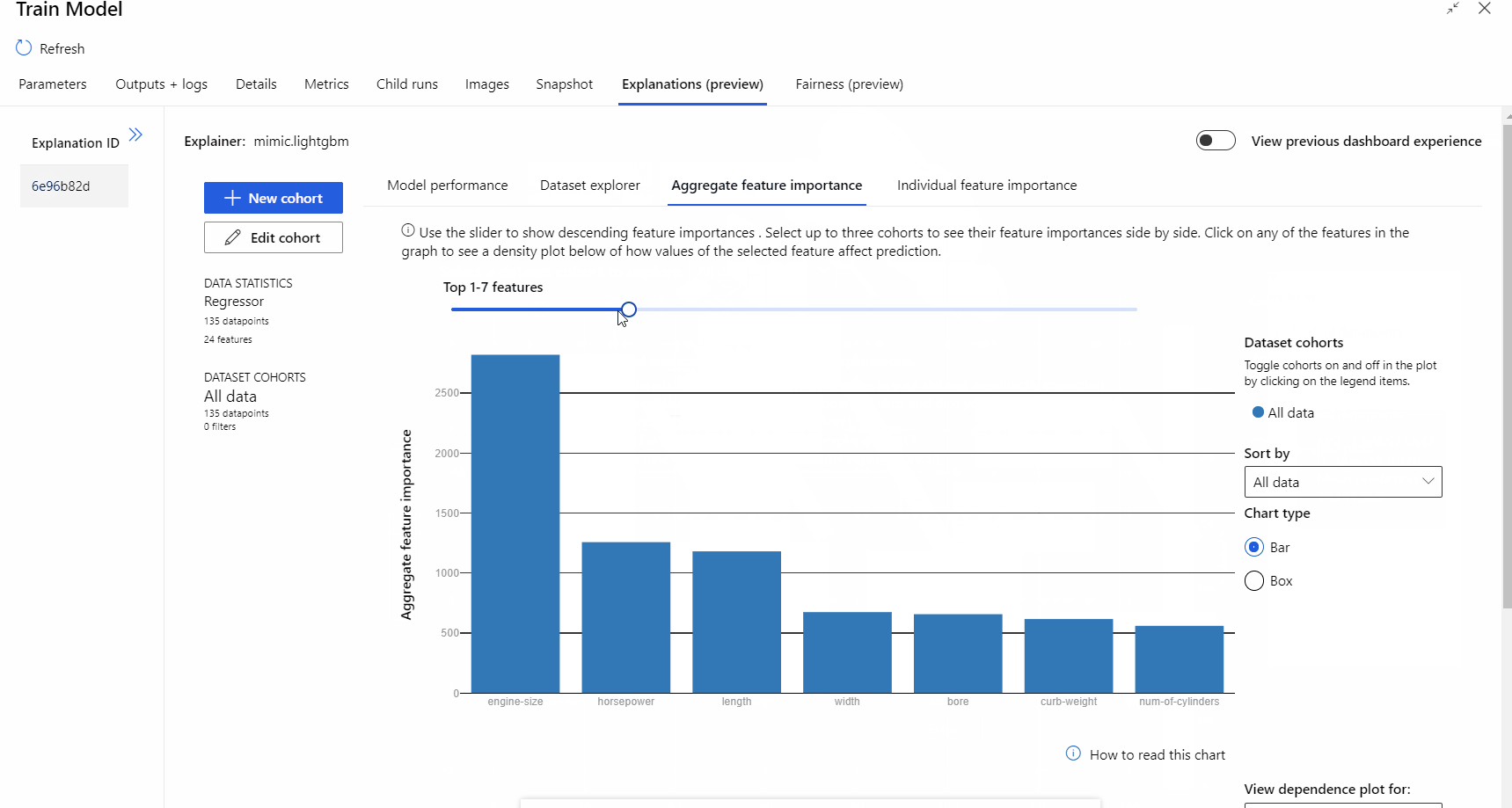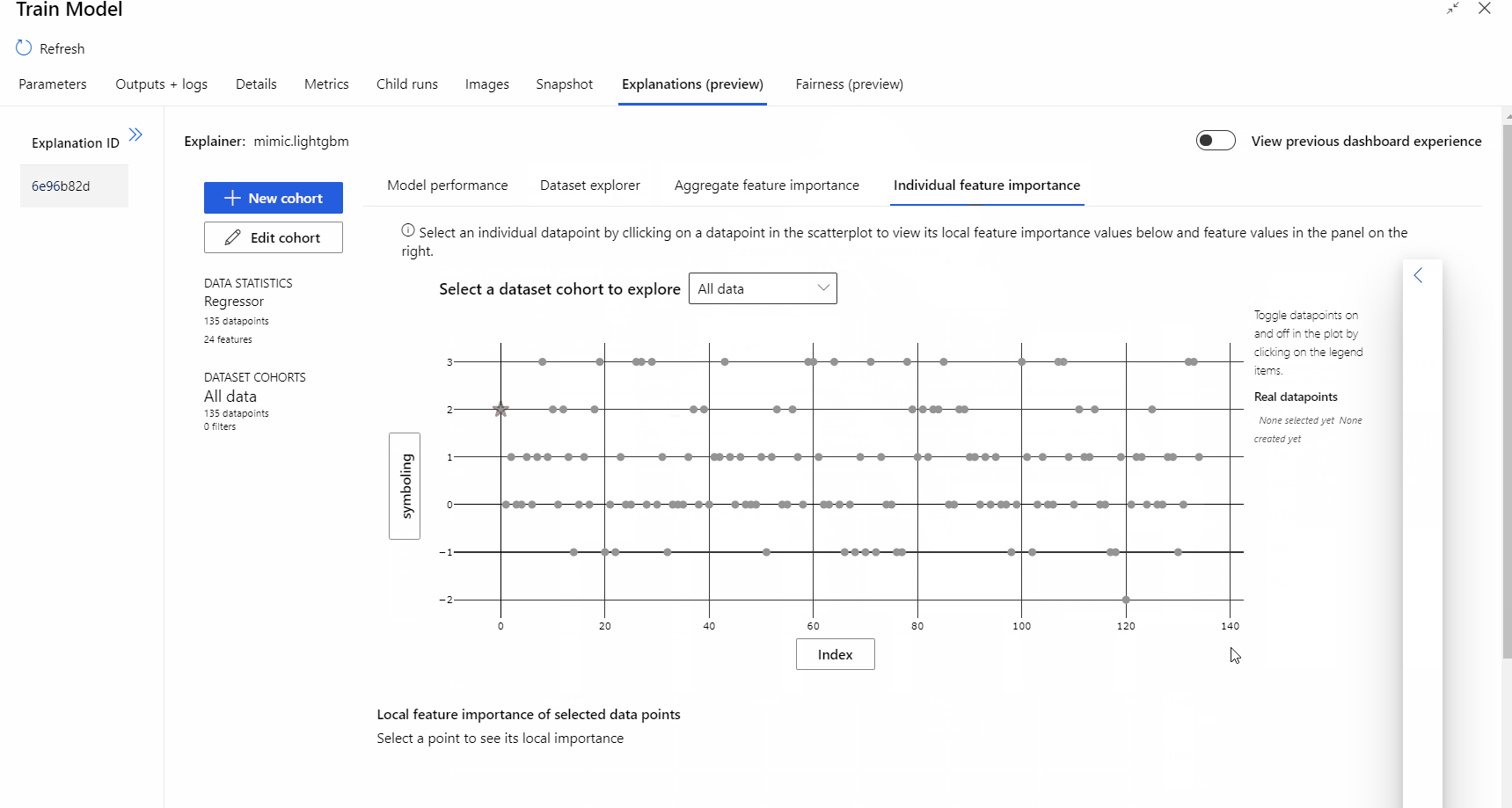
Para saber mais sobre como utilizar explicações de modelos no Azure Machine Learning, veja o artigo de procedimentos sobre Interpretar modelos de ML.
Resultados
Após a preparação do modelo:
Para utilizar o modelo noutros pipelines, selecione o componente e selecione o ícone Registar conjunto de dados no separador Saídas no painel direito. Pode aceder a modelos guardados na paleta de componentes em Conjuntos de dados.
Para utilizar o modelo na previsão de novos valores, ligue-o ao componente Modelo de Classificação , juntamente com novos dados de entrada.
Passos seguintes
Veja o conjunto de componentes disponíveis para o Azure Machine Learning.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários